2.2 기울기 소실 및 폭주 (Vanishing & Exploding Gradients)
순환 신경망(RNN)은 이론적으로 긴 시퀀스를 처리할 수 있는 능력을 갖추고 있지만, 기울기 소실(Vanishing Gradient) 및 기울기 폭주(Exploding Gradient) 문제로 인해 이들을 효과적으로 학습시키는 것은 딥러닝에서 가장 큰 과제 중 하나였습니다.
동기: 장기 신용 할당의 어려움 (The Difficulty of Long-Term Credit Assignment)
2시간 전에 제공된 힌트가 필요한 퍼즐을 풀려고 하는데, 그 이후로 새로운 정보가 계속해서 쏟아진다고 상상해 보세요.
- 기울기 소실 (Vanishing Gradients) 은 모델이 먼 과거를 잊게 만듭니다. 업데이트를 위한 신호가 너무 작아져서 모델이 시퀀스의 앞부분으로부터 학습하는 것을 멈춥니다.
- 기울기 폭주 (Exploding Gradients) 는 모델이 과도하게 반응하게 만듭니다. 먼 과거의 작은 변화가 현재에 거대하고 혼란스러운 변화를 일으켜 학습을 불안정하게 만듭니다.
이 문제는 장기 종속성을 훨씬 더 잘 처리하는 LSTM과 결과적으로 트랜스포머의 탄생을 촉발했습니다.
비유: 전화 놀이(소실)와 눈덩이 효과(폭주)
50명의 사람들이 줄을 서서 전화 놀이(귓속말 전하기) 를 하고 있다고 상상해 보세요.
- 기울기 소실 은 메시지가 각 단계를 거칠 때마다 점점 더 작아지고 알아듣기 어렵게 되는 것과 같습니다. 50번째 사람에게 도달할 때쯤에는 그저 희미하고 이해할 수 없는 속삭임일 뿐입니다. 마지막 사람은 첫 번째 사람의 메시지로부터 유용한 정보를 전혀 배울 수 없습니다.
- 기울기 폭주 는 처음에 작은 소문(“비가 올지도 모른대”)으로 시작하는 것과 같습니다. 줄을 따라 전달되면서 사람들이 각자 과장하기 시작합니다. 50번째 사람에게 도달했을 때는 “거대한 허리케인이 도시를 파괴하고 있대!”로 변해 있습니다. 신호가 겉잡을 수 없이 커져 버린 것입니다.
근본 원인: 시간에 따른 역전파 (BPTT)
RNN은 역전파의 확장인 시간에 따른 역전파 (BPTT, Backpropagation Through Time) 를 사용하여 학습됩니다. 네트워크는 시간 단계에 따라 펼쳐지고, 기울기는 출력에서부터 시작하여 처음으로 거슬러 올라가며 계산됩니다.
은닉 상태 가중치 행렬 에 대한 업데이트를 고려해 보겠습니다. 기울기는 시간 단계에 따른 행렬 곱셈의 체인을 포함합니다:
만약 의 고유값(eigenvalues)이 1보다 작으면, 이를 반복적으로 곱함으로써 기울기가 기하급수적으로 감소합니다 (기울기 소실). 반대로 1보다 크면 기울기가 기하급수적으로 증가합니다 (기울기 폭주).
결과
- 기울기 소실: 초기 시간 단계의 신호가 가중치를 업데이트하기에 너무 약해져서 네트워크가 장기 종속성을 학습할 수 없습니다.
- 기울기 폭주: 업데이트가 너무 커져 가중치가 진동하거나
NaN(Not a Number)이 되어 학습이 불안정해집니다.
기울기 소실 시뮬레이션
BPTT에서 연쇄 법칙을 모방하여 1보다 작은 가중치 값을 반복적으로 곱함으로써 기울기가 어떻게 사라지는지 시뮬레이션할 수 있습니다.
import torch
# 가중치 미분값 시뮬레이션 (활성화 함수 미분값 * 가중치)
# 이 값이 < 1이면 소실되고, > 1이면 폭주합니다.
w_derivative = 0.9
# 시퀀스 길이
seq_len = 50
gradient = 1.0
gradients = []
for t in range(seq_len):
gradient *= w_derivative
gradients.append(gradient)
print(f"1단계에서의 기울기: {gradients[0]:.4f}")
print(f"25단계에서의 기울기: {gradients[24]:.4f}")
print(f"50단계에서의 기울기: {gradients[49]:.4f}")
import matplotlib.pyplot as plt
plt.plot(gradients)
plt.title("Vanishing Gradient Simulation")
plt.xlabel("Backprop Steps (Time)")
plt.ylabel("Gradient Magnitude")
plt.show()예제: 기울기 흐름 시각화
가중치 크기를 조절하여 시간이 지남에 따라 역전파되는 기울기에 어떤 영향을 미치는지 확인해 보세요.
- 보다 작은 값은 기울기를 소실 시킵니다.
- 보다 큰 값은 기울기를 폭주 시킵니다.
기울기 소실 및 폭주 시뮬레이터
가중치 스케일을 조절하여 역전파 중에 기울기가 레이어를 거치며 어떻게 줄어들거나 커지는지 확인하세요.
레이어 i에서의 공식: 기울기는 W^(5-i)에 비례합니다.
기울기 소실: 초기 레이어로 갈수록 기울기가 기하급수적으로 줄어듭니다.
해결책: LSTM 및 GRU - 기억의 통제
기울기 소실 문제를 해결하기 위해 단순히 과거의 정보를 더 많이 전달하는 것뿐만 아니라, 무엇을 기억하고 무엇을 잊을지를 스스로 학습하는 똑똑한 메모리 시스템이 필요했습니다. 이를 위해 개발된 대표적인 아키텍처가 LSTM (Long Short-Term Memory) 과 GRU (Gated Recurrent Unit) 입니다.
LSTM: 장단기 메모리 (Long Short-Term Memory)
1997년 Sepp Hochreiter와 Jürgen Schmidhuber는 기울기 소실 문제를 해결하기 위해 LSTM을 제안했습니다. Sepp Hochreiter는 이미 1991년 그의 졸업 논문에서 기울기 소실 문제의 원인을 규명한 바 있습니다.
직관적 해석: 컨베이어 벨트로서의 셀 상태
LSTM의 핵심 혁신은 셀 상태(Cell State, ) 의 도입입니다. 기존 RNN의 은닉 상태()가 매 단계마다 복잡한 비선형 변환을 거치며 정보가 손실되거나 왜곡되는 것과 달리, 셀 상태는 일종의 선형 컨베이어 벨트 역할을 합니다. 정보는 이 벨트를 타고 큰 변화 없이 미래로 흘러갈 수 있습니다.
LSTM은 세 가지 “게이트”를 사용하여 셀 상태를 제어합니다:
- 망각 게이트 (Forget Gate): 셀 상태에서 어떤 정보를 버릴지 결정합니다.
- 입력 게이트 (Input Gate): 셀 상태에 어떤 새로운 정보를 저장할지 결정합니다.
- 출력 게이트 (Output Gate): 셀 상태의 어떤 부분을 은닉 상태로 출력할지 결정합니다.
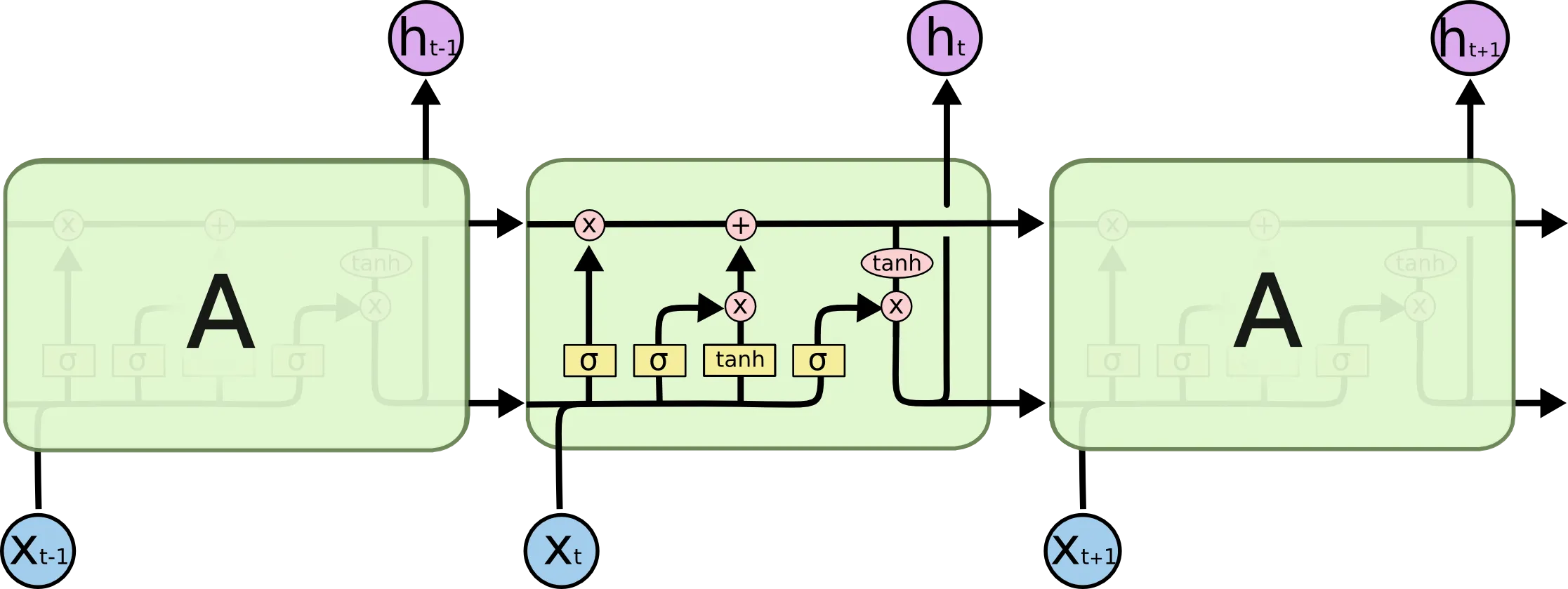
수학적 해석: 기울기 소실을 막는 원리
기존 RNN에서는 기울기가 다음과 같이 가중치 행렬의 거듭제곱 형태로 전달되었습니다:
반면 LSTM에서 셀 상태의 역전파는 다음과 같습니다: 여기서 는 망각 게이트(Forget Gate)의 출력값(0~1 사이)입니다. 만약 네트워크가 해당 정보를 기억해야 한다고 학습하여 이 된다면, 기울기는 감쇠 없이 그대로 과거로 전달됩니다. 즉, 활성화 함수의 미분값이나 가중치 행렬이 곱해지지 않아 기울기 소실이 발생하지 않습니다.
비유로 이해하기
LSTM은 일기장과 같습니다.
- 망각 게이트: “어제 먹은 점심 메뉴처럼 사소한 건 지우자.” (과거 기억 삭제)
- 입력 게이트: “오늘 새로 배운 중요한 공식은 기록하자.” (새로운 정보 추가)
- 출력 게이트: “이 일기 내용을 바탕으로 오늘 일기를 요약해서 친구에게 말해주자.” (현재 상태 출력)
GRU: 게이트 순환 유닛 (Gated Recurrent Unit)
2014년 조경현 교수 등이 제안한 GRU는 LSTM의 복잡한 구조를 단순화한 모델입니다.
특징
- 망각 게이트와 입력 게이트를 하나의 업데이트 게이트로 통합했습니다.
- 셀 상태와 은닉 상태를 하나로 합쳐 구조가 더 단순합니다.
- 파라미터 수가 적어 연산량이 적고, 데이터가 적은 상황에서 LSTM보다 우수한 성능을 보이기도 합니다.

RNN vs LSTM vs GRU 비교
| 특징 | 표준 RNN | LSTM | GRU |
|---|---|---|---|
| 구조 | 단순함 (1개의 tanh 레이어) | 복잡함 (4개의 상호작용 레이어) | 중간 (3개의 상호작용 레이어) |
| 메모리 메커니즘 | 은닉 상태만 존재 | 셀 상태 + 은닉 상태 | 은닉 상태만 존재 (통합됨) |
| 게이트 수 | 없음 | 3개 (Forget, Input, Output) | 2개 (Reset, Update) |
| 장기 종속성 해결 | 어려움 (기울기 소실) | 매우 우수 | 우수 |
| 연산 속도 | 빠름 | 느림 | 중간 |
| 파라미터 수 | 가장 적음 | 가장 많음 | 중간 |
Quizzes
Quiz 1: 왜 연쇄 법칙(chain rule)이 피드포워드 네트워크보다 RNN에서 기울기 소실을 더 심하게 유발합니까?
RNN에서는 모든 시간 단계에서 동일한 가중치 행렬 가 반복적으로 곱해집니다. 피드포워드 네트워크에서는 레이어마다 다른 가중치 행렬을 가지므로 동일한 값의 반복 곱셈 효과가 덜 뚜렷합니다 (하지만 매우 깊은 피드포워드 네트워크에서도 기울기 소실은 발생하며, 이는 ResNet의 개발로 이어졌습니다).
Quiz 2: LSTM의 셀 상태(Cell State)는 기울기 소실을 방지하는 데 어떻게 도움이 됩니까?
셀 상태 업데이트는 매 단계마다 비선형 활성화 함수를 거치지 않고 주로 선형적(망각 게이트의 곱셈과 입력의 덧셈)으로 이루어집니다. 이를 통해 기울기가 매 시간 단계마다 축소되는 미분값과 곱해지지 않고 셀 상태를 통해 역전파될 수 있습니다.
Quiz 3: Gradient Clipping은 무엇이며 어떤 문제를 해결합니까?
Gradient Clipping은 기울기 폭주를 방지하기 위해 사용되는 기술입니다. 기울기의 노름(norm)이 특정 임계값을 초과하면 해당 임계값으로 크기를 축소합니다. 이를 통해 업데이트가 너무 커져 학습이 불안정해지는 것을 방지합니다.
Quiz 4: 기울기 소실과 관련하여 심층 신경망에서 시그모이드(Sigmoid)보다 ReLU와 같은 활성화 함수가 선호되는 이유는 무엇인가요?
시그모이드 함수의 미분값은 최대 0.25입니다. 연쇄 법칙에서 이러한 미분값을 곱하면 기울기가 빠르게 0으로 수렴합니다. 반면 ReLU의 미분값은 양수 입력에 대해 1이므로, 곱해지더라도 기울기를 축소시키지 않습니다.
Quiz 5: LSTM과 GRU의 가장 큰 차이점은 무엇인가요?
LSTM은 세 가지 게이트(망각, 입력, 출력)를 가지며 셀 상태와 은닉 상태를 별도로 유지합니다. GRU는 두 개의 게이트(리셋, 업데이트)만을 가진 더 단순한 구조이며 셀 상태와 은닉 상태를 병합했습니다. GRU는 계산상 더 효율적이면서도 종종 유사한 성능을 달성합니다.
Quiz 6: 기울기 폭발(Exploding Gradients)을 방지하기 위해 재귀 가중치 행렬 의 스펙트럼 반지름(Spectral Radius) 이 만족해야 하는 필요조건을 기술하고 수학적으로 정당화하시오.
기울기 폭발을 방지하기 위한 필요조건은 재귀 가중치 행렬의 스펙트럼 반지름이 을 만족해야 하는 것입니다. 스펙트럼 반지름은 행렬 고유값(Eigenvalue)들의 최대 절대값으로 정의됩니다: 。 BPTT 과정에서 기울기는 야코비안 행렬의 연속된 곱으로 표현됩니다: . tanh와 같은 활성화 함수의 경우 미분값은 을 만족합니다. 따라서 곱의 노름(Norm)은 로 상한선이 정해집니다. 만약 스펙트럼 반지름 이면, 시퀀스 길이가 무한대로 갈 때 항이 기하급수적으로 증가하여 기울기 폭발을 유발합니다. 따라서 안정성을 위한 필요조건으로 이 요구됩니다.
References
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
- Cho, K., et al. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv:1406.1078.
- Pascanu, R., Mikolov, T., & Bengio, Y. (2013). On the difficulty of training recurrent neural networks. arXiv:1211.5063.