6.3 Large-scale Training Stability
1B 파라미터 모델을 학습시키는 것은 통제된 트랙에서 스포츠카를 모는 것과 같습니다. 스핀이 발생해도 복구가 쉽습니다. 반면 수만 개의 GPU에서 100B 이상의 파라미터 모델을 학습시키는 것은 초음속 제트기를 조종하는 것과 같습니다. 손상된 데이터 배치, 단일 어텐션 헤드에서의 미세한 수치 오버플로우, 혹은 갑작스러운 그래디언트 분산과 같은 아주 작은 이상 징후도 Loss Spike (손실 값 폭증)라는 치명적인 실패를 촉발할 수 있습니다.
과거의 대규모 학습은 철저히 ‘사후 대응적(reactive)‘이었습니다. OPT-175B나 초기 LLaMA 모델을 학습시킬 때, 엔지니어들은 대시보드를 24시간 모니터링해야 했습니다. Loss Spike 가 발생하면 학습을 일시 중지하고, 수백 스텝 이전의 체크포인트로 롤백한 뒤, 문제를 일으킨 데이터 배치를 건너뛰고 다시 시작하는 것이 표준 절차였습니다. 이러한 ‘롤백 세금(rollback tax)‘은 수백만 달러의 GPU 연산 자원 낭비를 초래했습니다.
2024~2025년에 이르러 패러다임은 사전 예방적(proactive) 안정성 확보로 전환되었습니다. DeepSeek-V3 [1] 와 같은 최신 모델들은 14.8조 개의 토큰을 학습하는 동안, 극단적인 FP8 혼합 정밀도(mixed precision)를 사용했음에도 불구하고 복구 불가능한 Loss Spike 나 롤백을 단 한 번도 겪지 않는 엔지니어링 마일스톤을 달성했습니다.
이 장에서는 학습 불안정성의 근본적인 원인을 해부하고, 수천억 개의 파라미터를 가진 모델이 초기화부터 수렴까지 안정적인 상태를 유지하도록 돕는 아키텍처적 개입(architectural interventions)에 대해 깊이 파헤칩니다.
🔍 케이스 스터디: 학습 안정성과의 사투 (OPT-175B)
Meta AI의 OPT-175B 학습 과정은 전례 없는 공개 로그북을 통해 기록된 기념비적인 엔지니어링 여정이었습니다. 팀은 학습 도중 로스가 갑자기 발산하는 70회 이상의 주요 로스 스파이크(Loss Spike)에 직면했습니다.
기술적 심층 분석:
- 발생 원인: 상당수의 스파이크는 데이터셋 내의 특정 “독성” 데이터 클러스터, 즉 고도로 반복적인 시퀀스(예: “the the the…”)나 잘못된 형식의 HTML 데이터에서 기인했습니다. 이러한 패턴은 트랜스포머 초기 레이어에서 갑작스러운 그래디언트 폭주를 유발했습니다.
- 하드웨어 요인: GPU ECC 오류 및 All-Reduce 통신 과정에서의 네트워크 타임아웃은 그래디언트 오염을 초래했고, 이는 로스 스파이크로 나타나기 전까지 모델 상태를 서서히 오염시켰습니다.
엔지니어링 해결책:
- 체크포인트 롤백 및 데이터 스킵: 가장 빈번하게 사용된 방법입니다. 스파이크 발생 전 약 100 스텝 지점의 체크포인트로 되돌린 후, 문제를 일으킨 데이터 배치를 건너뛰고 학습을 재개했습니다.
- 학습률(Learning Rate) 조정: 불안정한 구간을 통과하기 위해 일시적으로 학습률을 10분의 1로 낮추어 로스 표면을 완만하게 탐색했습니다.
- 옵티마이저 초기화(Optimizer Reset): 단순히 체크포인트에서 재개하는 것뿐만 아니라, Adam 옵티마이저의 모멘트(moments) 상태를 초기화하는 것이 중요했습니다. 초기화하지 않을 경우, 이전의 잘못된 그래디언트 방향에 대한 ‘관성’이 재개된 학습에도 악영향을 미치기 때문입니다.
핵심 교훈: 대규모 모델 학습은 아키텍처 설계만큼이나 데이터 품질 관리와 하드웨어 안정성 확보가 중요합니다.
참고 문헌: Zhang, S., et al. (2022). “OPT: Open Pre-trained Transformer Language Models.”
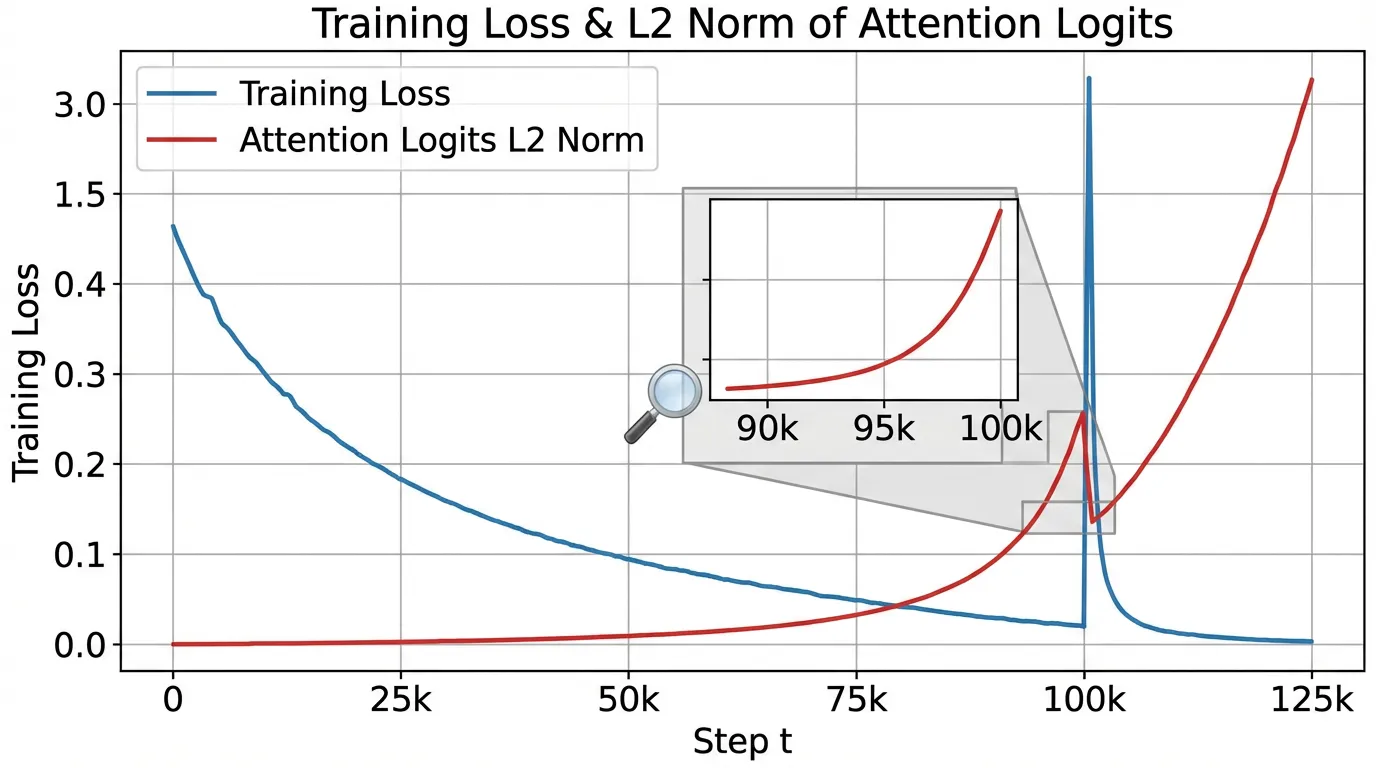
1. The Anatomy of a Loss Spike
불안정성을 예방하려면 먼저 그 기계적 원인을 이해해야 합니다. Loss Spike 는 순식간에 발생하지 않습니다. 이는 보이지 않게 누적된 수치적 질병의 말기 증상입니다.
최근 분석 [2] 에 따르면, 학습 발산(divergence)은 거의 항상 특정 선형 레이어—특히 Query/Key 프로젝션, 출력 프로젝션, FFN의 두 번째 FC 레이어—출력의 norm이 통제할 수 없이 커지는 현상을 동반합니다.
 Source: Generated by Gemini
Source: Generated by Gemini
The Logit Growth Problem
학습이 진행될수록 모델의 확신(confidence)은 강해집니다. Cross-entropy 손실을 줄이기 위해, 네트워크는 정답 토큰의 로짓(logit)을 극단적인 양수 값으로 밀어 올립니다.
- Attention Saturation: Query와 Key 벡터의 norm이 제어 없이 커지면, 내적 은 거대한 스칼라 값을 생성합니다.
- Softmax Collapse: 이 거대한 스칼라 값이 softmax 함수를 통과하면, 확률 분포가 거의 원-핫 벡터(예:
[0.0001, 0.9998, 0.0001])처럼 붕괴됩니다. - Gradient Starvation & Explosion: 정답이 아닌 토큰들의 그래디언트는 소실되는 반면, 정답 토큰의 그래디언트는 과도하게 민감해집니다. 다음 배치에서 노이즈가 있거나 분포를 벗어난(OOD) 토큰이 하나라도 섞여 있으면 천문학적인 그래디언트가 발생하고, 이는 역전파되어 AdamW 옵티마이저의 모멘텀 버퍼를 오염시키며 가중치 분포를 영구적으로 파괴합니다.
2. Architectural Stabilizers
현대의 파운데이션 모델들은 학습률을 낮추는 것과 같은 하이퍼파라미터 튜닝(이는 최종 성능 저하를 초래함)에 의존하는 대신, 내부 활성화 함수(activations)의 범위를 엄격하게 제한하도록 아키텍처 자체를 수정합니다.
2.1 QK Layer Normalization
표준 Transformer는 어텐션 블록의 입력에 LayerNorm (또는 RMSNorm)을 적용합니다. 하지만 와 프로젝션은 여전히 값이 표류(drift)할 수 있습니다. 내적을 수행하기 전 에 Query와 Key 벡터에 직접 추가적인 정규화를 적용함으로써, 어텐션 로짓이 은닉 차원(hidden dimension) 크기에 의해 엄격하게 제한되도록 강제합니다.
이는 어텐션 엔트로피의 붕괴를 막아주며, 엔지니어들이 발산 위험 없이 학습률을 최대 1.5배까지 안전하게 높일 수 있게 해줍니다 [2].
2.2 Softmax Capping (Logit Capping)
QK Norm을 적용하더라도 cross-entropy 손실 함수로 전달되는 최종 로짓은 너무 커질 수 있습니다. Gemma나 Grok과 같은 모델들은 Softmax Capping 을 사용하여, 스케일이 조정된 쌍곡탄젠트(hyperbolic tangent) 함수를 통해 pre-softmax 로짓을 고정된 범위 로 제한합니다.
일반적으로 는 30.0과 같은 값으로 설정됩니다. 의 선형 구간(0에 가까운 부근)에서는 그래디언트가 정상적으로 흐릅니다. 로짓이 에 가까워질수록 그래디언트는 자연스럽게 감소하며, 이는 모델이 과도한 확신을 갖는 것을 방지하는 자동적이고 미분 가능한 그래디언트 클리퍼(gradient clipper) 역할을 합니다.
2.3 The -loss (Auxiliary Logit Penalty)
PaLM [3] 의 학습 과정에서 도입된 -loss 는 기본 cross-entropy 손실에 추가되는 보조 목적 함수입니다. 이는 파티션 함수(softmax의 분모)의 로그 값에 페널티를 부여하여, 최대 로짓이 0에 가깝게 유지되도록 권장합니다.
여기서 는 일반적으로 매우 작은 상수(예: )입니다. 이 페널티는 거대한 로짓 그래디언트에 의해 옵티마이저의 지수 이동 평균(exponential moving averages)이 오염되는 것을 방지합니다.
3. Engineering Stable PyTorch Components
실제 PyTorch 환경에서 이러한 안정성 메커니즘을 구현해 보겠습니다. 다음 코드는 100B+ 규모의 학습을 위해 설계된 견고한 Attention 레이어와 사용자 정의 Cross-Entropy 손실 함수를 보여줍니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class RMSNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def forward(self, x):
variance = x.pow(2).mean(-1, keepdim=True)
x_norm = x * torch.rsqrt(variance + self.eps)
return self.weight * x_norm
class StableAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, logit_cap: float = 30.0):
super().__init__()
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.logit_cap = logit_cap
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, d_model, bias=False)
self.v_proj = nn.Linear(d_model, d_model, bias=False)
self.o_proj = nn.Linear(d_model, d_model, bias=False)
# Stability: QK Normalization
self.q_norm = RMSNorm(self.head_dim)
self.k_norm = RMSNorm(self.head_dim)
def forward(self, x):
B, L, D = x.size()
q = self.q_proj(x).view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(x).view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
# Apply RMSNorm to Q and K independently per head
q = self.q_norm(q)
k = self.k_norm(k)
# Scaled Dot-Product
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)
# Stability: Softmax Capping (Logit Capping)
if self.logit_cap > 0:
scores = self.logit_cap * torch.tanh(scores / self.logit_cap)
attn_weights = F.softmax(scores, dim=-1)
out = torch.matmul(attn_weights, v)
out = out.transpose(1, 2).contiguous().view(B, L, D)
return self.o_proj(out)
def cross_entropy_with_zloss(logits: torch.Tensor, targets: torch.Tensor, z_loss_weight: float = 1e-4):
"""
Computes Cross Entropy Loss with an auxiliary z-loss to prevent logit drift.
"""
# Standard Cross Entropy
ce_loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
# Compute z-loss: log^2(sum(exp(logits)))
# We use logsumexp for numerical stability
log_z = torch.logsumexp(logits, dim=-1)
z_loss = (log_z ** 2).mean()
return ce_loss + (z_loss_weight * z_loss)4. Advanced Stability: MoE and Decoupling
Auxiliary-Loss-Free Load Balancing
Mixture-of-Experts (MoE) 모델에서 토큰이 전문가(experts)에게 불균등하게 라우팅되면 하드웨어 병목 현상(expert collapse)이 발생합니다. 역사적으로, 균등한 분배를 강제하기 위해 학습 목적 함수에 보조 손실(auxiliary loss) 을 추가했습니다. 그러나 이 보조 손실은 모델의 그래디언트를 물리적으로 변경하며, 종종 언어 모델링의 주 목적과 충돌하여 불안정성을 유발합니다.
DeepSeek-V3 [1] 는 Auxiliary-Loss-Free Load Balancing 을 도입했습니다. 손실 함수를 수정하는 대신, 라우팅 로짓에 더해지는 편향(bias) 항을 동적으로 조정합니다.
결정적으로, 이 편향은 수학적으로 그래디언트 테이프(gradient tape)에서 분리(detach) 됩니다 (bias.detach()). 라우팅 메커니즘은 순전파(forward pass) 중에 완벽한 균형을 달성하지만, 역전파(backward pass)는 순수한 토큰-전문가 친화도에 기반해서만 라우터 가중치를 업데이트합니다. 이를 통해 MoE 학습 발산의 주요 원인을 완전히 제거했습니다.
Scale-Distribution Decoupling (SDD)
매우 깊은 Post-Norm 아키텍처에서는 깊이에 따라 잔차 스트림(residual stream)의 분산이 선형적으로 증가하여 그래디언트 폭발을 초래합니다. Wang et al. (2025) 은 Scale-Distribution Decoupling (SDD) [4] 을 제안했습니다. SDD는 fully-connected 레이어에서 가중치 행렬의 스케일(크기)과 분포(방향)를 명시적으로 분리합니다. 활성화 이전 단계(pre-activations)에 직접 정규화 메커니즘을 적용하고 학습 가능한 스케일링 벡터에 의존함으로써, SDD는 그래디언트가 잘 조절된 상태를 유지하도록 보장합니다. 이는 복잡한 초기화 트릭 없이도 Post-Norm Transformer가 안정적으로 확장될 수 있게 합니다.
5. Interactive: The Loss Spike Simulator
이러한 아키텍처적 선택이 어떻게 발산을 방지하는지 직관적으로 이해하기 위해, 아래의 시뮬레이터를 조작해 보십시오. 이는 가상의 학습 과정에서 내부 norm의 성장을 모델링합니다. QK-Norm과 Softmax Capping을 활성화하는 것이 노이즈가 섞인 데이터 배치에 대해 어떻게 ‘충격 흡수기(shock absorber)’ 역할을 하는지 관찰해 보세요.
Training Stability Simulator
6. Mixed Precision (FP8) Stability
모델이 조 단위 파라미터 영역으로 확장됨에 따라, BF16에서의 학습은 메모리 대역폭의 병목에 부딪히게 됩니다. 업계는 FP8 (8-bit floating point) 혼합 정밀도로 공격적으로 이동하고 있습니다.
FP8은 다이내믹 레인지를 심각하게 제한합니다 (E4M3 포맷에서 표현 가능한 최대값은 448입니다). 활성화 값의 norm이 커지면 즉시 FP8의 한계를 넘어 오버플로우가 발생하고, 이는 NaN 그래디언트를 초래합니다.
FP8에서 안정적으로 학습하기 위해 현대의 프레임워크들은 Fine-grained Quantization (세밀한 양자화)을 사용합니다. 단일 스케일 팩터로 전체 텐서를 양자화하는 대신, 텐서를 블록 단위(예: 타일)로 나누고 각 블록이 고유한 FP32 스케일 팩터를 갖게 합니다. 나아가, MLA(Multi-head Latent Attention)의 잠재 벡터(latent vectors)와 같은 중요한 “병목” 텐서들은 분산이 너무 커서 FP8로는 치명적인 정보 손실 없이 캡처할 수 없기 때문에 더 높은 정밀도(BF16)로 유지됩니다.
Summary and Next Steps
안정성은 더 이상 하이퍼파라미터 튜닝이라는 흑마법의 영역이 아닙니다. 이는 엄격한 아키텍처 공학입니다. QK Norm, Softmax Capping, 그리고 분리된 라우팅(decoupled routing)을 통해 내부 표현의 크기를 엄격하게 제어함으로써, 엔지니어들은 학습률을 안전하게 높이고 FP8과 같은 공격적인 저정밀도 포맷을 활용할 수 있습니다.
모델 아키텍처가 안정화되었으니, 다음 과제는 이 거대한 연산 그래프를 물리적 하드웨어에 매핑하는 것입니다. Chapter 7: Training Optimization & Systems 에서는 3D 병렬화, ZeRO 최적화, 그리고 Flash Attention이 어떻게 이 안정적인 행렬들을 수만 개의 GPU에 걸쳐 물리적으로 분산시키는지 탐구할 것입니다.
Quizzes
Quiz 1: 왜 QK LayerNorm이 단순히 전역 학습률(global learning rate)을 낮추는 것보다 Loss Spike를 예방하는 데 더 효과적일까요?
학습률을 낮추는 것은 전체 학습 과정을 균일하게 늦추어, 최종 모델의 성능과 수렴 속도를 저하시킵니다. 반면 QK LayerNorm은 국소적이고 동적으로 작용합니다. 이는 전역 스텝 크기와 무관하게 어텐션 메커니즘의 엔트로피를 구체적으로 제한함으로써, 다른 레이어의 학습에 페널티를 주지 않고 스파이크를 촉발하는 특정 조건(어텐션 붕괴)만을 방지합니다.
Quiz 2: Softmax Capping에서 로짓이 극단적으로 커질 때 함수는 역전파(그래디언트 흐름)에 어떤 영향을 미칩니까?
의 도함수는 입니다. 입력 로짓이 매우 커져서 제한 값 에 접근하면, 는 1 또는 -1에 가까워지고 그 도함수는 0에 수렴합니다. 따라서 로짓이 극단적일 때 그래디언트는 자연스럽게 0에 가깝게 축소되며, 이는 과도한 확신을 가진 예측이 거대한 가중치 업데이트를 일으키는 것을 막는 미분 가능한 자동 그래디언트 클리퍼 역할을 합니다.
Quiz 3: DeepSeek-V3의 Auxiliary-loss-free balancing에서 동적 편향(dynamic bias)이 그래디언트 테이프에서 반드시 분리(
동적 편향이 분리되지 않으면, 역전파 과정에서 주 언어 모델링 손실을 최소화하기 위해 편향에 대한 그래디언트가 계산됩니다. 옵티마이저는 자연스럽게 이 편향을 취소하려고 시도할 것입니다 (편향이 로드 밸런싱을 위해 인위적으로 토큰을 최적이 아닌 전문가에게 강제로 보내고 있기 때문입니다). 이를 분리함으로써 편향은 순수하게 순전파 라우팅 개입으로만 작용하고, 라우터 네트워크는 충돌하는 그래디언트 신호 없이 목적 함수로부터 순수하게 학습할 수 있습니다..detach())되어야 하는 이유는 무엇입니까?
Quiz 4: Scale-Distribution Decoupling (SDD)이 해결하고자 하는, 깊은 Post-Norm Transformer 구조에서의 불안정성의 주된 원인은 무엇입니까?
Post-Norm 아키텍처에서는 잔차 분기(residual branch)의 출력이 후속 정규화 없이 메인 잔차 스트림에 직접 더해집니다. 네트워크가 깊어질수록 잔차 스트림의 분산(스케일)이 선형적으로 증가합니다. 이러한 무제한적인 성장은 역전파 중 그래디언트 폭발을 초래합니다. SDD는 가중치의 스케일과 분포를 명시적으로 분리하여, 소실(vanishing) 초기화 기법에 의존하지 않고 수학적으로 분산을 제어함으로써 이 문제를 해결합니다.
References
- DeepSeek-V3 Technical Report. arXiv:2412.19437
- Methods of Improving LLM Training Stability. arXiv:2410.16682
- PaLM: Scaling Language Modeling with Pathways. arXiv:2204.02311
- Wang, Y., Zhuo, Z., Zeng, Y., Zhou, X., Yang, J., & Li, X. (2025). Scale-Distribution Decoupling: Enabling Stable and Effective Training of Large Language Models. arXiv:2502.15499.