15.3 Search-time Compute
이전 섹션에서는 Tree of Thoughts와 Graph of Thoughts가 어떻게 추론을 외부화(externalize)하는지 살펴보았습니다. 외부의 Python 오케스트레이터가 모델에게 이산적인 상태(discrete states)들을 생성하고, 평가하고, 탐색하도록 강제하는 방식이었습니다. 이 접근법은 효과적이지만, 근본적으로 모델 외부에 덧붙여진(bolted-on) 형태에 불과합니다. 모델은 전체적인 탐색 알고리즘을 알지 못한 채 수동적인 생성기로만 남아있게 됩니다.
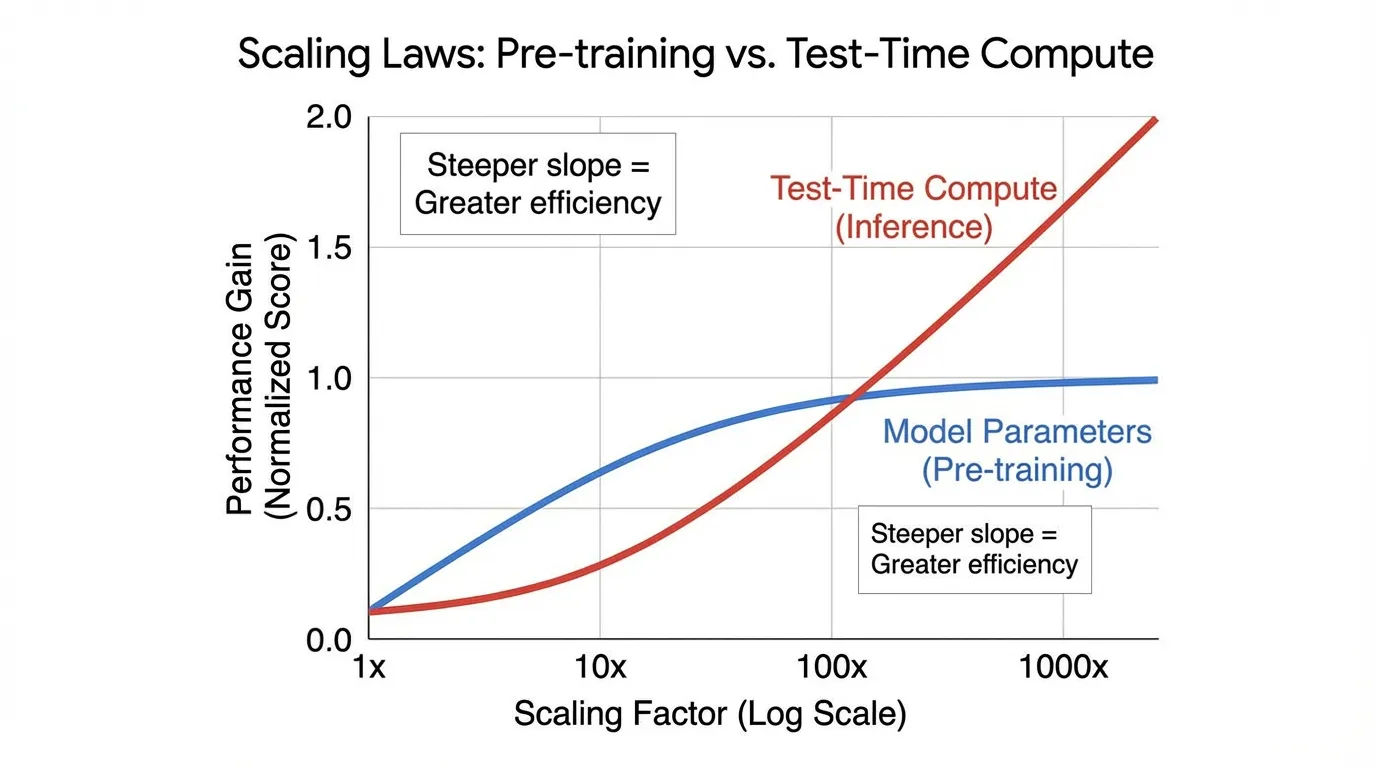
2024년 말부터 2025년 초에 이르러 패러다임이 전환되었습니다. 연구자들은 외부 스크립트에 의존하여 탐색 트리를 관리하는 대신, 모델이 탐색 과정을 내재화(internalize) 하도록 만드는 방법을 발견했습니다. 최종 답변을 내놓기 전에 모델이 오랜 시간 동안 “생각(think)“할 수 있도록 허용함으로써, 성능 확장의 새로운 차원인 Inference-Time Scaling Laws (또는 Test-Time Compute)가 열리게 되었습니다.
이 섹션에서는 Search-time compute의 메커니즘, 사전 학습(Pre-training)에서 추론(Inference)으로 이동하는 경제적 패러다임의 변화, 그리고 OpenAI의 o1이나 DeepSeek-R1과 같은 추론 모델들의 내부 아키텍처를 깊이 있게 탐구합니다.
1. The Inference-Time Scaling Law
역사적으로 AI 산업은 단일한 확장 축, 즉 Pre-training Compute 에 의존해왔습니다. 더 똑똑한 모델을 얻기 위해서는 더 큰 파라미터 행렬을 더 많은 데이터셋으로, 더 많은 GPU 시간을 들여 학습시켜야 했습니다 (8장에서 다룬 Power Law 및 Chinchilla scaling laws 참조).
하지만 사전 학습의 확장은 심각한 수확 체감(diminishing returns)에 직면해 있습니다. 모델을 70B(700억 개)에서 1T(1조 개) 파라미터로 키우는 데는 기하급수적인 자본 지출이 필요합니다.
Inference-time scaling은 이와 직교하는(orthogonal) 새로운 벡터를 제공합니다. Snell et al. (2024) [1] 의 연구는 추론 시점 에 추가적인 연산량을 지능적으로 할당하는 것이 단순히 모델 크기를 키우는 것보다 더 큰 성능 향상을 가져올 수 있음을 입증했습니다. FLOPs를 동일하게 맞춘 평가에서, 무거운 Test-time compute를 활용하는 작은 Base 모델이 표준적인 Zero-shot 생성에만 의존하는 14배 더 큰 모델을 능가할 수 있습니다.
 Source: Snell et al., 2024 [1]
Source: Snell et al., 2024 [1]
이는 대니얼 카너먼(Daniel Kahneman)이 주창한 System 1 vs. System 2 thinking 의 AI 버전이라고 할 수 있습니다. 표준적인 자기회귀(Autoregressive) 디코딩은 System 1 입니다. 빠르고 반사적이며 복잡한 논리에서 할루시네이션(환각)을 일으키기 쉽습니다. 반면 Search-time compute는 System 2 입니다. 느리고 신중하며 여러 경로를 평가하고, 말을 뱉기 전에 스스로 오류를 교정(self-correcting)합니다.
2. Mechanisms of Test-Time Compute
그렇다면 추론 시점에 연산량을 정확히 어떻게 “소비”할까요? 무식하게 외부 래퍼(wrapper)를 씌우는 방식부터 네이티브한 내부 프로세스까지 세 가지 주요 메커니즘이 존재합니다.
Parallel Scaling (Best-of-N)
Test-time compute를 확장하는 가장 단순한 방법은 높은 Temperature를 사용하여 개의 독립적인 해결책을 병렬로 생성한 다음, 별도의 Reward Model (또는 Verifier)을 사용하여 이들의 점수를 매기고 가장 좋은 것을 선택하는 것입니다.
Best-of- 방식은 성능을 안정적으로 향상시키지만( 에 비례하여 로그 스케일로 확장됨), 매우 비효율적입니다. 수학 증명의 첫 단계에서 모델이 치명적인 논리적 오류를 범하더라도, 모델은 근본적으로 결함이 있는 풀이를 생성하느라 수백 개의 토큰을 낭비하게 됩니다.
import torch
import torch.nn as nn
from transformers import PreTrainedModel, PreTrainedTokenizer
class BestOfNInference(nn.Module):
def __init__(self, generator: PreTrainedModel, verifier: PreTrainedModel, tokenizer: PreTrainedTokenizer):
super().__init__()
self.generator = generator
self.verifier = verifier # 최종 정답을 평가하는 Outcome Reward Model (ORM)
self.tokenizer = tokenizer
@torch.no_grad()
def generate_and_select(self, prompt: str, n: int = 64, max_new_tokens: int = 512) -> str:
"""
Best-of-N 샘플링을 실행합니다.
"""
input_ids = self.tokenizer(prompt, return_tensors="pt").input_ids.to(self.generator.device)
# 1. 병렬 생성을 위해 입력 확장: Shape [N, seq_len]
input_ids_expanded = input_ids.repeat(n, 1)
# 2. Temperature 스케일링을 사용하여 N개의 다양한 후보 생성
outputs = self.generator.generate(
input_ids_expanded,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
pad_token_id=self.tokenizer.pad_token_id
)
prompt_len = input_ids.shape[1]
responses = outputs[:, prompt_len:]
# 3. Verifier를 사용하여 후보 채점
# Verifier는 보상을 나타내는 스칼라 로짓(logit)을 출력합니다.
rewards = self.verifier(outputs).logits.squeeze(-1) # Shape: [N]
# 4. 가장 높은 보상을 받은 후보 선택
best_idx = torch.argmax(rewards)
best_response = responses[best_idx]
return self.tokenizer.decode(best_response, skip_special_tokens=True)Sequential Scaling (Step-Level Search)
Best-of- 의 비효율성을 해결하기 위해, 최종 결과가 아닌 중간 단계를 평가하는 Process Reward Model (PRM) 을 사용할 수 있습니다. Beam Search나 Lookahead Search 같은 알고리즘은 PRM을 활용하여 잘못된 추론 가지(branches)를 조기에 잘라내고(prune), 유망한 경로에 연산량을 재할당합니다. (PRM에 대한 심층적인 내용은 다음 섹션인 15.4에서 다룹니다).
Internal Scaling (The o1 Paradigm)
가장 진보된 형태의 Test-time compute는 외부 오케스트레이터를 완전히 제거합니다. OpenAI의 o1이나 DeepSeek-R1 [2] 과 같은 모델들은 연속적인 토큰 스트림 내부에서 탐색 과정을 내재화하도록 훈련됩니다.
프롬프트가 주어지면, 모델은 최종 답변을 출력하기 전에 긴 시퀀스의 “생각하는 토큰(thinking tokens)” (숨겨진 Chain-of-Thought)을 생성합니다. 이 단계 동안 모델은 자율적으로 전략을 제안하고, 실행하고, 자신의 오류를 인식하고, 되돌아가고(backtrack), 논리를 검증합니다.
3. Training for Internal Search: The DeepSeek-R1 Approach
내부 탐색을 내재화하는 것이 목표라면, 모델이 이를 수행하도록 어떻게 훈련시켜야 할까요? 표준적인 Supervised Fine-Tuning (SFT)만으로는 충분하지 않습니다. 사람이 작성한 추론 과정을 모델에게 학습시키면, 모델은 탐색과 자기 교정이라는 실제 과정(process) 이 아닌, 추론의 스타일(style) 만을 모방하게 됩니다.
여기서의 돌파구는 최종 정답을 객관적으로 검증할 수 있는 작업(예: 수학, 코딩)에 대규모 Reinforcement Learning (RL) 을 적용하는 것입니다.
DeepSeek-R1은 Base 모델에 Group Relative Policy Optimization (GRPO) 와 같은 알고리즘을 사용하여 순수 RL을 적용할 수 있음을 보여주었습니다. PPO (Proximal Policy Optimization)와 달리 GRPO는 메모리를 많이 차지하는 별도의 Value Model을 필요로 하지 않습니다. 대신 동일한 프롬프트에 대해 여러 개의 출력을 그룹으로 생성하고, 규칙 기반 검증기(예: “코드가 단위 테스트를 통과했는가?”)를 사용하여 점수를 매긴 다음, 그룹 내에서 보상을 정규화하여 어드밴티지(advantages)를 계산합니다.
이 RL 단계 동안 매우 흥미로운 현상이 발생합니다. 인간의 명시적인 프롬프팅 없이도 모델은 “Aha!” 모멘트를 경험하게 됩니다. 모델은 자신의 이전 단계를 검증하는 데 더 많은 토큰을 할당할수록 최종 보상이 증가한다는 사실을 자연스럽게 학습합니다. 그 결과 다음과 같은 행동들이 자발적으로 발현됩니다:
- “잠깐, 이 계산은 틀린 것 같아. 다시 평가해보자…”
- “다른 접근 방식을 시도해 볼까…”
생각하는 단계의 길이는 곧 탐색 깊이의 대리 지표(proxy)가 됩니다. 단순히 자기회귀 엔진을 더 오래 실행하는 것만으로, 모델은 더 넓은 상태 공간을 네이티브하게 탐색하게 됩니다.
Inference-Time Scaling Simulator
4. Compute-Optimal Allocation
Test-time compute에 있어서 중요한 엔지니어링 과제 중 하나는 할당의 효율성입니다. “프랑스의 수도는 어디인가?” 와 같은 단순한 쿼리에 10,000개의 생각 토큰을 할당하는 것은 FLOPs의 엄청난 낭비입니다. 반대로 복잡한 물리학 문제에 100개의 토큰만 할당하면 실패로 이어질 것입니다.
Snell et al. [1] 은 Compute-Optimal Inference 라는 개념을 공식화했습니다. Test-time compute의 효과는 Base 모델의 역량 대비 프롬프트의 난이도에 크게 의존합니다.
- 쉬운 프롬프트 (Easy Prompts): Base 모델이 이미 높은 성공 확률을 가지고 있습니다. 추가적인 연산량은 아주 미미한 이득만을 가져옵니다.
- 불가능한 프롬프트 (Impossible Prompts): 필요한 지식이 모델의 가중치에 완전히 부재합니다. 아무리 Test-time 탐색을 많이 해도 모델이 모르는 사실을 마법처럼 만들어낼 수는 없습니다.
- 스위트 스팟 (Challenging Prompts): 모델이 필요한 기본 지식(primitives)은 가지고 있지만, 이를 연결하기 위해 깊은 논리적 체이닝이 필요한 경우입니다. 바로 이 지점에서 Test-time compute가 기하급수적인 수익을 창출합니다.
현대의 인프라는 적응형 라우팅(adaptive routing)에 의존합니다. 가벼운 분류기(또는 모델 자체의 초기 엔트로피)가 프롬프트의 난이도를 결정하고, 최대 생각 토큰 예산(budget)을 동적으로 설정합니다.
5. Summary and Open Questions
Inference-time scaling은 AI의 경제학을 근본적으로 변화시켰습니다. 우리는 Pre-training 클러스터의 제약을 받던 세계에서 Inference 인프라의 제약을 받는 세계로 전환하고 있습니다. 만약 7B 모델이 단순히 “더 오래 생각하는 것”만으로 70B 모델과 맞먹을 수 있다면, 엣지 디바이스와 클라우드 API를 위한 배포 전략은 비동기적이고 장기 실행되는(long-running) 생성 작업을 지원하도록 완전히 재설계되어야 합니다.
그러나 RL을 통해 탐색을 내재화하는 것은 자동화된 검증이 가능한 도메인(수학, 코드)에 크게 의존합니다. 다음 개척지이자 중요한 미해결 과제는 규칙 기반 보상 함수가 존재하지 않는 창의적 글쓰기나 전략 기획과 같은 개방형(open-ended), 주관적 도메인에 어떻게 Inference-time scaling을 적용할 것인가입니다.
이 간극을 메우기 위해서는 복잡한 논리를 평가할 수 있는 강력한 모델이 필요합니다. 다음 섹션에서는 Verifiers and Process Reward Models (PRMs) 의 엔지니어링에 대해 살펴보겠습니다.
Quizzes
Quiz 1: 두 방식 모두 많은 양의 Test-time compute를 사용함에도 불구하고, Best-of- 샘플링이 OpenAI o1처럼 탐색을 내재화하는 방식에 비해 연산적으로 비효율적이라고 간주되는 이유는 무엇입니까?
Best-of- 은 처음부터 끝까지 개의 독립적인 전체 시퀀스를 생성합니다. 만약 후보 중 하나가 10번째 토큰에서 논리적 오류를 범하더라도, 모델은 결함이 있는 풀이의 나머지 500개 토큰을 생성하는 데 연산량을 그대로 낭비합니다. 반면 내재화된 탐색(o1 등)은 모델이 생성 도중에 오류를 인식하고, 되돌아가며(backtrack), 토큰 예산을 유망한 경로에 재할당할 수 있게 해주어 잘못된 가지를 네이티브하게 잘라냅니다.
Quiz 2: Compute-Optimal Inference의 개념에 따르면, 어떤 유형의 프롬프트에서 Test-time 스케일링이 FLOPs 측면에서 가장 낮은 투자 대비 수익(ROI)을 산출합니까?
Test-time compute는 두 가지 극단적인 경우에 가장 낮은 ROI를 산출합니다. 첫째는 “쉬운(Easy)” 프롬프트로, Base 모델이 Zero-shot System 1 사고만으로 이미 100%에 가까운 정확도를 달성하여 추가 연산이 불필요한 경우입니다. 둘째는 “불가능한(Impossible)” 프롬프트로, 모델에 필요한 사전 학습 지식이 근본적으로 부족하여 아무리 탐색을 수행해도 정답을 찾아낼 수 없는 경우입니다.
Quiz 3: DeepSeek-R1에서 사용된 GRPO (Group Relative Policy Optimization)는 전통적인 PPO에 비해 추론 RL 과정에서 메모리 오버헤드를 어떻게 줄입니까?
전통적인 PPO는 Advantage 계산을 위한 베이스라인을 추정하기 위해 VRAM에 별도의 Value Model(종종 Policy 모델과 동일한 크기)을 유지해야 합니다. GRPO는 이 Value Model을 제거합니다. 대신 단일 프롬프트에 대해 여러 응답(Group)을 생성하고 채점한 뒤, 해당 점수들의 평균과 표준편차를 사용하여 베이스라인과 Advantage를 직접 계산합니다.
Quiz 4: 제공된 Best-of- 의 PyTorch 구현에서, Greedy Decoding 대신
Greedy Decoding은 결정론적(deterministic)이므로, 정확히 동일한 시퀀스를 번 생성하게 되어 Best-of- 의 목적을 완전히 무효화합니다. Temperature를 적용하여 샘플링하면 생성된 후보들 간의 다양성(diversity)이 보장되며, 모델이 서로 다른 추론 경로를 탐색할 수 있게 되어 Verifier가 평가할 수 있는 다양한 풀이 풀(pool)을 제공하게 됩니다.temperature=0.7 과 do_sample=True 를 적용하는 이유는 무엇입니까?
Quiz 5: 추론 시퀀스 검색을 위한 MCTS에서 UCT 공식은 탐색(exploration)과 활용(exploitation)을 어떻게 균형 있게 조절합니까? UCT 방정식을 공식화하고 생성된 토큰 시퀀스 길이 에 따라 이 균형이 어떻게 달라지는지 설명하시오.
UCT 공식은 다음과 같이 정의됩니다: . 여기서 는 활용 항(평균 프로세스 보상)이며, 는 부모 노드 의 방문 횟수, 는 동작(토큰/단계) 를 취한 후 노드 의 방문 횟수, 는 탐색 상수입니다. 토큰 시퀀스 검색에서 생성된 시퀀스 길이 가 증가함에 따라 트리의 깊이가 기하급수적으로 확장됩니다. 이로 인해 초기에는 보상이 높지만 최종적으로는 틀린 하위 분기(sub-branch)에 검색 알고리즘이 갇히는 것을 방지하기 위해 탐색 항 이 매우 중요해집니다. 그러나 깊은 분기에서 탐색에 너무 많은 연산량을 할당하면 최종 답변의 향상 없이 테스트 시간 토큰 예산을 심각하게 팽창시킬 수 있습니다.
References
- Snell, C., Lee, J., Xu, K., & Kumar, A. (2024). Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. arXiv:2408.03314.
- DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948.
- Brown, N., et al. (2024). Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. arXiv:2407.21787.