10.5 Alignment Tax: 안전성의 숨겨진 청구서
사전 학습(Pre-training)은 파운데이션 모델에 방대한 세계 지식, 날것의 논리적 추론 능력, 그리고 다양한 언어적 표현력을 부여합니다. 반면, 이전 장들에서 다룬 정렬(Alignment) 과정(RLHF, DPO, KTO 등)은 모델이 유용하고(Helpful), 정직하며(Honest), 무해하도록(Harmless) 지식의 ‘표현 방식’을 엄격하게 제한합니다. 하지만 이 제한은 결코 공짜가 아닙니다.
안전성과 인간의 선호도를 추구하는 과정에서, 엔지니어들은 모델의 핵심 지능이 측정 가능할 정도로 저하되는 현상을 일관되게 관찰합니다. 이를 정렬 세금 (Alignment Tax) 이라 부릅니다. 모델에게 특정 페르소나를 강제하거나 특정 주제를 회피하도록 훈련시킬수록, 모델은 복잡한 수학 문제를 푸는 방법을 잊어버리고, 창의적인 엔트로피를 상실하며, 위험할 정도로 과도한 확신을 갖게 됩니다.
본 장에서는 정렬 세금 의 물리적 증상을 해부하고, 그 기저에 있는 수학적 원인을 분석하며, 이를 완화하기 위한 최첨단 엔지니어링 기법들을 구현해 보겠습니다.
1. 정렬 세금의 3대 증상
정렬 세금은 사후 학습(Post-training) 파이프라인에서 세 가지 뚜렷한 실패 모드로 발현됩니다.
A. 파국적 망각 (Catastrophic Forgetting)
가장 명백한 증상은 MMLU, HumanEval, GSM8K와 같은 표준 추론 벤치마크에서 제로샷(Zero-shot) 성능이 하락하는 것입니다. 베이스 모델(Base Model)은 복잡한 Python 스크립트를 완벽하게 작성할 수 있지만, RLHF를 거친 후에는 동일한 프롬프트에 대해 작성을 거부하거나, 코드를 너무 많이 축약해버리거나, 불필요한 대화형 문구(“물론입니다! 요청하신 코드는 다음과 같습니다…”)를 남발하다가 컨텍스트 윈도우를 소진해 버리기도 합니다. 모델이 논리적 엄밀함을 대화의 예의바름과 맞바꾼 결과입니다.
B. 선호도 붕괴 (Preference Collapse)
베이스 모델은 확률적 시뮬레이터입니다. 셰익스피어, 인터넷 커뮤니티 유저, 또는 Linux 터미널의 스타일로 텍스트를 생성할 수 있습니다. 그러나 정렬된 모델은 최근 연구에서 말하는 선호도 붕괴(preference collapse) 와 비슷한 실패 모드를 겪을 수 있습니다 [1]. 출력 분포가 보상(Reward)을 착취하기 쉬운 좁은 영역으로 붕괴해 버립니다. 보상 모델(Reward Model)이 무미건조하고 ‘AI 비서스러운’ 어조에 높은 점수를 주기 때문에, 정책 모델의 엔트로피는 급락합니다. 프롬프트에서 어떤 페르소나를 요구하든 상관없이, 모델은 창의적 다양성을 잃고 예측 가능하고 반복적인 어휘 구조로 회귀합니다.
C. 캘리브레이션 파괴 (Calibration Destruction)
베이스 모델은 자연적으로 캘리브레이션(Calibration)이 잘 되어 있습니다. 베이스 모델이 특정 토큰에 70%의 확률을 부여했다면, 역사적으로 그 토큰은 70%의 확률로 정답이었습니다. 즉, 모델은 “자신이 무엇을 아는지 정확히 알고” 있습니다. GPT-4 개발 당시, 연구진은 RLHF가 모델의 캘리브레이션을 완전히 파괴한다는 사실을 발견했습니다 [2]. 인간 라벨러들은 모델이 불확실성을 표현하는 것(“확실하지는 않지만, 정답은 ~인 것 같습니다”)에 페널티를 주기 때문에, 보상 모델은 단호하고 권위 있는 언어를 사용하도록 장려합니다. 그 결과, 정렬된 모델은 환각(Hallucination)을 내뱉을 때조차 100%의 수학적 확신을 가지게 되며, 내부의 확률 분포와 외부의 출력 어조가 완전히 분리되어 버립니다.
2. 근본적 원인 (The Root Causes)
출력 스타일을 약간 조정하는 것이 왜 기저의 추론 능력까지 파괴하는 것일까요? 그 해답은 최적화 역학과 신경망의 기하학에 있습니다.
- 보상 과적합 (Goodhart’s Law): 보상 모델은 복잡한 인간 선호도를 저차원으로 압축한 대리 지표(Proxy)에 불과합니다. PPO와 같은 강화학습 알고리즘이 이 지표를 극대화하려 할 때, 필연적으로 ‘꼼수(Hacks)‘를 발견하게 됩니다. 답변을 무조건 길게 쓰거나 특정 예의 바른 키워드를 사용하면 보상 점수가 인위적으로 부풀려진다는 것을 깨닫고, 표면적인 특성을 극대화하기 위해 논리적 정확성을 희생시킵니다.
- 연속 학습 간섭 (Continual Learning Interference): 시스템 관점에서 정렬(Alignment)은 연속 학습(Continual Learning) 문제입니다. 안전성 데이터셋(대화 턴, 거절 응답)의 분포는 사전 학습 데이터셋(웹 크롤링, GitHub 코드)의 분포와 근본적으로 다릅니다. RLHF 중에 경사 하강법(Gradient Descent)을 적용하면, 안전성을 위한 가중치 업데이트가 이전에 논리적 연역을 담당했던 Transformer 레이어의 가중치 행렬을 물리적으로 덮어써 버리게 됩니다 [3].
3. 엔지니어링 완화 기법 (Engineering Mitigations)
AI 연구자들은 안전성과 모델 성능 사이의 트레이드오프 곡선을 완화하기 위해 여러 기술을 개발했습니다.
A. KL 발산 페널티 (KL Divergence Penalty)
가장 기본적인 방어선은 이전 장들에서 다룬 KL 페널티입니다. 보상에 를 추가함으로써, 정렬된 정책()이 베이스 모델()에서 너무 멀어지지 않도록 강제합니다. 극단적인 모드 붕괴를 막아주긴 하지만, 이는 매우 투박한 도구입니다. 특정 추론 능력을 보호하기보다는 모델 전체를 전역적으로 억제할 뿐입니다.
B. 사전 학습 데이터 혼합 (PTX: Pre-Training Mix)
초기 InstructGPT 논문 [4] 에서 도입된 PTX 는 원본 사전 학습 데이터의 일부를 RLHF 학습 루프에 다시 섞어 넣는 기법입니다. PPO 업데이트를 진행할 때, 모델은 대화형 프롬프트에 대한 강화학습 그래디언트를 계산하는 동시에, 사전 학습 데이터 배치에 대해 표준 다음 토큰 예측(Cross-Entropy) 그래디언트를 함께 계산합니다. 이를 통해 모델이 지시사항(Instruction)을 따르는 법을 배우는 동안에도 일반적인 언어 모델링 능력을 유지하도록 강제합니다.
C. 모델 평균화 (Weight Interpolation)
추가 연산 없이(Zero-compute) 놀라운 효과를 내는 완화 기법은 가중치 보간 (Weight Interpolation) [5] 입니다. 를 사전 학습된 모델의 가중치, 을 RLHF 이후의 가중치라고 할 때, 두 가중치를 선형 보간하여 새로운 모델을 만들 수 있습니다: 미세 조정(Fine-tuning)은 일반적으로 사전 학습된 가중치 근처의 볼록한(Convex) 손실 분지 내에서 발생하기 때문에, 두 가중치를 평균 내는 것만으로도 정렬 속성의 대부분을 유지하면서 베이스 모델의 특징 다양성과 추론 능력을 복구할 수 있습니다.
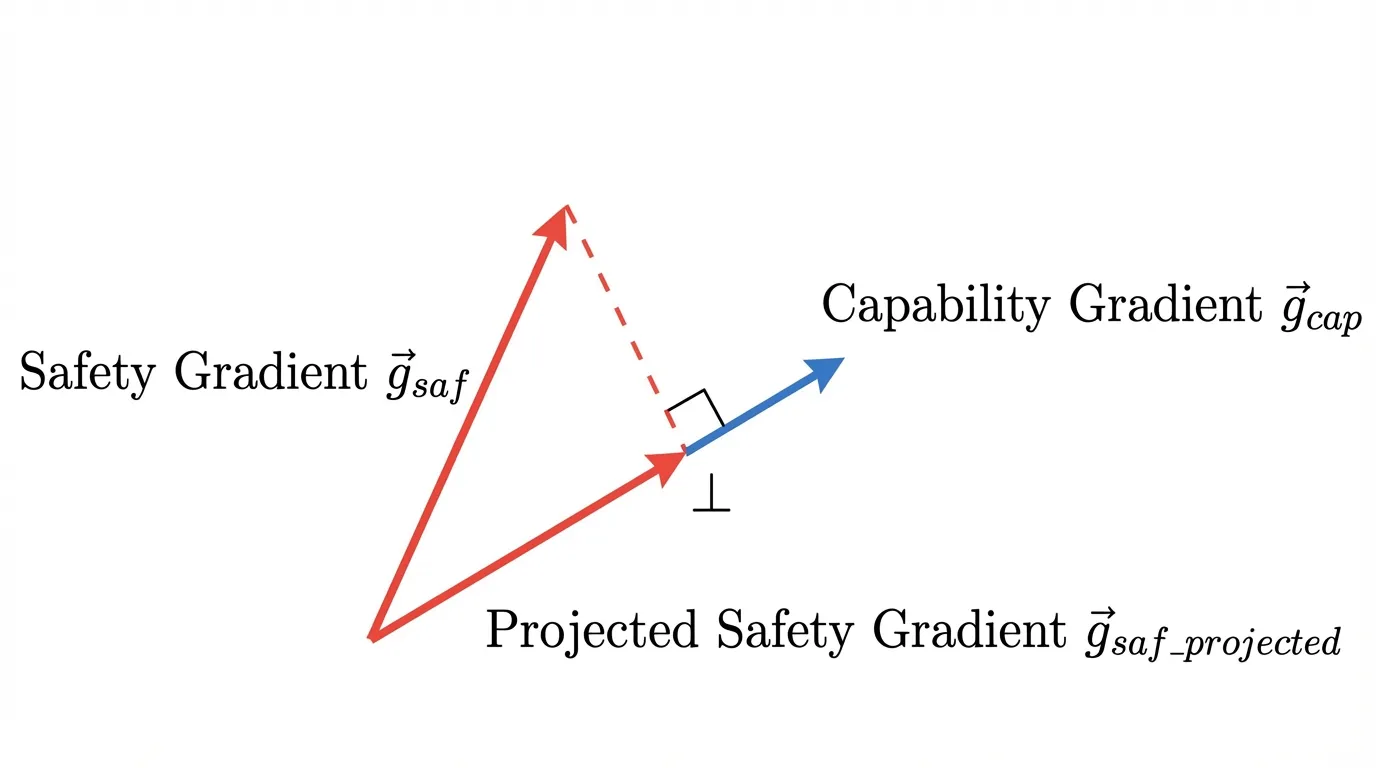
D. 직교 그래디언트 투영 (Orthogonal Gradient Projection)
정렬 세금을 완화하는 또 다른 계열의 접근법은 연속 학습(continual learning)에서 나온 투영 기반 기법을 가져오는 방식입니다 [6]. 이 기법은 안전성 그래디언트를 맹목적으로 적용하여 추론 능력을 덮어쓰는 대신, 두 그래디언트를 기하학적으로 분리합니다. 일반적인 추론 성능을 위한 그래디언트()와 안전성을 위한 그래디언트()를 각각 계산한 뒤, 안전성 그래디언트를 추론 그래디언트의 직교 여공간으로 투영합니다.
이상적인 경우에는 정렬 업데이트가 보호하고 싶은 능력 방향과 직교하도록 만들어, 핵심 추론 특성에 대한 직접적인 간섭을 줄여 줍니다.
 Source: Generated by Gemini
Source: Generated by Gemini
4. PyTorch 구현: 직교 그래디언트 투영
이제 이런 직교 그래디언트 투영 기법이 PyTorch 코드에서 어떻게 구현되는지 보겠습니다. 이 기술은 두 번의 독립적인 역전파(Backward pass)를 수행해 그래디언트를 평탄화(Flatten)한 뒤, 벡터 투영 연산을 수행하고 옵티마이저가 스텝을 밟기 전에 파라미터 그래디언트를 다시 채워 넣는 과정을 거칩니다.
import torch
import torch.nn as nn
def orthogonal_gradient_projection(
model: nn.Module,
safety_loss: torch.Tensor,
capability_loss: torch.Tensor
):
"""
안전성 그래디언트를 추론(Capability) 그래디언트의 직교 여공간으로 투영합니다.
정렬 세금(Alignment Tax)을 방지하기 위해 모델의 그래디언트를 제자리(in-place)에서 수정합니다.
"""
# 1. 추론 그래디언트 계산 (보존해야 할 "방해 금지" 방향)
model.zero_grad()
capability_loss.backward(retain_graph=True)
cap_grads = []
for param in model.parameters():
if param.grad is not None:
cap_grads.append(param.grad.view(-1))
if not cap_grads:
return # 투영할 그래디언트가 없음
g_cap = torch.cat(cap_grads)
# 2. 안전성 그래디언트 계산 (정렬 업데이트 방향)
model.zero_grad()
safety_loss.backward()
saf_grads = []
for param in model.parameters():
if param.grad is not None:
saf_grads.append(param.grad.view(-1))
g_saf = torch.cat(saf_grads)
# 3. 직교 투영 연산: g_saf_proj = g_saf - proj_{g_cap}(g_saf)
# 수학 공식: proj_u(v) = (v dot u / ||u||^2) * u
dot_product = torch.dot(g_saf, g_cap)
norm_sq = torch.dot(g_cap, g_cap) + 1e-8 # 수치적 안정성을 위한 epsilon 추가
projection = (dot_product / norm_sq) * g_cap
g_saf_projected = g_saf - projection
# 4. 투영된 그래디언트를 모델 파라미터에 다시 적용
idx = 0
for param in model.parameters():
if param.grad is not None:
numel = param.numel()
# 1차원으로 평탄화된 그래디언트를 원래 텐서 형태로 복구(Reshape)
param.grad.copy_(g_saf_projected[idx:idx + numel].view_as(param))
idx += numel
# 이제 안전하게 옵티마이저(예: AdamW)의 step()을 호출할 수 있습니다.5. Interactive: 정렬 세금 트레이드오프 시뮬레이션
아래의 시각화 도구를 사용하여 다양한 완화 전략이 파운데이션 모델의 파레토 프론티어(Pareto Frontier)에 어떤 영향을 미치는지 직접 실험해 보십시오. PTX(Pre-Training Mix)나 직교 투영(Orthogonal Projection) 기법을 사용하면 기초 성능(Capability)을 보존하는 데 유리하지만, 목표로 하는 안전성(Safety) 수준에 도달하기 위해 최적화 스텝이 어떻게 달라지는지 관찰해 보시기 바랍니다.
Alignment Strategy
(Pareto Optimal)
Safety: 52.5
요약 및 다음 단계
정렬 세금 (Alignment Tax) 은 현대 AI 시대의 근본적인 엔지니어링 트레이드오프, 즉 ‘날것의 지능’과 ‘인간을 위한 안전성’ 사이의 균형을 상징합니다. 우리는 이 세금이 모드 붕괴와 파국적 망각으로 어떻게 나타나는지, 그리고 PTX 혼합이나 직교 그래디언트 투영과 같은 정교한 기술들이 어떻게 이러한 한계를 극복하게 해주는지 살펴보았습니다.
이것으로 Chapter 10: Alignment 를 마칩니다. 우리는 인간 피드백의 기초부터 DPO의 수학적 우아함, 그리고 정렬 세금의 복잡한 기하학까지 긴 여정을 지나왔습니다.
다음 장인 Chapter 11: Multimodal Learning 에서는 텍스트 전용 도메인을 넘어설 것입니다. 파운데이션 모델이 어떻게 서로 다른 데이터 모달리티 사이의 간극을 연결하고, CLIP과 같은 Vision-Language 아키텍처를 통해 ‘보는 법’을 배우며, 네이티브하게 소리를 ‘듣고 이해하는지’ 탐구할 것입니다.
Quizzes
Quiz 1: RLHF가 모델의 캘리브레이션(Calibration)을 파괴하여, 환각(Hallucination) 상태에서도 과도한 확신을 갖게 만드는 이유는 무엇입니까?
인간 라벨러들은 본능적으로 단호하고 권위 있게 들리는 답변을 선호하며, 주저하거나 불확실성을 표현하는 응답에 페널티를 주는 경향이 있습니다. 보상 모델(Reward Model)은 이러한 편향을 학습하여 정책 모델이 절대적인 확신을 가지고 텍스트를 생성하도록 장려합니다. 그 결과, 모델 외부로 표출되는 어조가 내부의 실제 확률 분포와 분리되면서 자연스러운 캘리브레이션이 파괴됩니다.
Quiz 2: 모델 평균화(Weight Interpolation) 기법은 어떻게 추가적인 학습 연산(Compute) 없이 정렬 세금을 완화합니까?
RLHF와 같은 미세 조정은 일반적으로 사전 학습된 가중치 근처의 볼록한(Convex) 손실 분지 내에서 이루어집니다. 사전 학습된 가중치와 정렬된 가중치를 선형 보간(Linear interpolation)함으로써, 우리는 두 피처(Feature) 표현을 효과적으로 평균 냅니다. 단순한 스칼라 곱셈 연산만으로, 정렬 속성을 유지하는 데 필요한 안전성 벡터를 보존하면서 동시에 베이스 모델의 다양한 피처 공간을 복원하여 핵심 추론 능력을 회복할 수 있습니다.
Quiz 3: 직교 그래디언트 투영(Orthogonal Gradient Projection)에서 안전성 그래디언트와 추론 그래디언트가 완벽하게 평행(Parallel)하다면 수학적으로 어떤 일이 발생합니까?
두 벡터가 완벽하게 평행하다면, 안전성 그래디언트를 추론 그래디언트 위로 투영한 값은 안전성 그래디언트 자체와 동일해집니다. g_saf_projected = g_saf - projection 공식에 따라 결과는 영벡터(Zero vector)가 됩니다. 즉, 모델은 해당 배치(Batch)에 대해 가중치를 전혀 업데이트하지 않으며, 안전성 학습을 포기하는 대신 추론 능력을 완벽하게 보존하는 선택을 하게 됩니다.
Quiz 4: 논리적 추론 작업에서 발생하는 정렬 세금을 막기 위해 표준 KL 발산 페널티(KL divergence penalty)만 사용하는 것이 불충분한 이유는 무엇입니까?
KL 페널티는 전역적인 분포 수준(Distribution-level)의 제약입니다. 정렬된 모델의 전체 출력 확률이 베이스 모델과 가깝게 유지되도록 강제하지만, ‘스타일’ 토큰과 ‘추론’ 토큰을 구분하지 못합니다. 모델은 단순히 베이스 모델의 어휘 분포를 모방하여 KL 제약 조건을 만족시키면서도, 다단계 논리적 연역에 필요한 특정 네트워크 가중치는 물리적으로 덮어써 버릴 수 있기 때문입니다.
References
- Xiao, J., Li, Z., Xie, X., Getzen, E., Fang, C., Long, Q., & Su, W. J. (2024). On the Algorithmic Bias of Aligning Large Language Models with RLHF: Preference Collapse and Matching Regularization. arXiv:2405.16455.
- OpenAI. (2023). GPT-4 Technical Report. arXiv. arXiv:2303.08774.
- Lin, Y., et al. (2024). Mitigating the Alignment Tax of RLHF. arXiv. arXiv:2309.06256.
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. arXiv. arXiv:2203.02155.
- Askell, A., et al. (2021). A General Language Assistant as a Laboratory for Alignment. arXiv. arXiv:2112.00861.
- Lin, S., Yang, L., Fan, D., & Zhang, J. (2022). TRGP: Trust Region Gradient Projection for Continual Learning. arXiv:2202.02931.