16.3 Multi-agent Collaboration
이전 장에서는 단일 자율 에이전트(Autonomous agent)가 LATS와 성찰형 메모리(Reflective memory) 같은 계획 아키텍처를 사용하여 복잡한 환경을 탐색하는 방법을 살펴보았습니다. 그러나 단일 에이전트는 필연적으로 인지적 한계(Cognitive ceiling)에 부딪힙니다. 작업의 복잡성이 증가함에 따라, 단일 컨텍스트 윈도우(Context window)는 이질적인 지시사항, 중간 스크래치패드(Scratchpads), 그리고 상충하는 목표들로 오염됩니다.
더욱 치명적인 것은 단일 에이전트가 겪는 페르소나 붕괴 (Persona collapse) 현상입니다. 만약 단일 LLM에게 “창의적인 개발자”와 “엄격한 보안 감사자” 역할을 동시에 수행하도록 프롬프트를 주면, 모델은 이 상충하는 목표 사이의 긴장감을 유지하는 데 어려움을 겪습니다. 결국 두 가지 특성 중 어느 것도 완벽히 수행하지 못하고 어중간하게 타협한 결과물을 생성하게 됩니다.
이를 해결하기 위해 우리는 단일 지능의 심리학에서 다중 지능의 사회학으로 패러다임을 전환합니다. Multi-agent collaboration (다중 에이전트 협업) 은 인지적 부하를 분산시키고, 엄격한 역할 전문화를 강제하며, 토론(Debate)을 활용하여 환각(Hallucinations)을 걸러냅니다. 소프트웨어 회사가 기획자, 엔지니어, QA 테스터의 협업에 의존하듯, 다중 에이전트 시스템은 특화된 LLM들을 조율하여 단일 모델의 한계를 아득히 뛰어넘는 목표를 달성합니다.
1. AI의 사회학: 통신 토폴로지 (Communication Topologies)
여러 에이전트가 상호작용할 때, 그들의 통신 구조인 토폴로지(Topology)는 시스템의 효율성과 역량을 결정짓는 핵심 요소입니다. AutoGen [1] 과 MetaGPT [2] 같은 초기 프레임워크들은 이러한 상호작용 패턴을 공식화했습니다.
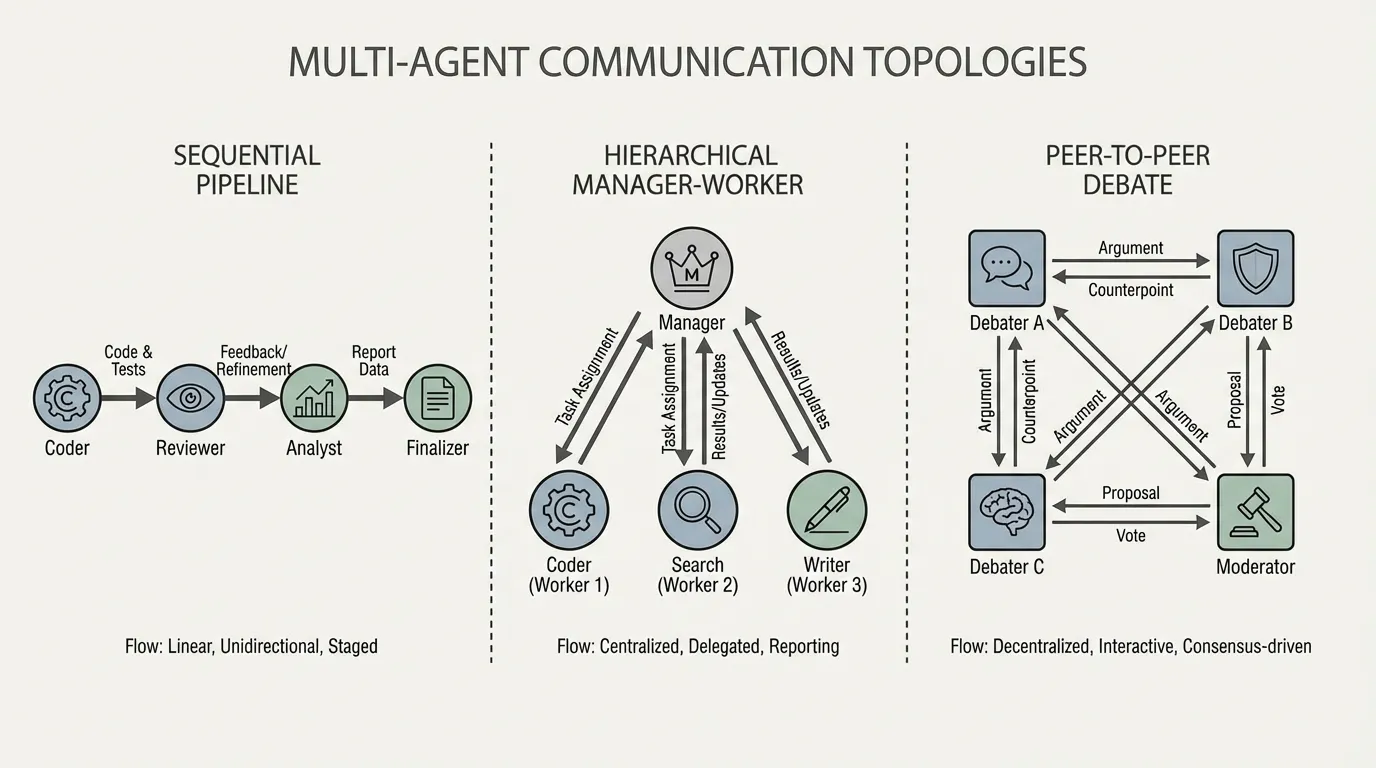
1.1 순차적 파이프라인 (Sequential Pipelines)
가장 단순한 토폴로지는 선형 체인입니다. 에이전트 A가 작업을 완료하고 그 결과물을 에이전트 B에게 전달합니다.
- 메커니즘: Planner 에이전트가 기획서를 작성 Coder 에이전트가 코드를 구현 QA 에이전트가 테스트 코드를 작성합니다.
- 장점: 결정론적(Deterministic)이며 예측 가능합니다. 각 에이전트는 이전 단계의 결과물만 확인하면 되므로 컨텍스트 오버헤드가 적습니다.
- 단점: 매우 취약(Brittle)합니다. 만약 Planner 가 근본적인 오류를 범했다면, 파이프라인 끝에 있는 QA 에이전트가 복잡한 역방향 라우팅 로직 없이 피드백을 맨 처음으로 돌려보내기 어렵습니다.
1.2 계층형 구조 (Hierarchical: Manager-Worker)
기업의 조직 구조에서 영감을 받은 이 방식은, 중앙의 “Manager” 에이전트가 작업을 분해하고 이를 특화된 “Worker” 에이전트들에게 위임합니다.
- 메커니즘: Manager 는 전역 상태(Global state)와 목표를 유지합니다. 웹 검색기(Web Searcher), 파이썬 실행기(Python Executor) 등의 Worker 들을 비동기적으로 호출하고, 이들의 응답을 취합하여 최종 결과물을 합성합니다.
- 장점: 병렬 처리가 가능한 작업에 매우 적합합니다. Manager 는 깔끔하고 높은 수준의 컨텍스트 윈도우를 유지할 수 있습니다.
- 단점: Manager 가 병목(Bottleneck)이 됩니다. Manager 의 추론이 실패하면 전체 시스템이 붕괴됩니다.
1.3 공동 토론 및 P2P (Joint Debate and Peer-to-Peer)
엄격한 계층 구조 대신, 서로 다른 시스템 프롬프트(예: “제안자” vs “회의론자”)를 가진 에이전트들을 공유 환경에 배치하여 합의에 도달할 때까지 해결책을 토론하게 합니다. 연구에 따르면 다중 에이전트 토론은 사실성(Factuality)과 수학적 추론 능력을 극적으로 향상시킵니다 [3].
- 메커니즘: 복잡한 수학 문제가 주어지면 3개의 에이전트가 독립적으로 풀이를 생성합니다. 그런 다음 서로의 풀이를 읽고 반복적으로 비판합니다.
- 합의의 수학적 정의: 에이전트들의 출력 간 의미론적 거리(Semantic distance)가 임계값 이하로 떨어지거나, 지정된 “Judge(판사)” 에이전트가 토론이 해결되었다고 판단할 때 시스템은 수렴(Convergence)에 도달합니다.
 Source: Generated by Gemini
Source: Generated by Gemini
토폴로지 비교 요약
| 토폴로지 (Topology) | 최적의 사용 사례 | 컨텍스트 효율성 | 오류 복구 능력 |
|---|---|---|---|
| Sequential | 표준화되고 예측 가능한 워크플로우 (예: ETL 파이프라인). | 높음 | 낮음 |
| Hierarchical | 광범위한 다중 도메인 리서치 및 병렬 실행. | 보통 | 보통 |
| Debate (P2P) | 고도의 추론, 수학 증명 및 팩트 체크. | 낮음 (토큰 소모 심함) | 높음 |
2. 상태 관리: 블랙보드 패턴 (The Blackboard Pattern)
단순한 다중 에이전트 시스템에서 에이전트들은 원시 채팅 기록(Raw chat histories)을 주고받으며 통신합니다. 이는 토큰의 기하급수적인 폭발을 초래합니다. 만약 에이전트 A와 에이전트 B가 각각 1,000토큰 길이의 메시지를 5번 주고받았다면, 리뷰어인 에이전트 C는 갑자기 10,000토큰 분량의 대화 기록을 떠안게 되며, 이 중 상당수는 대화형 노이즈(“알겠습니다, 지금 코드를 작성하겠습니다”)에 불과합니다.
이 문제를 해결하기 위해 최첨단 프레임워크들은 Blackboard Pattern 을 활용합니다. 에이전트 간 직접 메시징 대신, 에이전트들은 구조화된 산출물(Artifacts)을 중앙화된 “블랙보드(공유 메모리 공간)“에 게시합니다. 에이전트들은 자신의 역할과 관련된 블랙보드의 특정 파티션만 구독합니다.
MetaGPT 는 Standard Operating Procedures (SOPs) 를 강제하여 이를 선구적으로 구현했습니다. 에이전트들은 자유 형식의 텍스트를 교환하지 않고, 강력한 타입(Strongly typed)의 산출물(예: ProductRequirementDocument 객체 또는 APISpecification JSON)을 교환합니다. 이는 엄격한 상태 관리를 강제하고 컨텍스트 저하(Context degradation)를 방지합니다.
3. 잠재 공간 통신 엔지니어링 (Engineering Latent-Space Communication)
2026년 현재, 긴밀하게 결합된 에이전트 군집(Agent swarms)에서 텍스트 기반의 JSON 전달에만 의존하는 것은 연산적으로 비효율적이라고 간주됩니다. 중간 생각(Intermediate thoughts)을 텍스트로 디코딩(자기회귀 생성)하고 다음 에이전트의 컨텍스트 윈도우에서 다시 인코딩하는 과정은 막대한 컴퓨팅 자원을 낭비합니다.
최신 SOTA 접근법은 Latent-Space Communication (잠재 공간 통신 또는 신경망 메시지 전달) 입니다. 텍스트를 생성하는 대신, Worker 에이전트들은 밀집 은닉 표현(Dense hidden representations - 임베딩 또는 KV 캐시 블록)을 출력합니다. 그런 다음 Manager 에이전트는 교차 어텐션(Cross-Attention) 메커니즘을 사용하여 이러한 잠재 상태(Latent states)를 동적으로 쿼리하고, 현재 목표에 관련된 특징(Features)만 집계합니다.
PyTorch 구현: 다중 에이전트 어텐션 라우터
아래는 잠재 공간 라우터의 PyTorch 구현체입니다. 이 코드는 Manager 에이전트가 개의 Worker 에이전트들의 연속적인 잠재 상태에 어떻게 어텐션(Attention)을 가하는지 보여줍니다. 이는 텍스트 병목 현상을 우회하여 Manager 가 Worker 들의 “마음을 직접 읽을 수 있게” 해줍니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiAgentAttentionRouter(nn.Module):
"""
잠재 공간 기반 다중 에이전트 통신을 위한 신경망 라우터.
Manager 에이전트가 Cross-Attention을 사용하여 여러 Worker 에이전트의
은닉 상태(Hidden states)를 쿼리하고, 텍스트 디코딩 없이 인사이트를 집계합니다.
"""
def __init__(self, hidden_dim: int = 1024, num_heads: int = 8):
super().__init__()
self.hidden_dim = hidden_dim
# Cross-Attention: Manager가 Query, Worker들이 Key와 Value를 제공
self.cross_attention = nn.MultiheadAttention(
embed_dim=hidden_dim,
num_heads=num_heads,
batch_first=True
)
# 집계된 잠재 상태를 처리하기 위한 Feed-forward 네트워크
self.ffn = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim * 4),
nn.GELU(),
nn.Linear(hidden_dim * 4, hidden_dim)
)
self.layer_norm1 = nn.LayerNorm(hidden_dim)
self.layer_norm2 = nn.LayerNorm(hidden_dim)
def forward(self, manager_query: torch.Tensor, worker_states: torch.Tensor) -> torch.Tensor:
"""
Args:
manager_query: 형태 (Batch, Seq_Len_M, Hidden_Dim)의 텐서.
Manager 에이전트의 현재 잠재 상태.
worker_states: 형태 (Batch, Num_Workers * Seq_Len_W, Hidden_Dim)의 텐서.
모든 Worker 에이전트들의 잠재 상태를 연결(Concatenate)한 것.
Returns:
aggregated_state: 형태 (Batch, Seq_Len_M, Hidden_Dim)의 텐서.
Worker의 인사이트가 주입되어 업데이트된 Manager 상태.
"""
# Manager가 Worker들의 상태를 쿼리함
attn_output, attn_weights = self.cross_attention(
query=manager_query,
key=worker_states,
value=worker_states
)
# 잔차 연결(Residual connection) 및 LayerNorm
x = self.layer_norm1(manager_query + attn_output)
# 잔차 연결이 포함된 FFN
ffn_output = self.ffn(x)
aggregated_state = self.layer_norm2(x + ffn_output)
return aggregated_state, attn_weights
# --- 실행 예시 ---
if __name__ == "__main__":
batch_size = 2
hidden_dim = 1024
manager_seq_len = 16 # 예: Manager의 현재 생각 벡터 길이
worker_seq_len = 64 # 예: 각 Worker의 잠재 스크래치패드 길이
num_workers = 3 # 예: Coder, Searcher, QA
# 라우터 초기화
router = MultiAgentAttentionRouter(hidden_dim=hidden_dim, num_heads=8)
# Manager의 현재 잠재 상태 시뮬레이션
manager_query = torch.randn(batch_size, manager_seq_len, hidden_dim)
# 3명의 서로 다른 Worker로부터 온 잠재 상태 시뮬레이션
worker_1_state = torch.randn(batch_size, worker_seq_len, hidden_dim)
worker_2_state = torch.randn(batch_size, worker_seq_len, hidden_dim)
worker_3_state = torch.randn(batch_size, worker_seq_len, hidden_dim)
# Worker 상태들을 시퀀스 차원을 따라 연결하여 Key/Value 풀 생성
combined_worker_states = torch.cat([worker_1_state, worker_2_state, worker_3_state], dim=1)
# 형태(Shape): (2, 192, 1024)
# 라우팅 및 집계 수행
updated_manager_state, attention_map = router(manager_query, combined_worker_states)
print(f"Manager Query 형태: {manager_query.shape}")
print(f"결합된 Worker States 형태: {combined_worker_states.shape}")
print(f"업데이트된 Manager State 형태: {updated_manager_state.shape}")
print(f"Attention Map 형태: {attention_map.shape}")
# Attention Map 형태: (Batch, Manager_Seq, Total_Worker_Seq)이러한 API 수준의 오케스트레이션 에서 텐서 수준의 오케스트레이션 으로의 아키텍처 전환은 다중 에이전트 파운데이션 모델의 최전선을 정의합니다. 이는 사후 학습(Post-training) 단계에서 에이전트 군집 전체를 관통하는 End-to-end 역전파(Backpropagation)를 가능하게 하여, 에이전트들이 서로에게 어텐션을 가하는 방식을 최적화할 수 있게 합니다.
4. 인터랙티브 시각화: 에이전트 토폴로지 (Agent Topologies)
서로 다른 다중 에이전트 아키텍처에서 메시지와 상태 업데이트가 어떻게 흐르는지 직관적으로 이해하기 위해 아래의 인터랙티브 시각화 도구를 살펴보십시오. 토론(Debate) 토폴로지의 중복 검증 경로(Redundant verification paths)와 비교할 때, 계층형(Hierarchical) 토폴로지에서 어떻게 병목 현상이 발생하는지 관찰할 수 있습니다.
(참고: 프로덕션 환경에서는 위에서 보여준 비동기 라우팅을 처리하기 위해 LangGraph 와 같은 그래프 오케스트레이션 라이브러리나 시간적 상태 머신(Temporal state machines)이 사용됩니다.)
5. 미해결 과제와 앞으로의 방향
다중 에이전트 협업은 단일 에이전트의 페르소나 붕괴(Persona collapse)와 좁은 컨텍스트 문제를 해결합니다. SOPs 를 강제하고, 블랙보드 메모리를 활용하며, 잠재 공간 통신으로 전환함으로써 우리는 자율적으로 소프트웨어를 작성하고, 연구를 수행하며, 비즈니스를 운영할 수 있는 강력한 “지능의 사회(Societies of mind)“를 구축할 수 있습니다.
그러나 에이전트 군집이 며칠 또는 몇 주 동안 지속적으로 실행됨에 따라 새로운 문제가 대두됩니다. 에이전트 생태계는 한 달 전에 있었던 대화에서 사용자의 선호도를 어떻게 기억할까요? 매 세션마다 수백만 개의 토큰을 다시 읽지 않고도 장기적인 사실적 지식의 수명 주기를 어떻게 관리할 수 있을까요?
다음 섹션인 16.4 Long-term Memory for Agents 에서는 에이전트가 시간이 지남에 따라 지속되고 진화할 수 있도록 하는 메모리 계층 구조(벡터 데이터베이스, GraphRAG 통합, 그리고 지속적 평생 학습 아키텍처)에 대해 심도 있게 다룹니다.
Quizzes
Quiz 1: 환각(Hallucinations)을 줄이는 데 있어서 단일 에이전트의 자가 성찰보다 다중 에이전트 토론(Multi-agent debate)이 더 효과적인 이유는 무엇입니까?
자가 성찰을 하는 단일 에이전트는 확증 편향(Confirmation bias)에 빠지기 쉽습니다. 즉, 이후의 추론이 초기 출력에 크게 얽매이게 됩니다. 반면 다중 에이전트 토론은 서로 다른 에이전트에게 각기 다른 페르소나와 시스템 프롬프트를 할당하여, 물리적으로 분리된 컨텍스트 윈도우가 다양한 추론 경로를 생성하도록 강제합니다. 이러한 구조적 독립성은 시스템이 환각된 사실에 집단적으로 동의하는 것을 훨씬 더 어렵게 만듭니다.
Quiz 2: 계층형(Manager-Worker) 토폴로지에서 컨텍스트 윈도우 고갈의 주요 원인은 무엇이며, 블랙보드 패턴(Blackboard pattern)은 이를 어떻게 완화합니까?
컨텍스트 고갈은 Manager 에이전트가 일반적으로 모든 Worker 에이전트로부터 원시 대화 기록(Raw transcripts)을 수신하여 컨텍스트가 노이즈로 넘쳐날 때 발생합니다. 블랙보드 패턴은 직접적인 메시지 전달을 에이전트들이 구조화되고 강력한 타입의 산출물(예: JSON 요약이나 코드 블록)만을 게시하는 공유 메모리 공간으로 대체하여 이를 완화합니다. Manager는 최종 산출물만 읽으므로 토큰 오버헤드가 대폭 감소합니다.
Quiz 3: 에이전트 간 텍스트 기반 API 메시지 전달에 비해 잠재 공간 통신(Latent-Space Communication)이 가지는 근본적인 엔지니어링 이점은 무엇입니까?
텍스트 기반 통신은 송신 에이전트가 자신의 생각을 토큰으로 자기회귀적으로 디코딩하고, 수신 에이전트가 그 토큰을 다시 잠재 공간으로 인코딩해야 합니다. 이는 연산 비용이 많이 들고 미묘한 확률 정보를 잃게 만듭니다. 잠재 공간 통신은 텍스트를 완전히 우회하여 교차 어텐션(Cross-Attention)과 같은 메커니즘을 통해 연속적인 은닉 상태(임베딩 또는 KV 캐시)를 직접 전달하므로 속도가 더 빠르고 풍부한 의미론적 데이터를 보존합니다.
Quiz 4: MetaGPT의 SOPs(Standard Operating Procedures) 사용은 초기 대화형 에이전트 군집에서 자주 보이던 혼란스러운 시스템 붕괴를 어떻게 방지합니까?
초기 군집(예: 원시 AutoGen 루프)은 에이전트들이 자유롭게 대화하도록 허용했으며, 이는 종종 실제 작업은 생성하지 않은 채 정중하게 동의만 하는 무한 루프(“훌륭합니다, 동의합니다!”)로 이어졌습니다. SOPs는 에이전트가 구조화되지 않은 채팅을 출력하는 것을 금지하는 엄격한 기업 워크플로우를 강제합니다. 대신, 시퀀스의 다음 에이전트가 트리거되기 전에 구체적이고 실행 가능한 산출물(예: PRD, API 명세서)을 반드시 생성해야 합니다.
Quiz 5: 계층형 멀티 에이전트 시스템에서, 두 Worker 에이전트가 공유 블랙보드 메모리에 상충되는 산출물을 게시한 경우 Manager가 이를 해결해야 합니다. 상충되는 상태를 조정하기 위해 사용되는 명시적 논리 파라미터를 정식화하십시오.
충돌 해결은 가중 합성(Weighted synthesis) 시퀀스로 정식화됩니다. 의미론적 모순은 발산 임계값 방정식을 사용하여 채점됩니다: . 만약 인 경우 교차 어텐션 라우터는 중재 프롬프트(Arbitration Prompt)를 발동시킵니다. 이 프롬프트는 발산된 두 산출물을 전문가 보정 가중치 와 함께 순차적으로 컨텍스트에 입력하여, Manager가 전문가 페르소나 가중 우선순위의 균형을 수학적으로 조정한 합성 벡터를 도출하게 만듭니다: .
References
- Wu, Q., et al. (2023). AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv:2308.08155.
- Hong, S., et al. (2023). MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. arXiv:2308.00352.
- Du, Y., et al. (2023). Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv:2305.14325.
- Qian, C., et al. (2023). Communicative Agents for Software Development (ChatDev). arXiv:2307.07924.