3.3 위치 인코딩 전략
트랜스포머 아키텍처는 순환(recurrence)이나 합성곱(convolution)을 포함하지 않기 때문에 단어 순서에 대한 개념이 없습니다. 모델에 위치 감각을 제공하려면 시퀀스에 있는 토큰의 상대적 또는 절대적 위치에 대한 정보를 주입해야 합니다. 여기서 위치 인코딩(Positional Encoding) 이 등장합니다.
동기: Bag-of-Words 문제
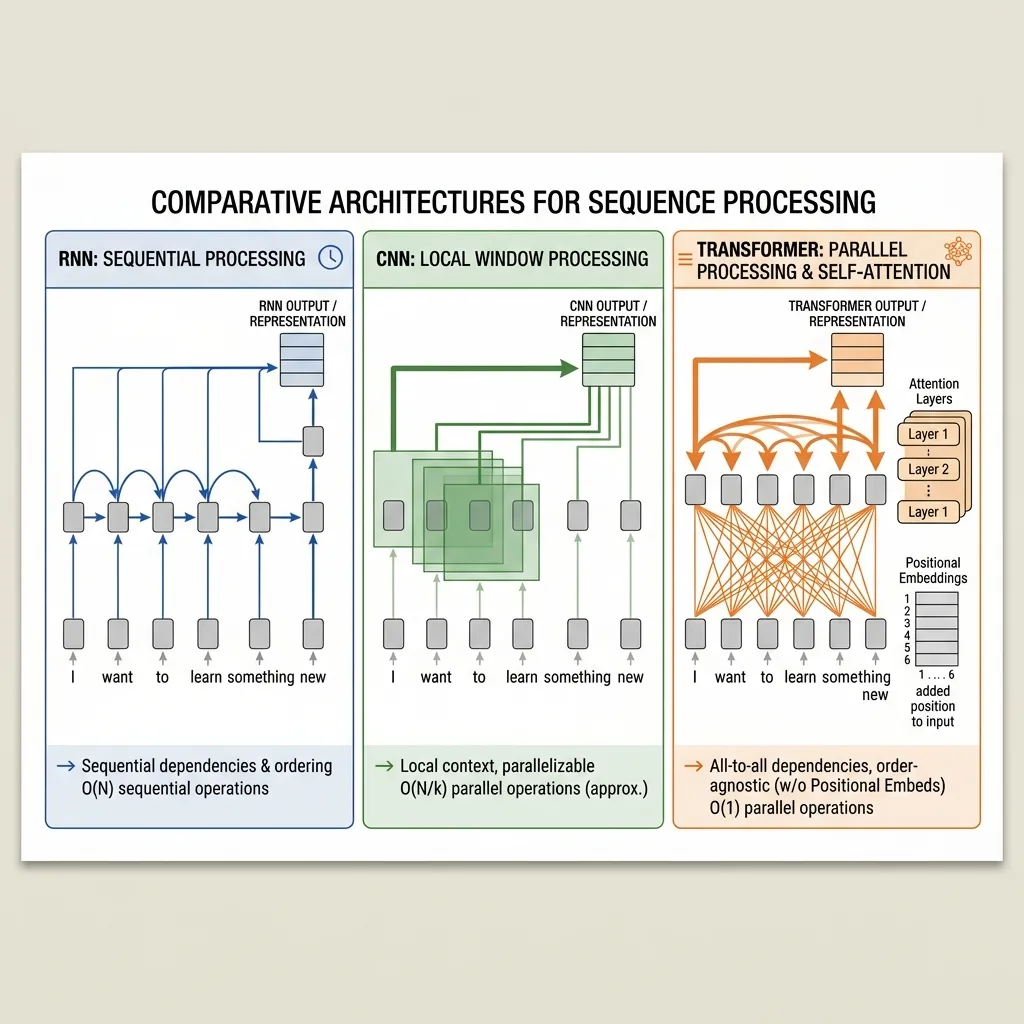
위치 인코딩이 필요한 이유를 이해하려면 트랜스포머가 RNN 이나 CNN 과 같은 기존 시퀀스 모델과 비교하여 데이터를 어떻게 처리하는지 대조해 봐야 합니다.
1. RNN (Recurrent Neural Networks): 자연스러운 순서
RNN은 토큰을 하나씩 순차적으로 처리합니다. 모델은 각 단계에서 업데이트되는 은닉 상태(hidden state)를 유지합니다: . 단어 A를 처리한 다음 단어 B, 단어 C를 처리하기 때문에 자연스럽게 시간과 순서에 대한 개념을 갖게 됩니다. B가 A 다음에 왔다는 것을 알 수 있습니다.
2. CNN (Convolutional Neural Networks): 지역적 순서
CNN은 텍스트의 지역적 윈도우(예: n-gram)에 필터를 적용합니다. 단어를 3개 또는 5개씩 묶어서 봄으로써 모델은 지역적인 순서 와 근접성을 포착합니다. 어떤 단어가 인접해 있는지 알 수 있습니다.
3. 트랜스포머 (Self-Attention): 순열 불변성
이와 대조적으로, 셀프 어텐션은 시퀀스의 모든 토큰을 동시에 병렬로 처리합니다. 이 공식에는 인덱스나 위치에 대한 개념이 없다는 점에 주목하세요. 입력 문장의 단어 순서를 섞으면 출력 벡터도 똑같이 섞일 뿐, 값 자체는 동일합니다. 모델은 입력을 시퀀스가 아닌 단어들의 집합 (또는 bag of words)으로 처리합니다.
- 비유:
- RNN은 손가락으로 줄을 따라가며 문장을 단어 단위로 읽는 것과 같습니다.
- CNN은 한 번에 3개의 단어를 보여주는 돋보기를 통해 문장을 보는 것과 같습니다.
- Transformer 는 모든 단어를 믹서기에 넣고 혼합물을 보는 것과 같습니다. 라벨(위치 정보)이 없으면 어떤 단어가 먼저였는지 알 수 없습니다.
이 대칭성을 깨고 트랜스포머에 순서 개념을 부여하기 위해 우리는 위치 인코딩 을 추가해야 합니다.
비유: 흩어진 종이의 페이지 번호
책이 있는데 모든 페이지가 찢어져 바닥에 흩어져 있다고 상상해 보세요.
- 페이지들을 그냥 읽으면(순수 셀프 어텐션) 각 페이지의 내용은 이해할 수 있지만 이야기의 순서는 알 수 없습니다. 페이지 A가 페이지 B보다 먼저인가요?
- 위치 인코딩은 종이들을 바닥에 던지기 전에 각 시트의 하단에 페이지 번호 를 적는 것과 같습니다. 이제 종이들이 흩어져 있어도 페이지 번호를 읽고 시퀀스에서 해당 페이지가 정확히 어디에 속하는지 알 수 있습니다.
트랜스포머에서는 단순히 숫자를 덧붙이는 것이 아니라, 단어 임베딩에 복잡한 파동 패턴을 추가합니다.
사인파 위치 인코딩의 수학
“Attention Is All You Need” [1]의 저자들은 서로 다른 주파수의 사인 및 코사인 함수를 사용하여 위치 인코딩을 생성했습니다.
시퀀스의 위치에 있는 토큰과 차원 에 대해:

여기서:
- 는 시퀀스에서의 위치입니다.
- 는 차원 인덱스입니다 ().
- 은 임베딩의 차원입니다.
왜 사인파인가?
저자들은 어떤 고정된 오프셋 에 대해 가 의 선형 함수로 표현될 수 있기 때문에, 이 방식이 모델이 상대적 위치 에 의해 어텐션을 쉽게 학습할 수 있게 해줄 것이라고 가설을 세웠기 때문에 이 방식을 선택했습니다.
상대적 위치를 위한 선형 관계
모델이 상대적 위치에 주의를 기울일 수 있게 해주는 수학적 특성을 살펴보겠습니다. 특정 차원 에 대해 위치 인코딩은 다음과 같습니다: 여기서 입니다.
만약 위치의 인코딩을 찾고자 한다면, 삼각함수의 합공식을 사용할 수 있습니다:
여기서 와 는 고정된 오프셋 에 대해 상수입니다. 따라서 에서의 인코딩을 에서의 인코딩의 선형 조합으로 표현할 수 있습니다:
이러한 선형 관계 덕분에 모델은 절대적인 위치에 관계없이 상대적인 위치에 주의를 기울이는 법을 쉽게 배울 수 있습니다.
사인파를 넘어서: 위치 인코딩의 진화
사인파 접근 방식은 훌륭한 출발점이었지만, 이후 모델에 위치 정보를 더 잘 캡처하기 위한 다양한 방법들이 개발되었습니다. 다음은 가장 대표적인 기술들의 비교입니다:
1. 절대적 위치 인코딩 (Absolute Positional Encodings - Sinusoidal & Learned)
- Sinusoidal : 고정된 함수입니다. 이론적으로는 더 긴 시퀀스로의 외삽(Extrapolation)이 가능하지만, 실제로는 성능이 저하됩니다.
- Learned : 위치 자체를 학습 가능한 임베딩(단어 임베딩처럼)으로 처리합니다. BERT 및 GPT-2/3에서 사용되었습니다. 단순하지만 학습 중에 정의된 최대 시퀀스 길이를 넘어서는 외삽이 불가능합니다.
2. 상대적 위치 인코딩 (Relative Positional Encodings)
각 토큰에 절대적인 위치를 부여하는 대신, 토큰 간의 거리 를 인코딩합니다.
- Shaw et al. (2018) : 셀프 어텐션을 수정하여 키(Key)와 값(Value)에 상대적 위치 표현을 포함합니다.
3. 현대 SOTA 인코딩 (Modern SOTA Encodings)
- RoPE (Rotary Position Embedding) : 위치에 따라 쿼리(Query)와 키(Key) 벡터에 회전 행렬을 적용합니다. 상대적 거리를 자연스럽게 포착하며 Llama, Gemma, DeepSeek, Qwen 등 많은 현대 LLM에서 사용됩니다.
- ALiBi (Attention with Linear Biases) : 임베딩을 추가하는 대신, 거리에 따라 선형적으로 증가하는 정적 패널티를 어텐션 스코어에 더합니다. 매우 효율적이며 길이 외삽 능력이 뛰어납니다.
비교 테이블
| 방법 | 유형 | 외삽 가능성 | 학습 가능 여부 | 사용된 모델 | 장점 | 단점 |
|---|---|---|---|---|---|---|
| Sinusoidal | 절대적 | 제한적 | 아니오 | Original Transformer | 학습할 파라미터가 없음 | 고정되어 있어 모든 작업에 최적은 아님 |
| Learned | 절대적 | 불가 | 예 | BERT, GPT-3 | 데이터에 적응함 | 더 긴 시퀀스를 처리할 수 없음 |
| RoPE | 상대적 | 뛰어남 | 아니오 | Llama, Gemma, DeepSeek, Qwen | 상대적 거리를 잘 포착함 | 구현이 복잡함 |
| ALiBi | 상대적 | 뛰어남 | 아니오 | BLOOM, MPT | 매우 단순하며 외삽이 뛰어남 | 매우 긴 시퀀스에는 미세 조정이 필요할 수 있음 |
왜 사인파를 선택했고, 왜 다른 방식으로 이동했는가?
오리지널 트랜스포머가 사인파 인코딩을 사용한 이유는 다음과 같습니다:
- 파라미터가 없음 : 모델 크기를 늘리지 않았습니다.
- 이론적 외삽 : 저자들은 더 긴 시퀀스를 처리할 수 있기를 기대했습니다.
그러나 모델이 커지고 시퀀스 길이가 중요해지면서(예: 책 한 권 처리), RoPE 와 ALiBi 같은 방법들이 긴 컨텍스트 작업 처리에서 훨씬 더 우수한 성능을 입증하여 오늘날의 대세가 되었습니다.
Rotary Position Embedding (RoPE) 자세히 알아보기
사인파 인코딩이 훌륭한 출발점이었지만, 현대의 SOTA LLM들(Llama 3, Gemma 4, DeepSeek V3, Qwen 3, GLM 시리즈 등)은 거의 예외 없이 Rotary Position Embedding (RoPE) [2]를 사용합니다. RoPE는 절대적 위치 인코딩과 상대적 위치 인코딩의 장점을 결합한 하이브리드 방식입니다.
직관적 이해: 2D 공간에서의 회전
토큰의 표현을 다차원 공간의 한 점으로 상상해 보세요. 단순화를 위해 2차원만 살펴보겠습니다.
- 위치 정보가 없다면, 두 토큰 벡터 사이의 거리와 각도는 고정되어 있습니다.
- RoPE는 이 벡터들을 회전시켜 위치 정보를 주입합니다. 회전 각도는 시퀀스 내 토큰의 위치에 비례합니다.
토큰 A가 위치 에 있고 토큰 B가 위치 에 있다면, RoPE는 토큰 A를 만큼, 토큰 B를 만큼 회전시킵니다. 두 토큰 사이의 어텐션 스코어(내적)를 계산할 때, 결과는 두 각도의 차이인 에 의존하게 됩니다. 이는 토큰들 사이의 상대적 거리를 완벽하게 포착합니다!
RoPE의 수학
RoPE는 입력 임베딩에 더해지는 것이 아니라, 선형 투영(linear projection)된 후의 쿼리() 및 키() 벡터에 적용됩니다.
2D 벡터 에 대해 RoPE는 회전 행렬을 적용합니다:
차원 벡터의 경우, 차원을 개의 쌍으로 묶고 각 쌍에 서로 다른 주파수 를 사용하여 2D 회전을 적용합니다.
어텐션 스코어 계산에서 마법이 일어납니다. 위치 의 쿼리를 , 위치 의 키를 이라고 해봅시다: 이기 때문에, 내적 결과는 오직 상대적 거리 에만 의존합니다.
왜 RoPE가 현대 LLM을 지배하는가 (인사이트)
- 완벽한 상대적 위치 인식: 모델이 상대적 거리를 추출하도록 학습해야 하는 절대적 인코딩과 달리, RoPE는 어텐션 스코어가 상대적 거리의 함수임을 수학적으로 보장합니다.
- 거리에 따른 감쇠: 서로 다른 주파수를 사용함으로써, 거리가 멀어질수록 토큰 간의 상관관계가 자연스럽게 감쇠합니다. 이는 가까운 단어가 대개 더 중요하다는 인간 언어의 직관과 일치합니다.
- 길이 외삽 (Length Extrapolation): RoPE는 학습 중에 본 것보다 긴 시퀀스를 절대적 인코딩보다 훨씬 더 잘 처리합니다. RoPE Scaling(예: Linear Scaling 또는 NTK-aware scaling)과 같은 기술을 사용하면, 주파수를 단순히 스케일링함으로써 4K 컨텍스트로 학습된 모델을 128K 이상으로 확장할 수 있습니다.
PyTorch 구현
다음은 PyTorch에서 위치 인코딩 행렬을 생성하는 방법입니다.
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# (max_len, d_model) 크기의 행렬 생성
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 사인 및 코사인 값 채우기
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 배치 차원 추가 (1, max_len, d_model)
pe = pe.unsqueeze(0)
# 버퍼로 등록 (옵티마이저에 의해 업데이트되지 않음)
self.register_buffer('pe', pe)
def forward(self, x):
# x shape: (batch_size, seq_len, d_model)
# 입력 임베딩에 위치 인코딩 추가
x = x + self.pe[:, :x.size(1)]
return x
# 사용 예시
d_model = 16
seq_len = 10
pe_layer = PositionalEncoding(d_model)
# 시뮬레이션된 입력 임베딩
x = torch.randn(1, seq_len, d_model)
x_encoded = pe_layer(x)
print("원본 형태:", x.shape)
print("인코딩된 형태:", x_encoded.shape)예제: 인코딩 행렬
위치 인코딩 행렬을 시각화해 보세요. 가로축은 임베딩 차원을 나타내고, 세로축은 시퀀스에서의 위치를 나타냅니다. 파동 패턴을 통해 모델이 위치를 구별할 수 있습니다.
Quizzes
Quiz 1: 트랜스포머는 왜 절대 위치 숫자(1, 2, 3…)를 인코딩으로 그냥 사용하지 않습니까?
절대 정수를 그냥 더하면 긴 시퀀스의 경우 값이 매우 커져서 단어 임베딩을 지배할 수 있습니다. 또한 모델이 학습 중에 본 것보다 더 긴 시퀀스 길이로 일반화되지 않을 수 있습니다. 사인파 인코딩은 -1과 1 사이로 제한되며 위치의 부드럽고 연속적인 표현을 제공합니다.
Quiz 2: 사인 함수와 코사인 함수를 모두 사용하면 어떤 이점이 있습니까?
두 함수를 모두 사용하면 모델이 상대적 위치를 선형 조합으로 표현할 수 있습니다. 구체적으로, 는 의 선형 변환으로 계산될 수 있으므로 모델이 상대적 위치(예: “왼쪽으로 2단계 떨어진 단어”)에 어텐션을 기울이는 법을 더 쉽게 배울 수 있습니다.
Quiz 3: 사인파 위치 인코딩의 대안이 있습니까?
예. 많은 현대 모델(예: GPT-3)은 학습 가능한 위치 임베딩 (Learned Positional Embeddings) 을 사용합니다. 여기서 위치 벡터는 단어 임베딩과 마찬가지로 학습 중에 학습되는 파라미터로 처리됩니다. 또 다른 인기 있는 방법은 Llama 모델에서 사용되는 RoPE (Rotary Position Embedding) 로, 위치에 따라 쿼리 및 키 벡터에 회전을 적용합니다.
Quiz 4: 위치 인코딩에서 왜 차원마다 다른 주파수를 사용하나요?
서로 다른 주파수를 사용하면 매우 긴 시퀀스 길이에서도 반복되지 않는 고유한 패턴을 각 위치마다 생성할 수 있습니다. 낮은 차원은 높은 주파수(짧은 파장)를 갖고, 높은 차원은 낮은 주파수(긴 파장)를 가져서 모델이 미세한 위치 관계와 거친 위치 관계를 모두 포착할 수 있게 합니다.
Quiz 5: PyTorch 구현에서 왜 위치 인코딩 행렬에
register_buffer를 사용하나요?register_buffer는 모델 상태의 일부이지만 옵티마이저에 의해 학습될 파라미터가 아닌 텐서에 사용됩니다. 이를 통해 모델을 저장할 때 위치 인코딩 행렬도 함께 저장되고, 모델에 .to('cuda')를 호출할 때 GPU로 이동되지만, 이에 대한 그래디언트는 계산되지 않습니다.
Quiz 6: 위치 에서의 2차원 서브스페이스에 대한 RoPE 회전 행렬을 수학적으로 공식화하고, 위치 의 쿼리와 위치 의 키의 내적이 상대적 거리 에만 엄격하게 의존함을 증명하시오.
2차원 벡터 에 대해, 위치 에서의 RoPE 행렬은 입니다. 쿼리와 키의 2차원 표현을 각각 와 라고 합시다. RoPE로 인코딩된 벡터들의 내적은 입니다. 은 각도 만큼의 회전을 나타내는 직교 행렬이므로, 전치 행렬은 역행렬인 회전 행렬과 같습니다. 따라서 은 결합된 각도 만큼의 회전인 을 나타냅니다. 결과적으로 가 되며, 이는 상대적 거리 에만 명시적으로 의존하여 상대적 위치 정보를 완벽하게 보존함을 보여줍니다.
References
- Vaswani, A., et al. (2017). Attention is all you need. Advances in neural information processing systems, 30. arXiv:1706.03762.
- Su, J., et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864.