이전 장에서는 수조 개의 파라미터를 가진 MoE (Mixture of Experts) 아키텍처의 라우팅 메커니즘을 해부했습니다. 우리는 DeepSeek-V3와 Grok-1 같은 모델들이 어떻게 연산 비용을 파라미터 수와 분리하여 방대한 세상의 지식을 흡수하는지 살펴보았습니다. 하지만 무한한 용량을 가진 아키텍처라도 그것을 채울 데이터가 없다면 무용지물입니다.
2026년 현재, 최첨단 파운데이션 모델(Foundation Model)을 학습시키기 위해서는 단순히 방대한 데이터셋을 확보하는 것을 넘어, 단 하나의 병목 현상 없이 수천 개의 GPU에 수십조 개의 토큰을 동시에 스트리밍할 수 있는 산업용 수준의 데이터 공급망(Data supply chain)이 필요합니다.
과거의 데이터 엔지니어링은 정적인 레코드를 데이터 웨어하우스로 이동시키기 위해 수동으로 ETL (Extract, Transform, Load) 파이프라인을 작성하는 작업이 주를 이루었습니다. 그러나 파운데이션 모델 시대에 이 패러다임은 붕괴되었습니다. 텍스트, 이미지, 오디오를 아우르는 페타바이트급 데이터의 엄청난 규모와 복잡성은 근본적인 변화를 강제했습니다. 오늘날의 데이터 엔지니어링은 자율적이고 스스로 적응하는 시스템(Autonomous, self-adapting systems) 을 구축하는 예술입니다. AI 모델들의 아키텍처 역량이 수렴해감에 따라, AI 기업의 진정한 ‘해자(Moat)‘이자 주요 차별화 요소는 바로 독자적인 데이터 파이프라인 인프라가 되었습니다.
개발자 관점에서 보면 이 장의 핵심은 더 단순합니다. 학습 코드가 아무리 좋아도 데이터 공급망이 흔들리면 GPU는 멈추고, loss는 튀고, 모델은 이상한 버릇을 배웁니다. 실제 장애는 “데이터가 부족하다”보다 “좋은 데이터가 언제, 어떤 순서로, 어떤 버전으로 들어갔는지 설명할 수 없다”에서 더 자주 발생합니다.
실무에서 자주 터지는 문제는 다음과 같습니다.
- 중복 데이터: 같은 문서가 수백 번 들어가면 모델은 특정 문체와 답변 패턴에 과적합됩니다. 벤치마크 문제와 유사한 텍스트가 섞이면 평가 점수도 오염됩니다.
- 언어/도메인 비율 드리프트: 한국어, 코드, 수학, 고객지원 문서의 비율이 릴리스마다 달라지면 모델 성격이 조용히 바뀝니다. 데이터 mix는 하이퍼파라미터입니다.
- 라이선스와 PII: 나중에 제거해야 할 데이터가 들어가면 재학습 비용이 눈덩이처럼 커집니다. ingestion 시점의 출처, 라이선스, 삭제 가능성 추적이 중요합니다.
- 샤드 품질 편차: 일부 샤드만 깨졌거나 압축 포맷이 다르면 특정 rank가 계속 느려집니다. GPU utilization 그래프만 보면 모델 병목처럼 보이지만 실제 원인은 데이터입니다.
- 재개 불가능한 스트림: 체크포인트에서 재시작했을 때 같은 샘플을 반복하거나 건너뛰면 loss curve가 이상해지고 실험 재현성이 사라집니다.
1. 데이터 파이프라인의 3단계 진화
전통적인 ETL에서 AI 네이티브 데이터 오케스트레이션(Orchestration)으로의 전환은 3단계의 진화 모델로 분류할 수 있습니다. 파운데이션 모델의 요구사항에 맞게 확장되는 시스템을 엔지니어링하려면 이 발전 과정을 이해하는 것이 필수적입니다.
Level 1: 최적화된 파이프라인 (Optimized Pipelines)
전통적인 빅데이터 시대(예: Apache Spark, Hadoop)의 접근 방식입니다. 엔지니어들은 처리량(Throughput)을 극대화하기 위해 연산자(Operator)를 수동으로 구성하고 매개변수를 조정하는 데 집중합니다. 만약 업스트림(Upstream)에서 스키마가 변경되거나 데이터 분포에 변화가 생기면(예: 웹 크롤링 중 새로운 언어의 대량 유입), 파이프라인은 중단됩니다. 변환 로직을 다시 작성하기 위해 반드시 사람의 개입이 필요합니다.
Level 2: 자가 인식 파이프라인 (Self-Aware Pipelines)
데이터의 양이 인간의 모니터링 능력을 초과함에 따라 파이프라인은 “자가 인식(Self-aware)” 단계로 발전했습니다. 이러한 시스템은 내부 상태와 데이터 분포를 지속적으로 모니터링합니다. 통계적 프로파일링을 사용하여 다운스트림(Downstream)에서 장애가 발생하기 전에 “컨텍스트 부패(Context rot)” 또는 스키마 드리프트(Schema drift)를 감지합니다. 스스로 문제를 수정하지는 못하지만, 신뢰도 높은 경고(Alert)를 생성하여 오염된 데이터가 수백만 달러가 투입되는 사전 학습(Pre-training) 과정을 망치는 것을 방지합니다.
Level 3: 자가 적응형 파이프라인 (Self-Adapting Pipelines - SOTA 2026)
현재의 최첨단(SOTA) 기술입니다. Level 3 시스템에서 데이터 파이프라인은 사람의 개입 없이 들어오는 데이터의 변화에 자동으로 반응합니다. 업스트림 소스의 스키마가 변경되면, AI 에이전트가 이러한 이상 징후를 가로채고 필요한 SQL 또는 Python 변환 코드를 생성합니다. 이후 샌드박스 환경에서 이를 테스트하고 동적으로 수정 사항을 배포합니다. 데이터 엔지니어의 역할은 파이프라인 코드를 작성하는 것에서 에이전트 기반 오케스트레이터를 감독(Supervising) 하는 것으로 전환되었습니다.
Data Pipeline Evolution
Evolution of data infrastructure for foundation model training.
Level 1: Optimized Pipelines
Manual ETL and batch processing. The pipeline breaks on schema changes, requiring human intervention.
- Manual ETL
- Static Schema
- High Human Dependency
Level 2: Self-Aware Pipelines
Continuously monitors data distribution and state. Detects anomalies and generates alerts, but cannot self-heal.
- Data Profiling
- Anomaly Detection
- Automated Alerts
Level 3: Self-Adapting Pipelines
AI agents detect data changes, dynamically generate and test transformation code, and self-heal the pipeline.
- Agent Orchestration
- Auto-remediation
- Dynamic Code Generation
2. AI 워크로드를 위한 아키텍처의 패러다임 전환
Level 3의 자율성과 GPU 클러스터가 요구하는 엄청난 처리량을 지원하기 위해, 데이터 엔지니어링의 기본 인프라는 근본적으로 재설계되었습니다.
제어 평면으로서의 메타데이터 (Metadata as the Control Plane)
레거시 시스템에서 메타데이터는 데이터 검색(예: 데이터 카탈로그)을 위해 수동적으로 사용되었습니다. 오늘날 메타데이터는 능동적인 제어 평면(Control Plane) 입니다. 스토리지와 컴퓨팅 계층에서 메타데이터를 추상화함으로써, 시스템은 심하게 파편화된 환경에서도 통합된 접근을 달성할 수 있습니다. 오케스트레이터는 메타데이터 계층에 쿼리를 보내 특정 GPU 노드가 정확히 어떤 데이터 샤드(Shard)를 처리해야 하는지 결정하며, 이를 통해 분산 클러스터 전반에서 결정론적이고 재현 가능한 학습(Reproducible training)을 가능하게 합니다.
개방형 테이블 포맷 (Open Table Formats, OTFs)
Apache Iceberg [1] , Delta Lake [2] , Apache Hudi와 같은 포맷은 AI 데이터 레이크의 기본 토대가 되었습니다. 이들은 원시 객체 스토리지(Object storage) 위에 직접 ACID (Atomicity, Consistency, Isolation, Durability) 트랜잭션을 제공합니다.
파운데이션 모델 학습에서 OTF 는 중앙 집중식 데이터베이스 엔진의 필요성을 없애주기 때문에 매우 중요합니다. 1만 개의 GPU로 구성된 클러스터는 메타데이터 매니페스트를 사용하여 페타바이트 규모의 데이터셋의 정확히 동일한 스냅샷을 스토리지에서 직접 동시에 읽을 수 있으며, 전통적인 데이터베이스의 병목 현상을 완벽하게 우회합니다.
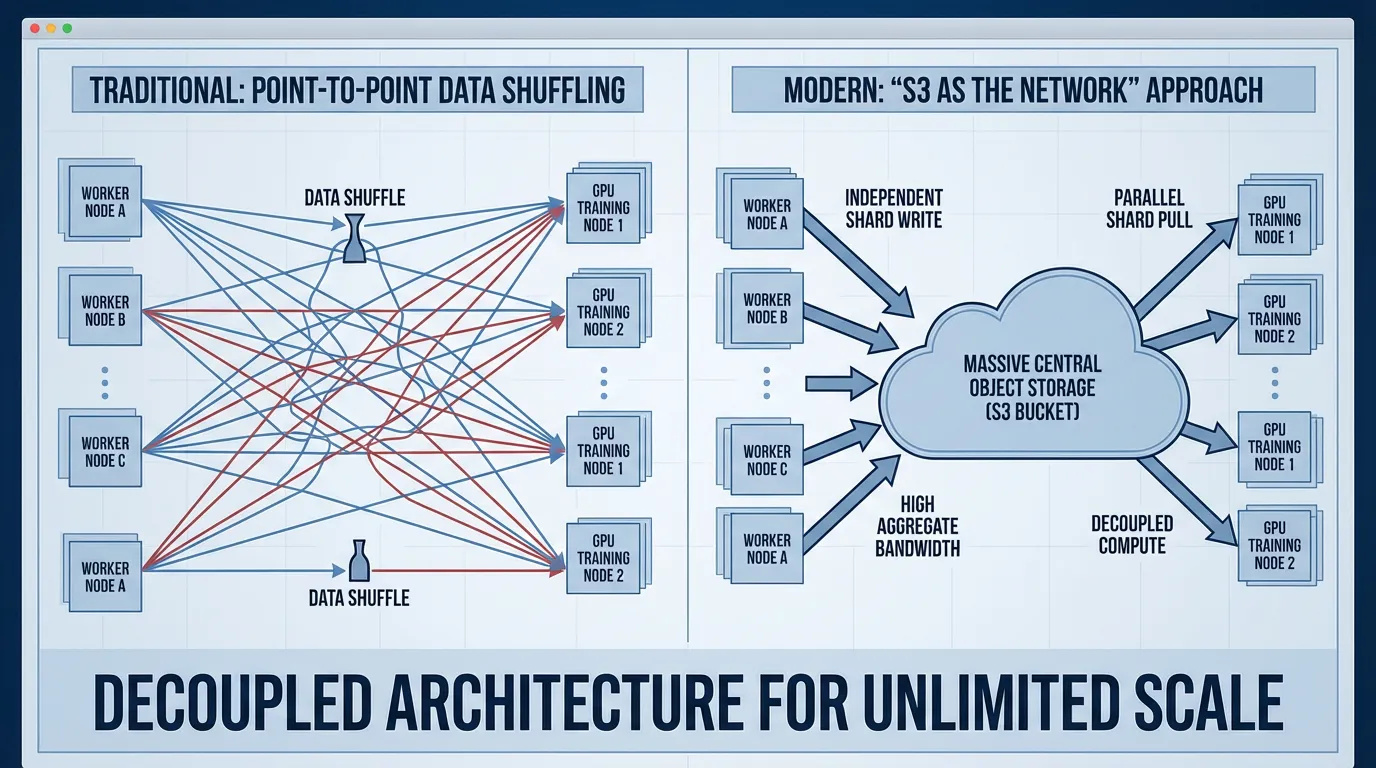
네트워크로서의 S3 (S3 as the Network)
대규모 AI 엔지니어링에서 직관에 반하는 변화 중 하나는 Amazon S3나 Google Cloud Storage와 같은 클라우드 객체 스토리지를 주력 네트워크 교환 매체로 취급한다는 것입니다. 전통적인 분산 시스템은 데이터를 섞기(Shuffle) 위해 직접적인 네트워크 프로토콜(TCP/RPC)에 크게 의존합니다. 하지만 파운데이션 모델의 규모에서는 지점 간(Point-to-point) 네트워킹이 쉽게 깨지는 병목이 됩니다.
대신, 업스트림 처리 노드들은 고도로 압축되고 직렬화된 텐서 샤드를 객체 스토리지에 직접 기록합니다. 다운스트림 학습 노드들은 이 샤드들을 비동기적으로 가져옵니다. 객체 스토리지는 사실상 무한한 집계 읽기 대역폭(Aggregate read bandwidth)을 제공하여 복잡한 네트워크 토폴로지를 고도로 병렬화된 HTTP GET 요청으로 대체합니다.
 Source: Generated by Gemini
Source: Generated by Gemini
실무 패턴: Dataset Manifest를 먼저 설계하기
대규모 학습에서는 “데이터셋 경로” 하나만 기록해서는 부족합니다. 모델 카드나 실험 로그에 최소한 아래 정보를 남겨야 나중에 성능 변화의 원인을 추적할 수 있습니다.
| 항목 | 왜 필요한가 |
|---|---|
| source id / crawl date | 데이터가 언제 수집되었는지 알아야 contamination과 최신성 문제를 분리할 수 있습니다. |
| license / policy tag | 상업 사용 가능 여부, 삭제 요청 대응, 내부 문서 여부를 추적합니다. |
| filter version | 품질 필터, PII 필터, dedup 로직이 바뀌면 같은 원천 데이터도 완전히 다른 학습셋이 됩니다. |
| tokenizer version | 토크나이저가 바뀌면 token count와 길이 분포가 바뀝니다. 학습 budget 비교가 깨집니다. |
| shard hash | 실제 학습에 들어간 파일이 무엇인지 바이트 수준으로 재현합니다. |
| mixture weight | 코드 30%, 한국어 10%처럼 도메인 비율을 명시합니다. 이 값은 learning rate만큼 중요합니다. |
좋은 파이프라인은 최종 .jsonl이나 .parquet 파일만 만드는 시스템이 아닙니다. 어떤 샘플이 왜 들어갔고 왜 빠졌는지 설명할 수 있는 provenance system 입니다. 특히 enterprise AI에서는 “이 답변이 어떤 내부 문서에서 학습되었는가?”라는 질문이 법무, 보안, 고객지원 이슈와 바로 연결됩니다.
3. 일급 객체로서의 텐서와 벡터
전통적인 데이터 파이프라인은 문자열, 정수, 타임스탬프를 처리하기 위해 구축되었습니다. 그러나 멀티모달 파운데이션 모델을 사전 학습하려면 다차원 배열(Tensor)과 고차원 임베딩(Embedding)을 네이티브하게 처리해야 합니다.
이미지나 오디오를 원시 BLOB 형태로 저장하고 학습 중에 GPU에서 디코딩한다면, 즉시 컴퓨팅 병목 현상이 발생할 것입니다. CPU가 JPEG나 MP3를 디코딩하기 위해 고군분투하는 동안 비싼 GPU는 유휴 상태(Idle)에 빠지게 됩니다.
현대의 데이터 엔지니어링은 이러한 연산을 업스트림으로 밀어냅니다. 데이터 파이프라인은 데이터가 학습 클러스터에 도달하기 훨씬 전에 데이터를 전처리하고, 토큰화하며, 원시 텐서 포맷(예: .safetensors 또는 텐서 확장이 적용된 최적화된 Parquet)으로 직렬화(Serialize)합니다.
텐서 스트림을 위한 내결함성 실행 (Durable Execution) 엔지니어링
테라바이트 규모의 텐서를 GPU로 스트리밍할 때 네트워크 중단이나 노드 장애는 불가피합니다. 따라서 데이터 로더가 정확한 상태를 체크포인트로 저장하고, 모델에 중복된 데이터를 공급하지 않으면서(중복 데이터는 Loss Spike를 유발함) 끊김 없이 재개할 수 있는 내결함성 실행(Durable execution) 을 구현해야 합니다.
다음은 객체 스토리지에서 텐서 샤드를 읽어오도록 설계된 단순화된 내결함성 IterableDataset 의 PyTorch 구현입니다. 이 클래스는 내부 상태를 추적하여 학습 작업이 중단되더라도 정확히 중단된 지점부터 다시 시작할 수 있도록 합니다.
import torch
import os
import json
from torch.utils.data import IterableDataset, DataLoader
from typing import Iterator, List, Dict
class DurableTensorStreamer(IterableDataset):
"""
대규모 사전 학습(Pre-training)을 위해 설계된 내결함성(Durable) 상태 유지 데이터셋입니다.
사전 토큰화된 텐서 샤드(Shard)를 스트리밍하며, 상태에 대한 정밀한 체크포인트를 유지합니다.
"""
def __init__(self, shard_uris: List[str], checkpoint_path: str, batch_size: int):
super().__init__()
self.shard_uris = shard_uris
self.checkpoint_path = checkpoint_path
self.batch_size = batch_size
# 내결함성 실행을 위한 상태 추적 변수
self.current_shard_idx = 0
self.current_sample_idx = 0
self._load_checkpoint()
def _load_checkpoint(self):
"""이전 학습 실행이 중단된 경우 데이터셋 상태를 불러옵니다."""
if os.path.exists(self.checkpoint_path):
with open(self.checkpoint_path, 'r') as f:
state = json.load(f)
self.current_shard_idx = state.get('shard_idx', 0)
self.current_sample_idx = state.get('sample_idx', 0)
print(f"데이터 스트림 재개: Shard {self.current_shard_idx}, Sample {self.current_sample_idx}")
def save_checkpoint(self):
"""성공적인 모델 체크포인트 저장 후 학습 루프에 의해 호출됩니다."""
state = {
'shard_idx': self.current_shard_idx,
'sample_idx': self.current_sample_idx
}
# 실제 프로덕션 환경에서는 객체 스토리지에 원자적(Atomically)으로 기록해야 합니다.
with open(self.checkpoint_path, 'w') as f:
json.dump(state, f)
def _download_and_load_shard(self, uri: str) -> torch.Tensor:
"""S3에서 사전 토큰화된 데이터 청크를 다운로드하는 과정을 시뮬레이션합니다."""
# 실제로는 boto3나 클라우드 스토리지 SDK를 사용하여 .safetensors 또는 .pt 파일을 가져옵니다.
# 여기서는 길이 4096의 시퀀스 10,000개로 구성된 샤드를 시뮬레이션합니다.
return torch.randint(0, 50257, (10000, 4096), dtype=torch.long)
def __iter__(self) -> Iterator[torch.Tensor]:
worker_info = torch.utils.data.get_worker_info()
# 멀티 프로세싱 데이터 로딩을 처리하기 위해 샤드를 분할합니다.
if worker_info is not None:
per_worker = len(self.shard_uris) // worker_info.num_workers
worker_id = worker_info.id
start_idx = worker_id * per_worker
end_idx = start_idx + per_worker
worker_shards = self.shard_uris[start_idx:end_idx]
else:
worker_shards = self.shard_uris[self.current_shard_idx:]
for shard_idx, uri in enumerate(worker_shards):
# 체크포인트를 위한 절대 인덱스
actual_shard_idx = self.current_shard_idx + shard_idx
# 텐서 블록을 메모리에 로드
tensor_block = self._download_and_load_shard(uri)
# 샤드 중간에서 장애 복구 시 해당 위치로 빨리 감기(Fast-forward)
start_sample = self.current_sample_idx if actual_shard_idx == self.current_shard_idx else 0
for i in range(start_sample, len(tensor_block), self.batch_size):
batch = tensor_block[i : i + self.batch_size]
# 배치를 반환합니다. 학습 루프는 주기적으로 save_checkpoint()를 호출해야 합니다.
yield batch
# 상태 업데이트
self.current_sample_idx = i + self.batch_size
# 다음 샤드를 위해 샘플 인덱스 초기화
self.current_sample_idx = 0
self.current_shard_idx = actual_shard_idx + 1
# 사용 예시:
# shards = [f"s3://bucket/dataset/shard_{i}.pt" for i in range(1000)]
# dataset = DurableTensorStreamer(shards, "./data_checkpoint.json", batch_size=32)
# dataloader = DataLoader(dataset, batch_size=None, num_workers=4) # dataset이 배치를 반환하므로 batch_size=None4. 에이전트 기반 오케스트레이션: 자동화하되 검증 가능하게
데이터 엔지니어링의 규모가 커짐에 따라 인간의 개입 자체가 가장 큰 병목이 됩니다. 다만 “에이전트가 알아서 데이터 파이프라인을 고친다”라는 말은 조심해서 들어야 합니다. 프로덕션에서 중요한 것은 자동화의 화려함이 아니라 자동화된 변경을 검증하고 되돌릴 수 있는 구조 입니다.
LLM 에이전트가 잘하는 일은 사람이 반복해서 하던 주변 작업입니다. 예를 들어 실패한 Spark job의 로그를 요약하고, schema mismatch의 원인을 찾고, 샘플 데이터를 보고 변환 SQL 초안을 만들고, quality report를 자연어로 설명하는 일입니다. 반대로 에이전트가 바로 운영 테이블을 수정하거나 필터 기준을 바꾸게 하면 위험합니다. 데이터 파이프라인의 작은 변경은 수조 토큰 규모에서는 모델 행동 변화로 증폭됩니다.
실무적인 설계는 다음처럼 나누는 것이 좋습니다.
| 자동화 대상 | 허용하면 좋은 범위 | 반드시 막아야 할 범위 |
|---|---|---|
| 로그 분석 | 실패 원인 후보, 재시도 제안, 관련 run 링크 수집 | 운영 job 자동 재배포 |
| SQL/코드 생성 | PR 초안, 샘플 데이터에 대한 dry-run | 승인 없는 production table write |
| 품질 평가 | 중복률, 언어 분포, PII hit rate 리포트 | 품질 threshold 자동 완화 |
| 데이터 mix 탐색 | 후보 mixture와 예상 token budget 계산 | 학습 job의 최종 mixture 무단 변경 |
에이전트를 붙일 때는 세 가지 로그를 남겨야 합니다. 첫째, 에이전트가 본 입력 로그와 샘플입니다. 둘째, 에이전트가 제안한 변경 diff입니다. 셋째, 변경 전후의 품질 지표입니다. 이 세 가지가 없으면 자동화는 생산성을 올리는 도구가 아니라 원인 분석을 불가능하게 만드는 블랙박스가 됩니다.
GPU 기아 상태를 막는 데이터 로더 체크리스트
학습 클러스터에서 데이터 파이프라인이 충분히 빠른지 보려면 “파일을 잘 읽는다”가 아니라 tokens/sec/GPU를 유지하는가 를 봐야 합니다.
- tokens/sec/GPU: 모델 step time과 함께 봅니다. 토큰 공급량이 흔들리면 optimizer나 커널 튜닝보다 먼저 데이터 로더를 의심해야 합니다.
- p95 shard load latency: 평균이 아니라 꼬리 지연이 중요합니다. 한 rank만 느려도 전체 step이 멈춥니다.
- cache hit rate: 로컬 NVMe 캐시나 object store cache가 실제로 동작하는지 확인합니다.
- bad shard retry rate: 깨진 샤드가 반복적으로 재시도되면 전체 학습이 느려집니다. 일정 횟수 이후 격리해야 합니다.
- resume exactness: 체크포인트 재개 후
(dataset_version, shard_id, offset)이 정확히 이어지는지 테스트합니다. - sample auditability: 학습 중 문제가 된 배치의 샘플 ID를 나중에 복원할 수 있어야 합니다.
5. 요약 및 다음 단계
파운데이션 모델 규모의 데이터 엔지니어링은 분산 시스템 설계의 정수를 보여줍니다. 우리는 수동 ETL 스크립트에서 스스로 적응하는 에이전트 오케스트레이션 파이프라인으로 이동했습니다. 개방형 테이블 포맷(OTF)을 사용하여 스토리지와 컴퓨팅을 분리하고, 메타데이터를 제어 평면으로 격상시켰으며, 텐서를 일급 객체로 다루기 위해 데이터셋의 아키텍처를 재설계했습니다.
이 장에서 꼭 가져가야 할 실무 감각은 하나입니다. 데이터 파이프라인은 모델 학습의 배관이 아니라 모델 품질을 결정하는 제어 시스템입니다. 데이터의 출처, 버전, 필터, mixture, 샤드 상태, 재개 위치를 설명할 수 있어야 모델 성능도 설명할 수 있습니다.
하지만 이러한 텐서들을 GPU로 스트리밍하기 전에, 우리는 근본적인 질문에 직면해야 합니다. 인간의 언어, 코드, 그리고 원시 바이트(Bytes)를 신경망이 실제로 처리할 수 있는 밀집된 정수 시퀀스로 어떻게 변환할 것인가?
다음 섹션인 6.2 Tokenization Science (토큰화의 과학) 에서는 토큰 압축의 수학과 엔지니어링에 대해 깊이 파헤칩니다. 왜 Byte-level BPE가 토큰화 전쟁에서 승리했는지, 어휘 사전(Vocabulary)의 크기가 모델 효율성에 어떤 영향을 미치는지, 그리고 최적화되지 않은 토크나이저가 어떻게 모델의 추론 능력을 인위적으로 훼손할 수 있는지 탐구할 것입니다.
Quizzes
Quiz 1: 개의 GPU로 구성된 분산 학습 클러스터가 멀티모달 사전 학습을 위해 시퀀스 길이 의 마이크로 배치 를 처리합니다. 각 시퀀스에는 텍스트 토큰(토큰당 4바이트)과 차원 , 비전 토큰 개로 사전 처리된 비전 임베딩(float16, 2바이트)이 포함되어 있습니다. GPU 기아 상태(Starvation) 없이 의 스텝 타임을 유지하기 위해 데이터 레이크에서 요구되는 최소 집합 네트워크 대역폭(Gbps 단위)을 계산하세요.
먼저 시퀀스당 데이터 크기를 계산합니다: 텍스트 바이트 = . 비전 바이트 = . 시퀀스당 총합 = . 총 글로벌 배치 크기(바이트) = . 필요한 집합 대역폭 = . Gbps(초당 기가비트) 단위로 변환하면 = 입니다.
Quiz 2: Level 3 “자가 적응형(Self-Adapting)” 파이프라인에서 인간 데이터 엔지니어의 주요 역할은 무엇입니까?
Level 3 파이프라인에서는 시스템이 스키마 드리프트와 같은 이상 징후를 자동으로 감지하고 AI 에이전트를 사용하여 코드 수정 사항을 생성 및 배포합니다. 인간 데이터 엔지니어는 수동으로 ETL 코드를 작성하는 것에서 벗어나 감독관(Supervisor) 역할을 수행하게 됩니다. 이들은 검증 매개변수를 정의하고, AI 에이전트를 위한 가드레일 및 보상 함수를 설정하며, 시스템의 전반적인 아키텍처적 무결성과 보안을 보장하는 데 집중합니다.
Quiz 3: 파운데이션 모델 사전 학습 중에 원시 멀티모달 데이터(예: JPEG 또는 MP3)를 데이터 레이크에 저장하고 GPU 노드에서 직접 디코딩하는 것이 치명적인 안티 패턴(Anti-pattern)인 이유는 무엇입니까?
GPU는 대규모 병렬 행렬 곱셈에 최적화되어 있으며 순차적인 파일 디코딩에는 적합하지 않습니다. 원시 파일이 학습 클러스터로 전송되면, 학습 노드의 CPU가 미디어를 디코딩하느라 심각한 병목 현상을 겪게 되고, 그동안 매우 비싼 GPU는 데이터 기아(Starvation) 상태에 빠져 유휴(Idle) 상태가 됩니다. 최신 파이프라인은 이러한 연산을 업스트림으로 밀어내어, 데이터가 학습 클러스터에 도달하기 전에 미리 다차원 텐서(예: .safetensors)로 디코딩하고 직렬화합니다.
Quiz 4: Apache Iceberg와 같은 개방형 테이블 포맷(OTF)은 분산 GPU 학습을 위한 중앙 집중식 데이터베이스의 병목 현상을 어떻게 해결합니까?
OTF는 스토리지 및 컴퓨팅 계층에서 메타데이터를 추상화하여 원시 객체 스토리지에서 직접 ACID 트랜잭션을 허용합니다. 메타데이터 매니페스트가 모든 데이터 샤드의 정확한 위치를 명시적으로 매핑하기 때문에, 1만 개의 GPU로 구성된 분산 클러스터가 스토리지에서 직접 데이터셋의 정확히 동일한 스냅샷을 동시에 읽을 수 있습니다. 이는 동시 연결 부하로 인해 다운될 수 있는 중앙 집중식 데이터베이스 엔진의 필요성을 완전히 우회하게 해줍니다.
References
- Apache Software Foundation. (2024). Apache Iceberg: A Table Format for Huge Analytic Datasets. [Link]
- Armbrust, M., et al. (2020). Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores. Proceedings of the VLDB Endowment. arXiv:2008.06750