2.3 어텐션의 여명 (The Dawn of Attention)
어텐션(Attention)의 도입은 트랜스포머와 현대 파운데이션 모델 시대로 직접 이어지는 결정적인 순간이었습니다. 이는 시퀀스 투 시퀀스(Seq2Seq) 모델의 근본적인 병목 현상을 해결했습니다.
동기: 정보 병목 현상 극복
긴 문서를 번역하는 번역가라고 상상해 보세요.
- 어텐션이 없을 때: 문서를 처음부터 끝까지 다 읽고, 모든 내용을 기억한 다음, 문서를 덮고 기억에만 의존해서 다른 언어로 번역본을 작성해야 합니다. 이것이 초기 Seq2Seq 모델이 하려고 했던 방식입니다.
- 어텐션이 있을 때: 문서를 읽으면서 번역본의 각 단어를 작성할 때마다 원본 텍스트에서 해당 단어와 관련된 특정 부분을 다시 들여다봅니다.
어텐션은 디코더가 관련 있는 입력 단어에 동적으로 “주의를 기울일(pay attention)” 수 있게 함으로써 모델이 긴 문장을 처리할 수 있도록 도왔습니다.
비유: 형광펜
두꺼운 교과서를 읽으며 시험공부를 하고 있다고 상상해 보세요.
- 기존 방식 (RNN 인코더-디코더) 은 전체 챕터를 암기하여 하나의 포스트잇에 요약하려는 것과 같습니다. 그리고 시험 문제를 풀 때는 오직 그 포스트잇만 사용합니다. 만약 챕터가 50페이지 분량이라면, 그 포스트잇은 많은 세부 사항을 놓칠 것입니다.
- 어텐션 방식 은 형광펜 을 들고 챕터를 읽는 것과 같습니다. 시험 중에 특정 질문을 받으면, 책장을 다시 넘겨 질문과 가장 관련이 있는 형광펜 칠해진 부분에 시선을 집중합니다. 모든 것을 포스트잇 하나에 욱여넣을 필요가 없습니다. 책 전체에 접근할 수 있지만, 어디를 봐야 할지 알고 있는 것입니다.
Seq2Seq 병목 현상
어텐션 이전에는 기계 번역과 같은 작업을 위한 표준 접근 방식이 RNN(또는 LSTM)을 사용하는 인코더-디코더 (Encoder-Decoder) 아키텍처였습니다.
- 인코더: 입력 시퀀스를 처리하고 모든 정보를 컨텍스트 벡터 (Context Vector) (또는 상태)라고 불리는 단일 고정 크기 벡터로 압축합니다.
- 디코더: 이 단일 컨텍스트 벡터를 입력으로 받아 출력 시퀀스를 생성합니다.
문제점
50단어 문장을 다른 언어로 번역한다고 상상해 보세요. 인코더는 50단어의 모든 의미, 문법, 뉘앙스를 예를 들어 512개의 숫자로 이루어진 단일 벡터에 쑤셔 넣어야 합니다. 이것이 바로 심각한 병목 현상(Bottleneck) 입니다. 네트워크는 문장 끝에 도달할 때쯤이면 문장 앞부분을 잊어버리게 됩니다.
💡 비하인드 스토리: “입력 문장 뒤집기” 해킹 어텐션(Attention)이 발명되기 전, 연구자들은 이 병목 현상을 해결하기 위해 필사적이었습니다. 2014년, Google의 Ilya Sutskever 연구팀은 놀랍도록 단순한 꼼수(Hack)를 발견했습니다. 바로 인코더에 입력 문장을 거꾸로(역순으로) 넣는 것이었습니다! (예: “A B C” -> “C B A”). 왜 이것이 효과가 있었을까요? 번역된 문장의 첫 부분은 보통 원문의 첫 부분과 강하게 연관되어 있습니다. 입력을 뒤집으면 원문의 첫 단어인 “A”가 인코더에서 가장 마지막에 처리되므로, 디코더가 첫 번역 단어를 생성하기 직전에 생성된 컨텍스트 벡터(Context vector)에 “A”에 대한 정보가 가장 신선하게 남아있게 됩니다. 이 우아하지만 임시방편이었던 해결책은 번역 성능을 엄청나게 향상시켰으며, 동시에 당시 AI 학계가 진정한 “기억(Memory)” 메커니즘—결국 어텐션이 해결해 준—에 얼마나 목말라 있었는지를 보여주는 유명한 일화입니다.
해결책: Bahdanau 어텐션 - 인간처럼 번역하기
2014년, Bahdanau, Cho, Bengio는 *“Neural Machine Translation by Jointly Learning to Align and Translate”*라는 기념비적인 논문을 발표했습니다. 그들은 어텐션(Attention) 개념을 도입했습니다.
개발 비하인드 스토리: 이 아이디어는 인간이 번역하는 방식에서 영감을 받았습니다. 인간 번역가는 긴 문장을 번역할 때 전체 문장을 완벽하게 외운 상태에서 번역을 시작하지 않습니다. 대신, 번역문을 작성해 나가면서 원문의 특정 부분(예: 지금 번역하려는 단어와 관련된 부분)을 계속해서 ‘다시 들여다봅니다’. 연구진은 모델에도 이러한 ‘다시 들여다보는’ 능력을 부여하고자 했습니다.
단일 고정 컨텍스트 벡터에 의존하는 대신, 디코더가 생성의 각 단계에서 인코더의 모든 은닉 상태를 “되돌아볼(look back)” 수 있도록 허용하는 것입니다.
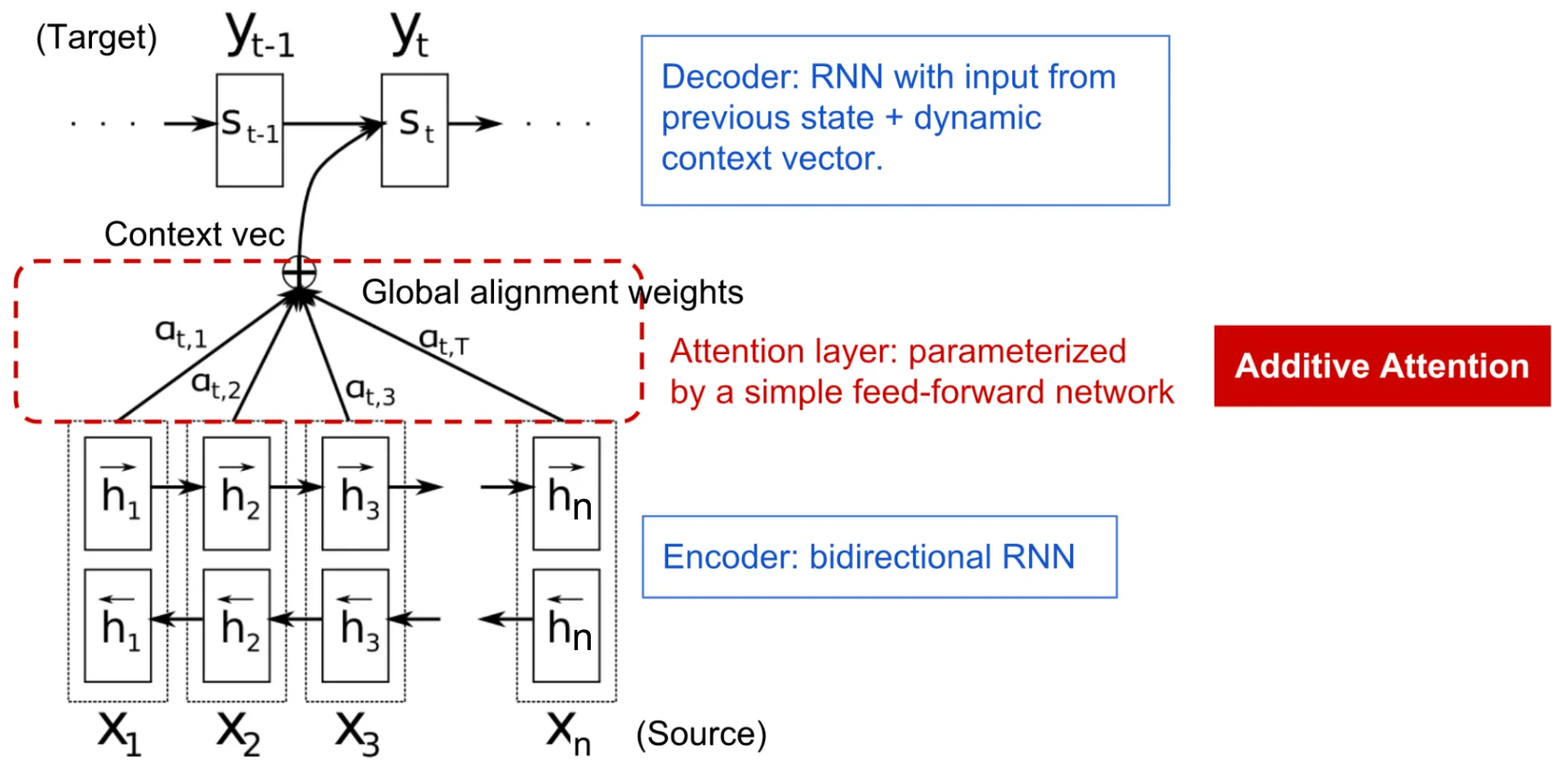
메커니즘
- 인코더 상태: 인코더는 은닉 상태 시퀀스 를 생성합니다.
- 정렬 점수 (Alignment Scores): 디코딩 단계 에서 모델은 위치 의 입력이 위치 의 출력과 얼마나 잘 정렬되는지 점수를 계산합니다. 이는 종종 디코더의 이전 상태 과 인코더 상태 의 함수입니다:
- 어텐션 가중치: 이 점수들은 소프트맥스 함수를 사용하여 정규화되어 어텐션 가중치 를 생성합니다:
- 컨텍스트 벡터: 단계 에 대한 컨텍스트 벡터 는 모든 인코더 은닉 상태의 *가중합(weighted sum)*입니다:
그런 다음 디코더는 와 자체 상태 을 사용하여 다음 단어를 예측합니다.
왜 모든 것을 바꾸었는가
어텐션은 고정 길이 병목 현상을 제거했습니다. 모델은 매 순간 입력의 어느 부분이 관련이 있는지 동적으로 결정하기 때문에 임의의 긴 시퀀스도 처리할 수 있습니다. 또한 어텐션 가중치를 시각화하여 모델이 번역 중에 어떤 단어에 집중하고 있는지 확인할 수 있으므로 어느 정도의 해석 가능성(Interpretability) 도 제공했습니다.
PyTorch 어텐션
다음은 디코더 상태와 인코더 상태로부터 컨텍스트 벡터를 계산하는 방법을 보여주는 PyTorch에서의 단순화된 점곱 어텐션(dot-product attention) 구현입니다.
import torch
import torch.nn.functional as F
def simple_attention(decoder_state, encoder_states):
# decoder_state: (batch, 1, hidden_dim)
# encoder_states: (batch, seq_len, hidden_dim)
# 1. 정렬 점수 계산 (점곱)
# scores shape: (batch, 1, seq_len)
scores = torch.bmm(decoder_state, encoder_states.transpose(1, 2))
# 2. 소프트맥스를 통해 어텐션 가중치 획득
# weights shape: (batch, 1, seq_len)
attention_weights = F.softmax(scores, dim=-1)
# 3. 인코더 상태들의 가중합으로 컨텍스트 벡터 획득
# context shape: (batch, 1, hidden_dim)
context = torch.bmm(attention_weights, encoder_states)
return context, attention_weights
# 사용 예시
batch_size = 1
seq_len = 5
hidden_dim = 4
# 시뮬레이션된 상태들
dec_state = torch.randn(batch_size, 1, hidden_dim)
enc_states = torch.randn(batch_size, seq_len, hidden_dim)
context, weights = simple_attention(dec_state, enc_states)
print("컨텍스트 벡터 형태:", context.shape)
print("어텐션 가중치:\n", weights)예제: 번역 정렬 (Translation Alignment)
영어를 프랑스어로 번역할 때 모델이 영어 단어에 어떻게 집중(attend)하는지 시각화해 보세요. 프랑스어 단어를 클릭하면 모델이 해당 단어를 생성할 때 어떤 영어 단어에 집중했는지 확인할 수 있습니다.
어텐션 정렬 시각화
프랑스어 단어(대상)를 클릭하여 모델이 어떤 영어 단어(원본)에 집중했는지 확인하세요.
Quizzes
Quiz 1: 어텐션이 없는 전통적인 인코더-디코더 모델에서 “병목 현상”은 무엇입니까?
병목 현상은 고정 크기의 컨텍스트 벡터입니다. 인코더는 시퀀스의 길이에 관계없이 전체 입력 시퀀스를 단일 벡터로 압축해야 합니다. 긴 문장의 경우, 특히 시퀀스 시작 부분의 단어에 대한 정보 손실이 발생합니다.
Quiz 2: 어텐션은 표준 RNN 인코더와 어떻게 다르게 컨텍스트 벡터를 계산합니까?
표준 RNN 인코더에서 컨텍스트 벡터는 단순히 RNN의 마지막 은닉 상태입니다. 어텐션에서 컨텍스트 벡터는 인코더가 생성한 모든 은닉 상태의 동적으로 계산된 가중합이며, 가중치는 현재 디코딩 단계에 따라 달라집니다.
Quiz 3: Bahdanau 어텐션은 순환 연결(recurrent connections)의 필요성을 제거합니까?
아닙니다. Bahdanau 어텐션은 RNN(특히 LSTM 또는 GRU)을 향상시키기 위해 설계되었습니다. 인코더와 디코더는 여전히 순환 네트워크였습니다. 순환 연결이 완전히 제거된 것은 “Attention is All You Need” 논문(Transformer)에 이르러서였습니다.
Quiz 4: 어텐션 모델의 해석 가능성(interpretability) 측면에 대해 논의해 보세요.
어텐션 모델은 어텐션 가중치()를 행렬(정렬 행렬)로 시각화할 수 있기 때문에 더 쉽게 해석할 수 있습니다. 이 행렬은 모델이 각 대상 단어를 생성할 때 어떤 원본 단어를 보고 있었는지 정확히 보여주므로 모델의 의사 결정 프로세스에 대한 통찰력을 제공합니다.
Quiz 5: 디코더 상태와 인코더 상태 사이의 정렬 점수(alignment score)를 계산하는 일반적인 방법은 무엇인가요?
일반적인 방법으로는 다음이 있습니다: 1) 점곱(Dot-product): , 단순하고 효율적입니다. 2) 일반(General): , 학습 가능한 가중치 행렬을 사용합니다. 3) 결합(Concat) (Bahdanau): , 작은 다층 퍼셉트론을 사용합니다.
Quiz 6: Bahdanau(가산형) 어텐션과 Luong(승산형/점곱) 어텐션의 정렬 점수(Alignment Score) 수식을 비교하고, 사용되는 디코더 은닉 상태(Hidden State) 시점의 차이를 설명하시오.
Bahdanau 어텐션은 가산형(Additive) 메커니즘을 사용합니다: 이며, 이는 이전 디코더 상태 과 인코더 상태 를 정렬합니다. 반면 Luong 어텐션은 승산형(Multiplicative) 메커니즘을 도입하여 ‘general’ 형태인 및 ‘dot’ 형태인 를 사용합니다. 결정적으로 Luong 어텐션은 현재 디코더 상태 를 인코더 상태 와 정렬합니다. 승산형 어텐션은 고도로 병렬화된 행렬 곱셈으로 최적화할 수 있어 계산 효율성이 더 높습니다.
References
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv:1409.0473.