10.4 KTO & IPO: DPO의 한계와 진화
DPO (Direct Preference Optimization)는 AI 정렬(Alignment) 기술에 있어 중요한 분수령이었습니다. 보상 모델(Reward Model)이 정책(Policy) 자체에서 암묵적으로 도출될 수 있음을 수학적으로 증명함으로써, 엔지니어들은 악명 높게 불안정한 강화학습(PPO) 루프를 완전히 우회할 수 있게 되었습니다.
하지만 DPO 알고리즘이 학술적 벤치마크를 넘어 대규모 실제 서비스 환경에 배포되면서, 두 가지 치명적인 엔지니어링 병목 현상이 드러났습니다.
- 과적합의 덫 (The Overfitting Trap): DPO 의 손실 함수는 하한선이 없습니다(Unbounded). 모델이 선택된 답변(Chosen)과 거절된 답변(Rejected) 사이의 확률 격차(Margin)를 무한대로 벌리도록 지속적으로 보상을 제공합니다. 이로 인해 모델의 엔트로피가 파괴되고, 다양성을 잃은 채 뻔하고 기계적인 답변만 반복하는 모드 붕괴(Mode Collapse) 현상이 발생합니다.
- 데이터 수집 비용 (The Data Acquisition Cost): 수학적으로 DPO 기법은 반드시 쌍으로 이루어진 선호도 데이터 ()를 요구합니다. 사용자가 단순히 ‘좋아요’나 ‘싫어요’ 버튼을 누르는 단일 피드백에 비해, 두 개의 답변을 비교하고 평가하는 고품질 쌍방향 데이터를 수집하는 것은 기하급수적으로 비싸고 어렵습니다.
이러한 물리적, 경제적 제약을 해결하기 위해 차세대 정렬 알고리즘들이 개발되었습니다. 본 장에서는 DPO 의 수학적 한계를 수정한 IPO (Identity Preference Optimization) 와, 쌍방향 데이터의 필요성을 완전히 제거한 KTO (Kahneman-Tversky Optimization) 에 대해 깊이 있게 다룹니다.
1. DPO의 수학적 결함
새로운 알고리즘이 왜 필요했는지 이해하기 위해, 먼저 DPO 의 손실 함수를 살펴보겠습니다.
괄호 안의 수식을 암묵적 보상 격차 (Implicit Reward Margin) 인 이라고 정의해 봅시다. 손실 함수는 단순하게 으로 표현됩니다.
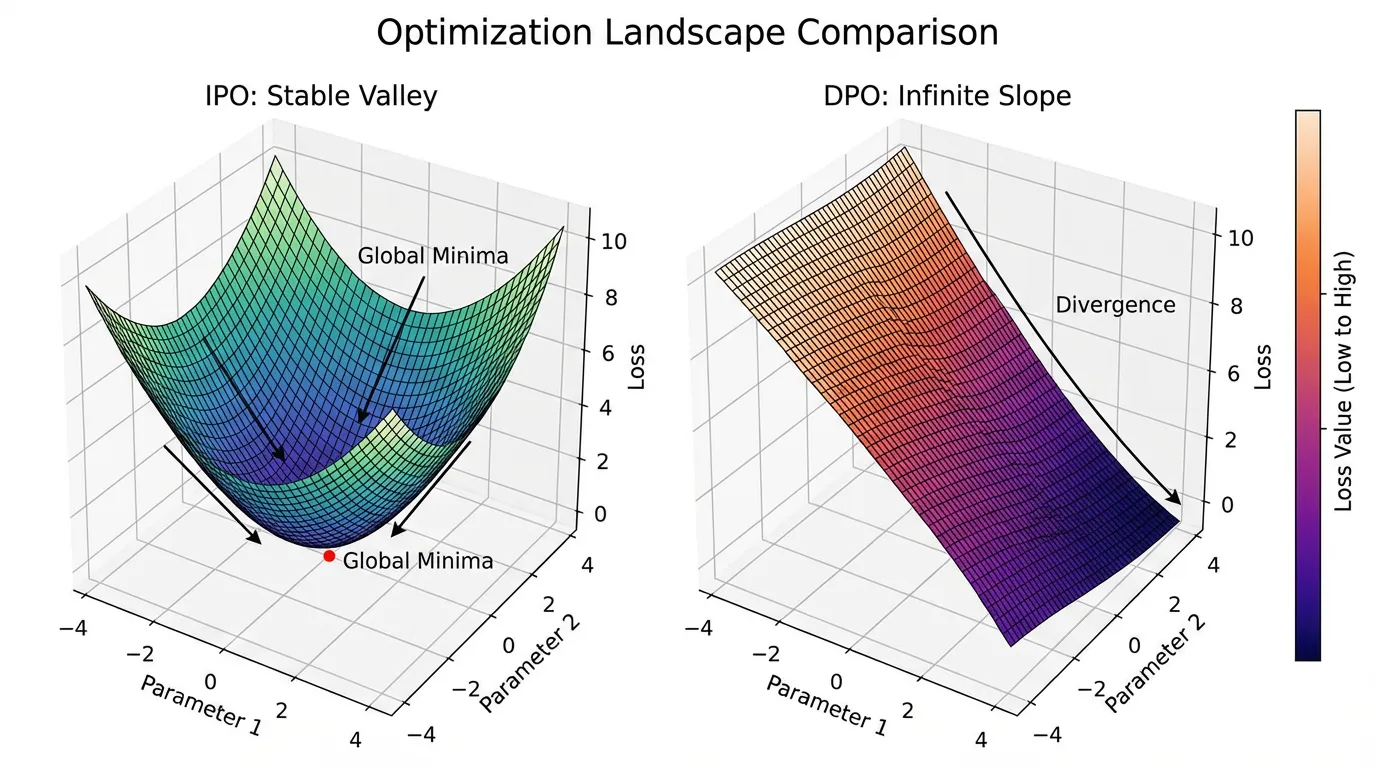
시그모이드 함수 는 일 때만 에 수렴하므로, DPO 의 손실은 격차 일 때만 에 도달합니다. 즉, 모델은 정답(Chosen)의 확률을 오답(Rejected)보다 ‘무한히’ 높게 만들 때까지 끊임없이 가중치를 업데이트합니다. 실제 환경에서 데이터셋에 확정적이거나 약간의 노이즈가 있는 쌍이 포함되어 있다면, DPO 모델은 공격적으로 과적합(Overfit)됩니다. 창의적이고 다양한 텍스트 생성을 멈추고, 가장 안전하고 경직된 패턴으로 붕괴해 버립니다.
2. IPO: Identity Preference Optimization
Google DeepMind의 연구진은 이 과적합 문제를 직접적으로 해결하기 위해 IPO [1] 알고리즘을 발표했습니다. IPO 의 핵심 아이디어는 단순하지만 강력합니다. “우리는 보상 격차가 무한대로 가는 것을 원하지 않는다. 단지 충분히 크기를 바랄 뿐이다.”
IPO 기법은 로지스틱 손실 대신 항등 함수(Identity function, 즉 평균 제곱 오차)를 사용합니다.
IPO의 “Aha!” 모먼트
제곱항인 를 자세히 살펴보십시오.
이 손실 함수의 절대적인 최솟값은 마진 이 정확히 일 때 발생합니다.
- 모델이 두 답변을 충분히 분리하지 못했다면, 손실은 큽니다.
- 모델이 두 답변을 정확히 만큼 분리했다면, 손실은 0이 됩니다.
- 결정적으로, 모델이 과도하게 확신을 가져 마진을 보다 더 크게 벌리면, 손실은 다시 증가합니다.
IPO 알고리즘은 모델이 “너무 과하게 정답을 맞히는 것”을 적극적으로 페널티 줍니다. 이 내장된 정규화(Regularization) 효과 덕분에 로짓(Logits)이 폭발하는 것을 막고, 모델의 엔트로피를 보존하여 모드 붕괴를 방지합니다.
DPO vs IPO Loss Landscape
Adjust $\beta$ to see how the optimal margin shifts.
3. KTO: Kahneman-Tversky Optimization
IPO 모델이 DPO 의 수학적 문제를 해결했지만, 여전히 쌍으로 된(Pairwise) 데이터가 필요하다는 근본적인 한계는 남아있습니다. 현실 세계에서 쌍방향 데이터를 수집하는 것은 악몽에 가깝습니다. 챗봇 사용자는 두 개의 긴 답변을 읽고 어느 것이 더 나은지 채점하고 싶어 하지 않습니다. 그들은 단지 자신이 받은 단일 답변에 👍 또는 👎 를 누를 뿐입니다.
Contextual AI는 오직 단일 이진 피드백 (Pointwise Binary Feedback) () 만을 사용하여 모델을 정렬할 수 있는 KTO [2] 방법론을 도입했습니다.
전망 이론 (Prospect Theory)과 인간의 편향
KTO 이론은 노벨 경제학상을 수상한 대니얼 카너먼(Daniel Kahneman)과 아모스 트버스키(Amos Tversky)의 행동 경제학 이론인 전망 이론에 기반을 두고 있습니다. 이 이론의 핵심은 손실 회피 (Loss Aversion) 입니다. 인간은 100달러를 얻었을 때의 기쁨보다 100달러를 잃었을 때의 고통을 훨씬 강렬하게 느낍니다.
기존의 정렬 알고리즘들은 인간이 완벽하게 이성적인 보상 극대화자라고 가정했습니다. 반면 KTO 기법은 인간의 인지적 편향을 명시적으로 모델링한 HALO (Human-Aware Loss) 를 도입합니다. 선호도 쌍의 우위를 최적화하는 대신, 기준점(Reference point) 대비 생성된 답변의 효용(Utility)을 최적화합니다.
KTO의 목적 함수
단일 생성에 대한 암묵적 보상을 라고 정의합시다. 를 기준점이라고 하며, 이는 일반적으로 배치(Batch) 내에서 정책 모델과 참조 모델 간의 예상 KL 발산(KL Divergence) 값으로 설정됩니다.
KTO 손실 함수는 다음과 같이 정의됩니다:
여기서 와 는 손실 회피의 정도를 제어하는 하이퍼파라미터입니다 (일반적으로 나쁜 출력에 더 큰 페널티를 주기 위해 로 설정합니다).
KTO 알고리즘은 움직이는 기준선()에 대해 각 생성을 독립적으로 평가하기 때문에, 와 쌍이 전혀 필요하지 않습니다. 복잡한 매칭 로직 없이, 10,000개의 “좋아요”와 2,000개의 “싫어요”가 있는 불균형한 데이터셋에서도 모델을 성공적으로 학습시킬 수 있습니다.
 Source: Generated by Gemini
Source: Generated by Gemini
4. cDPO: Conservative DPO
마지막으로 알아두어야 할 실용적인 변형은 cDPO (Conservative DPO) 입니다. 인간 라벨러(Annotator)들은 일관성이 매우 떨어집니다. 연구에 따르면 선호도 쌍에 대한 인간의 동의율은 종종 60-70% 수준에 불과합니다. 이는 데이터셋에 라벨 노이즈 (Label Noise) 가 포함되어 있음을 의미합니다. 거절된 답변이 실제로는 더 나았지만, 작업자가 실수를 했거나 주관적인 편향이 개입된 경우입니다.
cDPO 기법은 선호도 라벨이 뒤집혔을 확률 이 존재한다고 가정하고, 이 불확실성을 반영하여 DPO 손실을 수정합니다:
라벨이 뒤집혔을 가능성을 명시적으로 주입함으로써, cDPO 모델은 단일 선호도 쌍을 너무 맹신하는 것을 방지합니다. 결과적으로 노이즈가 많은 데이터셋에서도 훨씬 부드럽고 안정적으로 수렴하게 됩니다.
5. PyTorch 구현
이러한 우아한 수학적 개념들이 실제 실행 가능한 PyTorch 코드로 어떻게 변환되는지 살펴보겠습니다. 세 가지 알고리즘 모두 동일한 기반의 로그 확률(Log-probability) 텐서를 사용하며, 단지 이를 조작하는 방식만 다르다는 점에 주목하십시오.
import torch
import torch.nn.functional as F
def ipo_loss(
policy_chosen_logps: torch.Tensor, policy_rejected_logps: torch.Tensor,
ref_chosen_logps: torch.Tensor, ref_rejected_logps: torch.Tensor,
beta: float = 0.1
) -> torch.Tensor:
"""Identity Preference Optimization (IPO) Loss"""
# 암묵적 보상 격차(Implicit reward margin) 계산
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = ref_chosen_logps - ref_rejected_logps
logits = pi_logratios - ref_logratios
# IPO는 마진이 1 / (2 * beta) 일 때 정확히 최솟값 0을 갖도록 강제합니다.
loss = (logits - 1.0 / (2.0 * beta)) ** 2
return loss.mean()
def kto_loss(
policy_logps: torch.Tensor, ref_logps: torch.Tensor,
labels: torch.Tensor, # desirable(좋아요)일 경우 1.0, undesirable(싫어요)일 경우 0.0
beta: float = 0.1, lambda_d: float = 1.0, lambda_u: float = 1.33
) -> torch.Tensor:
"""Kahneman-Tversky Optimization (KTO) Loss"""
rewards = beta * (policy_logps - ref_logps)
# 배치 평균을 사용하여 z_0 (KL 발산)를 추정합니다.
# 기준선(Moving baseline)을 통한 그래디언트 흐름을 막기 위해 detach()를 사용합니다.
z_0 = rewards.detach().mean()
# 수학적 성질: 1 - sigmoid(x) == sigmoid(-x)
# 수치적 안정성을 위해 이 항등식을 사용합니다.
desirable_loss = F.sigmoid(-(rewards - z_0))
undesirable_loss = F.sigmoid(-(z_0 - rewards))
loss = labels * lambda_d * desirable_loss + (1.0 - labels) * lambda_u * undesirable_loss
return loss.mean()
def cdpo_loss(
policy_chosen_logps: torch.Tensor, policy_rejected_logps: torch.Tensor,
ref_chosen_logps: torch.Tensor, ref_rejected_logps: torch.Tensor,
beta: float = 0.1, epsilon: float = 0.1
) -> torch.Tensor:
"""Conservative DPO (cDPO) Loss"""
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = ref_chosen_logps - ref_rejected_logps
logits = pi_logratios - ref_logratios
# 표준 DPO 항과 라벨 노이즈를 대비한 반전(Flipped) 항
loss_correct = -F.logsigmoid(beta * logits)
loss_flipped = -F.logsigmoid(-beta * logits)
loss = (1.0 - epsilon) * loss_correct + epsilon * loss_flipped
return loss.mean()6. 알고리즘 비교 매트릭스
사후 학습(Post-training) 파이프라인을 설계할 때, 어떤 알고리즘을 선택할지는 전적으로 보유한 데이터의 제약과 모델의 목표에 달려 있습니다.
| 알고리즘 | 데이터 요구사항 | 과적합 위험 | 라벨 노이즈 강건성 | 최적의 사용 사례 |
|---|---|---|---|---|
| DPO | 쌍방향 () | 높음 (하한선 없음) | 낮음 | 매우 정교하게 큐레이션된 고품질 쌍방향 데이터셋. |
| IPO | 쌍방향 () | 낮음 (제한됨) | 중간 | DPO 적용 시 모드 붕괴나 창의성 상실이 발생하는 데이터셋. |
| cDPO | 쌍방향 () | 높음 | 높음 | 작업자 간의 의견 불일치가 높은 크라우드소싱 쌍방향 데이터. |
| KTO | 단일 이진 (👍/👎) | 낮음 | 높음 | 레거시 로그, 프로덕션 챗봇 피드백, 극도로 불균형한 데이터. |
요약 및 다음 단계
우리는 정렬(Alignment) 생태계가 표준 DPO 기법을 넘어 어떻게 빠르게 진화했는지 살펴보았습니다. 근본적인 수학적 결함을 해결한 IPO 와 데이터 수집의 병목을 해소한 KTO 를 통해, 엔지니어들은 파운데이션 모델을 조향할 수 있는 더욱 강력한 도구 모음을 갖추게 되었습니다.
그러나 RLHF부터 KTO 에 이르는 모든 선호도 최적화 알고리즘은, 근본적으로 모델의 가중치를 사전 학습(Pre-training)된 분포에서 강제로 끌어내는 방식을 사용합니다. 이러한 조작에는 숨겨진 비용이 따릅니다. 다음 장인 10.5 Alignment Tax 에서는 모델을 인간의 선호도에 맞추는 과정이 역설적으로 모델의 핵심 추론 능력과 창의성을 어떻게 저하시키는지, 그리고 연구자들이 안전성과 순수 지능 사이의 균형을 어떻게 맞추려 시도하는지 조사할 것입니다.
Quizzes
Quiz 1: IPO 알고리즘은 왜 선호도 쌍에 대해 모델이 “너무 강하게 정답을 맞히는 것”에 페널티를 부여합니까?
DPO의 목적 함수는 하한선이 없기 때문에, 선택된 답변과 거절된 답변 사이의 로그 확률 격차를 무한대로 밀어붙입니다. 이는 모델이 다양성을 잃고 기계적인 답변만 내뱉는 모드 붕괴(Mode Collapse)로 이어집니다. IPO는 에 중심을 둔 평균 제곱 오차 손실을 사용합니다. 격차가 이 정확한 값에 도달하면 손실은 0이 되며, 모델이 격차를 더 벌리려고 하면 오히려 손실이 증가합니다. 이는 모델의 과도한 확신을 명시적으로 규제하여 창의성과 엔트로피를 유지하게 만듭니다.
Quiz 2: KTO에서 기준점 는 방대한 데이터셋에 대한 추가적인 Forward Pass 없이 실무적으로 어떻게 추정됩니까?
일반적인 구현에서 는 정책 모델과 참조 모델 간의 예상 KL 발산을 나타냅니다. 전체 데이터셋에 대해 이를 계산하는 대신, 암묵적 보상인 beta * (policy_logps - ref_logps) 의 배치(Batch) 평균을 사용하여 동적으로 근사합니다. 이때 텐서는 연산 그래프에서 분리(detach)되어, 모델이 기준선 자체를 조작하려 들지 않고 안정적인 이동 기준선(Moving baseline)에 대해 개별 응답을 최적화하도록 만듭니다.
Quiz 3: cDPO 손실 함수에서 라벨 노이즈 매개변수 로 설정하면 어떤 일이 발생합니까?
이면 가정된 라벨 노이즈가 50%라는 뜻이며, 이는 선호도 라벨이 완전히 무작위(Random)임을 의미합니다. cDPO 손실 방정식은 가 됩니다. 이기 때문에, 그래디언트는 상쇄되거나 모델이 강한 선호도를 가지는 것 자체에 큰 페널티를 줍니다. 결과적으로 모델은 참조 모델(Reference Model)로부터 가중치를 변경하는 것을 거부하게 되며, 이는 신호에 유의미한 정보가 전혀 없을 때 수학적으로 가장 올바른 최적의 행동입니다.
Quiz 4: 조직에 사용자의 “좋아요/싫어요” 평가가 포함된 100만 개의 레거시 채팅 로그가 있다면, 어떤 정렬 알고리즘이 가장 적합하며 그 이유는 무엇입니까?
KTO (Kahneman-Tversky Optimization)가 가장 적합합니다. 챗봇과 같은 레거시 시스템은 (응답 A vs 응답 B) 형태의 쌍방향 선호도보다 단일 이진 피드백을 수집하는 경우가 많습니다. 이진 피드백을 억지로 쌍으로 변환하는 것은 어렵고 오류가 발생하기 쉬우며 많은 데이터를 버리게 만듭니다. 반면 KTO는 수학적으로 쌍을 이루지 않은 고도로 불균형한 이진 신호에서 직접 최적화하도록 설계되었기 때문입니다.
References
- Azar, M. G., et al. (2023). A General Theoretical Paradigm to Understand Learning from Human Preferences. arXiv:2310.12036.
- Ethayarajh, K., et al. (2024). KTO: Model Alignment as Prospect Theoretic Optimization. arXiv:2402.01306.
- Devanathan, R., et al. (2024). The Paradox of Preference: A Study on LLM Alignment Algorithms and Data Acquisition Methods. ACL Anthology.