20.4 신경망은 프로그램이다: 실행의 미래
앞 절들이 주로 “긴 시퀀스를 어떻게 더 효율적으로 처리할 것인가”를 다뤘다면, 이번 절은 “모델이 복잡한 문제를 어떤 계산 절차로 풀 것인가”를 다룹니다. 긴 컨텍스트를 싸게 읽는 것만으로는 충분하지 않습니다. 코딩, 데이터 분석, 수학, agent workflow에서는 모델이 중간 상태를 만들고, 검증하고, 필요하면 외부 실행기를 호출해야 합니다.
인공지능의 진화는 정적인 규칙 기반 시스템에서 동적인 데이터 주도형 모델로의 여정이었습니다. 하지만 파운데이션 모델(Foundation Models)의 다음 개척지는 데이터와 코드의 경계를 허물고 있습니다. 우리는 신경망이 단순한 함수 근사기(Function approximator)를 넘어, 프로그램을 생성하고 실행하는 주체 가 되는 패러다임으로 이동하고 있습니다.
이 절에서는 “Neural Networks as Programs”라는 개념을 다룹니다. 이는 모델이 복잡한 추론 과업을 해결하기 위해 구조화된 절차를 생성하고 조작하거나, 일부를 내부적으로 시뮬레이션하는 시스템을 이해하는 데 유용한 프레이밍입니다.
정적 가중치에서 동적 실행으로
전통적으로 신경망은 학습된 가중치를 가진 고정된 계산 그래프로 간주됩니다. 입력을 받아 행렬 곱셈과 비선형 활성화 함수를 거쳐 출력을 생성합니다. 이 방식은 강력하지만, 명시적인 알고리즘 논리, 장기적인 상태 관리, 또는 정확한 정밀도가 필요한 작업(예: 다단계 수학 알고리즘 실행)에는 어려움을 겪습니다.
Neural Networks as Programs 개념은 이러한 관점을 두 가지 주요 방식으로 전환합니다.
- 프로그램 생성자로서의 신경망 (Neural Networks as Program Generators): 모델이 문제를 해결하기 위해 명시적인 코드(예: Python, SQL) 또는 도메인 특화 언어(DSL)를 생성하고, 이는 외부 인터프리터에 의해 실행됩니다.
- 프로그램 실행자로서의 신경망 (Neural Networks as Program Executors): 모델 자체가 프로그램의 실행을 시뮬레이션하는 방법을 학습하여, 전통적인 CPU나 가상 머신과 유사하게 상태와 메모리를 동적으로 유지합니다.
진화: NTM에서 현대의 LLM까지
프로그램과 유사한 기능을 가진 신경망에 대한 아이디어는 새로운 것이 아닙니다. 초기 연구는 현대적 접근 방식의 기초를 마련했습니다.
- Neural Turing Machines (NTM): Graves 등(2014) [1] 이 발표한 NTM은 신경망 컨트롤러를 외부 메모리 뱅크와 결합했습니다. 이를 통해 네트워크는 복사, 정렬, 연상 기억과 같은 기본적인 알고리즘을 학습할 수 있었으며, 사실상 미분 가능한 컴퓨터로 작동했습니다.
- Differentiable Neural Computers (DNC): NTM의 진화된 형태 [2] 로, 더 복잡한 메모리 주소 지정 메커니즘과 그래프 탐색과 같은 구조화된 작업에서 더 나은 성능을 제공했습니다.
이러한 모델들은 신경망이 알고리즘 논리를 학습할 수 있음을 증명했지만, 학습시키고 확장하기가 어려웠습니다. 돌파구는 대규모 언어 모델(LLM)의 스케일과 고품질 코드를 생성하는 창발적 능력에서 비롯되었습니다.
프로그램 생성자로서의 LLM: 실행 가이드 생성 (Execution-Guided Synthesis)
오늘날 이 개념이 가장 실용적으로 구현된 사례 중 하나가 실행 가이드 생성 (Execution-Guided Synthesis) 입니다. 코드 실행 환경이나 데이터 분석 도우미에서 자주 볼 수 있는 패턴으로, 모델은 복잡한 문제를 자신의 가중치 안에서만 해결하려 하기보다 Python 프로그램을 작성하고 그것을 외부 실행 환경에 맡깁니다.
이는 강력한 피드백 루프를 생성합니다:
- 생성 (Generate): 모델이 사용자의 프롬프트를 기반으로 프로그램을 작성합니다.
- 실행 (Execute): 외부 환경이 프로그램을 실행하고 결과 또는 에러 로그를 반환합니다.
- 정제 (Refine): 실행이 실패하거나 에러가 발생하면, 모델은 에러 로그를 읽고 프로그램의 수정된 버전을 생성합니다.
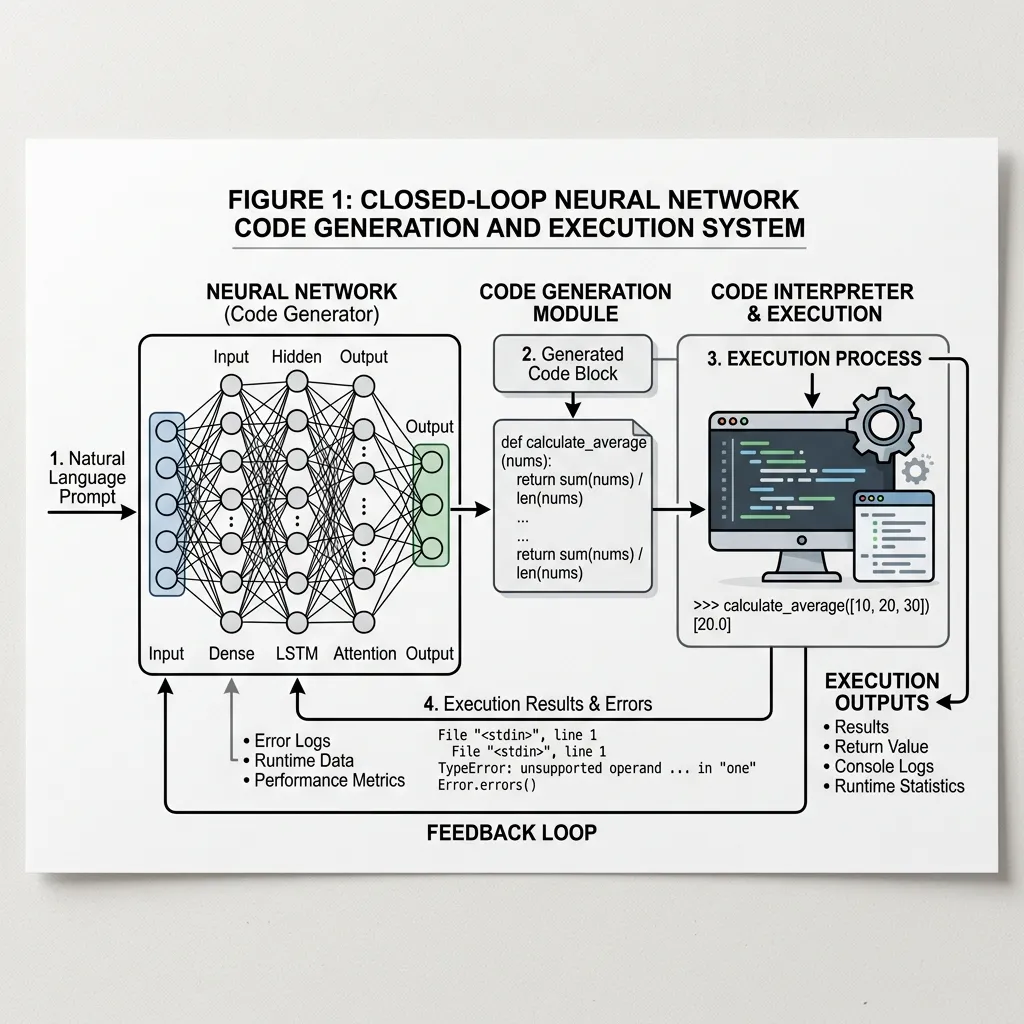 출처: Generated by Gemini
출처: Generated by Gemini
이러한 접근 방식은 정밀한 계산의 부담을 신경망에서 결정론적인 실행 환경으로 이전하여, 시스템의 정확성과 기능을 대폭 향상시킵니다.
Agentic coding에서의 실무 패턴
현대 코딩 에이전트는 보통 아래 루프를 따릅니다.
- 읽기: 관련 파일, 테스트, 문서, 이슈 설명을 찾습니다.
- 계획: 변경 범위를 작게 나누고 위험한 파일을 식별합니다.
- 수정: diff나 직접 파일 수정으로 패치를 만듭니다.
- 실행: unit test, type check, lint, integration test를 돌립니다.
- 반성: 실패 로그를 읽고 원인을 좁힙니다.
- 반복: 필요한 만큼 수정과 검증을 반복합니다.
이 루프에서 LLM은 모든 계산을 머릿속으로 하지 않습니다. 오히려 좋은 시스템일수록 테스트 러너, 타입체커, 검색 도구, 패키지 매니저, 샌드박스 같은 외부 프로그램에 일을 나눕니다. 그래서 “신경망은 프로그램이다”라는 말은 모델이 CPU를 대체한다는 뜻이 아니라, 모델이 프로그램을 만들고, 실행 결과를 해석하고, 다음 행동을 선택하는 controller 가 된다는 뜻에 가깝습니다.
실행 시뮬레이션: 신경망 인터프리터 (Neural Interpreter)
외부 실행을 위한 코드를 생성하는 것과 별개로, 모델이 내부적으로 실행을 시뮬레이션 하도록 학습시키는 방향도 중요한 연구 주제입니다. 외부 인터프리터를 쓰기 어렵거나, 너무 자주 호출하면 지연 시간과 비용이 커지는 상황에서 특히 의미가 있습니다.
Python 스크립트의 출력을 예측하도록 훈련된 모델을 생각해 보십시오. 이를 정확하게 수행하려면 모델은 변수 상태와 제어 흐름에 대한 멘탈 모델을 유지해야 합니다.
PyTorch 예제: 단순한 신경망 상태 머신
완전한 프로그램 합성은 간단한 예제의 범위를 벗어나지만, 신경망이 단순한 상태 머신이나 프로그램 실행자처럼 작동하도록 훈련될 수 있음을 보여줄 수 있습니다. 여기서는 입력 지침에 따라 카운트를 증가시키거나 감소시키는 카운터를 시뮬레이션하도록 학습하는 간단한 순환 신경망(RNN)을 구현하여, 상태 유지 및 실행 논리를 보여줍니다.
import torch
import torch.nn as nn
import torch.optim as optim
class NeuralCounter(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(NeuralCounter, self).__init__()
self.hidden_size = hidden_size
# 상태를 유지하기 위한 RNN 레이어
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
# 은닉 상태를 출력 값으로 매핑하는 선형 레이어
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, initial_state=None):
# x shape: (batch_size, sequence_length, input_size)
if initial_state is None:
initial_state = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
out, hidden = self.rnn(x, initial_state)
# 모든 타임스텝의 출력 매핑
out = self.fc(out)
return out, hidden
# 하이퍼파라미터
input_size = 2 # [증가, 감소] 원-핫 인코딩
hidden_size = 16
output_size = 1 # 현재 카운트
seq_length = 10
batch_size = 32
# 모델 인스턴스화
model = NeuralCounter(input_size, hidden_size, output_size)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 더미 훈련 데이터 생성
# 입력: 증가(1,0) 및 감소(0,1)의 시퀀스
inputs = torch.randint(0, 2, (batch_size, seq_length, 1))
# 원-핫 인코딩으로 변환: shape (batch_size, seq_length, 2)
inputs_one_hot = torch.zeros(batch_size, seq_length, 2)
inputs_one_hot.scatter_(2, inputs, 1.0)
# 타겟 계산 (증가 - 감소의 누적 합)
targets = torch.zeros(batch_size, seq_length, 1)
for i in range(batch_size):
current_count = 0.0
for t in range(seq_length):
if inputs[i, t, 0] == 0: # 증가
current_count += 1.0
else: # 감소
current_count -= 1.0
targets[i, t, 0] = current_count
# 훈련 루프
for epoch in range(100):
optimizer.zero_grad()
outputs, _ = model(inputs_one_hot)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f'Epoch [{epoch+1}/100], Loss: {loss.item():.4f}')
print("훈련 완료. 모델이 단순한 프로그램(카운터)을 시뮬레이션하는 법을 배웠습니다.")이 예제에서 RNN의 은닉 상태는 현재 카운트를 보유하는 “메모리” 또는 “레지스터” 역할을 하며, 네트워크는 입력 지침에 따라 이 상태를 업데이트하는 방법을 학습합니다.
미래: 뉴로-심볼릭 AI (Neuro-Symbolic AI) 및 자가 진화 시스템
Neural Networks as Programs의 궁극적인 실현은 딥러닝 신경망의 강력한 학습 능력과 심볼릭 AI의 엄격한 논리를 결합하는 뉴로-심볼릭 AI (Neuro-Symbolic AI) 에 있습니다.
미래의 시스템은 특정 작업을 위한 코드를 생성하는 것에 그치지 않고, 자신의 성능을 최적화하기 위해 완전히 새로운 알고리즘과 데이터 구조를 생성할 수 있습니다. 이는 AI가 새로운 도전에 적응하기 위해 자신의 “소프트웨어”를 지속적으로 다시 작성하여 사실상 자가 프로그래밍 엔티티가 되는 자가 진화 시스템 (Self-Evolving Systems) 의 개념으로 이어집니다.
다음 절로의 연결: 왜 Multi-Token Prediction이 중요해지는가
프로그램을 생성하려면 한 토큰 다음만 보는 것보다 더 긴 구조를 미리 잡는 능력이 중요합니다. 함수의 시그니처를 쓰는 순간, 몇 줄 뒤의 return 타입과 예외 처리를 어느 정도 계획해야 합니다. 수학 풀이도 마찬가지입니다. 다음 절의 Multi-Token Prediction은 이런 장기 구조를 학습 목표에 직접 넣으려는 시도입니다.
Quizzes
Quiz 1: 복잡한 추론을 위해 순수한 신경망 생성 대신 실행 가이드 생성(Execution-Guided Synthesis)을 사용할 때의 주된 장점은 무엇인가요?
주된 장점은 정밀도와 신뢰성입니다. 결정론적인 계산을 외부 인터프리터로 이관함으로써, 시스템은 신경망 가중치 고유의 환각(Hallucination) 및 계산 오류를 방지하고 논리적 및 수학적 작업에 대한 정확한 결과를 보장합니다.
Quiz 2: Neural Turing Machines (NTM)은 표준 순환 신경망(RNN)과 어떻게 다릅니까?
RNN은 고정된 크기의 은닉 벡터에 상태를 유지하는 반면, NTM은 컨트롤러(신경망)를 주소 지정이 가능한 외부 메모리 뱅크와 분리합니다. 이를 통해 NTM은 특정 위치를 읽고 쓸 수 있어, 훈련 중에 본 것보다 더 긴 시퀀스로 확장되는 알고리즘을 학습할 수 있습니다.
Quiz 3: 뉴로-심볼릭 AI의 맥락에서 “Symbolic”은 무엇을 의미하나요?
이는 전통적인 규칙 기반 AI, 논리, 그리고 이산적인 표현(예: 코드 또는 수학 공식)을 의미합니다. 이를 “Neural” 네트워크와 결합하면 시스템은 직관적인 패턴 인식과 엄격한 논리적 추론의 이점을 모두 누릴 수 있습니다.
Quiz 4: Neural Turing Machines (NTM)은 메모리 접근을 위해 하이브리드 주소 지정 메커니즘을 사용합니다. 콘텐츠 기반 주소 지정(Content-based addressing)과 위치 기반 주소 지정의 후속 보간 게이팅(Interpolation gating) 단계에 대한 수학적 수식을 작성하고 설명하세요.
NTM은 메모리 가중치 벡터 를 생성하기 위해 다단계 주소 지정 메커니즘을 사용합니다.
1. 콘텐츠 기반 주소 지정: 컨트롤러는 키 벡터 와 양의 스칼라 키 강도 를 출력합니다. 위치 에 대한 가중치는 메모리 행렬 와의 코사인 유사도에 의해 결정됩니다:
여기서 는 코사인 유사도입니다.
2. 보간 게이트: 콘텐츠 기반 주소와 이전 타임스텝의 주소 지정 벡터 을 혼합하기 위해, NTM은 컨트롤러가 출력하는 스칼라 보간 게이트 를 사용합니다:
이를 통해 네트워크는 유사한 콘텐츠에 집중하거나 과거의 초점을 기반으로 순차적으로 반복할 수 있습니다.
References
- Graves, A., Wayne, G., & Danihelka, Ivo. (2014). Neural Turing Machines. arXiv:1410.5401.
- Graves, A., et al. (2016). Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626), 471-476.