7.1 Data Parallelism (DP/DDP)
6장에서는 수만 개의 GPU가 광학 스위치로 연결된 물리적 인프라와, 수조 개의 파라미터를 가진 모델에 데이터를 공급하기 위한 파이프라인을 구축했습니다. 또한 Model Collapse 와 같은 통계적 붕괴 현상을 방지하고 고품질의 학습 데이터를 엔지니어링하는 방법도 살펴보았습니다.
이제 우리는 연산의 물리적 한계와 마주해야 합니다.
최신 Foundation Model 을 단일 GPU에서 학습시키는 것은 인간의 수명 내에는 수학적으로 불가능합니다. 80GB VRAM을 가진 H100 하나에 모델을 온전히 올릴 수 있다 하더라도, 15조 개의 토큰을 처리하는 데는 수십 년이 걸립니다. 시간을 압축하기 위해 우리는 수천 개의 가속기에 작업 부하를 분산시켜야 합니다.
가장 기본적이고 근본적인 분산 전략은 Data Parallelism (데이터 병렬화) 입니다. 이 패러다임에서는 모델의 아키텍처를 쪼개지 않고 클러스터 내의 모든 GPU에 완벽하게 복제합니다. 모델을 나누는 대신, 데이터를 나누는 것입니다.
1. 초기의 단순한 접근: DataParallel (DP)
역사적으로 엔지니어들은 PyTorch의 torch.nn.DataParallel (DP) 로 구현된 단일 프로세스, 멀티 스레드 패러다임을 사용하여 학습을 병렬화하려고 시도했습니다.
로직은 매우 직관적입니다:
- 복제 (Replicate): 단일 노드(예: 8-GPU 서버)의 모든 GPU에 모델을 복사합니다.
- 분산 (Scatter): 거대한 글로벌 배치(예: 1024개의 시퀀스)를 가져와 128개 시퀀스 단위의 마이크로 배치(Micro-batch)로 쪼갭니다. 각 GPU에 하나의 마이크로 배치를 보냅니다.
- 순전파 (Forward Pass): 각 GPU는 독립적으로 순전파를 계산하고 자체적인 로컬 Loss를 구합니다.
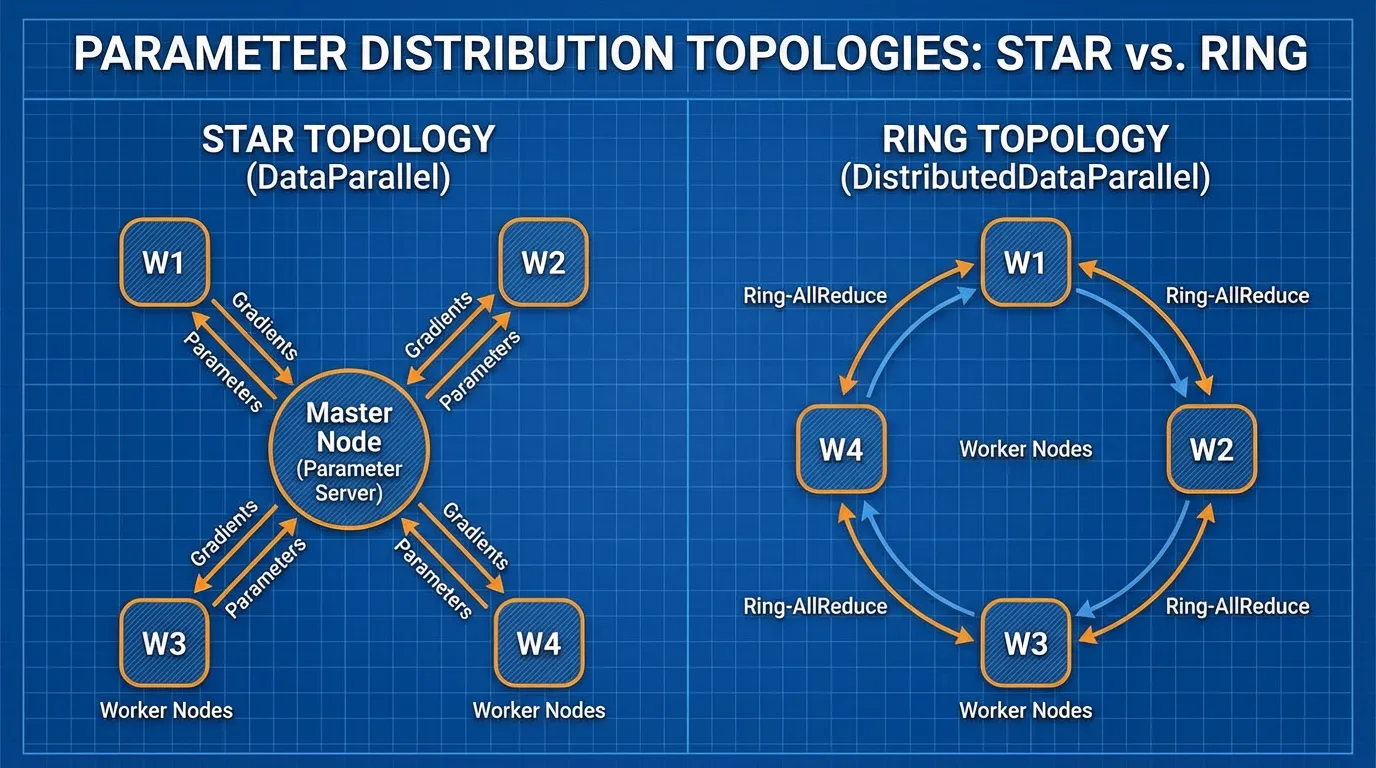
- 수집 및 역전파 (Gather & Backward): 여기서 아키텍처의 치명적인 한계가 드러납니다. DP는 Parameter Server 토폴로지를 사용하며 (일반적으로 GPU 0을 마스터로 암묵적 매핑), 모든 GPU는 자신의 그래디언트(Gradient)를 GPU 0으로 보냅니다. GPU 0은 그래디언트들의 평균을 내어 마스터 모델의 가중치를 업데이트한 다음, 새로운 가중치를 GPU 1-7로 다시 브로드캐스트(Broadcast)합니다.
 Source: Generated by Gemini
Source: Generated by Gemini
왜 DP는 더 이상 사용되지 않는가 (Deprecated)
DataParallel 은 최신 AI 인프라 환경에서 본질적인 결함을 가지고 있습니다:
- Python GIL (Global Interpreter Lock): 여러 스레드를 관리하는 단일 Python 프로세스로 동작하기 때문에, GIL이 실행 속도를 심각하게 제한합니다.
- GPU 0 병목 현상: 마스터 GPU는 심각한 통신 병목 지점이 됩니다. GPU 1-7이 유휴 상태(Idle)로 대기하는 동안, GPU 0은 그래디언트를 집계하고 가중치를 업데이트하느라 과부하에 걸립니다. 이는 극단적인 VRAM 불균형과 낮은 연산 활용도(종종 50% 미만의 MFU)를 초래합니다.
- 단일 노드의 한계: DP는 여러 대의 물리적 서버(Multi-node)에 걸쳐 확장할 수 없습니다.
Foundation Model 을 학습시키기 위해서는 마스터 노드라는 개념 자체를 완전히 제거해야 합니다.
2. 분산 학습의 표준: Distributed Data Parallel (DDP)
DP의 병목 현상을 해결하기 위해 업계는 Distributed Data Parallel (DDP) (torch.nn.parallel.DistributedDataParallel) 로 전환했습니다.
DDP는 멀티 프로세스 아키텍처로 동작합니다. 만약 1,024개의 GPU가 있다면, 1,024개의 독립적인 Python 프로세스를 생성합니다. 각 프로세스는 고유한 옵티마이저, 자체 메모리 공간, 그리고 완벽하게 동일한 모델 복제본을 가집니다.
각 프로세스가 독립적이기 때문에 GIL 경합(Contention)이 발생하지 않습니다. 프로세스들이 상호작용해야 하는 유일한 순간은 역전파(Backward pass) 과정에서 모든 복제본이 가중치를 동일하게 업데이트하도록 보장할 때뿐입니다. 중앙 마스터 노드 없이 이를 수행하기 위해 DDP는 고성능 컴퓨팅(HPC)의 탈중앙화된 통신 프리미티브인 Ring All-Reduce 알고리즘을 활용합니다.
Ring All-Reduce의 수학적 원리
2017년 Baidu Research에서 딥러닝에 도입한 [1] Ring All-Reduce는 개의 노드가 특정 노드에 과부하를 주지 않고도 그래디언트의 평균을 낼 수 있게 해줍니다.
모델의 그래디언트 총 크기를 이라고 가정해 봅시다 (예: 1B 파라미터 모델의 경우 약 4GB). 단순한 Parameter Server 구조에서는 마스터 노드가 바이트의 데이터를 수신해야 하며, 이는 클러스터 크기에 비례하여 선형적으로 증가하여 필연적으로 네트워크 대역폭을 붕괴시킵니다.
Ring All-Reduce에서 GPU들은 논리적인 원형(Ring)으로 배치됩니다. 알고리즘은 두 단계로 동작합니다:
- Scatter-Reduce: 그래디언트 텐서는 개의 블록으로 쪼개집니다. 각 GPU는 오른쪽 이웃에게 하나의 블록을 보내고 왼쪽 이웃으로부터 다른 블록을 받아 지속적으로 값을 누적합니다. 단계가 지나면, 모든 GPU는 개의 블록 중 정확히 하나 에 대해 완전히 집계된 합을 가지게 됩니다.
- All-Gather: 완전히 집계된 블록들이 다시 링을 따라 순환합니다. 추가로 단계가 지나면 모든 GPU가 완전하게 집계된 전체 그래디언트 텐서를 가지게 됩니다.
이 과정에서 단일 노드 가 전송하는 총 데이터 양은 다음과 같습니다:
로 갈수록 전송되는 데이터 양은 에 수렴합니다. 즉, 통신 오버헤드는 클러스터 내의 GPU 수와 독립적입니다. 이 수학적 특성 덕분에 기업들은 네트워크 붕괴 없이 100,000개의 GPU로 학습을 확장할 수 있습니다.
3. 연산과 통신의 중첩: Gradient Bucketing
Ring All-Reduce를 사용하더라도 전체 역전파(Backward pass)가 끝날 때까지 기다렸다가 수 기가바이트의 그래디언트를 네트워크로 전송하는 것은 GPU를 I/O 대기 상태(Idle)로 방치하는 결과를 낳습니다.
최신 DDP 구현체는 Gradient Bucketing (그래디언트 버키팅) 을 통해 이 문제를 해결합니다. 역전파 중에는 마지막 레이어(예: Layer 100)부터 첫 번째 레이어(Layer 1) 순으로 그래디언트가 계산됩니다. Layer 100의 그래디언트 전송을 시작하기 위해 Layer 1의 그래디언트 계산이 끝날 때까지 기다릴 필요가 없습니다.
DDP는 그래디언트를 “버킷(Bucket)” 단위로 그룹화합니다 (PyTorch의 기본값은 25MB). 계산된 그래디언트로 버킷이 가득 차는 즉시, DDP는 NCCL (NVIDIA Collective Communication Library) 백엔드를 통해 비동기적(Non-blocking)으로 all_reduce 네트워크 호출을 실행합니다.
Interactive: 연산과 통신의 중첩 (Overlap) 시각화
아래의 인터랙티브 타임라인을 사용하여 DDP가 역전파 연산과 네트워크 통신을 어떻게 중첩(Overlap)시키는지 확인해 보십시오. 버키팅이 GPU의 대기 상태를 방지하고, 순수한 연산 시간 뒤로 네트워크 지연 시간(Latency)을 숨기는 과정을 관찰할 수 있습니다.
Gradient Bucketing & Overlap Visualization
Notice: As soon as Bucket 1 is filled with gradients from Layers 4 and 3, the network transmission (All-Reduce) begins immediately. The GPU does not sit idle; it continues computing gradients for Layers 2 and 1 simultaneously, effectively hiding the network latency.
Note: PyTorch에서는 DDP 래퍼(Wrapper)의 bucket_cap_mb 파라미터를 사용하여 버킷 크기를 조정할 수 있습니다. 이 값을 사용 중인 InfiniBand나 NVLink 대역폭에 맞게 튜닝하는 것은 클러스터 처리량을 극대화하기 위한 매우 중요한 마이크로 최적화(Micro-optimization) 기법입니다.
4. PyTorch 상용 구현 (Production Implementation)
아래는 상용 환경(Production-grade) 수준의 DDP 구현 예시입니다. 단순한 토이 코드와 달리, 이 스크립트는 멀티 노드 실행의 표준인 torchrun 을 사용하며, NCCL 프로세스 그룹을 초기화하고, 두 GPU가 동일한 데이터를 보지 않도록 DistributedSampler 를 구성한 뒤 DDP 래퍼를 적용합니다.
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
# 1. 분산 프로세스 그룹 초기화
def setup():
# torchrun이 아래의 환경 변수들을 자동으로 설정합니다.
init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
return local_rank
def cleanup():
destroy_process_group()
# 설명을 위한 더미 데이터셋
class DummyCorpus(Dataset):
def __init__(self, size=10000, seq_len=512, vocab_size=32000):
self.data = torch.randint(0, vocab_size, (size, seq_len))
self.labels = torch.randint(0, vocab_size, (size, seq_len))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
def train():
local_rank = setup()
# 2. 모델 인스턴스화 및 로컬 GPU로 이동
# 실제 환경에서는 복잡한 Transformer 아키텍처가 들어갑니다.
model = nn.Sequential(
nn.Embedding(32000, 1024),
nn.Linear(1024, 4096),
nn.GELU(),
nn.Linear(4096, 32000)
).to(local_rank)
# 3. 모델을 DDP로 래핑
# gradient_as_bucket_view=True는 불필요한 메모리 복사를 방지하여 메모리를 최적화합니다.
model = DDP(model, device_ids=[local_rank], gradient_as_bucket_view=True)
# 4. Distributed Sampler 설정
dataset = DummyCorpus()
# Sampler는 각 프로세스가 데이터셋의 상호 배타적인 조각을 받도록 보장합니다.
sampler = DistributedSampler(dataset, shuffle=True)
dataloader = DataLoader(dataset, batch_size=16, sampler=sampler, num_workers=4)
optimizer = optim.AdamW(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
# 5. Training Loop
epochs = 3
for epoch in range(epochs):
# 중요: 매 에폭마다 서로 다른 셔플링을 보장하기 위해 sampler에 에폭을 설정해야 합니다.
sampler.set_epoch(epoch)
for step, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(local_rank), targets.to(local_rank)
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs.view(-1, 32000), targets.view(-1))
# Backward pass가 비동기 All-Reduce 버킷 전송을 트리거합니다.
loss.backward()
# 모든 그래디언트가 완전히 동기화된 후에만 옵티마이저가 스텝을 진행합니다.
optimizer.step()
if local_rank == 0 and step % 10 == 0:
print(f"Epoch {epoch} | Step {step} | Loss {loss.item():.4f}")
cleanup()
if __name__ == "__main__":
# 8개의 GPU가 있는 단일 노드에서 이 스크립트를 실행하려면:
# torchrun --standalone --nproc_per_node=8 train_ddp.py
train()동기화 장벽 (The Synchronization Barrier)
위 코드에서 optimizer.step() 은 암묵적인 동기화 지점(Synchronization point) 역할을 합니다. 다음 순전파(Forward pass)가 시작되기 전에 모든 GPU에 걸쳐 가중치가 정확히 동일해야 하므로, 마지막 Ring All-Reduce 버킷의 전송이 완료될 때까지 옵티마이저는 스텝을 진행할 수 없습니다. 만약 하나의 GPU가 다른 GPU들보다 느리다면 (예: 발열로 인한 스로틀링 문제 등으로 발생한 “Straggler” 노드), 전체 클러스터는 연산을 멈추고 해당 노드를 기다리게 됩니다. 이는 DDP 클러스터에서 동질적인(Homogeneous) 하드웨어 구성이 얼마나 중요한지를 보여줍니다.
Summary
Data Parallelism 은 분산 학습으로 들어가는 진입점입니다. DistributedDataParallel 과 Ring All-Reduce 알고리즘을 활용함으로써 우리는 네트워크 통신 오버헤드를 클러스터 크기와 분리시켰고, GPU를 추가함에 따라 처리량을 선형적으로 확장할 수 있게 되었습니다. 더 나아가 Gradient Bucketing 을 통해 네트워크 전송의 지연 시간(Latency)을 역전파 연산 뒤로 완벽하게 숨길 수 있었습니다.
하지만, 여전히 극복할 수 없는 명백한 한계가 존재합니다. DDP는 전체 모델의 가중치, 그래디언트, 그리고 옵티마이저 상태(Optimizer states)가 단일 GPU의 VRAM 안에 모두 들어가야만 동작합니다.
만약 80GB의 A100 GPU를 가지고 있다면, 표준 DDP를 사용하여 현실적으로 학습할 수 있는 모델의 최대 크기는 약 20억(2B) 파라미터 수준에 불과합니다 (Adam 옵티마이저 상태와 활성화 값(Activations)이 차지하는 메모리 때문입니다). 그렇다면 700억(70B)이나 1조(1T) 파라미터 모델을 학습시키고자 할 때는 어떻게 해야 할까요?
우리는 표준 Data Parallelism 을 넘어서서 메모리 공간 자체를 쪼개기 시작해야 합니다. 이어지는 7.2 ZeRO (Zero Redundancy Optimizer) 에서는 클러스터 전체에 걸쳐 모델의 상태를 산산조각 내어 단일 GPU의 메모리 장벽을 영원히 부수는 방법을 탐구할 것입니다.
Quizzes
Quiz 1: 단일 머신에서 여러 대의 GPU를 사용하여 학습할 때조차 PyTorch가 공식적으로
DP는 단일 프로세스, 멀티 스레드 아키텍처를 사용하기 때문에 Python의 GIL(Global Interpreter Lock)에 의해 심각한 병목 현상이 발생합니다. 또한 DP는 GPU 0이 마스터 노드 역할을 하여 모든 그래디언트를 수집하고 업데이트된 가중치를 분산시키는 Parameter Server 토폴로지에 의존합니다. 이는 GPU 0에 심각한 VRAM 불균형과 네트워크 혼잡을 유발합니다. 반면 DDP는 멀티 프로세싱(GIL 우회)과 탈중앙화된 Ring All-Reduce 토폴로지를 사용하여 메모리와 연산 활용도를 균형 있게 유지합니다.DataParallel (DP)의 사용을 중단(Deprecated)하고 DistributedDataParallel (DDP)을 권장하는 이유는 무엇인가?
Quiz 2: 1,000대의 GPU로 구성된 클러스터에서 Ring All-Reduce를 수행할 때, 단일 노드가 전송해야 하는 그래디언트 데이터의 양은 10대의 GPU로 구성된 클러스터와 비교하여 얼마나 더 많은가?
사실상 차이가 없습니다. Ring All-Reduce에서 단일 노드가 전송하는 총 데이터 양은 입니다. 일 때는 이고, 일 때는 입니다. 통신 볼륨은 점근적으로 에 수렴하며 클러스터 크기와 사실상 독립적입니다. 이것이 바로 Ring All-Reduce가 대규모 스케일링에 매우 적합한 이유입니다.
Quiz 3: DDP에서 “Gradient Bucketing (그래디언트 버키팅)“의 주요 목적은 무엇인가?
Gradient Bucketing은 연산(역전파)과 통신(네트워크 전송)을 중첩(Overlap)시키기 위해 사용됩니다. 그래디언트를 동기화하기 위해 전체 역전파가 끝날 때까지 기다리는 대신, DDP는 그래디언트를 버킷으로 그룹화합니다. 깊은 레이어의 그래디언트가 먼저 계산되어 버킷이 가득 차는 즉시 NCCL을 통해 비동기 All-Reduce를 트리거하며, 이를 통해 얕은 레이어의 연산이 진행되는 동안 네트워크 지연 시간을 숨길 수 있습니다.
Quiz 4: 1,024개의 GPU(각 80GB VRAM)로 구성된 클러스터가 있다고 가정할 때, 1,000억(100B) 파라미터 모델을 표준 DDP를 사용하여 학습할 수 있는가? 그 이유는 무엇인가?
불가능합니다. 표준 DDP는 모델 가중치, 그래디언트, 그리고 옵티마이저 상태의 전체 복제본이 ‘모든 단일 GPU’의 VRAM에 상주해야 합니다. 100B 파라미터 모델을 혼합 정밀도(Mixed precision)로 학습하려면 옵티마이저 상태와 가중치를 저장하는 데만 약 1.6 테라바이트(TB)의 VRAM이 필요하며, 이는 단일 GPU의 80GB 한계를 아득히 초과합니다. 따라서 ZeRO나 텐서 병렬화(Tensor Parallelism) 같은 고급 기술이 필수적입니다.
References
- Gibiansky, A. (2017). “Bringing HPC Techniques to Deep Learning.” Baidu Research. Link.
- Li, S., et al. (2020). PyTorch Distributed: Experiences on Accelerating Data Parallel Training. VLDB. arXiv:2006.15704.