5.2 Routing Algorithms (라우팅 알고리즘)
이전 섹션에서 우리는 Mixture of Experts (MoE) 아키텍처가 모델의 전체 용량(Capacity)과 추론 연산량(Compute)을 성공적으로 분리한다는 것을 확인했습니다. 하지만 이 우아한 아키텍처의 성공 여부는 단 하나의 매우 민감한 구성 요소인 Router (또는 Gating Network) 에 전적으로 의존합니다.
만약 전문가(Experts)들이 메가 병원의 전문의들이라면, 라우터는 환자를 분류하는 간호사입니다. 만약 이 분류 간호사가 전체 환자의 99%를 심장 전문의에게만 보낸다면, 심장 전문의는 과로로 쓰러질 것이고 다른 전문의들은 할 일 없이 대기만 하게 되며, 결국 병원 전체의 처리량은 붕괴될 것입니다. MoE 용어로 이러한 치명적인 시스템 실패 모드를 Expert Collapse (전문가 붕괴) 또는 라우팅 붕괴라고 부릅니다.
지난 10년간 MoE 아키텍처가 진화해 온 과정은, 근본적으로 이 ‘라우팅 문제’를 해결하기 위한 투쟁의 역사입니다. 이 섹션에서는 2017년의 초기 확률론적 해킹 기법부터, DeepSeek-V3와 같은 최전선(Frontier) 모델들을 구동하는 우아한 ‘보조 손실 없는(Auxiliary-loss-free)’ 패러다임에 이르기까지, 라우팅 알고리즘의 수학적 및 공학적 발전 과정을 해부해 보겠습니다.
1. 기준점: 표준 Top- 라우팅과 그 한계
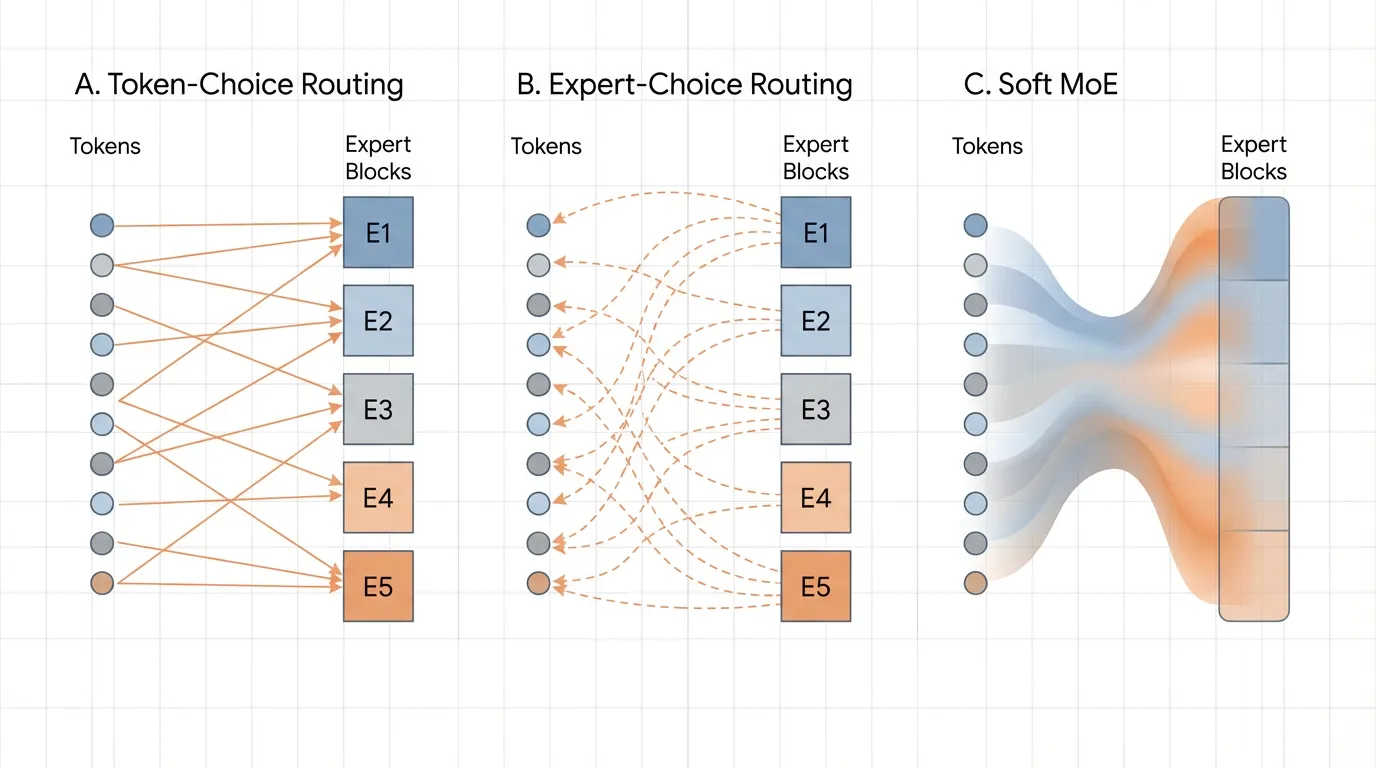
가장 직관적인 라우팅 접근법은 Token-Choice Routing (토큰 주도 라우팅, 구체적으로는 Top-) 입니다. 주어진 토큰 표현 에 대해, 라우터는 이를 개의 사용 가능한 전문가에 해당하는 로짓(Logits) 벡터로 투영합니다. 이후 Softmax 함수가 확률 분포를 생성하고, 토큰은 가장 높은 확률을 가진 개의 전문가에게 발송됩니다.
수학적으로는 타당해 보이지만, 이 순진한 접근 방식은 실제 학습 환경에서 ‘부익부 빈익빈(Rich get richer)‘이라는 자기 강화 피드백 루프에 빠져 실패합니다. 학습 초기에는 무작위 가중치 초기화로 인해 특정 배치의 토큰들에 대해 ‘Expert A’가 ‘Expert B’보다 아주 약간 더 나은 성능을 낼 수 있습니다. 라우터는 이를 학습하고 점차 더 많은 토큰을 ‘Expert A’에게 보냅니다. ‘Expert A’는 더 많은 토큰을 받기 때문에 더 많은 그래디언트 업데이트(Gradient updates)를 받게 되고, 결과적으로 성능이 더욱 좋아집니다. 불과 수천 스텝 만에 라우터는 모든 토큰을 ‘Expert A’에게 몰아주게 됩니다. 나머지 전문가들은 그래디언트를 전혀 받지 못해 학습이 멈추는 Dead Experts (죽은 전문가) 상태가 됩니다.
2. 1세대: Noisy Top- 와 보조 손실 (Auxiliary Losses)
전문가 붕괴를 막기 위해, Shazeer 등이 발표한 2017년의 기념비적인 MoE 논문 [1] 에서는 Noisy Top- Routing 을 도입했습니다. Top- 를 선택하기 전 로짓에 튜닝 가능한 가우시안 노이즈(Gaussian noise)를 주입함으로써, 라우터가 강제로 다양한 전문가를 탐색하도록 만들어 초기의 고착 현상을 방지합니다.
하지만 대규모 학습에서 노이즈만으로는 충분하지 않았습니다. 엔지니어들은 Auxiliary Load-Balancing Loss (보조 로드 밸런싱 손실, ) 이라는 개념을 도입했습니다. 이는 학습 중 주된 언어 모델링 손실(Language modeling loss)에 추가되는 페널티 항입니다. 전문가 간의 토큰 분포가 균등 분포(Uniform distribution)에서 벗어날 경우 수학적으로 모델에 페널티를 부여합니다.
여기서 는 페널티의 강도를 조절하는 하이퍼파라미터입니다.
엔지니어링 트레이드오프 (MoE의 “Alignment Tax”): 보조 손실은 하드웨어 활용도(Utilization) 문제는 해결했지만, 심각한 모델링 문제를 야기했습니다. 만약 가 너무 높으면, 라우터는 단순히 로드 밸런싱 할당량을 채우기 위해 토큰을 최적이 아닌 전문가에게 억지로 보내게 됩니다. 이는 Token-to-Expert Affinity (토큰과 전문가 간의 친화도) 를 훼손합니다. 즉, 모델이 하드웨어 효율성을 위해 지능(Intelligence)을 희생하는 결과를 낳게 됩니다.
3. 2세대: Expert Choice Routing (ECR)
2022년, Google Brain의 연구원들은 패러다임의 전환을 제안했습니다: Expert Choice Routing (ECR) [2]. 만약 토큰이 전문가를 선택하는 방식이 불균형을 초래한다면, 그 관계를 뒤집어보면 어떨까요?
ECR에서는 각 토큰이 Top- 전문가를 선택하는 대신, 각 전문가가 Top- 토큰을 선택 합니다.
모든 전문가에게는 고정된 Capacity Factor (주어진 배치에서 처리할 수 있는 최대 토큰 수) 가 할당됩니다. 라우터는 표준적인 토큰-전문가 친화도 행렬(Affinity matrix)을 계산합니다. 그런 다음 이 행렬을 전치(Transpose)합니다. 각 전문가는 전체 토큰 배치를 스캔한 뒤, 자신의 버퍼를 채우는 데 필요한 정확한 개수의 토큰을 당겨옵니다.
ECR의 PyTorch 구현
표준 Top- 와 달리, ECR은 전문가 차원이 아닌 시퀀스/배치 차원에 대해 작동합니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ExpertChoiceRouting(nn.Module):
def __init__(self, d_model, num_experts, capacity_factor):
super().__init__()
self.num_experts = num_experts
self.capacity_factor = capacity_factor
# 라우터 네트워크
self.router = nn.Linear(d_model, num_experts, bias=False)
def forward(self, x):
"""
x shape: [batch_size, seq_len, d_model]
"""
batch_size, seq_len, d_model = x.shape
num_tokens = batch_size * seq_len
# 전문가당 고정된 용량 계산
# 예: capacity_factor=2.0 이면, 전문가는 평균 토큰 할당량의 2배를 처리함
expert_capacity = int((num_tokens / self.num_experts) * self.capacity_factor)
x_flat = x.view(-1, d_model) # [num_tokens, d_model]
# 1. 친화도 로짓 계산: [num_tokens, num_experts]
logits = self.router(x_flat)
# 2. 라우팅 가중치로 변환 (전문가 차원에 대해 Softmax)
weights = F.softmax(logits, dim=-1)
# 3. 전치(TRANSPOSE): 전문가들이 모든 토큰을 볼 수 있도록 변환 -> [num_experts, num_tokens]
weights_t = weights.t()
# 4. 전문가의 선택(Expert Choice): 각 전문가가 자신의 버퍼 크기(`expert_capacity`)만큼의 상위 토큰을 선택
# top_weights, top_indices shape: [num_experts, expert_capacity]
top_weights, top_indices = torch.topk(weights_t, expert_capacity, dim=-1)
# (실제 전체 구현에서는 이제 top_indices를 사용하여 토큰을 gather하고,
# 해당 전문가를 통해 처리한 뒤, 다시 scatter하여 원래 형태로 복원합니다.)
return top_indices, top_weights
# 사용 예시
layer = ExpertChoiceRouting(d_model=1024, num_experts=8, capacity_factor=1.5)
dummy_input = torch.randn(2, 128, 1024) # 총 256개의 토큰
indices, weights = layer(dummy_input)
# 8명의 전문가 각각이 정확히 48개의 토큰을 선택함 (256 / 8 * 1.5)
print(f"Indices shape: {indices.shape}") # 예상 결과: [8, 48]ECR의 장단점:
- 장점 (Pro): 정의상 완벽한 로드 밸런싱이 보장됩니다. 보조 손실이 필요 없으므로, 강제 할당으로 인한 친화도 훼손 문제가 발생하지 않습니다.
- 단점 (Con): 토큰당 연산량이 가변적입니다. 매우 복잡한 토큰은 4명의 서로 다른 전문가에게 선택될 수 있는 반면, 단순하거나 정보량이 적은 토큰은 어떤 전문가에게도 선택되지 않아 순전파 과정에서 사실상 누락(Drop)될 수 있습니다. 이러한 가변적인 라우팅은 추론 시 자기회귀적(Autoregressive) 생성을 매우 복잡하게 만듭니다.
4. 3세대: Soft MoE와 미분 가능한 라우팅
또 다른 연구의 흐름은 미분 불가능한(Non-differentiable) argmax 나 topk 연산을 완전히 제거하는 것이었습니다. Soft MoE [3] 는 이산적이고 하드한 라우팅을 연속적이고 소프트한 할당으로 대체합니다.
온전한 형태의 토큰 하나를 특정 전문가에게 보내는 대신, Soft MoE는 시퀀스 내 모든 토큰의 가중 평균을 계산하여 이 “혼합된 토큰(Blended token)“을 전문가에게 전달합니다. 모든 연산이 연속적인 행렬 곱셈이기 때문에, 전체 라우팅 레이어가 완전히 미분 가능(Fully differentiable)해집니다.
이 방식은 수학적으로 우아하고 학습 시 매우 안정적이지만, 연속적인 혼합을 계산하기 위해 모든 전문가의 가중치를 메모리에 로드해야 합니다. 이는 초거대 규모 추론에 필수적인 ‘희소 활성화(Sparse activation)‘의 이점을 상쇄시키기 때문에, 수조 개의 파라미터를 가진 LLM보다는 주로 비전 모델(Vision MoEs)에서 제한적으로 사용됩니다.
 Source: Generated by Gemini
Source: Generated by Gemini
5. 보조 손실 없는 라우팅 (DeepSeek-V3)
최근의 발전 과정에서, 업계는 보조 손실(Auxiliary losses)이 모델 지능의 상한선을 심각하게 깎아먹고 있다는 사실을 깨달았습니다. DeepSeek-V3 [4] 는 시스템 엔지니어링의 걸작인 Auxiliary-Loss-Free Routing via Dynamic Bias (동적 편향을 통한 보조 손실 없는 라우팅) 를 도입했습니다.
손실 함수에 페널티를 부여하는 대신, DeepSeek-V3는 보조 손실 자체를 완전히 제거했습니다. 로드 밸런싱을 유지하기 위해, 그들은 라우팅 로짓에 각 전문가 에 대한 동적 편향(Dynamic bias) 항 를 추가했습니다:
작동 메커니즘:
- 학습 중에 시스템은 각 전문가의 부하(Load)를 모니터링합니다.
- 만약 특정 전문가 가 너무 많은 토큰을 받고 있다면 (과부하), 해당 편향 항 를 미세하게 감소시킵니다.
- 만약 전문가 가 토큰을 받지 못해 굶주리고 있다면 (저부하), 편향 항 를 미세하게 증가시킵니다.
- 핵심: 이 편향 항은 오직 Top- ‘선택’ 과정에만 사용됩니다. 이것은 연산 그래프(Computational graph)에서 분리되어(Detached) 있으며, 전문가 출력과 곱해지는 라우팅 가중치를 계산할 때는 사용되지 않습니다.
편향이 그래디언트 테이프(Gradient tape) 외부에서 동적으로 조정되기 때문에, 모델은 물리적으로 부하를 분산하도록 강제되지만, 역전파(Backpropagation) 과정은 인위적인 밸런싱 제약에 의해 전혀 오염되지 않습니다. 모델은 순수한 토큰-전문가 친화도만을 학습하게 되며, 이는 훨씬 더 가파른 수렴 곡선과 더 높은 추론 능력으로 이어집니다.
대화형 시각화: 라우팅 패러다임
이러한 알고리즘이 연산을 어떻게 분산시키는지 직관적으로 이해하기 위해 아래의 대화형 시뮬레이터를 사용해 보십시오. Token-Choice가 어떻게 병목 현상을 일으킬 수 있는지, 반면 Expert-Choice가 토큰 누락을 감수하면서 어떻게 하드웨어 활용도를 보장하는지 관찰할 수 있습니다.
Routing Paradigm Simulator
Compare how tokens are assigned to experts in different paradigms.
Tokens
Experts
요약 및 다음 장을 향하여
라우팅 알고리즘은 모든 MoE 모델의 정체성을 결정짓는 핵심입니다. 업계는 보조 손실을 배제하고 동적 편향 조정을 결합한 Top- 라우팅으로 크게 수렴했지만, 수천 개의 GPU에 걸쳐 이 토큰들을 실제로 이동시켜야 하는 물리적 현실은 완전히 새로운 병목 현상을 야기합니다.
수학적으로 라우팅 알고리즘이 부하의 균형을 완벽하게 맞췄다 하더라도, GPU 0에 있는 토큰을 GPU 412에 있는 전문가에게 클러스터 전체의 지연 없이 어떻게 효율적으로 전송할 수 있을까요? 다음 섹션인 5.3 Expert Parallelism (전문가 병렬화) 에서는 이러한 라우팅 알고리즘들이 지구적 규모에서 작동하도록 만드는 분산 시스템 엔지니어링의 세계로 깊이 들어가 보겠습니다.
Quizzes
Quiz 1: 학습 손실(Training loss)이 더 빠르게 수렴함에도 불구하고, 보조 로드 밸런싱 손실의 가중치()를 높이는 것이 왜 MMLU와 같은 벤치마크에서 모델의 제로샷 추론 능력을 저하시키는 결과를 초래할까요?
보조 손실은 라우터가 토큰-전문가 친화도(가장 관련성 높은 지식을 가진 전문가에게 토큰을 보내는 것)보다 하드웨어 활용도(토큰을 균등하게 분배하는 것)를 우선시하도록 강제합니다. 만약 가 너무 높으면, 수학 전문가의 버퍼가 가득 차 있다는 이유만으로 고도로 복잡한 수학 토큰이 프랑스 문학을 전문으로 하는 전문가에게 라우팅될 수 있습니다. 이는 전문가들의 전문성을 오염시키고 모델의 전반적인 추론 능력을 심각하게 저하시킵니다.
Quiz 2: Expert Choice Routing (ECR) 에서는 시퀀스 내의 특정 토큰이 어떤 전문가에게도 선택되지 않을 수학적 가능성이 존재합니다. 표준 Transformer 아키텍처에서 시퀀스 중간의 토큰이 누락(Drop)되는 것이 왜 매우 문제가 되며, 아키텍처는 이를 어떻게 보완해야 할까요?
표준 Transformer에서 토큰이 MoE 레이어에 의해 완전히 누락되면, 후속 레이어에서 해당 토큰의 표현은 영벡터(Zero-vector) 또는 순수한 잔차 연결(Residual connection) 값만 남게 됩니다. 이는 시퀀스 정보의 연속적인 흐름을 파괴하며, 특히 다음 토큰이 현재 토큰의 정확한 표현에 크게 의존하는 자기회귀적 생성(Autoregressive generation)에서 치명적입니다. 이를 보완 위해 ECR 모델들은 누락된 토큰을 앞으로 전달하기 위해 잔차 연결()에 크게 의존하지만, 여전히 Top- 라우팅에 비해 자기회귀적 KV-캐싱을 극도로 예측 불가능하게 만듭니다.
Quiz 3: DeepSeek-V3는 부하의 균형을 맞추기 위해 라우팅 로짓에 동적 편향 항 를 추가하지만, 라우팅 가중치의 그래디언트 계산에서는 이 편향을 명시적으로 제외합니다. 만약 역전파(Backpropagation) 과정 중 그래디언트 테이프에 이 편향 항이 포함된다면 어떤 일이 발생할까요?
만약 편향 항이 그래디언트 테이프에 포함된다면, 모델은 특정 배치의 일시적인 부하 불균형을 해결하기 위해 내부 라우터 가중치()를 영구적으로 수정하는 방향으로 학습하게 될 것입니다. 편향은 즉각적인 하드웨어 병목을 해결하기 위한 일시적이고 시스템적인 “찌르기(Nudge)” 역할을 해야 합니다. 그래디언트 계산에서 이를 제외함으로써, 라우터의 가중치는 오직 의미론적인 토큰-전문가 친화도(언어 모델링 목표의 교차 엔트로피 손실)에 기반해서만 업데이트되며, 모델은 “현재 GPU에게 편리한 것”이 아니라 “무엇이 정답인지”를 순수하게 학습할 수 있게 됩니다.
References
- Shazeer, N., et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv:1701.06538.
- Zhou, Y., et al. (2022). Mixture-of-Experts with Expert Choice Routing. arXiv:2202.09368.
- Puigcerver, J., et al. (2023). From Sparse to Soft Mixtures of Experts. arXiv:2308.00951.
- DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv:2412.19437.