1.4 The Bitter Lesson
2019년, 강화 학습의 개척자 중 한 명인 리처드 서튼(Richard Sutton)은 “The Bitter Lesson” (쓴 교훈)이라는 제목의 짧은 에세이를 썼습니다. 이 글은 현대 AI 분야에서 가장 영향력 있는 텍스트 중 하나가 되었으며, 이후 파운데이션 모델의 부상과 강하게 맞물려 읽히게 되었습니다.
비하인드 스토리: 이 에세이가 발표되었을 때 AI 학계에서는 적지 않은 논쟁이 일어났습니다. 특정 분야의 규칙과 휴리스틱을 오랫동안 다듬어 온 연구자들에게는, 서튼의 주장이 그 전통 전체를 지나치게 단순화한 비판처럼 들릴 수도 있었기 때문입니다. 하지만 몇 년 뒤 대규모 신경망 모델들이 실제로 강한 성과를 내기 시작하면서, 이 글은 도발적인 주장이라기보다 AI 발전의 방향을 설명하는 유용한 관점으로 다시 읽히게 되었습니다.
이 교훈을 간단한 비유를 통해 이해해 봅시다.
비유: 장인(匠人) vs. 자동화된 공장
당신이 복잡한 기계를 생산하고 싶다고 가정해 봅시다.
- 장인 (인간의 지식)은 평생을 바쳐 하나의 설계를 완성합니다. 모든 톱니바퀴와 레버를 손으로 직접 깎습니다. 결과물은 아름답고 잘 작동하지만, 만드는 데 수개월이 걸리고 쉽게 대량 생산(scale)할 수 없습니다.
- 자동화된 공장 (컴퓨팅 & 학습)은 매우 단순하고 일반적인 설계로 시작합니다. 톱니바퀴를 깎는 구체적인 방법은 모릅니다. 하지만 하루에 수백만 번의 실험을 수행하면서 프로세스를 자동으로 개선할 수 있습니다. 곧 공장은 장인이 상상할 수 있었던 것보다 더 복잡한 기계를 더 빠르게 생산해 냅니다.
여기서 장인에게 ‘쓴(bitter)’ 부분은, 평생 다듬어 온 전문 기술이 결국 더 단순하지만 연산량과 데이터를 크게 확장할 수 있는 시스템에 의해 추월될 수 있다는 점입니다.
The Lesson Stated (교훈의 내용)
서튼의 핵심 논지는 단순하지만 심오합니다:
“70년간의 AI 연구에서 얻을 수 있는 가장 큰 교훈은, 계산(computation)을 활용하는 일반적인 방법이 가장 효과적이며, 그것도 압도적인 차이로 효과적이라는 것이다.”
이 교훈이 AI 연구자들에게 ‘쓰다’고 하는 이유는, 인간의 지식, 직관, 그리고 hand-crafted feature에 크게 의존하는 방법들이 장기적으로는 정체 구간에 들어가는 경우가 많기 때문입니다. 그리고 시간이 지나면, 대규모 연산을 바탕으로 탐색하고 학습하는 일반적 방법이 그 자리를 대신하는 경우가 반복해서 나타납니다.
인간의 지식 vs. 컴퓨팅
서튼은 AI 역사에서 반복되는 패턴을 관찰했습니다:
- 연구자들은 인간의 지식을 인코딩하여 지능을 구축하려고 시도합니다 (예: 체스 규칙, 시각 특징).
- 이것은 단기적으로는 잘 작동하며 연구자들을 기분 좋게 만듭니다.
- 장기적으로 무어의 법칙(Moore’s Law)에 의해 컴퓨팅은 훨씬 더 저렴해집니다.
- 컴퓨팅을 활용하는 방법(무차별 대입 탐색 또는 거대 신경망 등)이 결국 인간 지식 기반의 방법들을 압도합니다.
The Two Pillars: Search and Learning (탐색과 학습)
서튼은 컴퓨팅 자원과 함께 끊임없이 확장되는 두 가지 범주의 방법을 식별합니다:
- Search (탐색): 방대한 가능성의 공간을 탐색하는 것 (예: AlphaGo의 몬테카를로 트리 탐색).
- Learning (학습): 방대한 양의 데이터를 기반으로 파라미터를 조정하는 것 (예: Transformer 학습).
Foundation model은 이 “학습(Learning)” 축이 대규모로 구현된 대표적 사례입니다. 문법, 물리학, 코드에 대한 규칙집을 명시적으로 넣기보다, 대규모 데이터와 최적화를 통해 유용한 구조를 내부적으로 학습합니다.
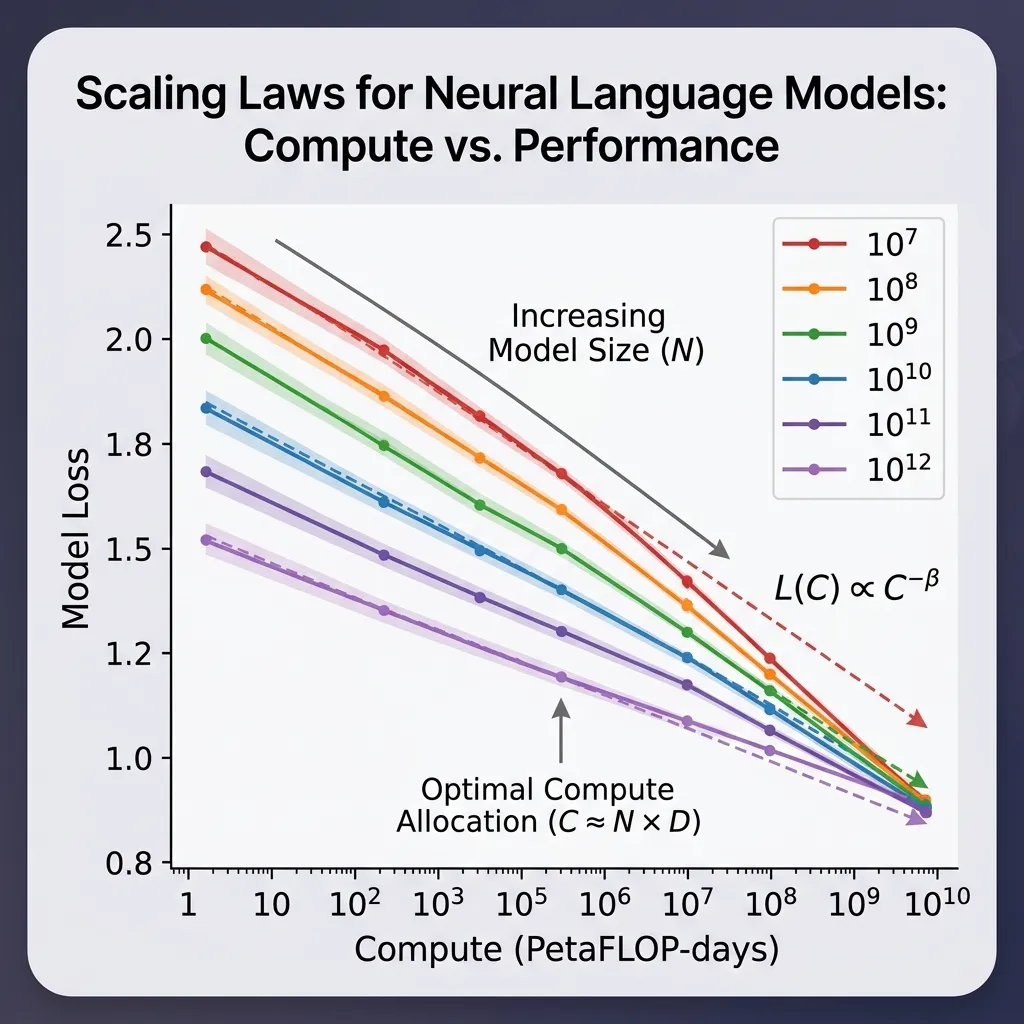
The Scaling Law (스케일링 법칙)
The Bitter Lesson의 구체적인 수학적 발현이 바로 Scaling Law (스케일링 법칙) 입니다. OpenAI 등의 연구에 따르면 거대 언어 모델의 성능은 세 가지 요소에 따라 예측 가능하게 확장됩니다:
- Model Size (): 파라미터 수.
- Dataset Size (): 토큰 수.
- Compute (): 학습에 사용된 총 부동 소수점 연산량 (FLOPs).
실제 스케일링 법칙 논문들은 보통 더 정교한 경험적 곡선을 맞추지만, 여기서는 간단한 설명용 형태로 다음과 같이 볼 수 있습니다: 여기서 은 손실(loss)이며, 는 스케일링 지수입니다.
이것이 의미하는 바는, 더 나은 성능을 원한다면 반드시 더 나은 알고리즘이 필요한 것이 아니라, 단지 를 확장하기만 하면 된다는 것입니다.
Code Example: Scaling Law 시뮬레이션
여기서 거대 모델을 직접 학습시킬 수는 없지만, 멱법칙 특성을 따라 컴퓨팅(모델 크기 데이터 크기)과 그에 따른 손실(loss) 사이의 관계를 시뮬레이션해 볼 수 있습니다.
import torch
import matplotlib.pyplot as plt
# 시뮬레이션된 스케일링 법칙 파라미터
alpha = 0.34 # 모델 크기에 대한 지수
beta = 0.28 # 데이터 크기에 대한 지수
# PyTorch를 사용하여 N과 D의 범위 정의
N_range = torch.logspace(1, 5, 20)
D_range = torch.logspace(1, 5, 20)
# N과 D에 대한 그리드 생성
N_grid, D_grid = torch.meshgrid(N_range, D_range, indexing='ij')
# PyTorch 연산을 사용하여 손실 그리드 계산
Loss = 1.0 / (N_grid**alpha) + 1.0 / (D_grid**beta)
# 플로팅을 위해 numpy로 변환 (matplotlib은 numpy를 필요로 함)
Loss_np = Loss.numpy()
N_np = N_range.numpy()
D_np = D_range.numpy()
# 결과 플로팅
plt.figure(figsize=(10, 6))
CS = plt.contourf(N_np, D_np, Loss_np, levels=20, cmap='viridis')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('Model Size (N)')
plt.ylabel('Dataset Size (D)')
plt.title('Simulated Scaling Law: Loss as a function of N and D')
plt.colorbar(CS, label='Loss')
plt.show()
print("우상단(더 많은 컴퓨팅)으로 이동할수록 항상 손실이 감소하는 것에 주목하세요.")Example: The Power of Scale
AI에 사용 가능한 “컴퓨팅 자원”을 조정해 보세요. 모델이 단순한 패턴 학습에서 복잡한 추론으로 어떻게 전환되는지 확인하여 The Bitter Lesson이 실제로 작동하는 모습을 확인해 보세요.
규모의 힘
사용 가능한 컴퓨팅 파워를 조절하여 모델의 능력이 어떻게 발현되는지 확인해보세요.
앞으로의 과제: 시퀀스 모델링의 도전
우리는 규모(scale)와 일반적인 방법이 강력하다는 것을 보았습니다. 하지만 이를 언어와 같은 시퀀스 데이터에 어떻게 적용할까요?
- 과거 토큰의 기억을 어떻게 효율적으로 유지할까요?
- 시퀀스가 극도로 길어지면 어떻게 될까요?
- 단순한 마르코프 체인에서 복잡한 신경망으로 어떻게 이동했을까요?
이러한 질문들은 우리가 시퀀스 데이터를 위해 특별히 설계된 모델들의 진화를 탐구할 챕터 2: 시퀀스 모델링 시대로 이어집니다.
Quizzes
Quiz 1: 왜 서튼의 교훈은 ‘쓰다(bitter)‘고 불리나요?
연구자들에게 쓴 이유는, 특정 규칙과 휴리스틱을 설계하는 인간의 독창성이 결국 대규모 계산과 함께 확장되는 단순하고 일반적인 방법보다 덜 효과적이라는 점을 시사하기 때문입니다. 이는 AI를 ‘가르치고’ 싶어 하는 전문가들의 자존심에 상처를 줍니다.
Quiz 2: The Bitter Lesson이 인간 전문가가 AI 연구에서 쓸모없다는 것을 의미하나요?
아닙니다. 인간의 전문 지식은 특징과 규칙을 설계하는 것에서 확장 가능한 아키텍처, 손실 함수, 그리고 데이터 파이프라인을 설계하는 것으로 이동합니다. 초점이 “무엇을 생각할 것인가”에서 “어떻게 배울 것인가”로 바뀝니다.
Quiz 3: 현대의 LLM은 어떻게 The Bitter Lesson을 반영하고 있나요?
LLM은 문법이나 논리에 대한 하드코딩된 규칙이 없습니다. 그것들은 단순히 수십억 개의 파라미터로 확장되고 수조 개의 토큰으로 학습된 단순한 다음 토큰 예측기입니다. 그들의 지능은 서튼이 예측한 대로 규모(scale)의 창발적 속성입니다.
Quiz 4: The Bitter Lesson은 특화된 AI 하드웨어 설계에 어떤 시사점을 주나요?
The Bitter Lesson은 하드웨어가 특정 알고리즘을 위한 특화된 연산보다는, 연산량과 함께 잘 확장되는 일반적이고 고도로 병렬화 가능한 연산(예: 행렬 곱셈)에 최적화되어야 함을 시사합니다. 이는 왜 특정 알고리즘 전용 아키텍처보다 GPU나 TPU가 지배적인 위치를 차지하게 되었는지를 설명합니다.
Quiz 5: “The Bitter Lesson”은 거대 모델의 “창발성(Emergence)” 개념과 어떤 관련이 있나요?
창발성은 작은 모델에서는 나타나지 않지만 큰 모델에서는 나타나는 능력을 말합니다. The Bitter Lesson은 우리가 컴퓨팅과 데이터를 확장함에 따라, 수동으로 규칙을 프로그래밍해서는 얻을 수 없었던 예상치 못한 창발적 능력이 나타날 것임을 예측합니다.
Quiz 6: Transformer 모델 학습을 위한 표준 연산량 근사식인 를 유도하고, 상수 이 도출되는 과정을 설명하시오.
Transformer 모델에서 정방향 패스(Forward pass) 시 각 파라미터는 토큰당 1회의 곱셈-덧셈(Multiply-Accumulate) 연산에 참여하며, 이는 파라미터당 FLOPs에 해당합니다. 따라서 정방향 패스는 토큰당 FLOPs가 필요합니다. 역방향 패스(Backward pass)에서는 정방향 패스의 약 2배의 연산량이 소요됩니다: 활성화 함수(Activation)에 대한 기울기를 구하는 데 FLOPs, 가중치(Weight)에 대한 기울기를 구하는 데 FLOPs가 필요합니다. 이를 모두 합산하면 전체 학습 단계(Forward + Backward)에서 토큰당 FLOPs가 소요됩니다. 여기에 데이터셋의 총 토큰 수 를 곱하면 전체 연산량 가 도출됩니다.
References
- Sutton, R. (2019). The Bitter Lesson. Link
- Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … & Amodei, D. (2020). Scaling laws for neural language models. arXiv:2001.08361.
- 추천 인터뷰: Dwarkesh Patel’s Interview with Rich Sutton ‘쓴 교훈’과 AI의 미래에 대한 서튼의 생각을 더 깊이 들을 수 있는 훌륭한 인터뷰입니다.