14.3 Advanced Retrieval: Hybrid Search & Re-ranking
이전 장에서 확인했듯, 조밀한 벡터 임베딩(Dense vector embeddings)과 HNSW 인덱스는 밀리초 단위의 의미론적 검색을 가능하게 합니다. 그러나 조밀한 벡터에만 전적으로 의존하는 방식은 정확한 키워드 매칭이 부족하여 실제 기업 환경에서 종종 실패합니다.
예를 들어 사용자가 “레거시 시스템 X에서 에러 코드 404 발생” 을 검색한다고 가정해 보겠습니다.
- 시맨틱 검색 은 “404”가 “찾을 수 없음” 또는 “웹 에러”와 관련이 있고 “레거시 시스템”이 “오래된 소프트웨어”와 관련이 있다는 것을 이해합니다. 따라서 “오래된 애플리케이션의 일반적인 웹 에러”에 대한 문서를 가져올 수 있습니다. 이는 개념적으로는 유사하지만 특정 “시스템 X”를 언급하지 않기 때문에 사용자에게는 쓸모가 없습니다.
- 키워드 검색 (Lexical) 은 “시스템 X”와 “404”라는 정확한 문자열을 찾습니다. 문서에 “찾을 수 없음” 대신 “누락된 리소스”와 같은 다른 단어가 사용되더라도 해당 시스템에 대한 정확한 로그 파일이나 문서를 찾아냅니다.
두 방식의 장점을 모두 취하기 위해 우리는 하이브리드 검색 (Hybrid Search) 이 필요합니다. 조밀한 벡터의 개념적 이해와 키워드 검색의 정확한 정밀도를 결합하는 것입니다. 본 장에서는 순위 융합 (Rank Fusion) 을 사용하여 이러한 신호를 결합하는 방법과 재순위화 (Re-ranking) 모델을 사용하여 이를 더욱 미세 조정하는 방법을 해부합니다.
1. 희소 벡터와 SPLADE (Sparse Vectors and SPLADE)
역사적으로 정확한 일치 검색은 TF-IDF(Term Frequency-Inverse Document Frequency) 기반 알고리즘인 BM25 에 의존했습니다. BM25는 문서를 어휘 사전(Vocabulary)의 크기와 동일한 차원을 갖는 고도로 희소한(Sparse) 벡터로 표현합니다. 특정 단어가 문서에 등장하지 않으면 해당 벡터 차원은 정확히 0이 됩니다.
BM25는 정확한 일치 문제를 훌륭히 해결하지만, 반대로 어휘 불일치 (Vocabulary Mismatch) 문제를 겪습니다. 사용자가 “automobile”을 검색했는데 문서에 “car”만 포함되어 있다면 BM25는 0점을 반환합니다.
이 간극을 메우기 위해 연구자들은 학습된 희소 표현 (Learned Sparse Representations) 을 도입했으며, 그중 SPLADE (Sparse Lexical and Expansion Model) [1] 가 업계 표준으로 자리 잡았습니다.
SPLADE의 작동 원리
SPLADE는 단순한 텍스트 빈도에 의존하는 대신, 문서를 BERT 스타일의 인코더에 통과시키고 MLM(Masked Language Modeling) 헤드를 활용합니다. MLM 헤드는 전체 토크나이저 어휘(예: 30,000 차원)에 대한 확률 분포를 출력합니다.
SPLADE는 이 로짓(Logits)에 ReLU 활성화 함수와 로그 포화(Log-saturation) 함수를 적용한 뒤, 학습 과정에서 강력한 정규화(Regularization)를 가합니다. 이는 모델이 어휘 차원의 95% 이상을 정확히 0으로 밀어내도록 강제하여, 기존의 역색인(Inverted Index, 예: Elasticsearch, Lucene) 구조에 색인할 수 있는 희소 벡터를 생성합니다.
문서 확장 (Document Expansion) 의 마법: SPLADE는 MLM 헤드를 사용하기 때문에 문서에 실제로 존재하지 않는 단어 에도 0이 아닌 가중치를 할당할 수 있습니다. 입력이 “car”인 경우, 신경망은 “automobile”에 해당하는 어휘 차원을 1.2의 가중치로 활성화합니다. 이를 통해 극도로 빠른 희소 역색인 검색 속도를 유지하면서도 의미론적 확장(Semantic expansion)을 달성합니다.
2. 하이브리드 검색과 RRF (Reciprocal Rank Fusion)
조밀한 검색기(HNSW)와 희소 검색기(BM25 또는 SPLADE)를 병렬로 운영할 때, 우리는 수학적 딜레마에 직면하게 됩니다. 서로 다른 스케일을 가진 두 검색기의 점수를 어떻게 결합할 것인가?
조밀한 벡터의 코사인 유사도 점수는 일반적으로 에서 사이를 갖는 반면, BM25 점수는 상한이 없고 문서 길이에 크게 의존하여 종종 에서 사이의 범위를 갖습니다. 이 점수들을 정규화(예: Min-Max 스케일링)하는 것은 매우 불안정합니다. 점수 분포가 특정 쿼리에 따라 동적으로 요동치기 때문입니다.
대신 현대의 시스템들은 점수(Scores) 를 융합하는 대신, RRF (Reciprocal Rank Fusion) [2] 를 사용하여 순위(Ranks) 를 융합합니다.
주어진 문서 에 대해, RRF 점수는 모든 검색 방법론 에 걸쳐 해당 문서의 순위 위치 의 역수를 취하여 계산됩니다:
파라미터 의 역할
상수 (전통적으로 으로 설정)는 중요한 평활화(Smoothing) 요소로 작용합니다.
- 만약 이면 수식은 최상위 순위에 극도로 민감해집니다. 성능이 떨어지는 검색기에서 1위를 하고 강력한 검색기에서 1000위를 한 문서가 여전히 엄청난 점수()를 받게 되어 노이즈에 취약해집니다.
- 으로 설정하면 1위()와 10위() 사이의 점수 차이가 압축됩니다. 이는 특정 문서가 최종 융합 리스트의 최상위로 올라가기 위해 여러 독립적인 검색기에서 일관되게 상위권에 랭크되도록 요구합니다.
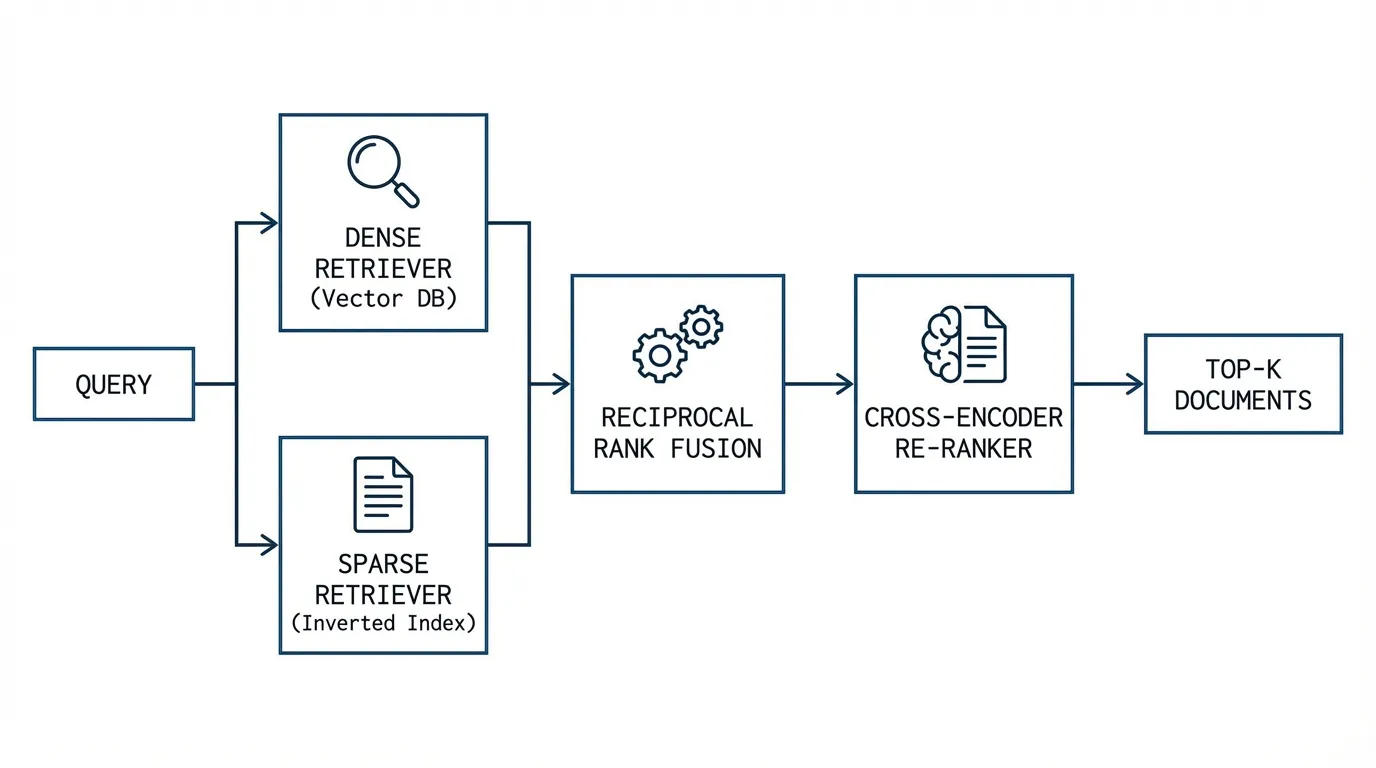 Source: Generated by Gemini. Dense와 Sparse 검색기의 결과를 RRF로 결합하는 하이브리드 검색 파이프라인.
Source: Generated by Gemini. Dense와 Sparse 검색기의 결과를 RRF로 결합하는 하이브리드 검색 파이프라인.
3. 쿼리 변환: HyDE 및 확장 (Query Transformation)
인덱스를 검색하기 전에 사용자의 쿼리를 변환하여 재현율을 높일 수 있습니다. 이는 짧은 쿼리를 긴 문서와 비교할 때 발생하는 “쿼리-문서 비대칭성”을 극복하는 데 도움이 됩니다.
A. 쿼리 확장 (Query Expansion)
LLM은 사용자의 쿼리에 대한 여러 변형이나 동의어를 생성합니다. 모든 변형을 검색하면 다른 단어를 사용할 수 있는 관련 문서를 찾을 가능성이 높아집니다.
B. HyDE (Hypothetical Document Embeddings) [5]
쿼리로 검색하는 대신, LLM이 가상 답변(Hypothetical answer) 을 생성합니다. 그런 다음 이 가짜 답변을 임베딩하여 벡터 DB를 검색합니다. 가짜 답변은 실제 답변과 동일한 의미 공간에 있기 때문에 종종 짧은 쿼리보다 더 나은 매칭 결과를 얻을 수 있습니다.
4. 2단계 파이프라인: 재순위화 (Re-ranker) 모델의 등장
1단계 검색(Hybrid Search)은 재현율 (Recall) 과 지연 시간 (Latency) 에 최적화되어 있습니다. 수십억 개의 문서를 약 100개의 후보 풀로 빠르게 필터링합니다. 그러나 Bi-Encoder는 전체 문서를 단일 벡터로 압축하기 때문에 복잡한 구문론적(Syntactic) 관계를 잃어버리는 한계가 있습니다.
2단계는 오직 정밀도 (Precision) 에 최적화됩니다. 상위 100개의 후보를 가져와 재순위화 모델 (Re-ranker) 에 통과시킵니다. 후보 풀이 작기 때문에 연산량이 많은 무거운 아키텍처를 사용할 여유가 생깁니다.
Cross-Encoders vs. Bi-Encoders (BERT 와의 연결)
Bi-Encoder에서는 쿼리와 문서를 완전히 독립적으로 처리하여 별도의 벡터를 생성한 다음 코사인 유사도를 사용하여 비교합니다. 반면 Cross-Encoder 에서는 쿼리와 문서를 단일 시퀀스([CLS] Query [SEP] Document [SEP])로 연결하여 트랜스포머 레이어를 함께 통과시킵니다.
이를 통해 Self-Attention 메커니즘이 All-to-all 비교를 수행할 수 있습니다. 쿼리의 3번째 단어가 네트워크의 모든 레이어에서 문서의 50번째 단어에 직접 주의(Attend)를 기울일 수 있습니다. 이는 SOTA 수준의 압도적인 정확도를 제공하지만, 추론 시 시간 복잡도가 이기 때문에 수백만 개의 문서에 대한 1단계 검색용으로는 절대 사용할 수 없습니다.
이것은 Chapter 4.1 에서 다룬 Encoder-only architectures 와 직접적으로 연결됩니다. 전체 입력에 대해 self-attention 을 사용하는 BERT 와 같은 모델은 쿼리의 모든 토큰이 문서의 모든 토큰에 주의를 기울일 수 있기 때문에 Cross-Encoder 에 완벽하게 적합합니다.
5. 지연 상호작용: ColBERT (Late Interaction)
Bi-Encoder의 압도적인 속도와 Cross-Encoder의 정밀한 정확도 사이의 절충안이 있을까요? 2020년, 연구자들은 ColBERT (Contextualized Late Interaction over BERT) [3] 를 도입했습니다.
ColBERT는 문서 임베딩이 저장되는 방식을 근본적으로 바꿉니다. 문서 토큰을 단일 벡터로 풀링(Pooling)하는 대신, 문서 내의 모든 개별 토큰 에 대해 하나의 차원 벡터를 생성하여 거대한 임베딩 행렬(Matrix)로 저장합니다.
쿼리 시점에 ColBERT는 MaxSim 연산을 계산합니다. 쿼리의 모든 토큰에 대해 문서의 모든 토큰과의 내적(Dot product)을 계산하고, 그중 최댓값을 취한 뒤, 이 최댓값들을 모두 합산합니다.
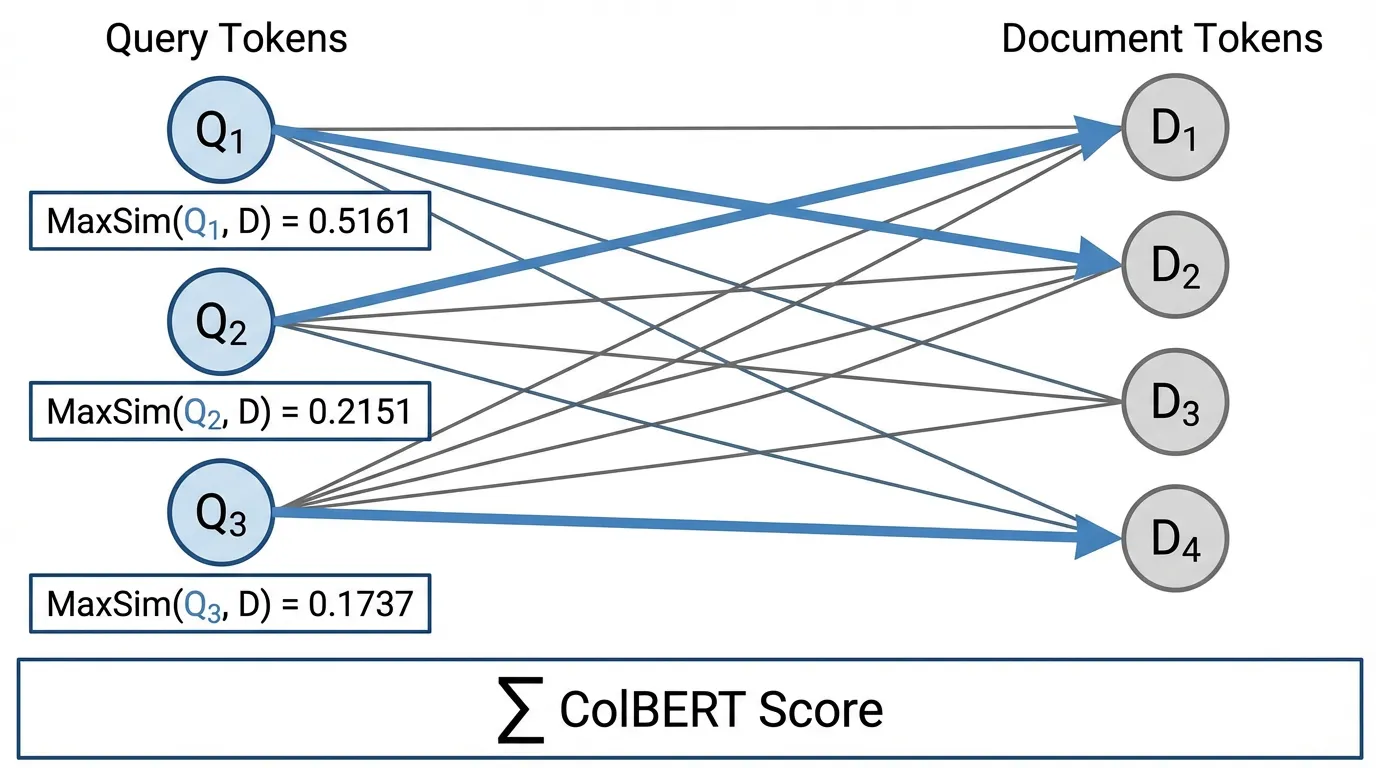 Source: Khattab, O., & Zaharia, M. (2020). ColBERT 아키텍처의 MaxSim 연산 구조.
Source: Khattab, O., & Zaharia, M. (2020). ColBERT 아키텍처의 MaxSim 연산 구조.
MaxSim 연산 엔지니어링
MaxSim을 효율적으로 구현하려면 GPU 병렬 처리를 활용하기 위한 세심한 텐서(Tensor) 조작이 필요합니다. 아래는 배치(Batched) 처리된 MaxSim의 프로덕션 수준 PyTorch 구현입니다.
import torch
import torch.nn.functional as F
def batched_colbert_maxsim(
queries: torch.Tensor,
documents: torch.Tensor,
query_mask: torch.Tensor
) -> torch.Tensor:
"""
배치 처리된 ColBERT MaxSim 점수를 계산합니다.
Args:
queries: (batch_size, Q_len, dim) 형태의 텐서
documents: (batch_size, D_len, dim) 형태의 텐서
query_mask: (batch_size, Q_len) 형태의 텐서. 유효한 토큰은 1, 패딩은 0.
Returns:
scores: 스칼라 관련도 점수를 포함하는 (batch_size,) 형태의 텐서.
"""
# 1. L2 정규화 (L2 정규화된 벡터의 내적 = 코사인 유사도)
q_norm = F.normalize(queries, p=2, dim=2)
d_norm = F.normalize(documents, p=2, dim=2)
# 2. BMM(Batch Matrix Multiplication)을 통한 토큰 간 유사도 행렬 계산
# Shape: (batch_size, Q_len, dim) x (batch_size, dim, D_len) -> (batch_size, Q_len, D_len)
sim_matrix = torch.bmm(q_norm, d_norm.transpose(1, 2))
# 3. 문서 토큰 차원에 대한 Max Pooling
# 모든 쿼리 토큰에 대해, 전체 문서 토큰 중 가장 높은 유사도 점수를 찾습니다.
# Shape: (batch_size, Q_len)
max_sims, _ = torch.max(sim_matrix, dim=2)
# 4. 쿼리의 패딩 토큰을 마스킹하여 최종 점수에 기여하지 않도록 합니다.
max_sims = max_sims * query_mask
# 5. 모든 유효한 쿼리 토큰에 걸쳐 최대 유사도를 합산합니다.
# Shape: (batch_size,)
scores = torch.sum(max_sims, dim=1)
return scores
# --- 실행 예시 ---
batch_size = 32
dim = 128
q_len = 16
d_len = 256
# 시뮬레이션된 표현(Representations)
queries = torch.randn(batch_size, q_len, dim)
documents = torch.randn(batch_size, d_len, dim)
query_mask = torch.ones(batch_size, q_len) # 단순화를 위해 패딩이 없다고 가정
scores = batched_colbert_maxsim(queries, documents, query_mask)
print(f"MaxSim Scores shape: {scores.shape}") # 출력: torch.Size([32])6. 재순위화 모델로서의 LLM (RankGPT)
고성능 Instruction-Tuned LLM의 부상과 함께, 2단계 검색의 최신 패러다임은 특화된 Cross-Encoder를 완전히 폐기하고 LLM 자체를 사용하여 문서를 순위 매기는 방향으로 이동하고 있습니다.
초기의 시도들은 Pointwise 순위 지정(LLM에게 문서를 1~10점으로 평가하라고 요청)이나 Pairwise 순위 지정(문서 A가 문서 B보다 나은지 묻는 방식)을 사용했습니다. 두 접근법 모두 결함이 있습니다. Pointwise 채점은 캘리브레이션 드리프트(Calibration drift)를 겪고, Pairwise 채점은 의 비교 연산을 요구합니다.
현재의 SOTA(State-of-the-Art)는 RankGPT [4] 와 같은 아키텍처로 대중화된 Listwise Ranking 입니다. 이 접근법에서는 쿼리와 모든 후보 문서가 LLM의 거대한 컨텍스트 윈도우 안에 통째로 패킹(Packing)됩니다. 모델은 문서 식별자들의 순열(Permuted list)을 직접 출력하도록 프롬프팅됩니다.
프롬프트 예시:
I will provide you with 10 passages, each indicated by a numerical identifier [].
Rank the passages based on their relevance to the search query: "How to optimize PyTorch DDP?"
[1] {Passage 1 text...}
[2] {Passage 2 text...}
...
[10] {Passage 10 text...}
Output the ranking in descending order of relevance using identifiers, e.g., [4] > [1] > [7]...모든 후보를 동시에 확인함으로써 어텐션 메커니즘은 본질적으로 다중 문서 비교 추론(Multi-document comparative reasoning)을 수행합니다. 비록 토큰 소비량과 지연 시간이 증가한다는 단점이 있지만, 전통적인 Cross-Encoder에 비해 우수한 nDCG@10 지표를 달성합니다.
7. 인터랙티브 컴포넌트: RRF (Reciprocal Rank Fusion) 시뮬레이터
RRF가 왜 그토록 견고한지 직관적으로 이해하기 위해 아래의 시각화 도구를 활용해 보십시오. 파라미터를 조절하여 이것이 어떻게 평활화(Smoothing) 요소로 작용하는지 관찰하십시오. 단일 검색기에서 발생한 환각(Hallucinated) 결과가 최종 출력을 장악하는 것을 방지하기 위해, 문서가 최상위 자리를 차지하려면 Sparse와 Dense 리스트 모두 에서 합리적으로 좋은 성과를 내야 한다는 점을 확인할 수 있습니다.
Reciprocal Rank Fusion (RRF) Demo
Query: "Error 404 on legacy system X"
RRF formula: Score = 1 / (k + rank_dense) + 1 / (k + rank_sparse)
Adjust k to see how the fused ranking changes. Higher k favors balanced results.
Dense Rank (Meaning)
Sparse Rank (Keywords)
Fused Result (RRF)
💡 Observation
At k=60, **System X 404 Log** wins because it ranks well in both (2nd place), even though it is not #1 in either. If you lower k significantly (e.g., to k=1), top-ranked items dominate, and it becomes a tie or favors the specialists.
8. 요약 및 다음 단계
고급 검색(Advanced retrieval)은 어떠한 단일 벡터 표현도 깊은 의미론적 의도와 엄격한 어휘적 정밀도를 동시에 포착할 수 없다는 사실을 인정하는 데서 출발합니다. 하이브리드 검색(SPLADE와 HNSW를 RRF로 결합)을 실행함으로써 시스템은 최대의 재현율(Recall)을 달성합니다. 이후 이 후보들을 지연 상호작용 모델(ColBERT)이나 Listwise LLM(RankGPT)에 통과시켜 정밀도(Precision)를 극대화하고, 생성 모델이 가능한 최고 품질의 컨텍스트를 제공받도록 보장합니다.
그러나 완벽한 검색이 이루어지더라도, 텍스트 청크(Chunks)의 선형적인 나열만으로는 복잡한 다중 홉(Multi-hop) 질문(예: “Attention 논문의 저자가 설립한 스타트업을 인수한 회사는 어디인가?”)에 답하지 못하는 경우가 많습니다. 이에 답하기 위해 검색 시스템은 단순한 텍스트 유사도가 아니라 관계(Relationships)와 엔티티(Entities)를 이해해야 합니다.
관계형 지식을 어떻게 표현하고 탐색할 수 있을까요? 다음 장인 14.5 GraphRAG & Practical Ontology 에서 이를 살펴보겠습니다.
Quizzes
Quiz 1: 프로덕션 시스템에서 BM25와 Dense 벡터 점수를 결합할 때, 점수 정규화(예: Min-Max 스케일링) 방식이 일반적으로 기피되는 이유는 무엇입니까?
BM25 점수는 상한이 없고 특정 쿼리의 길이나 코퍼스 통계에 크게 의존하기 때문에, 그 분포가 쿼리마다 매우 불규칙하게 요동칩니다. 이러한 점수를 정규화하면 예측할 수 없는 가중치 편향이 발생합니다. 반면 RRF는 순수하게 서수적인 순위(Ordinal ranks)에 의존하므로 기본 점수 분포와 무관하게 안정적인 융합이 가능합니다.
Quiz 2: ColBERT의 MaxSim 연산에서, 각 쿼리 토큰에 대해 문서 토큰들과의 유사도 ‘평균’이 아닌 ‘최댓값(Maximum)‘을 취하는 이유는 무엇입니까?
특정 쿼리 토큰(예: “PyTorch”)은 일반적으로 긴 문서 내에서 오직 한두 개의 특정 단어와 강하게 정렬됩니다. 만약 모든 문서 토큰에 걸쳐 평균 유사도를 구한다면, 정확히 일치하는 단어에서 발생한 강력한 신호가 문서 내 수백 개의 무관한 배경 토큰들에 의해 완전히 희석(Diluted)되어 버리기 때문입니다.
Quiz 3: 대규모 코퍼스에 대한 1단계 검색(First-stage retrieval)에 Cross-Encoder를 사용할 수 없게 만드는 가장 큰 연산 병목 현상은 무엇입니까?
Cross-Encoder는 쿼리와 문서를 하나로 연결하여 트랜스포머 레이어를 함께 통과시켜야 합니다. 즉, 문서의 표현(Representation)을 오프라인에서 미리 계산해 둘 수 없습니다. 100만 개의 문서가 있다면, 시스템은 쿼리 시점에 100만 번의 거대한 신경망 순전파(Forward pass)를 수행해야 하므로 실시간 서비스가 불가능한 지연 시간이 발생합니다.
Quiz 4: SPLADE는 BM25와 같은 전통적인 희소 검색 알고리즘을 괴롭히는 “어휘 불일치(Vocabulary Mismatch)” 문제를 어떻게 해결합니까?
SPLADE는 BERT 스타일 인코더의 MLM(Masked Language Modeling) 헤드를 활용하여 신경망 기반의 문서 확장을 수행합니다. 문서에 명시적으로 등장하지 않는 동의어나 관련어의 어휘 차원에도 0이 아닌 가중치를 할당할 수 있게 함으로써, 정확한 일치(Exact-match) 인프라를 사용하면서도 의미론적 검색을 달성합니다.
Quiz 5: 다중 리트리버 결과 에 걸쳐 문서 의 RRF 점수 융합을 규정하는 정규 수학적 시퀀스를 제시하고, 이론적 상한선을 정식화하십시오.
문서 에 대한 RRF 점수는 다음과 같이 정의됩니다: . 여기서 는 리트리버 내에서의 서수 순위이고, 는 평활화 파라미터입니다. 모든 리트리버에서 1위로 서열화된 문서의 이론적 상한선은 입니다. 반대로 후보 풀에 아예 랭크되지 않은 문서의 하한선은 0으로 수학적 경계가 형성됩니다. 이러한 공식화는 엔지니어들이 요동치는 기본 점수와 무관하게 융합 결과에 대한 확실한 계층 경계를 도출할 수 있도록 돕습니다.
References
- Formal, T., et al. (2021). SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval. arXiv:2109.10086.
- Cormack, G. V., Clarke, C. L. A., & Buettcher, S. (2009). Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods. SIGIR.
- Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. arXiv:2004.12832.
- Sun, W., et al. (2023). Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents. arXiv:2304.09542.
- Gao, L., et al. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. arXiv:2212.10496.