11.5 Video Generation Foundations
이 장의 앞선 섹션들에서는 두 가지 흐름을 보았습니다. Any-to-Any 아키텍처는 여러 모달리티를 공유된 토큰 공간으로 매핑했고, 확산 모델은 이미지 생성의 강력한 백본으로 자리잡았습니다. 출력해야 할 대상이 연속적이고 고차원적인 비디오(video)가 되는 순간, 이 두 흐름은 훨씬 더 큰 시스템 스케일에서 만나게 됩니다. 비디오 생성은 단순히 이미지의 연속을 만들어내는 것이 아닙니다. 그것은 시간에 따른 고차원 물리적 상태의 진화를 예측하는 과정입니다.
역사적으로 비디오 생성은 계단식(cascaded) 3D U-Net (예: Stable Video Diffusion)에 의존해 왔습니다. 이 패러다임에서는 기본 모델이 저해상도 프레임을 생성하고, 별도의 시간적 초해상도(temporal super-resolution) 모델이 움직임을 보간(interpolate)했습니다. 이 모듈식 접근법은 작동은 했지만, 장기적인 일관성과 복잡한 물리 법칙을 처리하는 데 본질적인 한계가 있었습니다. 객체의 형태가 부자연스럽게 변형되거나 기본적인 물리 법칙을 위반하는 일이 빈번했습니다.
2024년에서 2026년 사이의 중요한 돌파구 가운데 하나는 Spatiotemporal Patches (시공간 패치) 위에서 작동하는 Diffusion Transformers (DiT) 의 확산이었습니다. 이는 OpenAI의 Sora [1] 를 통해 널리 주목받았고, 이후 FullDiT [2] 나 Wan 2.1 [3] 과 같은 오픈 웨이트(open-weight) 모델들에 의해 더 확장되었습니다. 비디오를 2D 프레임의 연속이 아닌 연속적인 3D 볼륨으로 취급함으로써, 이 모델들은 객체 영속성, 카메라 움직임, 시간적 일관성 측면에서 이른바 “세계 시뮬레이터(world simulators)“에 가까운 특성을 보여주곤 합니다.
1. Tokenizing the Multiverse: Spacetime Patches
비디오를 Transformer에 입력하려면 먼저 토큰화(tokenization)를 수행해야 합니다. 텍스트에서는 Byte-Pair Encoding (BPE)을 사용하고, 이미지(Vision Transformers)에서는 2D 공간 패치를 사용합니다. 비디오의 경우, 우리는 Spacetime Patches (또는 3D 패치) 를 사용합니다.
현대의 아키텍처는 비디오를 프레임 단위로 처리하는 대신 Spatiotemporal Autoencoder (3D VAE) 를 활용합니다. 이 네트워크는 원시 픽셀 데이터 — 형태가 인 데이터 — 를 공간적 차원과 시간적 차원 양쪽에서 동시에 압축하여 저차원 잠재 공간(latent space)으로 변환합니다.
이 연속적인 잠재 볼륨은 이후 3D 청크(예: latents)로 분할되고, 평탄화(flatten)되어 1D 토큰 시퀀스로 변환됩니다. 이 통합된 시퀀스는 짧은 시간 간격 동안의 시각적 외형과 움직임의 역학(dynamics)을 모두 캡슐화합니다.
아래는 압축된 3D 비디오 잠재 표현(latent)이 어떻게 Diffusion Transformer에 적합한 평탄화된 토큰 시퀀스로 변환되는지 보여주는 현실적인 PyTorch 구현체입니다.
import torch
import torch.nn as nn
class SpacetimePatchEmbed(nn.Module):
"""
3D 잠재 비디오 볼륨을 1D 시공간 토큰 시퀀스로 변환합니다.
"""
def __init__(self, in_channels=4, embed_dim=1152, patch_size=(2, 2, 2)):
super().__init__()
self.patch_size = patch_size
# 3D Convolution은 패치 추출과 선형 투영(linear projection)을 동시에 수행합니다.
# stride를 patch_size와 동일하게 설정하여 겹치지 않는(non-overlapping) 3D 패치를 생성합니다.
self.proj = nn.Conv3d(
in_channels, embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
# x shape: (Batch, Channels, Time, Height, Width)
B, C, T, H, W = x.shape
# 패치 추출 및 투영
x = self.proj(x)
# Output shape: (Batch, embed_dim, T', H', W')
# 여기서 T' = T // patch_size, H' = H // patch_size 등.
# 공간 및 시간 차원을 단일 시퀀스 차원으로 평탄화(flatten)
x = x.flatten(2) # shape: (Batch, embed_dim, T'*H'*W')
# 표준 Transformer의 입력 형태인 (Batch, Sequence_Length, Embed_Dim)에 맞게 전치(transpose)
x = x.transpose(1, 2)
return x
# 압축된 비디오 잠재 표현(latent)을 시뮬레이션하는 실행 예제
batch_size = 2
latent_channels = 4
# 8 fps로 촬영된 2초 분량의 비디오 (총 16 프레임)가
# 3D VAE에 의해 공간적으로 32x32 크기의 잠재 표현으로 압축되었다고 가정합니다.
video_latent = torch.randn(batch_size, latent_channels, 16, 32, 32)
patcher = SpacetimePatchEmbed(in_channels=latent_channels, embed_dim=1152, patch_size=(2, 2, 2))
tokens = patcher(video_latent)
print(f"Input latent shape: {video_latent.shape}")
print(f"Output token sequence shape: {tokens.shape}")
# Sequence length = (16/2) * (32/2) * (32/2) = 8 * 16 * 16 = 2048 토큰2. The Nightmare: Attention in Video
비디오를 1D 시퀀스로 토큰화하는 것은 우아한 방법이지만, 치명적인 연산 병목 현상을 야기합니다. 24 fps의 720p 해상도 10초짜리 비디오는 쉽게 100,000개 이상의 토큰을 생성할 수 있습니다. 표준 self-attention은 시퀀스 길이에 대해 의 시간 및 메모리 복잡도를 가지므로, 모든 토큰에 대해 동시에 어텐션을 계산하는 것은 일반적인 하드웨어에서는 불가능에 가깝습니다.
엔지니어들은 정보를 효율적으로 라우팅하기 위해 여러 가지 아키텍처 전략을 개발했습니다:
- Factorized Attention (Pseudo-3D): 모델이 먼저 동일한 프레임 내의 공간적(spatial) 토큰들에 대해서만 어텐션을 계산한 후, 동일한 공간적 위치에 대해 시간(temporal) 축을 따라 별도의 어텐션 레이어를 계산합니다. 연산 비용은 저렴하지만, 화면을 가로질러 빠르게 이동하는 객체를 추적하는 모델의 능력을 심각하게 제한합니다.
- Full Spatiotemporal Attention: 모든 토큰이 공간과 시간에 걸쳐 다른 모든 토큰을 참조(attend)합니다. FullDiT [2] 와 같은 모델은 이를 처리 가능하게 만들기 위해 하드웨어 친화적인 구현(예: RingAttention)을 활용하며, 결과적으로 압도적으로 우수한 시간적 일관성을 제공합니다.
- Sparse / Compact Attention: NABLA (Neighborhood Adaptive Block-Level Attention)와 같은 최근의 혁신 기술은 어텐션 마스크를 동적으로 제한합니다. 특화된 어텐션 헤드들이 국소적인 3D 이웃 영역, 십자형(cross-shaped) 공간 상호작용, 또는 특정 시간적 거리에만 집중하도록 하여, 생성 품질의 저하 없이 FLOPs를 획기적으로 줄입니다.
Spatiotemporal Attention Routing
Hover over tokens to see the receptive field for each attention mechanism.
Full Spatiotemporal: All tokens attend to each other across space and time. Highest computational complexity ($O(n^2)$), but ensures perfect 3D consistency.
3. The Diffusion Transformer (DiT) Backbone
비디오가 토큰화되고 어텐션 메커니즘이 정의되면, 실제 생성은 Diffusion Transformer [4] 에 의해 처리됩니다. 엄격한 공간적 다운샘플링과 업샘플링 블록에 의존하는 기존의 U-Net과 달리, DiT는 평탄화된 토큰 시퀀스 위에서 작동하므로 임의의 해상도, 종횡비(aspect ratio), 그리고 길이에 본질적으로 유연하게 대응할 수 있습니다.
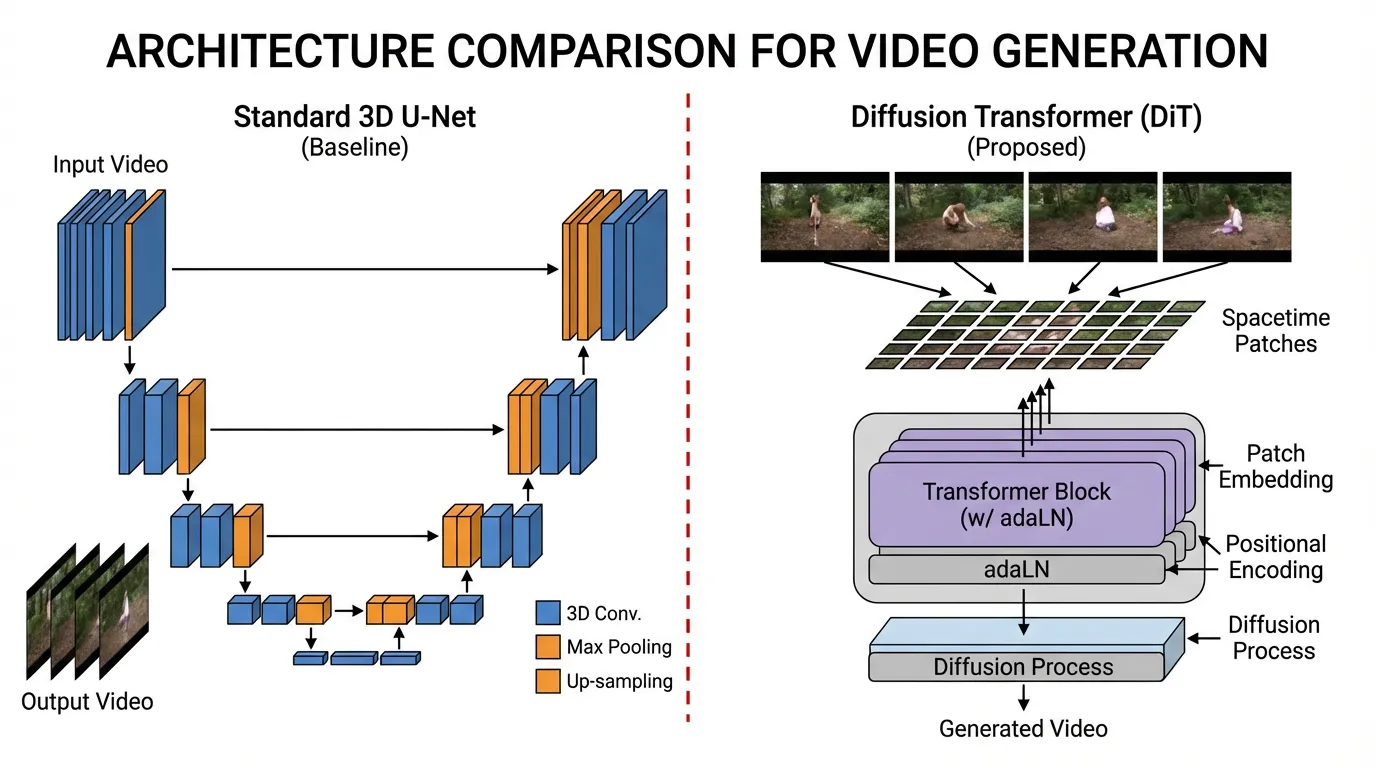 Source: Generated by Gemini
Source: Generated by Gemini
Adaptive Layer Normalization (adaLN)
그렇다면 평탄한 구조의 Transformer는 자신이 무엇을 생성해야 하는지 어떻게 알 수 있을까요? DiT에서는 Adaptive Layer Normalization (adaLN) 을 통해 조건(conditions)이 주입됩니다. 텍스트 프롬프트 임베딩, 현재의 디퓨전 타임스텝(노이즈 레벨), 그리고 기타 전역 조건들이 다층 퍼셉트론(MLP)을 통과합니다. 이 MLP는 모든 self-attention 및 feed-forward 블록 이전에 적용되는 레이어 정규화(layer normalization)의 스케일()과 시프트() 파라미터를 출력합니다. 이는 모든 단일 조건에 대해 연산량이 많은 교차 어텐션(cross-attention) 레이어를 요구하지 않고도, 노이즈 제거(denoising) 과정을 목표 분포로 지속적으로 유도합니다.
In-Context Conditioning
고급 비디오 생성을 위해 사용자는 종종 텍스트 프롬프트, 시작 이미지, 깊이 맵(depth map) 시퀀스, 카메라 궤적 벡터 등 여러 조건을 동시에 제공합니다.
FullDiT와 같은 현대 아키텍처는 In-Context Conditioning 을 채택합니다. 각 조건을 위해 별도의 어댑터 네트워크를 학습시키는 대신 (이는 파라미터 중복과 브랜치 충돌을 유발함), 모델은 모든 조건 신호를 토큰화하고 이를 노이즈가 섞인 비디오 잠재 표현(latents)과 함께 하나의 거대한 시퀀스로 직접 이어 붙입니다(concatenate). 완벽한 self-attention 메커니즘이 카메라의 움직임, 깊이 맵, 텍스트 프롬프트 간의 복잡한 상호작용을 네이티브하게 해결하여 완벽하게 동기화된 움직임을 보장합니다.
4. Emergent World Simulation
DiT가 거대한 규모(예: Wan 2.1 14B 모델)로 확장되고 다양한 물리, 기하학, 조명 환경을 포함하는 수조 개의 시공간 패치 위에서 학습될 때, 매혹적인 현상이 발생합니다. 모델이 world simulator (세계 시뮬레이터) [1] 의 특성을 보이기 시작하는 것입니다.
모델은 노이즈가 섞인 3D 잠재 볼륨이 어떻게 깨끗한 비디오로 변환되는지 예측하도록 강제되기 때문에, 내부적으로 해당 볼륨을 지배하는 규칙을 학습해야만 합니다:
- Object Permanence (객체 영속성): 자동차가 건물 뒤로 주행할 때, self-attention 메커니즘은 자동차의 토큰을 컨텍스트 윈도우(context window) 내에 유지하여 자동차가 반대편에서 올바른 색상과 궤적으로 다시 나타나도록 보장합니다.
- 3D Consistency (3D 일관성): 프롬프트가 “동상 주위를 선회하는 드론”을 지정할 때, 모델은 변화하는 원근법, 조명 반사, 배경의 시차(parallax)를 정확하게 렌더링하여 사실상 암시적인 신경망 렌더링 엔진(neural rendering engine) 역할을 수행합니다.
- Fluid Dynamics & Physics (유체 역학 및 물리): 바위에 부딪히는 물보라나 유리가 깨지는 것과 같은 복잡한 상호작용은 하드코딩된 물리 엔진을 통해 합성되는 것이 아니라, 실제 세계 데이터에서 학습된 시공간 패치들의 통계적 보간(statistical interpolation)을 통해 합성됩니다.
이러한 모델들이 아직 완벽한 시뮬레이터는 아니지만(여전히 불가능한 물리를 환각하거나 객체를 융합하는 오류를 범하기도 함), 방향성은 분명히 흥미롭습니다. 연속적인 멀티모달 데이터 위에서 Diffusion Transformer를 확장(scaling)하는 것은 물리적 규칙성을 더 잘 내재화하는 모델로 가는 가장 유망한 현재 경로들 가운데 하나입니다.
5. 멀티모달의 최전선: Sora, Veo, 그리고 그 너머
멀티모달 학습은 단순한 크로스 모달 정렬(CLIP 등)에서 완전한 Any-to-Any 생성 및 물리적 세계 시뮬레이션으로 빠르게 진화했습니다. 현재의 지형과 앞으로 나아갈 길을 살펴보면 몇 가지 핵심 트렌드가 나타납니다.
최첨단 상업 모델
비디오 생성의 최전선은 방대한 데이터셋으로 학습된 거대한 모델들이 정의하고 있습니다:
- OpenAI Sora: 전례 없는 비디오 품질과 객체 영속성을 보여주며, 세계 시뮬레이터의 초기 프로토타입 역할을 했습니다.
- Google Veo 3.1: 구글의 최첨단 비디오 생성 모델로, 영화와 같은 품질과 프롬프트 준수 능력을 극한으로 끌어올렸습니다.
- Seedance: 창작 산업에서 주목받고 있는 또 다른 고품질 비디오 생성 모델의 예입니다.
생성을 넘어: 월드 모델 (World Models)
월드 모델의 개념은 멀티모달 연구의 핵심이 되고 있습니다. Google Genie 3와 같은 모델은 사용자가 생성된 환경과 상호작용할 수 있도록 함으로써 비디오 생성을 한 단계 더 발전시켰습니다. 단일 이미지나 설명을 입력받아 플레이 가능한 인터랙티브 월드를 생성하여 물리 법칙과 행동-결과 루프를 효과적으로 시뮬레이션합니다.
앞으로 나아갈 길: JEPA 및 대안적 패러다임
현재는 자기회귀(Auto-regressive) 및 확산(Diffusion) 모델이 지배적이지만, 진정한 이해를 위한 대안적 패러다임도 등장하고 있습니다. 얀 르쿤(Yann LeCun)의 **JEPA (Joint Embedding Predictive Architecture)**는 픽셀 공간이 아닌 표현 공간(Representation Space)에서 예측함으로써 표현을 학습할 것을 제안합니다. 생성형 모델로부터의 근본적인 전환으로서, 우리는 JEPA와 자율 에이전트의 미래를 Chapter 20에서 자세히 다룰 것입니다.
멀티모달 AI의 미래는 수동적인 생성을 넘어 능동적인 시뮬레이션으로 이동하는 데 있습니다. 여기서 모델은 단순히 사실적인 비디오를 생성하는 데 그치지 않고, 자신이 시뮬레이션하는 세계의 물리 법칙을 이해하고 그와 상호작용하게 됩니다.
요약 및 다음 단계
계단식 U-Net에서 Diffusion Transformer로의 전환은 비디오 생성 기술의 성숙을 의미합니다. 비디오를 시공간 패치(Spacetime Patches)로 압축하고 정교한 시공간 어텐션 메커니즘을 활용함으로써, 현대 모델들은 비디오를 통합된 3D 볼륨으로 처리합니다. 이러한 아키텍처의 우아함은 다중 조건 신호의 매끄러운 통합을 허용하고 창발적인 물리적 추론 능력을 잠금 해제하여, 진정한 세계 시뮬레이터를 향한 토대를 마련합니다.
Quizzes
Quiz 1: 현대의 비디오 생성 모델들이 프레임을 개별적으로 처리하는 대신 Spacetime Patches(시공간 패치)를 사용하는 이유는 무엇인가?
프레임을 개별적으로 처리하거나 프레임당 2D 패치를 사용하면 프레임 간의 시간적 상관관계를 무시하게 되어, 깜빡임(flickering) 현상이나 물리적으로 일관되지 않은 결과를 초래하기 쉽습니다. 시공간 패치는 비디오를 공간 및 시간 차원 양쪽에서 동시에 압축하여, Transformer가 시간의 흐름에 따른 움직임 역학, 객체 영속성, 3D 일관성을 네이티브하게 학습할 수 있도록 해줍니다.
Quiz 2: 비디오 DiT에서 Full Spatiotemporal Attention을 사용할 때 발생하는 주요 연산 병목 현상은 무엇이며, 모델들은 이를 어떻게 완화하는가?
Full Spatiotemporal Attention은 시퀀스 길이에 대해 의 복잡도를 갖습니다. 고해상도 비디오는 수십만 개의 토큰을 생성하므로 전체 어텐션을 계산하는 것은 불가능에 가깝습니다. 모델들은 Factorized Attention (공간 어텐션과 시간 어텐션을 분리하여 계산)을 사용하거나, 어텐션 범위를 국소적인 3D 이웃이나 십자형 패턴으로 제한하는 고급 Sparse/Compact Attention 메커니즘을 사용하여 이 문제를 완화합니다.
Quiz 3: Diffusion Transformer (DiT)에서 Adaptive Layer Normalization (adaLN)은 어떤 역할을 하는가?
표준 레이어 정규화와 달리, adaLN은 외부 조건 신호에 기반하여 정규화된 활성화(activations)의 스케일과 시프트를 동적으로 조절합니다. DiT에서는 텍스트 프롬프트 임베딩, 현재의 디퓨전 타임스텝(노이즈 레벨), 기타 조건들이 다층 퍼셉트론(MLP)을 통과하여 각 Transformer 블록의 스케일 및 시프트 파라미터를 생성함으로써, 노이즈 제거(denoising) 과정을 유도합니다.
Quiz 4: 비디오 생성의 맥락에서, ControlNet과 같은 기존의 어댑터 기반 방식과 비교할 때 “In-Context Conditioning” (FullDiT에서 볼 수 있듯)의 장점은 무엇인가?
기존의 어댑터는 각 조건(예: 깊이 맵용 하나, 카메라 포즈용 하나)마다 별도의 신경망 브랜치를 학습시켜야 하므로, 여러 조건을 동시에 사용할 때 파라미터 중복과 브랜치 충돌이 발생합니다. In-Context Conditioning은 모든 조건 토큰을 노이즈가 섞인 비디오 잠재 표현과 함께 단일 시퀀스로 직접 이어 붙이므로, 모델의 전체 self-attention 메커니즘이 모든 제약 조건 간의 상호작용과 물리를 네이티브하게 해결할 수 있습니다.
References
- Brooks, T., et al. (2024). Video generation models as world simulators. OpenAI. OpenAI Research.
- Ju, X., et al. (2025). FullDiT: Multi-Task Video Generative Foundation Model with Full Attention. arXiv:2503.19907.
- Wan Team. (2025). Wan: Open and Advanced Large-Scale Video Generative Models. arXiv:2503.20314.
- Peebles, W., & Xie, S. (2023). Scalable Diffusion Models with Transformers. arXiv:2212.09748.