13.1 PTQ vs QAT
이전 장에서 우리는 긴 컨텍스트(Long Context) 추론 시 발생하는 동적 메모리(KV Cache) 오버헤드를 Chunked Prefill과 분리형 서빙(Disaggregated Serving) 같은 시스템 엔지니어링으로 해결하는 방법을 살펴보았습니다. 하지만 컨텍스트 윈도우를 최적화하더라도, 모델의 정적 가중치(Static Weights) 자체가 차지하는 거대한 메모리 장벽은 그대로 남아있습니다. 16비트 정밀도(BF16)를 사용하는 70B(700억 개) 파라미터 모델은 가중치를 메모리에 올리는 데만 140GB 이상의 VRAM을 요구하며, 이는 소비자용 하드웨어에서의 구동을 원천적으로 차단하고 기업의 서빙 인프라 비용을 기하급수적으로 증가시킵니다.
이 물리적 한계를 돌파하기 위한 핵심 기술이 바로 양자화 (Quantization)입니다. 양자화는 고정밀 부동소수점(FP32/BF16) 값을 더 낮은 정밀도의 이산적인 정수 구간(INT8, INT4 등)으로 매핑하는 수학적 압축 과정입니다.
양자화 연구 분야는 모델이 이러한 압축 과정에서 발생하는 ‘노이즈(오차)‘를 언제, 그리고 어떻게 대면하는지에 따라 두 가지 패러다임으로 나뉩니다. 바로 학습 후 양자화 (Post-Training Quantization, PTQ)와 양자화 인지 학습 (Quantization-Aware Training, QAT)입니다.
1. 선형 양자화의 수학적 이해 (Linear Quantization)
두 패러다임을 나누기에 앞서, 기저에 깔린 공통적인 수학적 원리를 이해해야 합니다. 가장 널리 사용되는 압축 방식은 선형 양자화 (Affine Quantization)입니다. 이 방식은 스케일 팩터(Scale Factor) 와 제로 포인트(Zero-point) 를 사용하여 고정밀 텐서 를 양자화된 정수 텐서 로 매핑합니다.
추론 시 하드웨어는 행렬 곱셈에 이 정수 연산을 사용하며, 그 결과는 다시 부동소수점 표현으로 역양자화(Dequantization)됩니다.
이때 원본 와 복원된 사이의 차이가 바로 양자화 오차 (Quantization Error)입니다. PTQ와 QAT의 근본적인 차이는 이 오차를 시스템이 어떻게 다루느냐에 있습니다.
2. Post-Training Quantization (PTQ): 수동적 접근
PTQ 는 철저히 수동적인 후속(Downstream) 프로세스입니다. 모델은 전체 정밀도(Full Precision)로 학습을 완료합니다. 학습이 끝나면 가중치를 동결(Freeze)하고, 변환 스크립트를 통해 이를 낮은 정밀도로 매핑합니다.
연속적인 분포를 이산적인 구간으로 매핑해야 하므로, 최적의 스케일()과 제로 포인트()를 결정하는 과정이 필수적입니다. 이를 캘리브레이션 (Calibration) 단계라고 부릅니다. 엔지니어는 소규모 데이터셋(일반적으로 100~1,000개의 샘플)을 모델에 통과시켜 모든 레이어의 활성화(Activation) 범위(최소/최대값)를 관찰하고 스케일을 계산합니다.
캘리브레이션의 함정 (The Calibration Trap)
PTQ는 연산량이 적어 수 분에서 수 시간 내에 완료된다는 장점이 있지만, 시스템적으로 매우 취약합니다. 캘리브레이션에 사용된 데이터셋이 실제 프로덕션 환경의 데이터 분포를 완벽하게 대변하지 못한다면, 계산된 활성화 스케일은 너무 좁게 설정됩니다.
이후 프로덕션 환경에서 모델이 분포 외(Out-of-distribution) 입력을 만나게 되면, 활성화 값이 캘리브레이션된 범위를 초과하여 심각한 클리핑(Clipping, 잘림 현상)이 발생합니다. 이는 모델의 순전파(Forward-pass) 논리를 파괴하고, 종종 Perplexity(혼란도)가 급격히 치솟는 치명적인 성능 저하를 초래합니다. 대형 언어 모델에서 발생하는 거대한 활성화 이상치(Activation Outliers)는 PTQ를 극도로 어렵게 만드는 주범입니다.
PyTorch를 이용한 캘리브레이션 루프 엔지니어링
아래는 선형 레이어(Linear Layer)에 대해 대칭적(Symmetric) Min-Max 캘리브레이션을 수행하는 PyTorch 구현 예시입니다.
import torch
import torch.nn as nn
class PTQLinear(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_features, in_features))
self.bias = nn.Parameter(torch.zeros(out_features))
self.weight_scale = None
self.act_scale = None
def calibrate(self, x):
"""
절대 최댓값을 기반으로 스케일을 캘리브레이션합니다.
실제 프로덕션에서는 이동 평균(Moving Average)이나 KL 발산(KL-divergence)을
사용하여 이상치(Outlier)에 대한 견고성을 높입니다.
"""
# 활성화 값 캘리브레이션 (INT8 범위: -128 ~ 127)
max_act = torch.max(torch.abs(x))
self.act_scale = max_act / 127.0
# 가중치 캘리브레이션
max_w = torch.max(torch.abs(self.weight))
self.weight_scale = max_w / 127.0
def forward(self, x):
if self.weight_scale is None:
# 캘리브레이션 이전의 일반적인 순전파
return nn.functional.linear(x, self.weight, self.bias)
# 양자화된 추론 시뮬레이션 (실제 하드웨어에서는 INT8/INT32로 실행됨)
q_w = torch.clamp(torch.round(self.weight / self.weight_scale), -128, 127)
q_x = torch.clamp(torch.round(x / self.act_scale), -128, 127)
# INT32 누산 (Accumulation)
out = nn.functional.linear(q_x, q_w)
# 다음 레이어를 위해 부동소수점으로 역양자화 (Dequantize)
return out * (self.weight_scale * self.act_scale) + self.bias
# 실행 예시
layer = PTQLinear(128, 64)
calibration_data = torch.randn(32, 128) # 실제 환경의 데이터를 완벽히 대변해야 함!
layer.calibrate(calibration_data)
output = layer(calibration_data)
print(f"Quantized Output Shape: {output.shape}")3. Quantization-Aware Training (QAT): 능동적 접근
PTQ는 8비트 이하로 압축할 때 심각한 ‘정확도 하한선(Accuracy Floor)‘에 부딪힙니다. LLM을 PTQ를 통해 8비트에서 4비트로 낮추면, 수동적으로 무시하기에는 반올림 오차(Rounding Error)가 너무 커지기 때문에 모델이 완전히 망가지는 경우가 많습니다.
QAT 는 이 한계를 돌파합니다. 사후에 양자화하는 대신, QAT는 학습 또는 파인튜닝 과정 중에 연산 그래프(Computational Graph) 내부에 ‘가짜 양자화(Fake Quantization)’ 노드를 삽입합니다. 모델의 옵티마이저(Optimizer)는 순전파 시에 양자화 오차를 직접 ‘목격’하고, 역전파(Backward-pass) 시에 이를 보상하기 위해 마스터 가중치를 조정합니다. 즉, 모델이 저정밀도 환경에서 살아남는 법을 스스로 학습하는 능동적인 방식입니다.
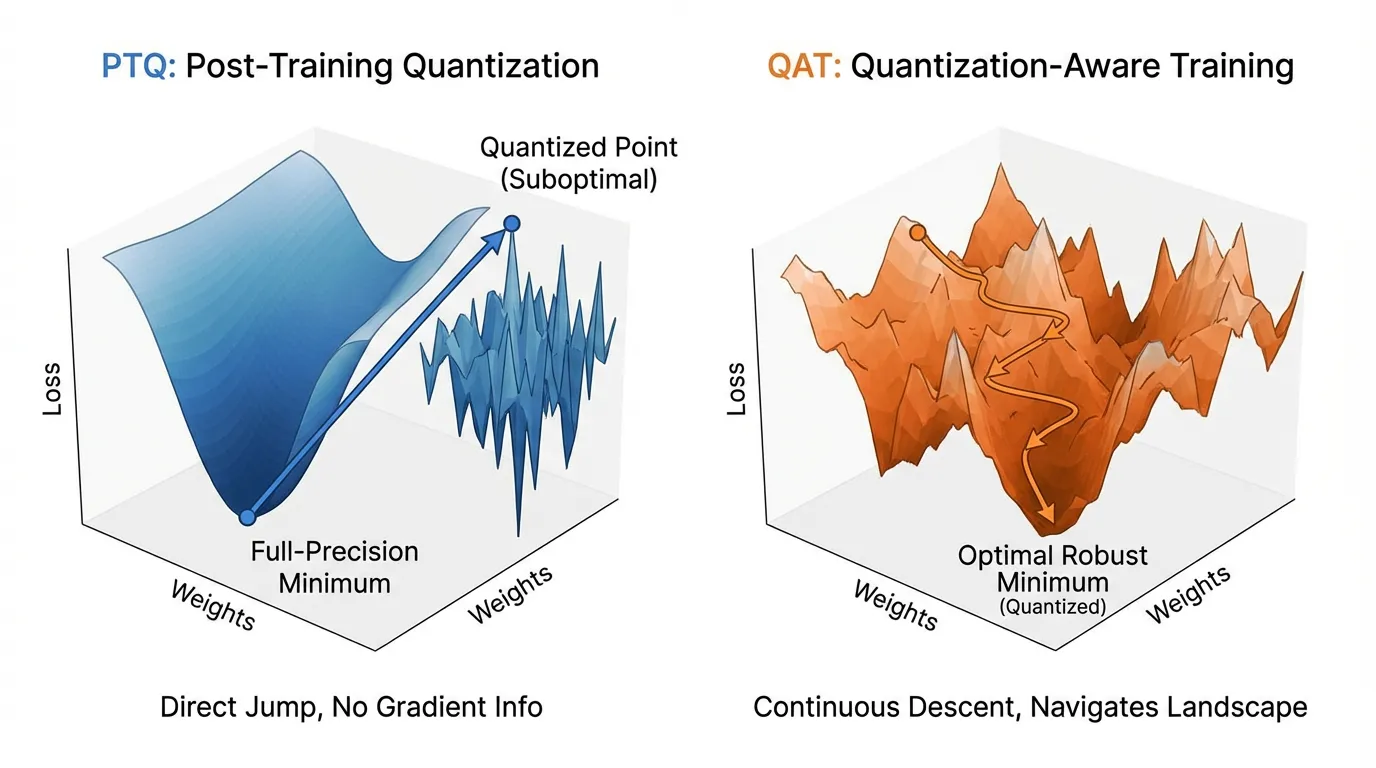 Source: Generated by Gemini. (좌) PTQ는 학습이 끝난 후 강제로 가중치를 이동시키므로 손실 지형(Loss Landscape)에서 최적점을 벗어납니다. (우) QAT는 양자화된 그리드 위에서 직접 최적화를 수행하여 새로운 로컬 미니마를 찾습니다.
Source: Generated by Gemini. (좌) PTQ는 학습이 끝난 후 강제로 가중치를 이동시키므로 손실 지형(Loss Landscape)에서 최적점을 벗어납니다. (우) QAT는 양자화된 그리드 위에서 직접 최적화를 수행하여 새로운 로컬 미니마를 찾습니다.
Straight-Through Estimator (STE)의 수학적 속임수
QAT를 구현할 때 직면하는 가장 큰 수학적 장애물은 round() (반올림) 함수입니다.
round() 와 같은 계단 함수의 미분값은 거의 모든 곳에서 0이며, 계단 부분에서는 정의되지 않습니다. 표준 역전파를 그대로 실행하면, 양자화 노드에서 기울기(Gradient)가 0이 되어 가중치 업데이트가 완전히 멈추게 됩니다.
이를 해결하기 위해 QAT는 Straight-Through Estimator (STE) [1] 를 사용합니다. 역전파 과정에서 STE는 round() 연산을 단순히 무시하고, 해당 노드의 로컬 기울기를 로 간주하여 기울기를 통과시킵니다.
STE를 활용한 Fake Quantization 엔지니어링
import torch
import torch.nn as nn
class RoundSTE(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
return torch.round(x)
@staticmethod
def backward(ctx, grad_output):
# Straight-Through Estimator: 기울기를 변경 없이 그대로 통과시킴
return grad_output
def fake_quantize(tensor, scale, bits=4):
q_max = (1 << (bits - 1)) - 1
q_min = -(1 << (bits - 1))
# STE를 사용한 스케일링 및 반올림
scaled = tensor / scale
rounded = RoundSTE.apply(scaled)
# 클리핑 및 역양자화
clipped = torch.clamp(rounded, q_min, q_max)
return clipped * scale
class QATLinear(nn.Module):
def __init__(self, in_features, out_features, bits=4):
super().__init__()
# 마스터 가중치는 전체 정밀도(FP32/BF16)로 유지됨
self.weight = nn.Parameter(torch.randn(out_features, in_features) * 0.02)
self.bias = nn.Parameter(torch.zeros(out_features))
self.bits = bits
def forward(self, x):
# 가중치에 대한 스케일을 동적으로 계산
w_max = torch.max(torch.abs(self.weight))
q_max = (1 << (self.bits - 1)) - 1
w_scale = w_max / q_max
# 가짜 양자화(Fake Quantization) 적용
q_weight = fake_quantize(self.weight, w_scale, self.bits)
# 순전파는 양자화된 가중치를 사용하지만, 연산 그래프는
# STE를 통해 전체 정밀도인 self.weight로 기울기를 라우팅함.
return nn.functional.linear(x, q_weight, self.bias)
# 실행 예시
layer = QATLinear(128, 64, bits=4)
x = torch.randn(32, 128)
out = layer(x)
loss = out.sum()
loss.backward()
# 기울기가 전체 정밀도 가중치로 성공적으로 흘러 들어옴!
print(f"Master Weight Gradient Shape: {layer.weight.grad.shape}")4. 최신 SOTA: 메모리 한계의 극복과 혼합 정밀도
역사적으로 QAT는 엄청난 컴퓨팅 자원을 요구하는 ‘사치스러운’ 기술이었습니다. FP32 마스터 가중치, INT4 가짜 양자화 가중치, 그리고 FP32 기울기를 동시에 메모리에 올려야 했기 때문에, 일반적인 학습보다 VRAM 요구량이 두 배 이상 높았습니다.
VRAM 세금(Tax)의 극복
최근 Unsloth [2] 와 같은 프레임워크들은 QAT를 대중화시켰습니다. 이들은 가짜 양자화 연산을 행렬 곱셈에 직접 융합(Fusion)하는 커스텀 Triton 커널을 작성하여, SRAM 내부에서 실시간(On-the-fly)으로 양자화된 가중치를 계산합니다. 이를 통해 양자화된 텐서를 고대역폭 메모리(HBM)에 물리적으로 구체화(Materialize)할 필요가 없어졌고, QAT의 메모리 사용량을 표준 LoRA 파인튜닝 수준으로 대폭 낮추었습니다.
혼합 정밀도 (Mixed-Precision)와 스케일링
트랜스포머의 모든 레이어가 양자화 노이즈에 동일하게 반응하는 것은 아닙니다. 기초적인 특징(Feature)을 추출하는 초기 레이어와 최종 예측을 수행하는 프로젝션 레이어는 양자화에 매우 민감한 반면, 중간에 위치한 중복적인 레이어들은 노이즈에 강건합니다.
최근의 양자화 연구 [3] 는 혼합 정밀도 양자화 (Mixed-Precision Quantization)를 제안합니다. 일괄적으로 4비트를 적용하는 대신, 학습 가능한 스케일링 팩터()를 도입하여 레이어의 민감도 와 가중치 분산 에 따라 비트를 동적으로 할당합니다. 민감한 레이어에는 INT8을, 강건한 레이어에는 INT4/INT2를 할당함으로써, 전체 정밀도 모델 대비 성능 저하를 5% 이내로 방어하면서도 모델 크기를 70% 가까이 줄이는 SOTA 성능을 달성하고 있습니다.
5. 인터랙티브 시각화: 양자화 오차 시뮬레이터
아래의 시각화 컴포넌트는 높은 분산을 가진 가중치 분포에서 낮은 비트(Bit-width)로 PTQ를 수행할 때 왜 심각한 오차가 발생하는지, 그리고 QAT가 학습을 통해 어떻게 가중치 분포 자체를 양자화 그리드(Bins)에 맞게 능동적으로 변형(Shift)시키는지를 보여줍니다.
In PTQ, the weight distribution is fixed, so the rounding error area increases rapidly as the bit-width decreases.
6. 요약 및 비교
| 특징 | Post-Training Quantization (PTQ) | Quantization-Aware Training (QAT) |
|---|---|---|
| 복잡도 | 낮음 (수 분 ~ 수 시간 소요) | 높음 (전체 학습 또는 파인튜닝 필요) |
| 필요 데이터 | 소규모 캘리브레이션 셋 (100~1000 샘플) | 전체 학습/파인튜닝 데이터셋 |
| 정확도 유지력 | 8비트에서는 우수함; 4비트 이하에서는 취약 | 극단적인 저비트(4-bit, 2-bit, 1.58-bit)에서 압도적 |
| 메모리 오버헤드 | 거의 없음 | 역사적으로 높았으나, 현재 융합 커널(Fused Kernels)로 해결됨 |
| 최적 사용 사례 | 8비트 모델의 빠르고 경제적인 프로덕션 배포 | 온디바이스(Edge) AI 및 초경량화 SOTA LLM 구축 |
다음 섹션에서는 이러한 이론적 패러다임에서 파생된 구체적인 알고리즘들(GPTQ, AWQ, GGUF)을 살펴보고, 최신 하드웨어 아키텍처 위에서 양자화된 텐서들이 물리적으로 어떻게 배치되고 연산되는지 깊이 파헤쳐 보겠습니다.
Quizzes
Quiz 1: 캘리브레이션 데이터셋에서 완벽한 성능을 보인 PTQ 모델이, 실제 프로덕션 환경에 배포되었을 때 갑작스럽게 Perplexity가 폭발하며 텍스트 생성에 실패하는 근본적인 이유는 무엇입니까?
캘리브레이션 데이터셋이 실제 프로덕션 데이터의 분포를 완벽히 대변하지 못했기 때문입니다. 모델이 프로덕션 환경에서 분포 외(OOD) 입력을 받게 되면, 내부 레이어의 활성화(Activation) 값이 캘리브레이션 단계에서 계산된 스케일 범위를 초과하게 됩니다. 이로 인해 심각한 클리핑(Clipping) 현상이 발생하고, 순전파 로직이 파괴되어 모델이 의미 있는 토큰을 생성할 수 없게 됩니다.
Quiz 2: QAT(Quantization-Aware Training)의 순전파 과정에서는 저정밀도를 시뮬레이션하기 위해
round() (반올림) 함수가 사용됩니다. 역전파 과정에서 Straight-Through Estimator (STE)라는 수학적 기법이 반드시 필요한 이유는 무엇입니까?round() 와 같은 계단 함수의 수학적 미분값은 거의 모든 구간에서 0이며, 정수 지점에서는 정의조차 되지 않습니다. 만약 표준 역전파 알고리즘을 그대로 적용한다면, 연산 그래프를 타고 내려오던 기울기(Gradient)가 양자화 노드에서 0과 곱해져 소멸되어 버립니다. STE는 이 노드에서의 로컬 기울기를 강제로 1로 근사하여 통과시킴으로써, 손실(Loss)에 대한 기울기가 전체 정밀도(FP32) 마스터 가중치까지 무사히 도달해 업데이트될 수 있도록 만듭니다.
Quiz 3: 트랜스포머 모델을 양자화할 때, 모든 레이어에 일괄적으로 4비트를 적용하는 균일 양자화(Uniform Quantization)가 최적의 성능을 내지 못하는 이유는 무엇입니까?
트랜스포머 내부의 각 레이어는 양자화 노이즈에 대한 민감도가 다릅니다. 기초적인 특징을 추출하는 첫 번째 레이어나 최종 예측을 담당하는 마지막 레이어는 노이즈에 매우 민감하여 4비트로 압축 시 치명적인 정보 손실이 발생합니다. 반면 중간 레이어들은 중복된 정보를 많이 포함하고 있어 강건합니다. 따라서 민감도에 따라 INT8과 INT4를 섞어 쓰는 혼합 정밀도(Mixed-Precision) 방식이 정확도와 메모리 압축률 사이의 최적의 트레이드오프를 제공합니다.
Quiz 4: PTQ는 가중치를 4비트 이하로 압축할 때 심각한 ‘정확도 하한선’에 부딪히는 반면, QAT는 성능을 유지할 수 있습니다. 최적화 관점에서 이 두 패러다임의 가장 큰 차이점은 무엇입니까?
PTQ는 수동적(Passive)인 프로세스입니다. 이미 학습이 끝난 가중치를 가장 가까운 양자화 그리드(Bin)로 강제 이동시키며, 이때 발생하는 반올림 오차를 피할 수 없는 손실로 받아들입니다. 반면 QAT는 능동적(Active)인 프로세스로, 학습 과정 중에 옵티마이저가 양자화 오차를 직접 확인합니다. 이를 통해 모델은 가중치 자체를 양자화 그리드에 더 잘 들어맞는 방향으로 동적으로 이동시키며, 결과적으로 양자화 노이즈를 ‘학습을 통해 극복’하게 됩니다.
Quiz 5: Straight-Through Estimator (STE)를 사용하여 선형 양자화 노드를 통해 기울기를 역전파하는 명시적인 수학적 공식을 정식화하고, 로컬 기울기의 범위가 어떻게 제한되는지 서술하시오.
순전파 과정을 클리핑 경계 를 포함한 라 하겠습니다. QAT에서 STE를 적용한 역전파 편미분 공식은 지시 함수(Indicator Function)를 사용하여 다음과 같이 근사 및 정의됩니다: . 이 공식은 손실 그래디언트가 클리핑 범위 내에서는 어떠한 왜곡도 없이 연속 가중치 마스터 레이어로 온전히 통과하지만, 가중치 가 최대 양자화 격자를 벗어나 클리핑 구간에 도달하면 그래디언트가 완전히 0으로 소멸되어 업데이트를 차단한다는 점을 보여줍니다.
References
- Bengio, Y., Léonard, N., & Courville, A. (2013). Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. arXiv:1308.3432.
- Unsloth AI. (2024). “Unsloth: Making LLM Fine-tuning 2x faster and use 70% less memory.” GitHub Repository.
- Hasan, J. (2024). Optimizing Large Language Models through Quantization: A Comparative Analysis of PTQ and QAT Techniques. arXiv:2411.06084.