6.5 Synthetic Data for Pre-training
이전 절에서 수조 개의 파라미터를 가진 모델을 연산하기 위한 물리적 인프라를 살펴보고, 7장에서 구축할 분산 시스템을 예고했다면, 이제 사전 학습(Pre-training)의 마지막이자 가장 본질적인 요소인 ‘데이터’ 그 자체를 다루어야 합니다.
2024년경, Epoch AI를 비롯한 여러 연구 기관은 Data Wall (데이터 장벽) 이 임박했음을 경고했습니다. 인터넷은 방대하지만, 고품질의 인간 생성 텍스트의 양은 유한합니다. Common Crawl, GitHub, 그리고 디지털화된 서적들을 모두 합쳐도 고품질 토큰은 대략 10조에서 15조 개 수준에 머뭅니다. 그러나 Foundation Model 의 스케일링 법칙(Scaling Laws)에 따르면, 파라미터 수가 증가함에 따라 학습 토큰 수 역시 비례하여 증가해야 합니다.
인간이 생성한 데이터가 고갈된다면, 다음 세대의 모델은 어떻게 학습시켜야 할까요? 이에 대한 공학적 합의는 재귀적인 해결책으로 수렴했습니다. 기존의 Foundation Model 을 사용하여 다음 세대의 Foundation Model 을 학습시킬 합성 데이터(Synthetic Data)를 생성하는 것입니다.
하지만 이 재귀적 접근법은 수학적으로 매우 위험한 함정을 내포하고 있습니다.
1. 재귀의 저주: Model Collapse (모델 붕괴)
2024년, Shumailov 등은 Nature 지에 Model Collapse [1] 라는 현상을 상세히 분석한 기념비적인 논문을 발표했습니다. 이는 충분한 양의 신규 인간 데이터 주입 없이, 이전 세대의 모델이 생성한 합성 데이터로 다음 세대 모델을 반복적으로 학습시킬 때 발생하는 비가역적인 성능 저하 현상입니다.
붕괴의 수학적 원리
언어 모델 가 특정 데이터셋으로 학습될 때, 모델은 데이터를 완벽하게 암기하는 것이 아니라 기저의 확률 분포를 근사(Approximate)합니다. 통계적 모델의 정의상, 이들은 최빈값(Mode, 가장 흔한 패턴)을 선호하고 꼬리(Tails, 희귀하거나 미묘한 아웃라이어 데이터)에는 더 낮은 확률 질량을 할당합니다.
1세대 모델이 합성 데이터를 생성하면, 이 데이터는 최빈값을 과대대표(Over-represent)하고 꼬리를 과소대표하게 됩니다. 2세대 모델이 이 합성 데이터로 학습될 때, 모델은 더욱 좁아진 분포를 학습하게 됩니다. 수학적으로 이는 데이터 분포의 분산 이 단조 감소하는 마르코프 연쇄(Markov chain)를 형성합니다.
세대가 지나면 분포는 디랙 델타 함수 로 붕괴합니다. 모델은 모든 다양성을 잃고, 복잡한 개념(예: 중세 건축)을 잊어버리며, 터무니없는 고정점(예: “blue-tailed jackrabbits”라는 문구를 끝없이 반복하는 것)으로 수렴합니다 [1].
Interactive: Model Collapse 시각화
아래 슬라이더를 사용하여 다양한 인간 데이터를 나타내는 초기 데이터 분포가 번의 합성 데이터 학습 세대를 거치며 어떻게 열화되는지 관찰해 보십시오. 꼬리 부분이 사라지고 모델이 좁게 이동한 평균값에 대해 과도하게 확신을 가지게 되는 과정을 확인할 수 있습니다.
Model Collapse Simulation
이러한 Model Collapse 를 방지하기 위해, 엔지니어들은 단순히 모델에게 “텍스트 100억 토큰을 작성해 줘”라고 프롬프트를 주고 이를 사전 학습 코퍼스에 추가할 수 없습니다. 합성 데이터는 엄격하게 엔지니어링되고, 필터링되며, 정답(Ground truth)에 단단히 고정되어야 합니다.
2. 양보다 질: “Textbooks” 패러다임
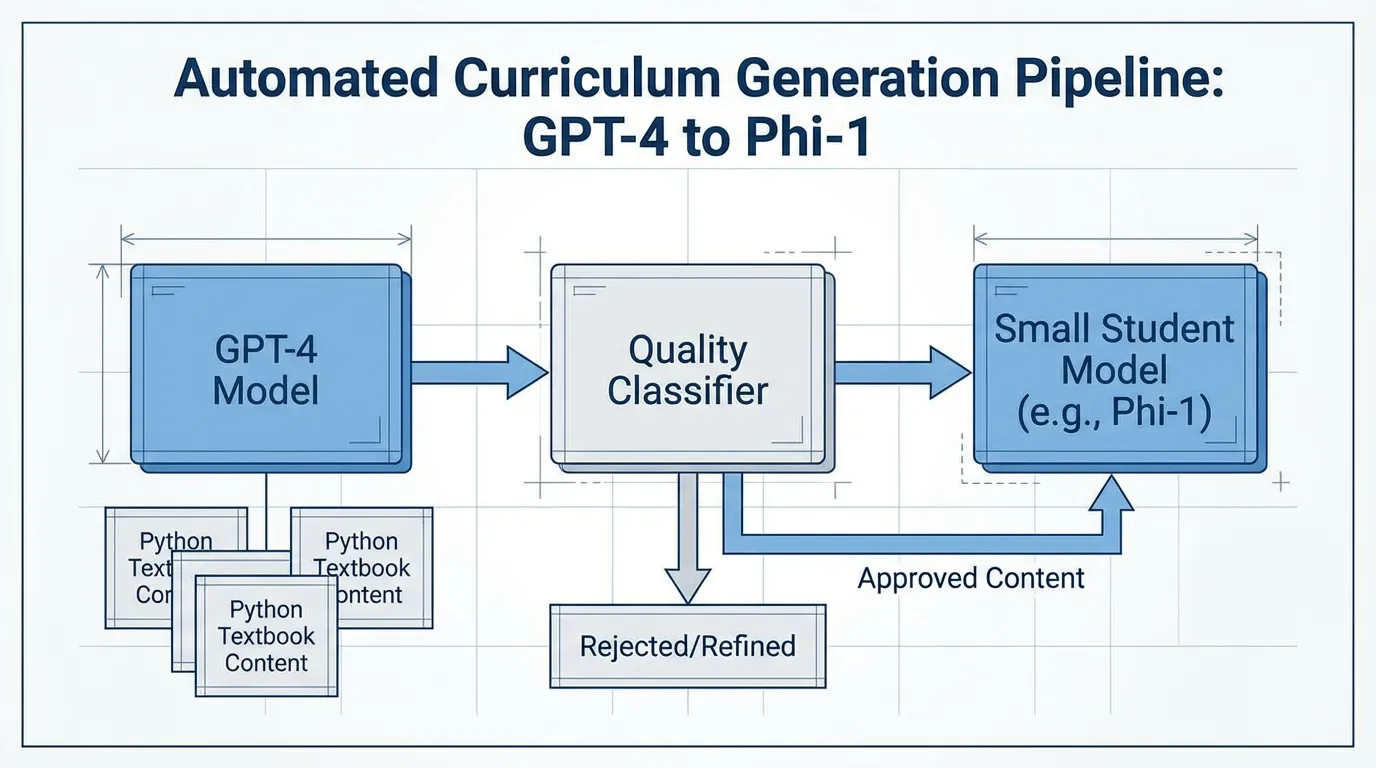
합성 사전 학습 데이터 분야의 첫 번째 주요 돌파구는 Microsoft Research의 Textbooks Are All You Need (2023) [2] 에서 나왔습니다.
이전까지의 표준 관행은 방대하고 노이즈가 많은 웹 데이터를 크롤링하는 것이었습니다. Microsoft는 Phi-1 모델(1.3B 파라미터)을 통해 정반대의 접근법을 취했습니다. 가공되지 않은 웹 스크래핑 데이터에 의존하는 대신, 그들은 GPT-3.5를 사용하여 교육적으로 설계된 고도로 구조화된 “교과서” 및 연습 문제 10억 토큰을 생성했습니다.
생성 프롬프트에 무작위성(어휘, 주제, 대상 독자 제한 등)을 주입하여 데이터의 다양성을 확보했습니다. 당대 모델들의 데이터 볼륨의 1%도 안 되는 양으로 학습되었음에도 불구하고, Phi-1은 코딩 벤치마크에서 SOTA(State-of-the-Art) 성능을 달성했습니다. 이는 매우 중요한 공학적 원칙을 증명했습니다. 소량의 엔트로피가 높고 완벽하게 구조화된 합성 데이터는, 방대하지만 노이즈가 많은 웹 데이터보다 기하급수적으로 더 높은 가치를 지닙니다.
 Source: Generated by Gemini
Source: Generated by Gemini
3. SOTA 모델들의 합성 데이터 스케일링
2025년과 2026년에 이르러, 합성 데이터는 실험적인 기법에서 최첨단 프런티어 모델 학습의 중추로 자리 잡았습니다.
Meta의 Llama 3 & 4 파이프라인
Meta는 Llama 시리즈를 위해 크게 두 가지 방식으로 합성 데이터를 활용했습니다 [3]:
- 데이터 필터링 (Pre-training): Llama 2는 Llama 3를 위한 원시 웹 코퍼스를 라벨링하고 필터링하는 거대한 분류기(Classifier)로 사용되었습니다. 모델이 웹 페이지의 품질과 도메인(과학, 법률, 정치 등)을 평가하여 균형 잡힌 고품질 데이터 믹스를 보장했습니다.
- 오프라인 증류 (Offline Distillation, Post-training): 405B 파라미터의 거대한 Llama 3 모델을 사용하여 수백만 개의 고품질 응답을 생성했습니다. 이 합성 응답들은 8B 및 70B 모델의 사후 학습(Post-training) 단계에서 인간이 작성한 답변을 완전히 대체했습니다.
DeepSeek의 전문가 증류 (Specialist Distillation)
DeepSeek-V3와 R1은 추론(Reasoning) 능력을 부트스트랩하기 위해 합성 데이터를 적극적으로 활용했습니다 [4]. DeepSeek은 Specialist Distillation 이라는 프로세스를 엔지니어링했습니다. 단일 범용 모델을 사용하여 데이터를 생성하는 대신, V3 베이스 모델을 고도로 특화된 전문가(예: 에이전트 코딩 전문가, 수학적 논리 전문가)로 미세 조정(Fine-tuning)했습니다. 이 전문가들은 수백만 개의 CoT(Chain-of-Thought) 궤적을 생성했습니다.
수학과 코드는 자동 검증 가능(Auto-verifiable) 하기 때문에 (파이썬 스크립트는 실행되거나 에러를 뱉고, 수학 방정식은 참이거나 거짓입니다), DeepSeek은 무한한 합성 데이터를 생성하고, 이를 실행 환경에 통과시켜 정확성을 검증한 뒤, 성공한 궤적만을 유지할 수 있었습니다. 이 방식은 주관적인 평가로 인해 발생하는 Model Collapse 의 위험을 완전히 우회합니다.
4. Rejection Sampling 파이프라인 엔지니어링
규모에 맞게 고품질 합성 데이터를 생성하기 위한 표준 방법론은 Rejection Sampling (기각 표본추출) 입니다. 생성기(Generator) 모델이 주어진 프롬프트에 대해 여러 개의 후보 응답을 생성합니다. 이후 보상 모델(Reward Model)이나 결정론적 검증기(예: 컴파일러)가 후보들을 평가하고, 가장 높은 점수를 받은 응답만이 학습 코퍼스에 추가됩니다.
아래는 Hugging Face transformers 라이브러리를 사용한 Rejection Sampling 파이프라인의 PyTorch 구현 예시입니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoModelForSequenceClassification
from typing import List, Dict
@torch.no_grad()
def rejection_sampling_pipeline(
prompts: List[str],
generator: AutoModelForCausalLM,
gen_tokenizer: AutoTokenizer,
reward_model: AutoModelForSequenceClassification,
reward_tokenizer: AutoTokenizer,
num_candidates: int = 8,
threshold: float = 0.8
) -> List[Dict[str, str]]:
"""
Rejection Sampling을 사용하여 합성 데이터를 생성합니다.
보상 임계값(Threshold)을 통과한 프롬프트-응답 쌍만을 반환합니다.
"""
device = generator.device
synthetic_dataset = []
for prompt in prompts:
# 1. N개의 후보 응답 생성
inputs = gen_tokenizer([prompt] * num_candidates, return_tensors="pt", padding=True).to(device)
# 합성 후보군 간의 다양성을 유도하기 위해 높은 Temperature 설정
outputs = generator.generate(
**inputs,
max_new_tokens=256,
temperature=0.9,
do_sample=True,
pad_token_id=gen_tokenizer.eos_token_id
)
candidates = gen_tokenizer.batch_decode(outputs, skip_special_tokens=True)
# 생성된 응답 부분만 추출 (프롬프트 텍스트 제거)
responses = [cand[len(prompt):].strip() for cand in candidates]
# 2. Reward Model을 사용하여 후보군 평가
# 포맷: "User: {prompt} \n Assistant: {response}"
eval_texts = [f"User: {prompt} \n Assistant: {resp}" for resp in responses]
reward_inputs = reward_tokenizer(eval_texts, return_tensors="pt", padding=True, truncation=True).to(device)
# Sequence Classification 헤드에서 스칼라(Scalar) 보상 값을 출력한다고 가정
rewards = reward_model(**reward_inputs).logits.squeeze(-1)
# 3. 가장 점수가 높은 후보 선택
best_idx = torch.argmax(rewards).item()
best_reward = rewards[best_idx].item()
# 4. 품질 보장을 위해 임계값(Threshold) 필터링 적용
if best_reward >= threshold:
synthetic_dataset.append({
"prompt": prompt,
"response": responses[best_idx],
"reward_score": best_reward
})
return synthetic_dataset
# 활용 예시 (모델이 로드되어 있다고 가정):
# dataset = rejection_sampling_pipeline(
# prompts=["Transformers에서 Pre-LN과 Post-LN의 차이점을 설명해 줘."],
# generator=llama_3_70b,
# gen_tokenizer=llama_tokenizer,
# reward_model=nemotron_reward_model,
# reward_tokenizer=reward_tokenizer
# )여기서 주목해야 할 공학적 트레이드오프가 있습니다. 8개의 후보를 생성하고 보상 모델을 실행하는 것은 표준 생성 방식에 비해 약 9배의 추론 연산량(Inference compute)을 요구합니다. 이것이 바로 프런티어 모델들이 실제 사전 학습(Pre-training loop)을 시작하기도 전에, 총 연산 예산의 막대한 비율을 데이터 준비 과정에 쏟아붓는 이유입니다.
Summary
Chapter 6을 통해 우리는 Foundation Model 을 사전 학습시키기 위해 필요한 전체 엔지니어링 스택을 횡단했습니다. 바이트 수준의 토크나이징(6.2)부터 시작하여, 대규모 스케일에서의 그래디언트 안정화 수학(6.3), 그리고 10만 개의 GPU 클러스터와 MEMS 광학 스위치라는 물리적 현실(6.4)까지 살펴보았습니다. 마지막으로 본 절에서는 정교하게 엔지니어링된 합성 파이프라인을 통해 “Data Wall”을 극복하고, 엄격한 Rejection Sampling과 자동 검증 환경을 활용하여 Model Collapse 의 수학적 함정을 피하는 방법을 다루었습니다.
이제 정제된 데이터가 준비되었고, 네트워크는 안정화되었으며, 거대한 물리적 인프라가 가동될 준비를 마쳤습니다. 우리는 마침내 loss.backward() 를 실행할 준비가 되었습니다. 하지만 80GB의 메모리밖에 없는 GPU들에 1조 개의 파라미터를 가진 모델을 물리적으로 어떻게 욱여넣을 수 있을까요?
이어지는 Chapter 7: Training Optimization & Systems 에서는 3D 병렬화(3D Parallelism), ZeRO 최적화, 그리고 Flash Attention 등 분산 학습의 소프트웨어 엔지니어링을 깊이 있게 파헤칠 것입니다.
Quizzes
Quiz 1: 기각 샘플링(Rejection Sampling) 파이프라인에서 각 프롬프트에 대해 개의 후보 시퀀스를 병렬로 생성합니다. 각 후보 시퀀스가 결정론적 검증기(verifier)를 통과할 독립적인 확률은 입니다. 단일 후보 생성 비용이 , 보상 평가 비용이 일 때 최소 하나 이상의 유효한 시퀀스를 얻기 위한 기대 연산 비용(FLOPs)을 유도하세요. 나아가 일 때 단일 병렬 패스에서 성공할 확률이 이상이 되도록 보장하는 최소 값을 계산하세요.
크기 의 병렬 패스에서 최소 하나 이상의 후보가 통과할 확률은 입니다. 성공할 때까지의 패스 수 는 기하 분포를 따르며 기대값 을 가집니다. 각 패스의 연산 비용은 FLOPs이므로 기대 총 연산 비용은 가 됩니다. 단일 패스에서 성공 확률을 위한 최소 를 구하면: 입니다. 따라서 최소 정수 는 19입니다.
Quiz 2: Microsoft의 “Textbooks Are All You Need” (Phi-1) 방법론은 2023년 당시 지배적이었던 스케일링 법칙(Scaling Laws)에 어떻게 반기를 들었는가?
당시 지배적인 스케일링 법칙은 모델의 성능이 파라미터 수와 원시 데이터의 양(수조 개의 토큰)에 비례하여 예측 가능하게 상승한다고 보았습니다. 하지만 Phi-1은 LLM을 사용해 완벽하게 구조화되고 엔트로피가 높은 ‘교과서’ 데이터를 생성함으로써 데이터의 질을 극단적으로 높였습니다. 그 결과, 단 70억(7B) 토큰으로 학습된 1.3B 파라미터 모델이 방대하고 노이즈 많은 웹 데이터로 학습된 10배 크기의 모델들과 필적하거나 능가하는 성능을 증명했습니다.
Quiz 3: 창의적 글쓰기나 역사 도메인에 비해 수학이나 코딩 도메인에서 사전 학습용 합성 데이터를 사용하는 것이 훨씬 쉽고 안전한 이유는 무엇인가?
수학과 코드는 ‘자동 검증 가능(Auto-verifiable)‘한 환경이기 때문입니다. 생성된 파이썬 스크립트는 컴파일러나 인터프리터를 통해 정상 동작 여부를 명확히 증명할 수 있고, 수학 증명은 규칙 기반 솔버로 검증할 수 있습니다. 이는 Rejection Sampling 과정에서 결정론적인 정답(Ground-truth) 보상 신호를 제공하여 모델이 환각(Hallucination)이나 붕괴에 빠지는 것을 막아줍니다. 반면 창의적 글쓰기는 주관적인 인간의 선호도나 LLM-as-a-Judge에 의존해야 하므로 재귀적 편향에 취약합니다.
Quiz 4: Meta의 Llama 3나 DeepSeek-V3의 문맥에서 “오프라인 증류(Offline Distillation)” 또는 “전문가 증류(Specialist Distillation)“란 무엇을 의미하는가?
거대하고 뛰어난 성능을 가진 프런티어 모델(예: Llama 3 405B)이나 고도로 미세 조정된 전문가 모델을 사용하여 주어진 프롬프트에 대한 수백만 개의 고품질 응답을 생성하는 과정입니다. 이렇게 생성된 합성 응답들은 더 작고 효율적인 모델(예: Llama 3 8B)을 위한 정답 학습 데이터로 사용되며, 인간 어노테이터(Annotator) 없이도 큰 모델의 추론 능력을 작은 모델로 효과적으로 전이(Distill)시키는 역할을 합니다.
References
- Shumailov, I., et al. (2024). “AI models collapse when trained on recursively generated data.” Nature. Link.
- Gunasekar, S., et al. (2023). Textbooks Are All You Need. arXiv:2306.11644.
- Meta. (2024). The Llama 3 Herd of Models. arXiv:2407.21783.
- DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv:2412.19437.