3.5 복잡도 분석
트랜스포머가 왜 RNN과 CNN을 제치고 현대 AI의 초석이 되었는지 이해하려면 그들의 계산 복잡도를 분석해야 합니다. 이 분석은 계산, 병렬화, 그리고 장기 종속성 모델링 능력 사이의 트레이드오프를 보여줍니다.
동기: 규모의 비용
책 한 권 전체나 긴 비디오를 처리하는 방향으로 나아가면서 시퀀스의 길이()가 늘어납니다.
- 계산 복잡도: 시퀀스를 처리하는 데 얼마나 많은 연산이 필요합니까?
- 병렬화: 모든 것을 한 번에 계산할 수 있습니까, 아니면 단계별 결과를 기다려야 합니까?
- 경로 길이: 멀리 떨어진 두 단어 사이를 신호가 이동하는 데 몇 단계가 필요합니까?
이러한 요소를 분석하면 왜 트랜스포머가 GPU에서 더 잘 확장되지만 극도로 긴 컨텍스트 윈도우에서는 어려움을 겪는지 이해할 수 있습니다.
비유: 도서관에서 책 찾기
도서관에서 특정 참고 자료를 찾고 있다고 상상해 보세요.
- RNN 방식은 통로를 걸어가는 것과 같습니다. 첫 번째 책장부터 시작하여 책을 하나씩 확인합니다. 시퀀스가 길면 오랜 시간이 걸립니다. 1~9번 책장을 지나기 전에는 10번 책장을 보기 시작할 수 없습니다. 이는 순차 연산입니다.
- 트랜스포머 방식은 순간이동 장치를 갖는 것과 같습니다. 도서관의 모든 책과 당신의 검색어를 동시에 비교할 수 있습니다. 하지만 이렇게 하려면 모든 책을 다른 모든 책과 비교하는 거대한 색인을 만들어야 합니다. 이는 처음에 많은 작업( 연산)이 필요하지만, 일단 완료되면 1단계 만에 즉시 연결을 찾을 수 있습니다.
복잡도 비교
“Attention Is All You Need” [1]의 저자들은 셀프 어텐션을 순환 및 합성곱 레이어와 비교하여 제공했습니다.
| 레이어 유형 | 레이어당 복잡도 | 순차 연산 | 최대 경로 길이 |
|---|---|---|---|
| 셀프 어텐션 | |||
| 순환 (Recurrent) | |||
| 합성곱 (Convolutional) |
여기서:
- 은 시퀀스 길이입니다.
- 는 표현 차원입니다.
- 는 합성곱의 커널 크기입니다.
트레이드오프 분석
-
레이어당 복잡도:
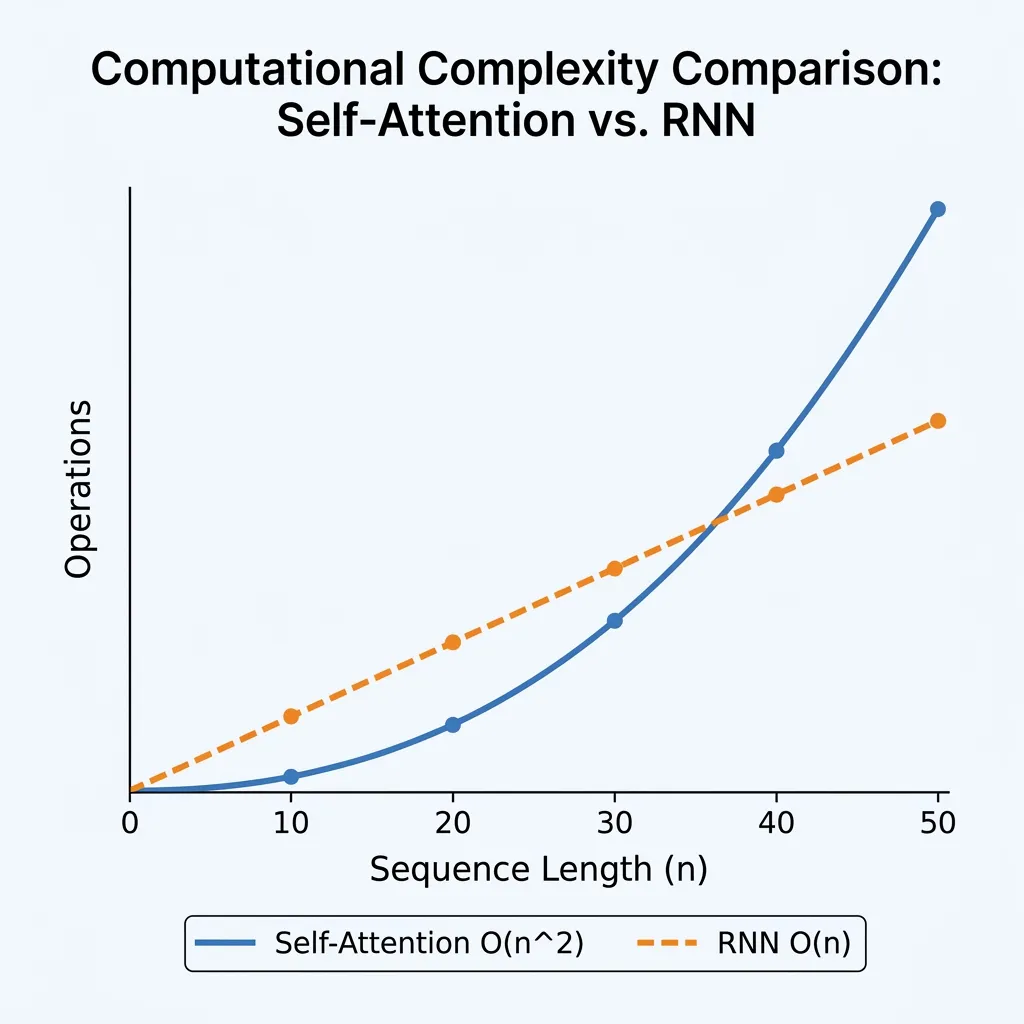
- 셀프 어텐션은 입니다. 시퀀스 길이 에 대해 이차식(quadratic)입니다. 일 때(2017년에는 일반적이었음) 셀프 어텐션은 순환 레이어보다 비용이 적게 들었습니다. 그러나 컨텍스트 윈도우가 커짐에 따라(예: ) 이 지배적인 비용이 됩니다.
- 순환은 입니다. 에 대해 선형이지만 에 대해 이차식입니다.
-
순차 연산:
- 셀프 어텐션은 입니다. 모든 연산을 병렬로 수행할 수 있어 GPU 활용도를 극대화합니다.
- 순환은 입니다. 개의 순차적 단계가 필요하므로 시간에 따른 병렬 처리가 불가능합니다.
-
최대 경로 길이:
- 셀프 어텐션은 입니다. 어떤 두 위치도 한 단계 만에 직접 상호 작용할 수 있습니다.
- 순환은 입니다. 첫 번째 토큰과 마지막 토큰을 연결하려면 신호가 개의 은닉 상태를 통과해야 하므로 기울기 소실이 발생합니다.
- 합성곱은 확장된 합성곱을 사용할 때 으로, RNN보다는 낫지만 트랜스포머보다는 못합니다.
복잡도 유도 과정
이러한 수치들을 진정으로 이해하기 위해 연산에 포함된 행렬 연산으로부터 복잡도를 유도해 봅시다.
1. 셀프 어텐션:
공식을 다시 떠올려 봅시다: . 단순화를 위해 라고 가정합니다.
- 연산: 크기의 행렬 와 크기의 행렬 를 곱합니다. 결과 행렬의 한 원소를 계산하기 위해 두 개의 차원 벡터의 내적(비용 )을 수행합니다. 결과는 행렬이므로 이 작업을 번 수행합니다. 총 비용: .
- Softmax 연산: 행렬의 각 행에 적용됩니다. 비용: .
- 곱하기: 크기의 어텐션 가중치 행렬과 크기의 를 곱합니다. 결과의 한 원소를 계산하기 위해 차원 행과 차원 열의 내적(비용 )을 수행합니다. 결과는 행렬입니다. 총 비용: .
- 이들을 결합하면 가장 지배적인 항은 가 됩니다.
2. 순환 (RNN):
RNN에서 단계 의 은닉 상태는 로 계산됩니다.
- 은닉 상태와 입력 모두 차원이라고 가정합니다.
- 행렬-벡터 곱셈 은 행렬과 벡터를 포함합니다. 이는 연산이 필요합니다.
- 시퀀스의 모든 개 토큰에 대해 이 작업을 순차적으로 반복해야 합니다.
- 총 비용: .
메모리 복잡도 시뮬레이션
셀프 어텐션 행렬에 필요한 메모리가 시퀀스 길이에 따라 어떻게 이차적으로 증가하는지 살펴보겠습니다. 이 PyTorch 기반 시뮬레이션은 어텐션 점수 행렬에 필요한 메모리를 추정합니다.
import torch
def estimate_attention_memory(seq_len, d_model=512, num_heads=8, batch_size=1):
# 어텐션 행렬 크기는 (batch_size, num_heads, seq_len, seq_len) 입니다.
# 각 요소는 float32 (4바이트) 입니다.
element_size = 4
total_elements = batch_size * num_heads * seq_len * seq_len
memory_bytes = total_elements * element_size
memory_mb = memory_bytes / (1024 * 1024)
return memory_mb
lengths = [1000, 5000, 10000, 50000]
print("추정된 어텐션 행렬 메모리:")
for n in lengths:
mem = estimate_attention_memory(n)
print(f"시퀀스 길이: {n:,} -> {mem:.2f} MB")예제: 이차 성장의 시각화
시퀀스 길이를 조절하여 셀프 어텐션의 연산(비교) 수가 으로 어떻게 이차적으로 증가하는지, 그리고 RNN의 연산 수가 어떻게 선형적으로 증가하는지 확인해 보세요.
Quizzes
Quiz 1: 셀프 어텐션이 순환 레이어보다 계산 비용이 적게 드는 경우는 언제입니까?
셀프 어텐션이 표현 차원 보다 시퀀스 길이 이 작을 때() 계산 비용이 더 적게 듭니다. 초기 NLP 작업에서는 문장이 짧았고 임베딩 차원이 상대적으로 컸기 때문에 셀프 어텐션이 매우 효율적이었습니다.
Quiz 2: 극도로 긴 시퀀스(예: 100k 토큰)를 다룰 때 트랜스포머의 주된 병목 현상은 무엇입니까?
병목 현상은 셀프 어텐션 메커니즘의 시간 및 메모리 복잡도입니다. 이 커짐에 따라 어텐션 행렬()의 크기가 이차적으로 커져 막대한 메모리 소비와 계산 요구량으로 이어집니다.
Quiz 3: 왜 RNN은 트랜스포머에 비해 GPU를 효과적으로 활용하지 못합니까?
RNN은 순차적 처리가 필요합니다. 단계 를 계산하려면 단계 의 출력이 필요합니다. 이 종속성은 모델이 모든 토큰을 병렬로 처리하는 것을 방해합니다. 트랜스포머는 순차 연산을 가지므로 모든 토큰을 한 번에 처리할 수 있어 GPU 병렬 처리를 최대한 활용할 수 있습니다.
Quiz 4: 왜 RNN의 순차 연산 복잡도는 이고 셀프 어텐션은 인가요?
RNN은 단계 의 은닉 상태가 단계 의 은닉 상태에 의존하기 때문에 토큰을 하나씩 순차적으로 처리해야 합니다. 이는 길이 의 순차적 종속성을 생성합니다. 반면 셀프 어텐션은 모든 토큰 쌍을 병렬로 비교하므로 시퀀스 길이에 관계없이 일정한 수의 단계 만에 모든 연산을 수행할 수 있습니다.
Quiz 5: 복잡도 비교 표에서 합성곱 레이어의 는 무엇을 나타내나요?
변수 는 합성곱의 커널 크기(또는 필터 폭)를 나타냅니다. 이는 합성곱 레이어가 한 번에 얼마나 많은 인접 토큰을 함께 보는지 결정합니다.
앞으로의 과제: 이차 복잡도를 넘어서
표준 트랜스포머의 복잡도를 분석하면서, 어텐션 메커니즘이 긴 시퀀스로 확장하는 데 있어 주된 병목 현상임을 확인했습니다.
미래를 향한 경쟁: 이 의 벽을 깨기 위한 연구는 현재 AI 학계의 가장 뜨거운 전장 중 하나입니다. 선형 복잡도 를 달성하기 위해 ‘Linear Transformer’, ‘Performer’, ‘Reformer’ 등 수많은 변형(X-formers)이 제안되었습니다. 그리고 최근에는 아예 어텐션을 사용하지 않고도 긴 시퀀스를 효과적으로 처리하는 State Space Model(예: Mamba) 같은 대안 아키텍처가 강력한 경쟁자로 떠오르고 있습니다.
다음 챕터로 넘어가면서 다음 질문들을 생각해 보세요.
- 선형 복잡도 를 달성하기 위해 어텐션 메커니즘을 어떻게 수정할 수 있을까요?
- 무한한 시퀀스를 처리하기 위해 외부 메모리나 압축을 사용할 수 있을까요?
- Gemini나 Claude 같은 현대 모델들은 어떻게 백만 토큰의 컨텍스트를 처리할까요?
이러한 질문들은 다음 챕터에서 효율적인 트랜스포머와 대안 아키텍처를 탐구하는 데 도움이 될 것입니다.
References
- Vaswani, A., et al. (2017). Attention is all you need. Advances in neural information processing systems, 30. arXiv:1706.03762.