14.2 벡터 인덱싱 및 DB 솔루션
문서가 고차원 벡터 임베딩으로 변환되면 다음 과제는 이를 효율적으로 검색하는 것입니다. 수백만 또는 수십억 개의 벡터가 있는 프로덕션 RAG 시스템에서 쿼리 벡터를 저장된 모든 벡터와 비교하는 것(Exact Search)은 실시간 응답을 위해 컴퓨팅적으로 불가능합니다.
밀리초 미만의 지연 시간을 달성하기 위해 우리는 Approximate Nearest Neighbor (ANN) 알고리즘을 사용합니다. 이 장에서는 업계 표준인 HNSW 알고리즘과 Google 의 최첨단 ScaNN 및 기타 접근 방식을 비교하고, 상용 Vector DB 환경을 살펴봅니다.
1. 검색 병목 현상: Exact vs. ANN
Exact search (K-Nearest Neighbors 또는 KNN)는 쿼리 벡터 와 데이터베이스의 모든 벡터 사이의 거리를 계산합니다.
- 시간 복잡도: , 여기서 은 문서 수이고 는 차원입니다.
- 10억 개의 768차원 벡터의 경우 한 번의 검색에 7,680억 번의 연산이 필요합니다.
ANN 알고리즘 은 대규모의 속도와 확장성을 얻기 위해 약간의 정확도(재현율, recall)를 희생하여 검색 복잡도를 또는 일부 경우에는 로 줄입니다.
2. HNSW: 벡터 인덱스의 왕
HNSW (Hierarchical Navigable Small World) [1] 는 가장 널리 사용되는 그래프 기반 ANN 알고리즘입니다. Pinecone, Milvus, Qdrant 및 FAISS 의 백엔드를 구동합니다.
HNSW 는 Skip-Lists 에서 영감을 받은 다층 그래프 구조를 구축합니다.
- Layer 0 (최하단): 모든 벡터를 조밀한 그래프로 포함합니다.
- 상위 레이어: 더 큰 거리를 연결하는 링크를 가진 기하급수적으로 적은 노드를 포함합니다.
검색은 최상위 레이어에서 시작하여 크게 도약한 다음, 더 조밀한 레이어로 떨어지면서 결과를 미세 조정합니다. 이를 통해 복잡도가 으로 줄어듭니다.
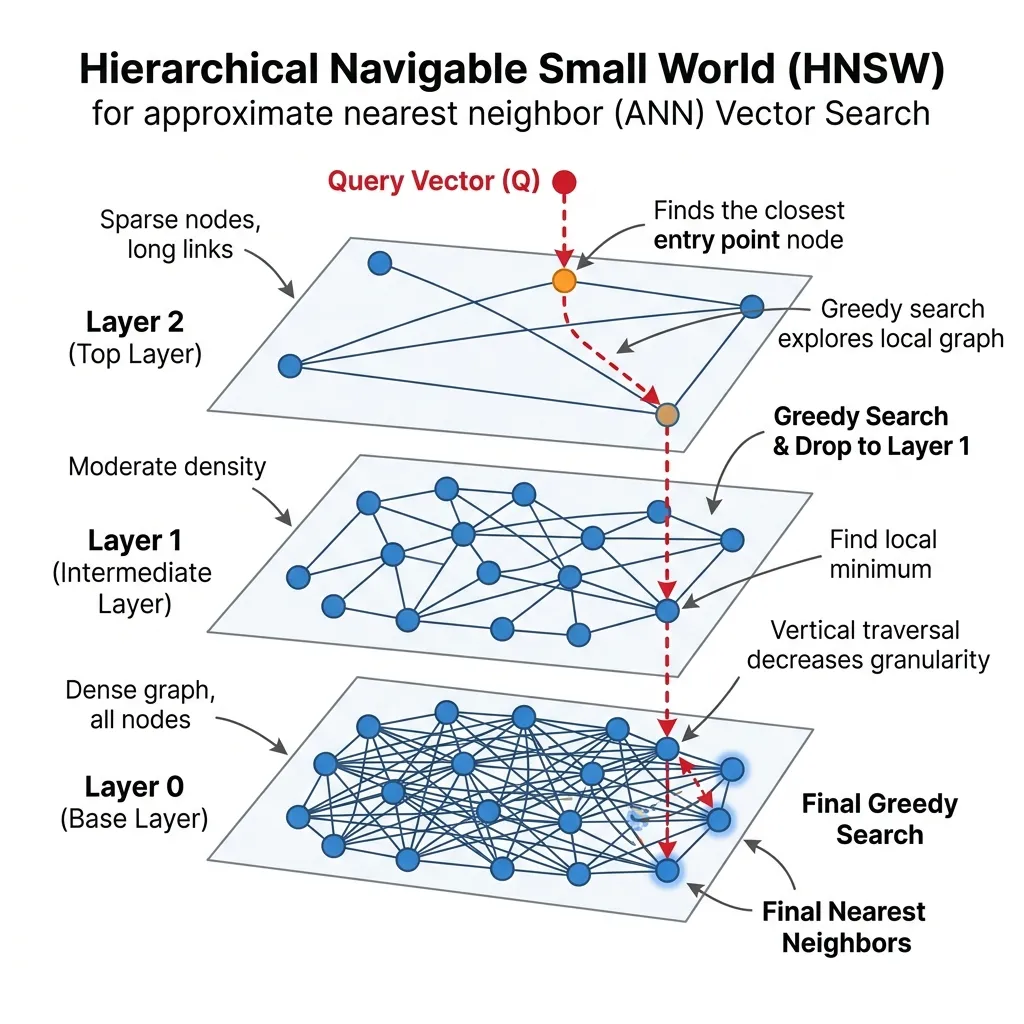
HNSW 라우팅 시각화
쿼리(빨간색)가 드문드문한 최상위 레이어로 들어가 가장 가까운 이웃을 찾기 위해 아래로 떨어지는 모습을 관찰해 보세요.
HNSW Routing Simulator
Click on an empty space on the graph to create a query (red dot). The search process is visualized as it drops from the upper layer (L2) to the lower layer (L0).
3. Google 의 ScaNN: MIPS 에 최적화
HNSW 도 훌륭하지만, Google 은 임베딩에서 내적(dot product) 또는 코사인 유사도로 검색할 때 사용되는 연산인 Maximum Inner Product Search (MIPS) 를 위해 특별히 ScaNN (Scalable Nearest Neighbors) [2] 을 개발했습니다.
혁신: Anisotropic Vector Quantization (비등방성 벡터 양자화)
전통적인 양자화(예: Product Quantization)는 벡터 자체의 복원 오차를 최소화하려고 합니다(양자화된 벡터를 원본과 최대한 가깝게 만듦).
ScaNN 은 Anisotropic Quantization 을 도입합니다. 내적 검색의 경우, 쿼리에 대한 방향 만 유지된다면 양자화된 벡터의 길이가 약간 달라도 상관없다는 점을 깨달았습니다. ScaNN 은 내적을 결정하는 평행 성분을 최대한 정확하게 유지하기 위해 벡터에 수직인 방향으로 의도적으로 오차를 도입합니다.
이를 통해 ScaNN 은 최첨단 속도와 재현율 트레이드오프를 달성할 수 있으며, MIPS 작업에 대한 순수 CPU 환경에서 종종 HNSW 를 능가합니다.
4. 알고리즘 비교표
초보자와 전문가 모두를 위한 주요 벡터 인덱싱 알고리즘의 비교는 다음과 같습니다.
| 알고리즘 | 유형 | 최적 용도 | 장점 | 단점 |
|---|---|---|---|---|
| HNSW | Graph-based | 범용, 높은 재현율 | - 최첨단 재현율/속도 밸런스 - 동적 추가/삭제 지원 | - 높은 메모리 소모 - 느린 인덱스 빌드 시간 |
| ScaNN | Quantization + Search | MIPS (내적), CPU 효율성 | - 극도로 빠른 검색 속도 - 낮은 메모리 사용량 | - 복잡한 구현 - 동적 업데이트가 더 어려움 |
| IVF (Inverted File) | Clustering | 대규모, 저메모리 | - 빠른 빌드 시간 - 낮은 메모리 | - HNSW 보다 낮은 재현율 - 클러스터 불균형에 취약 |
| Flat (Exact) | Brute Force | 소규모 데이터셋 (<10k) | - 100% 정확도 (재현율) - 인덱스 빌드 시간 없음 | - 선형적으로 확장 - 대규모 데이터에 너무 느림 |
5. 벡터 그 이상의 것: 메타데이터 및 접근 제어
실제 엔터프라이즈 RAG 시스템에서는 벡터 유사도만으로 검색하는 경우가 드뭅니다. 문서에는 생성 날짜, 작성자, 카테고리, 그리고 가장 중요한 접근 권한 과 같은 속성이 있습니다.
메타데이터의 필요성
전사적 RAG 시스템을 상상해 보세요. 임원 급여에 대한 HR 문서는 “시니어 직급의 급여 범위는 얼마인가요?”라는 쿼리에 대해 의미적으로 가장 가까운 일치 항목이더라도 모든 직원에게 표시되어서는 안 됩니다.
이를 처리하기 위해 우리는 벡터에 메타데이터 를 첨부합니다. 메타데이터는 각 벡터와 관련된 구조화된 데이터(JSON 형태)입니다. 예를 들면 다음과 같습니다.
{
"doc_id": "HR-2026-001",
"department": "HR",
"access_roles": ["admin", "hr_manager"],
"created_at": "2026-04-01"
}메타데이터 필터링 및 ANN
도전 과제는 메타데이터 필터링을 근사 근접 이웃(ANN) 검색과 결합할 때 발생합니다. 여기에는 두 가지 주요 접근 방식이 있습니다.
A. 사후 필터링 (Post-Filtering / Naive)
- ANN 검색을 수행하여 가장 유사한 벡터 개(예: )를 찾습니다.
- 메타데이터를 기반으로 결과를 필터링합니다(예:
access_roles에user_role이 포함된 문서만 유지).
- 문제점: 상위 100개 결과가 모두 제한된 HR 문서이고 사용자가 일반 직원인 경우, 사후 필터링은 0개 의 결과를 반환합니다. 리스트 아래쪽에 관련 있는 공개 문서가 있더라도 마찬가지입니다. 이를 “빈 결과 문제(empty result problem)“라고 합니다.
B. 사전 필터링 (Pre-Filtering / Harder but Better)
- 데이터베이스를 먼저 필터링하여 사용자가 볼 수 있는 권한이 있는 벡터만 남깁니다.
- 필터링된 서브셋에서 ANN 검색을 수행합니다.
- 문제점: 사전 필터링은 HNSW와 같은 알고리즘의 그래프 구조를 깨뜨릴 수 있습니다. 검색하기 전에 그래프에서 노드를 제거하면 경로가 끊어져 재현율이 떨어지거나 검색에 실패할 수 있습니다.
현대적인 솔루션: 필터링된 HNSW 및 비트맵
현대적인 벡터 데이터베이스(예: Pinecone, Milvus, Qdrant)는 필터링을 ANN 검색 프로세스에 직접 통합하여 이 문제를 해결합니다.
- 메타데이터에 대한 비트맵 또는 역인덱스(inverted index)를 유지합니다.
- HNSW 그래프 탐색 중에 각 단계에서 메타데이터 조건을 확인하여, 탐색 경로를 깨뜨리지 않고 필터와 일치하지 않는 노드를 건너뜁니다.
개발자를 위한 실무 가이드
RAG에서 역할 기반 접근 제어(RBAC)를 구현할 때:
- 권한 임베딩: 벡터 메타데이터에 항상 액세스 제어 목록(ACL)을 포함하세요.
- 사전 필터링 선호: 선택한 Vector DB가 단순한 사후 필터링이 아닌, ANN과 통합된 효율적인 사전 필터링을 지원하는지 확인하세요.
- 메타데이터 크기 유지: 메타데이터 페이로드가 크면 메모리 소비가 늘어나고 검색 속도가 느려질 수 있습니다. 필터링에 필요한 것만 저장하세요.
6. 상용 Vector DB 및 솔루션
알고리즘에서 인프라로 전환할 때 개발자는 벡터 검색을 관리하기 위해 몇 가지 선택을 할 수 있습니다.
A. 전문 Vector Databases
- Pinecone: 완전 관리형 클라우드 네이티브 벡터 DB 입니다. 인프라 관리 없이 신속하게 시작하기에 좋습니다.
- Milvus / Qdrant: 수십억 규모의 검색에 최적화된 오픈 소스 고성능 벡터 데이터베이스로, 자체 호스팅하거나 관리형 서비스로 사용할 수 있습니다.
B. 라이브러리 기반 솔루션
- FAISS (Facebook AI Similarity Search): Meta 에서 개발한 전설적인 라이브러리입니다. 데이터베이스가 아니라 Python 래퍼가 있는 C++ 로 작성된 핵심 알고리즘(HNSW 및 IVF 포함) 세트입니다. 다른 많은 시스템의 기초가 됩니다.
C. 클라우드 공급자 솔루션
- Google Cloud Vertex AI Vector Search: 이전에는 Matching Engine 으로 알려졌으며, 내부적으로 ScaNN 과 유사한 기술을 사용합니다. 극단적인 확장성과 낮은 지연 시간을 제공하지만 소규모 프로젝트의 경우 설정이 복잡할 수 있습니다.
- AWS OpenSearch / Azure AI Search: 벡터 검색 기능(일반적으로 HNSW 플러그인을 통해)을 추가한 기존 검색 엔진입니다. 이미 이러한 에코시스템을 사용하고 있고 하이브리드 검색이 필요한 경우에 좋습니다.
Quizzes
Quiz 1: HNSW 가 ScaNN 이나 IVF 와 같은 양자화 기반 방법에 비해 더 많은 메모리를 소모하는 이유는 무엇인가요?
HNSW 는 벡터 자체 외에도 모든 레이어에 대해 메모리에 그래프 구조(노드 간의 포인터/링크)를 저장해야 합니다. 양자화 방법은 벡터를 압축하고 복잡한 그래프 에지를 저장할 필요가 없습니다.
Quiz 2: 프로덕션 RAG 시스템에서 HNSW 대신 ScaNN 을 선택하는 시나리오는 무엇인가요?
주요 제약 조건이 CPU 에서의 검색 속도이고 유사도 측정 기준으로 내적(dot product)을 사용하는 경우 ScaNN 을 선택할 것입니다. ScaNN 의 비등방성 양자화는 이에 특별히 최적화되어 있어 HNSW 에 비해 표준 CPU 하드웨어에서 더 높은 처리량을 제공할 수 있습니다.
Quiz 3: 곱 양자화(Product Quantization, PQ)를 사용하여 차원 인 벡터 개를 저장하는 데 필요한 메모리 풋프린트(바이트 단위)를 계산하시오. (단, 서브 벡터 개수 , 부분 공간당 센트로이드 개수 으로 가정)
PQ는 768차원 벡터를 개의 서브 벡터로 분해하며, 각 서브 벡터의 차원은 입니다. 각 부분 공간은 개의 센트로이드를 가지므로, 서브 벡터당 식별자(Index)를 저장하는 데 ()가 필요합니다. 따라서 양자화된 각 벡터는 정확히 96바이트를 차지합니다. 벡터 1,000,000개의 경우 약 96MB의 스토리지가 소요됩니다. 추가적으로, 센트로이드 자체의 용량은 입니다. 원본 FP32 풋프린트가 약 3.07GB인 것과 비교했을 때, PQ는 비약적인 메모리 절감률을 제공합니다.
References
- Malkov, Y. A., & Yashunin, D. A. (2016). Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. arXiv:1603.09320.
- Guo, R., et al. (2020). Accelerating Large-Scale Random-Walk Based Search via Anisotropic Vector Quantization. ICML. arXiv:1908.10396.