15.4 Verifiers & Reward Models
Test-time compute가 추론의 엔진이라면, Verifier (검증기) 또는 Reward Model (보상 모델) 은 운전대와 같습니다. 이전 섹션에서 살펴보았듯이, 모델에게 “생각할” 시간을 더 주거나 여러 개의 후보 해답을 생성하도록 하는 것은, 시스템이 그 생각들 중 어떤 것이 실제로 올바른지 정확히 식별할 수 있을 때만 성능 향상으로 이어집니다.
강력한 검증 메커니즘이 없다면, Test-time compute를 확장하는 것은 단순히 모델이 대규모로 자신 있게 할루시네이션(환각)을 일으키도록 방치하는 것과 같습니다. 모델은 수천 개의 결함 있는 추론 경로를 생성하고 그중 하나를 임의로 선택해 버릴 것입니다.
이 섹션에서는 검증 시스템의 진화 과정을 추적합니다. 가장 기본적인 형태인 Outcome Reward Models (ORM) 에서 시작하여, OpenAI가 도입한 세밀한 Process Reward Models (PRM) 을 거쳐, 2024–2025년의 SOTA(State-of-the-Art) 기술인 Generative Verifiers (GenRM) 와 내재적 Self-Correction (SCoRe) 에 이르기까지 깊이 있게 탐구합니다.
1. The Baseline: Discriminative Reward Models
역사적으로 Reward Model(RM)은 Discriminative Classifiers (판별적 분류기) 로 구축되었습니다. 사전 학습된 LLM을 가져와서 100,000개의 단어 어휘(vocabulary)에 대해 다음 토큰을 예측하는 언어 모델링 헤드(Language Modeling Head)를 제거하고, 단일 스칼라 값을 출력하는 단순한 선형 회귀 헤드(Linear Regression Head)로 교체하는 방식입니다.
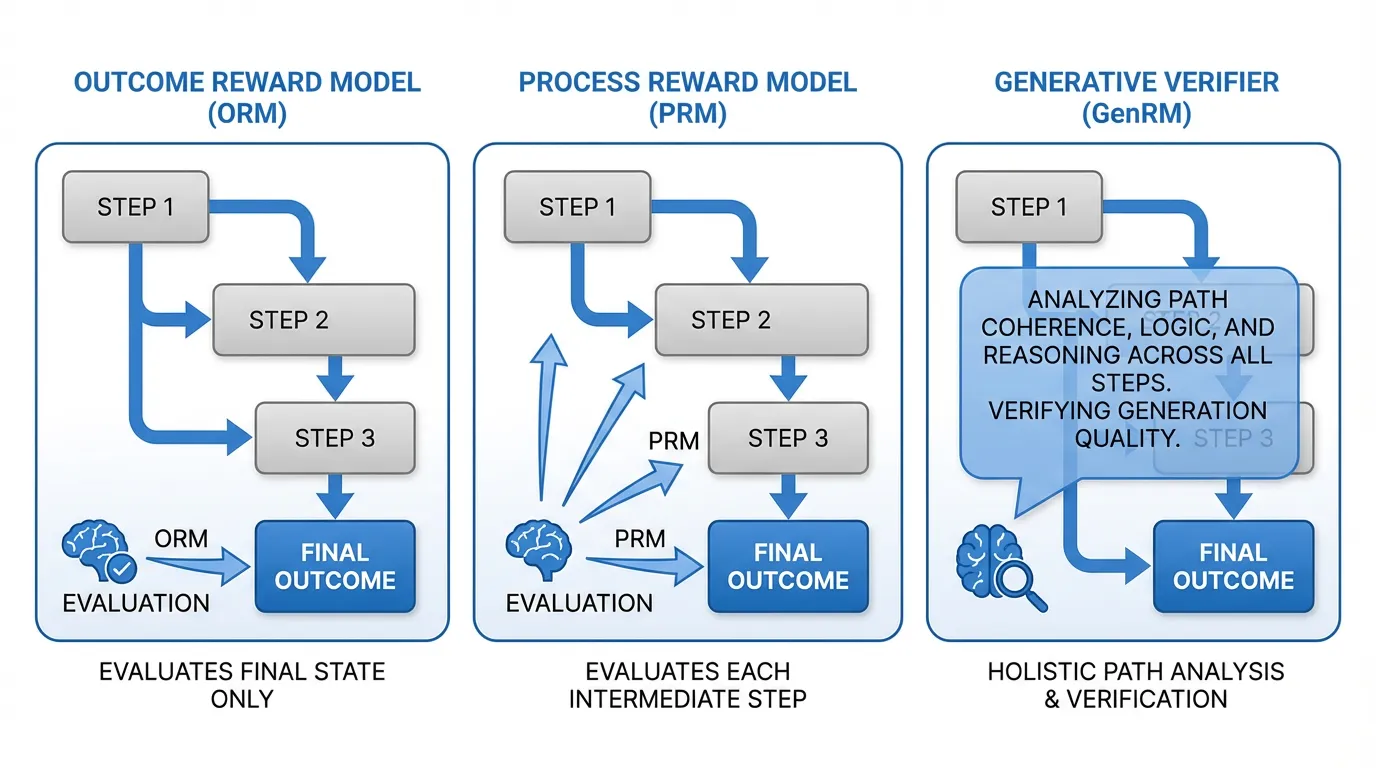
Outcome Reward Models (ORM)
Outcome Reward Model 은 오직 최종 답변만을 평가합니다. 모델에게 복잡한 수학 문제를 풀게 한 뒤, ORM은 최종 출력만을 보고 0과 1 사이의 점수를 부여합니다.
ORM은 훈련하기가 비교적 쉽지만(최종 정답 라벨만 있으면 됨), Sparse Reward Problem (희소 보상 문제) 이라는 치명적인 단점을 안고 있습니다. 만약 모델이 9단계의 훌륭한 논리적 단계를 수행하다가 10번째 단계에서 사소한 산술 오류를 범하더라도, ORM은 전체 시퀀스에 0점을 부여합니다. 이로 인해 강화학습(RL) 알고리즘이 적절한 신용 할당(Credit Assignment)을 수행하기가 매우 어려워집니다. 모델은 자신의 추론 중 어느 부분 에 결함이 있었는지 알지 못합니다.
Process Reward Models (PRM)
이러한 희소 보상 문제를 해결하기 위해, OpenAI의 연구진은 “Let’s Verify Step by Step” (Lightman et al., 2023) [1] 논문에서 Process Reward Model 을 도입했습니다.
최종 결과를 채점하는 대신, PRM은 Chain-of-Thought (CoT) 내부의 모든 개별 중간 단계 를 평가합니다. PRM을 훈련시키기 위해서는 인간 작업자(또는 더 강력한 AI 모델)가 풀이의 각 단계를 긍정(Positive), 부정(Negative), 또는 중립(Neutral)으로 수동 라벨링해야 합니다 (예: PRM800K 데이터셋).
PRM의 가장 큰 장점은 탐색 과정에서 조기 종료(Early-stopping) 메커니즘으로 작동한다는 것입니다. Tree of Thoughts (ToT) 알고리즘을 실행할 때, PRM은 3단계를 평가할 수 있습니다. 만약 3단계에 논리적 결함이 있다면 PRM은 낮은 점수를 부여하고, 탐색 알고리즘은 즉시 해당 가지(branch)를 잘라냅니다(Pruning). 이를 통해 4단계부터 10단계까지 생성하는 데 낭비되었을 막대한 연산량을 절약할 수 있습니다.
Engineering a Process Reward Model in PyTorch
내부적으로 PRM은 “단계(step)“가 끝나는 정확한 토큰(일반적으로 개행 문자 \n 또는 특정 구분자 토큰)에서 트랜스포머의 은닉 상태(Hidden State)를 추출하고, 그 단일 벡터를 분류 헤드(Classification Head)에 통과시킵니다.
import torch
import torch.nn as nn
from transformers import PreTrainedModel
class ProcessRewardModel(nn.Module):
def __init__(self, base_llm: PreTrainedModel):
super().__init__()
self.base_llm = base_llm
self.hidden_size = base_llm.config.hidden_size
# 어휘(Vocabulary) 헤드를 스칼라 회귀 헤드로 교체합니다.
# 해당 단계의 "정확성"을 나타내는 단일 로짓(logit)을 출력합니다.
self.score_head = nn.Linear(self.hidden_size, 1)
def forward(self, input_ids: torch.Tensor, step_end_indices: torch.Tensor):
"""
input_ids: [batch_size, seq_len]
step_end_indices: [batch_size, num_steps] - 각 단계가 끝나는 토큰의 인덱스
"""
# 1. Base LLM을 통한 Forward Pass
outputs = self.base_llm(input_ids, output_hidden_states=True)
# 마지막 레이어의 은닉 상태(Hidden States) 추출: Shape [batch, seq_len, hidden_size]
last_hidden_states = outputs.hidden_states[-1]
batch_size, num_steps = step_end_indices.shape
# 2. 단계의 경계(Step Boundaries)에서 특정 은닉 상태만 수집(Gather)
# 3D 텐서를 올바르게 인덱싱하기 위해 배치 인덱스 그리드를 생성합니다.
batch_indices = torch.arange(batch_size, device=input_ids.device).unsqueeze(1).expand(-1, num_steps)
# Shape: [batch, num_steps, hidden_size]
step_hidden_states = last_hidden_states[batch_indices, step_end_indices, :]
# 3. 프로세스 보상(Process Rewards) 계산
# Shape: [batch, num_steps]
step_logits = self.score_head(step_hidden_states).squeeze(-1)
# 4. Sigmoid를 적용하여 로짓을 확률(0.0 ~ 1.0)로 변환
step_probabilities = torch.sigmoid(step_logits)
return step_probabilities2. The Paradigm Shift: Generative Verifiers (GenRM)
PRM은 엄청난 도약이었지만, 근본적인 아키텍처 결함을 안고 있었습니다. 언어 모델링 헤드를 선형 회귀 헤드로 교체함으로써, 우리는 LLM의 가장 강력한 무기인 텍스트 생성(Text Generation) 능력을 박탈해 버렸습니다.
인간 교사가 수학 시험지를 채점할 때, 수식을 뚫어져라 쳐다보다가 즉시 0.14 라는 확률 점수를 내뱉지 않습니다. 교사는 수식을 읽고, 대수학의 규칙에 대해 생각하고, 머릿속으로 오류를 언어화 한 다음 (“잠깐, 등호를 넘어 +5를 옮기면 -5가 되어야지”), 그 후에 점수를 부여합니다.
2024년, Zhang et al. 은 보상 모델링을 Next-Token Prediction Task 로 재구성한 Generative Verifiers (GenRM) [2] 를 발표했습니다.
GenRM은 스칼라 값을 출력하는 대신, 질문과 후보 해답을 프롬프트로 받아 텍스트 기반의 비평(Critique)을 생성하도록 지시받습니다. 모델은 해답이 왜 맞거나 틀렸는지 설명하는 Verification Rationale (검증 논리, 즉 Chain-of-Thought)을 생성하고, 마지막 토큰으로 “Yes” 또는 “No”를 출력하며 끝을 맺습니다. 해답의 “점수”는 단순히 “Yes” 토큰에 할당된 확률 질량(Probability Mass)이 됩니다.
 Source: Zhang et al., 2024 [2]
Source: Zhang et al., 2024 [2]
The Advantages of GenRM
- Implicit Reasoning (내재적 추론): 판결을 내리기 전에 논리를 생성함으로써, 모델은 자체적인 작업 메모리(KV Cache)를 활용하여 논리의 정확성을 연산합니다. 이는 복잡한 증명에서 압도적으로 우수한 정확도를 이끌어냅니다.
- Easy-to-Hard Generalization (일반화 능력): 판별적 RM은 종종 표면적인 특징에 과적합(Overfitting)됩니다 (예: “길이가 긴 해답이 보통 정답이다”). 반면, 해답이 왜 올바른지 명확히 설명해야 하는 GenRM은 훈련된 것보다 더 어려운 문제에 대해서도 훨씬 더 잘 일반화됩니다.
- Test-Time Compute on Verification: GenRM은 생성형 모델이므로, 검증기 자체 에 Test-time compute를 적용할 수 있습니다. 동일한 후보 해답에 대해 16개의 다른 Verification Rationale을 샘플링하고 최종 “Yes/No” 토큰에 대해 다수결 투표(Majority Vote)를 진행하면, 검증 정확도가 비약적으로 상승합니다.
Interactive: Verifier Paradigms
Observe how different Reward Models evaluate the same flawed reasoning path.
Problem
Candidate Solution
Evaluation Logic
Mechanism: Scalar Regression on Final Token
Reading final step: x = 29/3
Comparing to Target: x = 5
Flaw: The model gets a 0, but has no idea that Step 2 was the actual mistake. The credit assignment is too sparse.
3. The Holy Grail: Intrinsic Self-Correction (SCoRe)
만약 모델이 GenRM을 통해 텍스트를 검증할 수 있다면, 단순히 자신의 실수를 스스로 고칠 수도 있지 않을까요?
놀랍게도, 역사적으로 그 대답은 “아니오” 였습니다. LLM 연구에서 잘 알려진 역설 중 하나는 모델이 내재적인 자가 교정(Intrinsic Self-Correction)에 끔찍할 정도로 서툴다는 것입니다. LLM에게 “확실합니까? 답변을 검토하고 실수가 있다면 수정하세요.” 라고 프롬프트를 주면, 모델은 Sycophancy (아부 현상/동조 현상) 에 굴복할 가능성이 매우 높습니다. 사용자가 의문을 제기했으므로 자신이 틀렸을 것이라 지레짐작하고 사과하며, 올바른 정답을 틀린 오답으로 바꿔버립니다. 반대로 초기 답변이 틀렸을 경우, 특정 오류를 찾아낼 논리적 기반이 부족하여 단순히 또 다른 틀린 답변을 할루시네이션해냅니다.
표준적인 Supervised Fine-Tuning (SFT)은 이 문제를 해결하지 못합니다. SFT는 오프라인에서 인간이 작성한 교정 데이터에 의존하기 때문입니다. 모델은 사과하고 수정하는 스타일(Style) 은 흉내 내도록 학습하지만, 실제 자신의 오류 분포 하에서 스스로를 교정하는 실제 정책(Policy) 은 학습하지 못합니다.
Multi-Turn RL and the Delta Reward
이 문제를 해결하기 위해 Kumar et al. (2024) 은 SCoRe (Self-Correction via Reinforcement Learning) [3] 를 도입했습니다. SCoRe는 자가 교정을 전적으로 모델 자신이 생성한 데이터를 기반으로 하는 멀티 턴(Multi-turn) 강화학습 문제로 취급합니다.
학습 루프는 두 번의 턴(Turn)으로 진행됩니다:
- Turn 1: 모델이 초기 시도()를 생성합니다.
- Turn 2: 모델은 을 검토하고 수정된 시도()를 생성하도록 프롬프트를 받습니다.
SCoRe의 핵심 아이디어는 Reward Shaping (보상 형성) 에 있습니다. 만약 단순히 에서 최종 정답을 맞힌 것에 대해 모델에게 보상을 준다면, RL 알고리즘은 “붕괴(Collapse)“할 것입니다. 모델은 보상을 극대화하는 가장 쉬운 방법이 에서 완벽한 정답을 생성하고, 교정 단계를 무시한 채 에서 그 완벽한 정답을 반복하는 것임을 깨닫게 됩니다.
모델이 교정이라는 기술(Skill) 을 학습하도록 강제하기 위해, SCoRe는 Delta Reward 를 적용합니다. 모델은 가 정답이면서 동시에 이 오답이었을 때만 막대한 보너스를 받습니다.
핵심은 특정 제품명이 아니라 학습 신호 그 자체입니다. 모델이 실제로 저지른 자기 실수 위에서 훈련되고, 이미 맞게 풀고 있던 것을 망치지 않으면서 오류를 고치는 델타(Delta) 에 보상을 받으면, 자가 교정은 단순한 프롬프트 요령이 아니라 학습 가능한 행동으로 바뀝니다.
4. Synthetic Data & The Verification Loop
현대 파운데이션 모델 엔지니어링에서 반복적으로 나타나는 주제는 인간 데이터의 고갈입니다. GenRM이나 PRM을 훈련시키기 위해 수백만 개의 단계별 검증 논리를 수동으로 작성해 줄 수학 박사는 세상에 충분하지 않습니다.
현재 검증기를 훈련시키기 위한 SOTA 파이프라인은 전적으로 Synthetic Data Loops (합성 데이터 루프) 에 의존하고 있습니다:
- Base 모델을 가져와 특정 수학 문제에 대해 100개의 해답을 생성합니다.
- 결정론적 규칙 기반 검사기(예: 최종 정답을 확인하는 Python 스크립트)를 사용하여 정답과 오답을 분리합니다.
- 오답에 대해 GPT-4o나 Claude 3.5 Sonnet과 같이 고도로 뛰어난 대형 “Teacher” 모델을 비평가(Critic)로 활용합니다: “여기에 수학 문제와 틀린 풀이가 있습니다. 논리가 실패하는 정확한 단계를 찾고, 왜 실패했는지 설명한 다음, ‘No’를 출력하세요.”
- 이렇게 생성된 합성 비평 데이터를 사용하여 더 작고 효율적인 “Student” 모델을 GenRM으로 파인튜닝(Fine-tuning)합니다.
이러한 루프를 통해 AI 업계는 거대한 프론티어 모델의 추론 능력을 극도로 효율적이고 특화된 검증기로 증류(Distillation)할 수 있으며, 이를 대규모로 배포하여 Search-time compute 알고리즘을 가이드할 수 있습니다.
5. Summary and Next Steps
우리는 모델이 수동적인 생성기에 불과했던 시대에서, 적극적인 탐색자(Searcher)로 활동하는 시대로 전환하고 있습니다.
- Outcome RMs 은 기본적인 Best-of-N 선택을 가능하게 했습니다.
- Process RMs 은 탐색 트리를 효율적으로 잘라낼(Pruning) 수 있게 해주었습니다.
- Generative Verifiers 는 평가 과정에 Chain-of-Thought를 활용할 수 있는 능력을 열어주었습니다.
- SCoRe 는 모델이 자신의 결함을 내재적으로 인식하고 수정하도록 훈련될 수 있음을 증명했습니다.
그렇다면 작업이 더 이상 객관적인 정답/오답이 있는 수학 문제나 코드 스니펫이 아니라면 어떻게 될까요? 모델이 API, 데이터베이스, 웹 브라우저와 상호 작용하며 실제 세계의 행동 공간(Action Space)을 탐색하기를 원한다면 어떻게 해야 할까요?
이를 달성하기 위해 모델은 단순한 추론 엔진에서 자율적인 행위자(Autonomous Actor)로 진화해야 합니다. 다음 Chapter 16: Agentic AI & Tools 에서는 파운데이션 모델이 어떻게 외부 도구를 사용하고, 장기 기억을 관리하며, 멀티 에이전트 협업을 오케스트레이션하도록 엔지니어링되는지 탐구하겠습니다.
Quizzes
Quiz 1: 길고 여러 단계로 이루어진 추론 작업에서, 강화학습(RL)을 적용할 때 Outcome Reward Model (ORM)이 Process Reward Model (PRM)에 비해 유용한 그래디언트(Gradients)를 제공하는 데 어려움을 겪는 이유는 무엇입니까?
ORM은 희소 보상 문제(Sparse reward problem)를 겪습니다. 모델이 20단계의 증명을 생성하다가 19단계에서 부호 오류를 범할 경우, ORM은 최종 점수로 0점을 부여합니다. RL 알고리즘은 20개의 단계 중 어느 단계가 실패의 원인인지 쉽게 파악할 수 없으므로 신용 할당(Credit assignment)이 매우 비효율적입니다. 반면 PRM은 각 단계를 개별적으로 채점하여, 모델이 정확히 어디서 잘못되었는지 알려주는 조밀하고 국소적인(Localized) 피드백을 제공합니다.
Quiz 2: Generative Verifiers (GenRM)의 맥락에서, 모델이 최종 “Yes” 또는 “No” 토큰을 출력하기 ‘전에’ “Verification Rationale” (검증 논리 설명)을 생성하는 것이 왜 그렇게 중요합니까?
자기회귀(Autoregressive) LLM은 토큰을 생성하기 전에 은닉 상태(Hidden states)에서 “미리 내다보거나(Look ahead)” 생각할 수 없기 때문입니다. 모델이 “Yes”나 “No”를 먼저 출력한다면, 이는 순전히 System 1의 Forward Pass에만 의존하여 성급한 판단을 내리도록 강제하는 것입니다. 논리를 먼저 생성함으로써 모델은 생성된 텍스트를 스크래치패드로 사용하여 KV Cache를 확장하고, 최종 판결을 내리기 전에 논리적으로 정확성을 연역하는 System 2 연산을 효과적으로 수행할 수 있습니다.
Quiz 3: 인간이 작성한 교정 데이터(Correction traces)에 대해 표준적인 Supervised Fine-Tuning (SFT)을 수행하는 것이 LLM에게 스스로 실수를 안정적으로 교정하는 방법을 가르치는 데 실패하는 이유는 무엇입니까?
SFT는 분포 불일치(Distribution mismatch) 문제를 안고 있습니다. 인간이 작성한 교정은 모델이 범하는 특이한 할루시네이션이 아니라 인간의 실수를 고칩니다. SFT로 훈련될 때, 모델은 교정하는 표면적인 “스타일”(예: “사과드립니다. 수정하겠습니다”라고 말하는 것)은 배우지만, 자신의 실제 논리적 결함을 식별하는 근본적인 정책(Policy)은 배우지 못합니다. 진정한 자가 교정을 학습하려면 SCoRe처럼 모델 자신이 생성한 궤적(Trajectories)에 대한 RL이 필요합니다.
Quiz 4: SCoRe 알고리즘에서, 보상 함수가 올바른 을 틀린 로 바꾸는 것에 대해 모델에 페널티를 주지 않고 오직 마지막 턴()의 정확성만 보상한다면 어떤 일이 발생할 가능성이 높습니까?
모델은 행동 붕괴(Behavior collapse) 및 아부 현상(Sycophancy)에 빠지게 됩니다. 모델은 첫 번째 턴에 관계없이 두 번째 턴에서 단순히 정답을 출력하는 것이 보상을 극대화하는 가장 쉬운 방법임을 배우게 됩니다. 더 나쁜 것은, 프롬프트가 오류가 있음을 암시할 경우 모델은 항상 첫 번째 답변을 변경하도록 학습하여, 처음에 맞았던 답변을 단지 “교정” 지시를 만족시키기 위해 오답으로 바꾸는 퇴화(Degradation) 현상을 일으킬 것입니다.
Quiz 5: 리워드 모델링(Reward Modeling)에서 흔히 사용되는 이진 교차 엔트로피(BCE) 쌍별 손실(pairwise loss)의 그래디언트를 도출하시오. 손실은 로 정의되며, 여기서 는 우수 응답(winning response), 은 열등 응답(losing response)입니다. 리워드 모델 매개변수 에 대한 명시적인 그래디언트를 도출하시오.
이유를 로 둡니다. 손실 함수는 입니다. 의 미분은 입니다. 따라서 이 됩니다. 연쇄 법칙(chain rule)을 사용하면 에 대한 그래디언트는 다음과 같습니다: . 이는 모델이 잘못하여 로 점수를 매겼을 때 스칼라 항 이 에 가까워져 매개변수를 업데이트하기 위한 그래디언트 크기를 최대화하는 반면, 쌍을 완벽히 구분해 냈을 때는 () 에 가까워짐을 보여줍니다.
References
- Lightman, H., et al. (2023). Let’s Verify Step by Step. arXiv:2305.20050.
- Zhang, L., et al. (2024). Generative Verifiers: Reward Modeling as Next-Token Prediction. arXiv:2408.15240.
- Kumar, A., et al. (2024). Training Language Models to Self-Correct via Reinforcement Learning. arXiv:2409.12917.