13.3 Weight Sparsification
양자화(Quantization)가 각 가중치의 수치적 정밀도를 낮추어 메모리 사용량을 줄인다면, 가중치 희소화(Weight Sparsification) 또는 가지치기(Pruning)는 가중치 자체를 완전히 제거하는 것을 목표로 합니다. 파라미터가 모델의 출력에 의미 있는 기여를 하지 않는다면, 이를 0으로 만들어 버리는 것입니다. 이는 메모리 요구량을 줄일 뿐만 아니라, 추론 시 필요한 부동소수점 연산(FLOPs)을 물리적으로 제거하는 효과를 가져옵니다.
그러나 대형 언어 모델(LLM)은 내부에 매우 민감한 논리적 표현(Representations)을 가지고 있습니다. 크기가 가장 작은 가중치들을 단순히 버리는 크기 기반 가지치기(Magnitude Pruning)는 높은 희소성(Sparsity) 수준에서 모델의 추론 능력을 철저히 파괴합니다. 현대의 LLM 희소화는 가중치와 활성화(Activation) 사이의 복잡한 상호작용을 평가하는 고급 알고리즘을 필요로 합니다.
이 섹션에서는 구조적 제약이 가져오는 엔지니어링의 현실, One-shot 헤시안 가지치기의 수학적 원리, 그리고 활성화 동역학에 기반하여 가중치를 가지치기하는 최신 알고리즘들을 심층적으로 탐구합니다.
1. 희소성의 지형: 비구조적 vs 구조적 (Unstructured vs. Structured)
모든 0이 동일하게 취급되는 것은 아닙니다. 가지치기된 가중치의 물리적인 배치 구조는 이론적인 FLOPs 감소가 실제 하드웨어에서의 속도 향상으로 이어질지를 결정합니다.
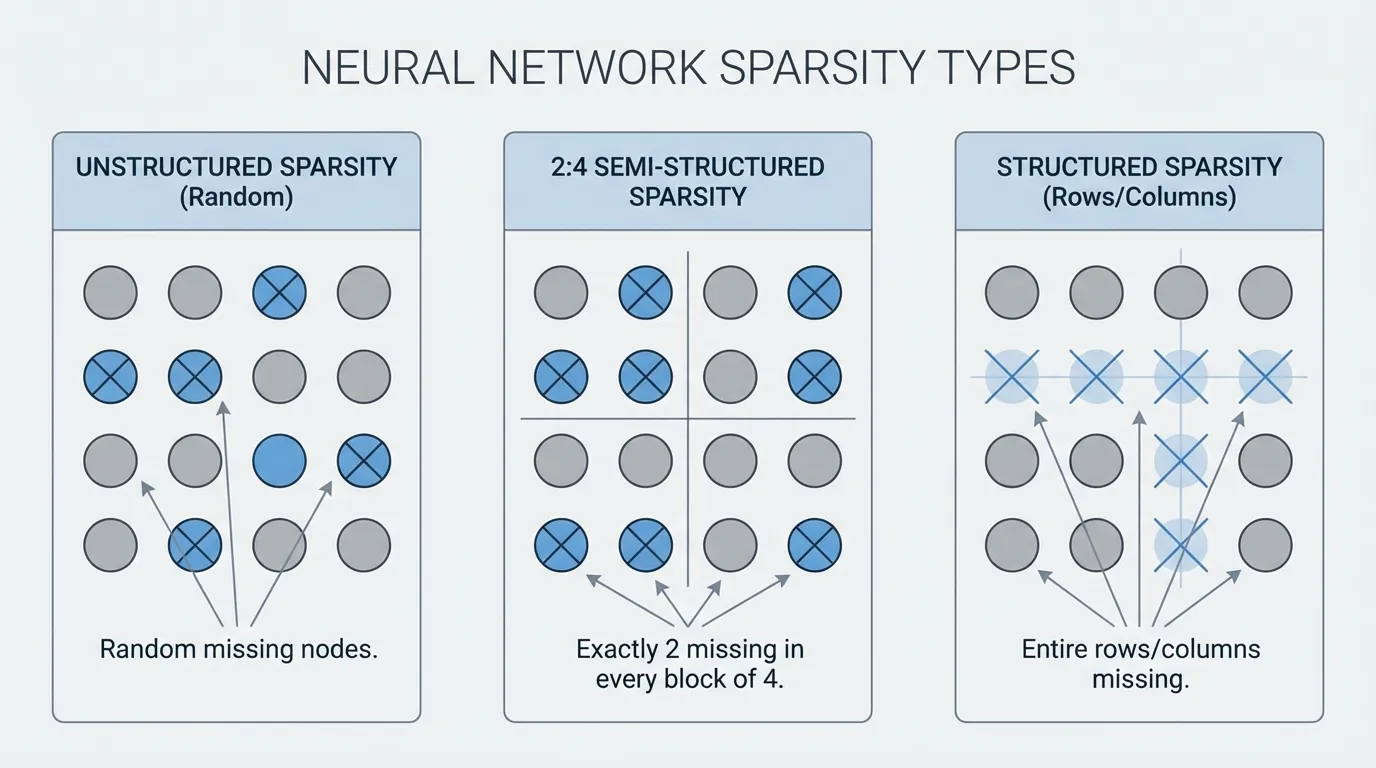 Source: Generated by Gemini. 다양한 희소성 패턴(비구조적, 2:4 반구조적, 구조적)의 메모리 배열 차이를 보여주는 개념도.
Source: Generated by Gemini. 다양한 희소성 패턴(비구조적, 2:4 반구조적, 구조적)의 메모리 배열 차이를 보여주는 개념도.
- Unstructured Sparsity (비구조적 희소성) : 무작위 위치의 개별 가중치가 0으로 설정됩니다. 모델의 정확도를 유지하는 데는 탁월하지만, 표준 GPU에서는 실제 속도 향상을 거의 제공하지 못합니다. 밀집 행렬 곱셈(Dense matrix multiplication) 커널은 연속적인 메모리 접근에 고도로 최적화되어 있기 때문에, 무작위로 흩어진 0을 건너뛰는 것은 분기(Branching)와 불규칙한 메모리 접근 패턴을 유발하여 GPU의 스트리밍 멀티프로세서를 마비시킵니다.
- Semi-Structured (N:M) Sparsity (반구조적 희소성) : 실용적인 하드웨어 타협안입니다. 2:4 희소성 에서는 행렬의 연속된 4개의 가중치 중 정확히 2개가 가지치기됩니다. NVIDIA의 Ampere, Hopper, Blackwell 아키텍처는 이러한 2:4 행렬을 메모리에서 압축하고 밀집 행렬 대비 최대 2배 빠른 속도로 연산을 수행하는 특수 희소 텐서 코어(Sparse Tensor Cores)를 갖추고 있습니다.
- Structured Sparsity (구조적 희소성) : 전체 구조(행, 열, 어텐션 헤드 또는 MLP 채널)가 통째로 제거됩니다. 이는 행렬의 차원을 물리적으로 축소시키며, 특수 코어 없이도 어떤 하드웨어에서든 표준 밀집 커널을 사용하여 즉각적인 엔드투엔드(End-to-end) 속도 향상을 얻을 수 있습니다. 역사적으로 이는 심각한 정확도 저하를 초래했지만, 최근의 혁신적인 연구들이 이 패러다임을 바꾸고 있습니다.
2. SparseGPT: One-Shot 헤시안 가지치기
GPTQ가 양자화에 혁명을 일으켰듯, SparseGPT [1] 는 100B(1천억 개) 이상의 파라미터를 가진 거대 모델을 값비싼 재학습이나 미세 조정 없이 단 한 번의 실행(One-shot)으로 50~60%의 비구조적 희소성으로 가지치기할 수 있음을 증명했습니다.
SparseGPT는 가지치기를 레이어 단위의 희소 회귀(Sparse regression) 문제로 공식화합니다. 단순히 가중치를 지우는 것이 아니라 다음과 같이 묻습니다: “이 가중치를 강제로 0으로 만든다면, 손실된 신호를 보상하기 위해 남아있는 가중치들을 어떻게 조정해야 할까?”
이를 해결하기 위해 SparseGPT는 이전 양자화 섹션에서 다루었던 것과 유사하게 레이어 입력 활성화 값의 역헤시안 행렬(Inverse Hessian Matrix, )을 사용합니다. 주어진 가중치 행렬 와 입력 에 대해, 목표는 다음의 제곱 오차를 최소화하는 희소 행렬 를 찾는 것입니다:
SparseGPT는 가중치 행렬을 순차적으로 처리합니다. 특정 가중치가 가지치기될 때, 그로 인해 발생하는 오차는 헤시안에 포착된 상관관계를 사용하여 아직 가지치기되지 않은 나머지 가중치들에 투영(Project)됩니다. 매우 높은 정확도를 유지하지만, 압축 단계에서 거대한 헤시안 행렬을 계산하고 역산하는 데 상당한 연산 오버헤드가 발생합니다.
3. Wanda: 가중치와 활성화를 통한 가지치기
SparseGPT가 복잡한 가중치 업데이트에 의존하는 반면, Wanda (Pruning by Weights and activations) [2] 는 가중치 업데이트가 전혀 없이도 경쟁력 있는 성능을 달성하는 놀랍도록 단순한 대안을 제시했습니다.
Wanda는 AWQ를 구동하는 것과 동일한 원칙, 즉 가중치의 중요도는 그 가중치를 통과하는 활성화 값의 크기와 뗄 수 없는 관계에 있다는 점에 기반합니다. 작은 가중치라도 거대한 활성화 이상치(Outlier)와 곱해진다면 결코 쓸모없는 것이 아닙니다.
절대적인 가중치 크기 에 기반하여 무작정 가지치기하는 대신, Wanda는 다음 공식을 사용하여 각 가중치의 점수를 매깁니다: 여기서 는 작은 캘리브레이션 데이터셋을 통해 계산된 번째 특징(Feature)에 대한 입력 활성화 값의 -노름(Norm)입니다.
Wanda는 이 점수를 출력 채널을 기준으로(동일한 행 내에 있는 가중치들끼리만 비교하여) 평가합니다. 가장 낮은 를 가진 가중치를 버림으로써, Wanda는 LLM 활성화의 “거대한 이상치”와 정렬된 가중치들을 자연스럽게 보호하며, 헤시안 역산 없이도 모델의 핵심 추론 경로를 보존합니다.
4. Wanda를 활용한 2:4 희소성 구현
비구조적 가지치기 알고리즘을 추론 가속에 실질적으로 활용하기 위해, 엔지니어들은 종종 이를 N:M 패턴으로 제약합니다. 아래의 PyTorch 구현은 Wanda 지표를 적용하여 엄격한 2:4 반구조적 희소성을 강제하고, NVIDIA의 희소 텐서 코어에 맞게 행렬을 포맷팅하는 방법을 보여줍니다.
import torch
def compute_wanda_scores(W: torch.Tensor, X: torch.Tensor) -> torch.Tensor:
"""
Wanda 중요도 점수를 계산합니다.
W: 가중치 행렬 [out_features, in_features]
X: 캘리브레이션 활성화 값 [batch * seq_len, in_features]
"""
# 각 입력 채널에 대한 활성화 값의 L2 노름(Norm) 계산
X_norm = torch.norm(X, p=2, dim=0) # Shape: [in_features]
# 가중치의 크기(Magnitude)에 활성화 노름을 곱함
# X_norm을 모든 출력 채널에 브로드캐스팅(Broadcasting)
scores = torch.abs(W) * X_norm.unsqueeze(0)
return scores
def apply_2_4_sparsity(W: torch.Tensor, scores: torch.Tensor) -> torch.Tensor:
"""
중요도 점수에 기반하여 2:4 반구조적 희소성을 적용합니다.
연속된 4개의 가중치 블록마다 정확히 2개의 0을 강제합니다.
"""
out_features, in_features = W.shape
assert in_features % 4 == 0, "in_features는 반드시 4의 배수여야 합니다."
# 점수와 가중치를 4개 단위의 블록으로 형태 변환(Reshape)
scores_blocked = scores.view(out_features, in_features // 4, 4)
W_blocked = W.clone().view(out_features, in_features // 4, 4)
# 각 블록에서 가장 점수가 낮은 2개의 인덱스를 찾음
_, indices = torch.topk(scores_blocked, k=2, dim=-1, largest=False)
# 마스크를 생성하고 가지치기할 위치에 False를 채움
mask = torch.ones_like(W_blocked, dtype=torch.bool)
mask.scatter_(dim=-1, index=indices, value=False)
# 마스크를 적용하고 원래 차원으로 되돌림
W_pruned = W_blocked * mask
return W_pruned.view(out_features, in_features)
# 실행 예시
out_feat, in_feat = 128, 256
W = torch.randn(out_feat, in_feat)
X = torch.randn(1024, in_feat) # 1024개의 캘리브레이션 토큰
scores = compute_wanda_scores(W, X)
W_sparse = apply_2_4_sparsity(W, scores)
# 2:4 희소성 검증 (정확히 50%가 0이어야 함)
sparsity = (W_sparse == 0).float().mean().item()
print(f"적용된 모델 희소성(Sparsity): {sparsity * 100:.1f}%")5. SliceGPT: 행과 열의 삭제
2:4 희소성이 특정 하드웨어의 지원을 필요로 하는 반면, SliceGPT [3] 는 계산적 불변성(Computational invariance)을 통한 구조적 가지치기라는 근본적으로 다른 접근 방식을 취합니다. 개별 가중치를 0으로 만드는 대신, SliceGPT는 가중치 행렬에서 전체 행(Row)과 열(Column)을 물리적으로 삭제해 버립니다.
SliceGPT는 직교 변환(Orthogonal transformations, PCA와 유사한 개념)을 사용하여 가중치 행렬을 수학적으로 더 작은 차원의 공간으로 투영(Project)합니다. 이 변환은 모델의 핵심 신호를 상위 행과 열에 집중시키고, 하위 행과 열에는 주로 노이즈만 남게 만듭니다. 그런 다음 이 하위 행과 열을 완전히 잘라냅니다(Slice off).
이 방식은 임베딩 차원(Embedding dimension) 자체를 줄이기 때문에, 결과적으로 생성된 행렬은 여전히 완전히 밀집된(Dense) 상태이며 크기만 작아집니다. 따라서 특수한 희소 실행 커널에 의존하지 않고도 어떤 하드웨어에서든 즉각적이고 비례적인 메모리 및 연산 속도 향상을 얻을 수 있습니다.
6. 인터랙티브 컴포넌트: 희소화 시각화 시뮬레이터
아래의 대화형 시각화는 극단적인 활성화 이상치(Outlier)가 존재하는 환경에서 다양한 가지치기 알고리즘이 가중치 행렬을 어떻게 처리하는지 보여줍니다.
- Magnitude Pruning 이 핵심 가중치를 어떻게 맹목적으로 파괴하는지 관찰해 보세요.
- Wanda 가 높은 활성화 값과 정렬된 가중치를 어떻게 보호하는지 확인해 보세요.
- 2:4 Sparsity 의 엄격한 블록 단위 제약을 이해해 보세요.
Activation Norms (||X||)
Weight Matrix (W)
Dense Matrix: Original weights. The top two activation channels (50.0, 40.0) represent massive outliers.
7. 요약 및 비교
| 알고리즘 | 가지치기 유형 | 핵심 메커니즘 | 하드웨어 가속 여부 |
|---|---|---|---|
| Magnitude | 비구조적 (Unstructured) | 0에 가장 가까운 가중치를 단순히 버림. | 없음 (희소 커널 필요). |
| SparseGPT | 비구조적 / N:M | 헤시안(Hessian) 기반의 오차 보상. | 높음 (2:4로 제약 시). |
| Wanda | 비구조적 / N:M | $ | W |
| SliceGPT | 구조적 (Structured) | 직교 투영 후 불필요한 행/열 물리적 삭제. | 모든 하드웨어에서 즉각적. |
파라미터를 지능적으로 제거함으로써, 가중치 희소화 기술은 엔지니어들이 거대하게 과적합된 모델을 제한된 하드웨어에 배포할 수 있게 해줍니다. 그러나 모바일 폰과 같은 엣지 디바이스에 70B 모델을 배포해야 할 때는 가지치기나 양자화만으로는 충분하지 않습니다. 다음 섹션에서는 원본 가중치를 압축하는 방식을 포기하고, 거대 모델을 모방하는 근본적으로 작은 모델을 학습시키는 지식 증류(Knowledge Distillation) 기법을 탐구해 보겠습니다.
Quizzes
Quiz 1: 비구조적 희소성(Unstructured Sparsity)이 표준 GPU에서 이론적인 파라미터 감소만큼의 실제 추론 속도 향상을 가져오지 못하는 이유는 무엇입니까?
표준 GPU의 행렬 곱셈 커널(밀집 커널)은 연속적인 메모리 블록에 접근하도록 고도로 최적화되어 있습니다. 비구조적 희소성으로 인해 무작위 위치에 0이 배치되면, 연산 시 이를 건너뛰기 위해 분기(Branching)와 불규칙한 메모리 접근 패턴이 발생합니다. 이는 스트리밍 멀티프로세서의 파이프라인을 정지(Stall)시켜 성능을 크게 저하시킵니다. 속도 향상을 얻기 위해서는 희소 텐서 코어(Sparse Tensor Cores)와 같은 특수 하드웨어를 활용할 수 있는 2:4 희소성 등의 제약된 패턴이 필요합니다.
Quiz 2: Wanda 알고리즘의 가지치기 지표는 전통적인 크기 기반 가지치기(Magnitude Pruning)와 근본적으로 어떻게 다릅니까?
크기 기반 가지치기는 0에 가까운 작은 가중치는 중요하지 않다고 단순하게 가정합니다. 반면 Wanda는 가중치의 크기가 작더라도, 그 가중치가 극단적으로 큰 활성화 이상치(Activation outlier)와 곱해진다면 네트워크 출력에 결정적인 역할을 할 수 있음을 인지합니다. 따라서 Wanda는 가중치의 크기와 해당 입력 활성화 값의 노름(Norm)을 곱하여 중요도 점수를 산정합니다.
Quiz 3: 2:4 반구조적 희소성(Semi-structured Sparsity) 패턴을 적용할 때, 행렬 전체를 기준으로 평가하지 않고 반드시 4개 단위의 블록 내에서 평가해야 하는 이유는 무엇입니까?
2:4 희소성은 NVIDIA의 희소 텐서 코어를 위해 설계된 엄격한 하드웨어 제약 조건이기 때문입니다. 이 코어들은 메모리에서 연속된 4개의 가중치 블록마다 정확히 2개의 0이 아닌 값과 2비트의 인덱스를 저장하여 행렬을 압축합니다. 만약 행렬 전체를 기준으로 50%의 0을 무작위로 할당한다면, 0의 분포가 고르지 않게 되어 하드웨어 레지스터의 구조적 요구사항을 위반하게 되고 압축 및 가속이 불가능해집니다.
Quiz 4: SliceGPT가 SparseGPT나 Wanda와 비교하여 운영 환경(Operational)에서 가지는 가장 큰 이점은 무엇입니까?
SparseGPT와 Wanda는 희소 행렬(Sparse matrix)을 생성하므로 이를 가속하기 위해서는 특수한 커널이나 하드웨어(예: 희소 텐서 코어)가 필요합니다. 반면 SliceGPT는 가중치 행렬에서 전체 행과 열을 물리적으로 삭제하여 모델의 임베딩 차원 자체를 줄입니다. 그 결과 생성된 행렬은 크기만 작아졌을 뿐 완전히 밀집된(Dense) 형태를 띠므로, 특수 지원 없이도 어떤 표준 하드웨어에서든 즉각적인 엔드투엔드(End-to-end) 속도 향상을 제공합니다.
Quiz 5: 배치 크기 , 시퀀스 길이 를 처리하는 차원의 밀집 선형 레이어(Dense linear layer) 행렬에 2:4 반구조적 희소성(Structured Sparsity)을 적용할 때, 메모리 대역폭(바이트 단위)과 연산 FLOPs의 정확한 이론적 감소량을 정식화(Formalize)하시오.
2:4 반구조적 희소성에서는 연속된 4개의 요소 중 정확히 2개의 0이 아닌 값만 블록별 2비트 인덱스 맵과 함께 저장됩니다. 4개의 float16 가중치( 바이트)를 저장하는 대신, 2개의 float16 가중치( 바이트)와 인덱스 매핑 메타데이터()만 저장합니다. 이는 이론적으로 파라미터 가중치의 감소와 약 의 메모리 풋프린트 절약( 바이트당 바이트 절약)을 가져옵니다. 연산 측면에서는 희소 텐서 코어가 0 연산을 물리적으로 생략하므로, GEMM 연산 FLOPs가 에서 으로 정확히 감소하게 됩니다.
References
- Frantar, E., & Alistarh, D. (2023). SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot. arXiv:2301.00774.
- Sun, M., Liu, Z., Bair, A., & Kolter, J. Z. (2023). A Simple and Effective Pruning Approach for Large Language Models. arXiv:2306.11695.
- Ashkboos, S., Croci, M. L., Nascimento, M. G., Hoefler, T., & Hensman, J. (2024). SliceGPT: Compress Large Language Models by Deleting Rows and Columns. arXiv:2401.15024.