이전 섹션에서 우리는 Supervised Fine-Tuning (SFT) 와 Parameter-Efficient Fine-Tuning (PEFT) 를 사용하여 모델의 가중치를 물리적으로 변경하는 방법을 살펴보았습니다. 두 패러다임 모두 전용 학습 단계, 그래디언트(Gradient) 계산, 그리고 옵티마이저(Optimizer) 상태를 필요로 합니다.
하지만 역전파(Backpropagation)에 할당할 연산 예산이 전혀 없다면 어떨까요? 혹은 LoRA 어댑터를 띄우는 것이 구조적으로 불가능한 실시간 환경에서 모델을 특정 사용자의 페르소나에 맞춰야 한다면 어떻게 해야 할까요?
여기서 Prompt Engineering 이 등장합니다. 주류 담론에서 프롬프트 엔지니어링은 종종 “심호흡을 하세요”나 “당신은 유용한 어시스턴트입니다”와 같은 문구를 추가하는 일종의 흑마법(Dark art)처럼 취급됩니다. 하지만 파운데이션 모델 엔지니어링의 관점에서 볼 때, 프롬프팅은 수학적으로나 기능적으로 SFT의 대용품(Surrogate) 입니다. 컨텍스트 윈도우(Context window)를 세심하게 구조화함으로써, 우리는 모델이 순전파 활성화(Forward-pass activations) 내부에서 전적으로 ‘암묵적인(Implicit)’ 미세 조정 과정을 거치도록 강제할 수 있습니다.
기계론적 관점: 암묵적 경사하강법으로서의 어텐션
수년 동안, 모델이 프롬프트에서 몇 개의 예제를 보는 것만으로 태스크에 적응하는 In-Context Learning (ICL) 의 경험적 성공은 발현적(Emergent) 미스터리로 취급되었습니다. 모델은 가중치를 업데이트하지 않고 어떻게 “학습”하는 것일까요?
2023년, Dai et al. [1] 과 von Oswald et al. [2] 의 기념비적인 연구는 이에 대한 기계론적(Mechanistic) 해답을 제시했습니다: 트랜스포머의 어텐션(Attention)은 경사하강법(Gradient Descent)과 수학적 쌍대성(Dual form)을 갖습니다.
프롬프트에 퓨샷(Few-shot) 예제 를 제공할 때, 모델은 단순히 이를 수동적으로 읽는 것이 아닙니다. 셀프 어텐션(Self-attention) 메커니즘은 메타 옵티마이저(Meta-optimizer)로 작동합니다. 순전파 과정에서 모델은 데모 예제로부터 “메타 그래디언트(Meta-gradients)“를 계산하고 이를 내부 표현에 적용하여 가중치 업데이트를 시뮬레이션합니다.
ICL의 수학적 이해
단순화된 선형 어텐션(Linear attention) 메커니즘을 고려해 보겠습니다. 표준 제로샷(Zero-shot) 추론은 전적으로 사전 학습된 가중치 에 의존합니다. 하지만 퓨샷 예제가 도입되면, 어텐션 메커니즘은 동적인 가중치 업데이트 을 구성합니다:
여기서:
- 는 데모 입력 의 키(Key) 벡터 표현입니다.
- 는 데모 레이블 의 값(Value) 벡터 표현입니다.
- 은 퓨샷 예제의 수입니다.
새로운 쿼리 (실제 사용자의 질문)가 처리될 때, 출력은 다음과 같습니다:
항에 주목하십시오. 이는 사용자의 쿼리와 퓨샷 예제 간의 어텐션 점수(유사도)입니다. 모델은 말 그대로 평균 제곱 오차(MSE) 목적 함수에 기반한 경사하강법 스텝을 수행하며, 내부 프로젝션 행렬을 실시간으로 조정하고 있는 것입니다. In-Context Learning 은 암묵적인 Supervised Fine-Tuning 입니다.
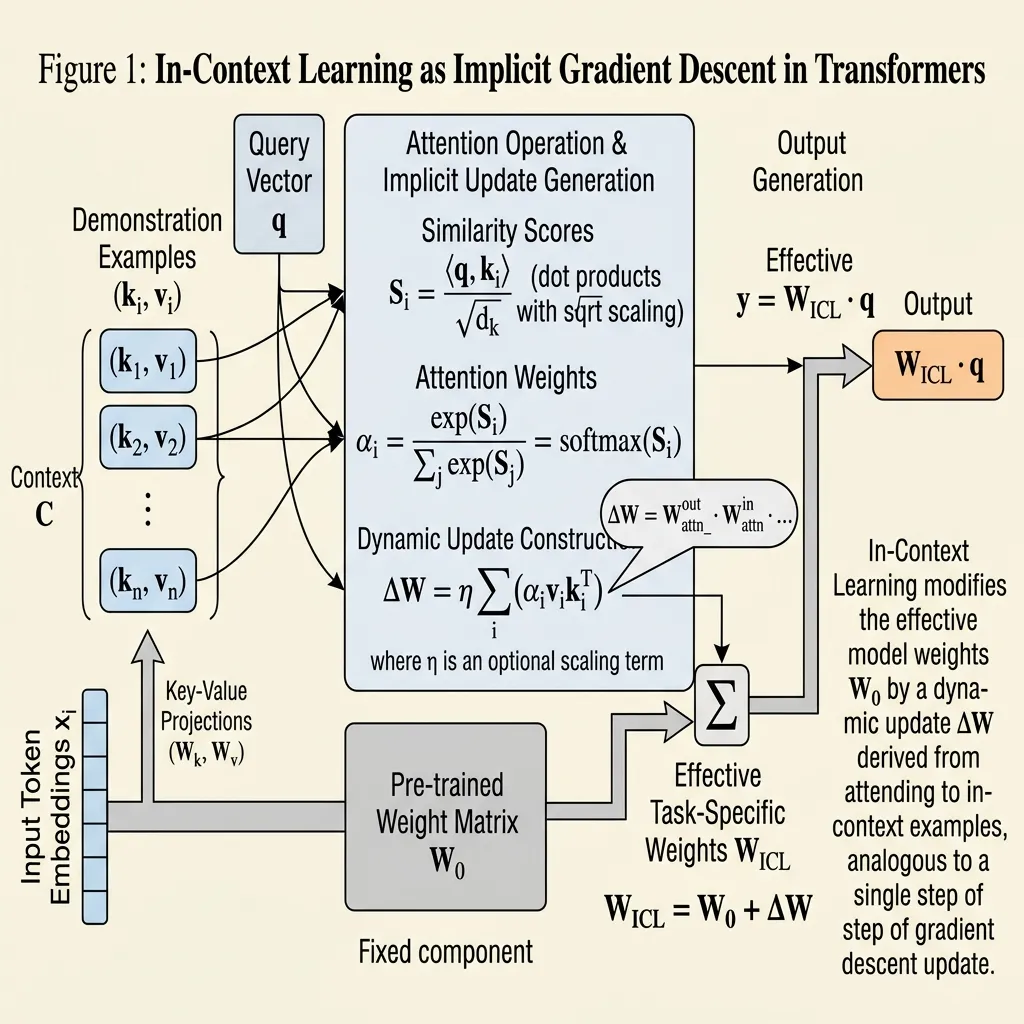 Source: Generated by Gemini. (트랜스포머 어텐션이 메타 옵티마이저로 작동하여 암묵적 가중치 업데이트를 계산하는 개념도).
Source: Generated by Gemini. (트랜스포머 어텐션이 메타 옵티마이저로 작동하여 암묵적 가중치 업데이트를 계산하는 개념도).
연산의 전개 (Unrolling Compute): Chain-of-Thought (CoT)
퓨샷 프롬프팅이 SFT의 데이터 측면을 대체한다면, Chain-of-Thought (CoT) 는 깊이(Depth) 측면을 대체합니다.
표준 트랜스포머 아키텍처의 근본적인 한계는 고정된 연산 깊이입니다. 80개의 레이어를 가진 모델은 토큰당 80번의 비선형 변환만 실행할 수 있습니다. 만약 어떤 문제를 푸는 데 500단계의 논리적 연역이 필요하다면, 아무리 미세 조정을 잘 받은 모델이라 할지라도 즉시 최종 답을 출력하도록 강제될 경우 실패할 수밖에 없습니다.
CoT (“단계별로 생각해 봅시다”)는 이러한 아키텍처적 병목을 우회합니다. 모델이 중간 추론 토큰을 생성하도록 강제함으로써, 우리는 모델이 자신의 연산 그래프를 전개(Unroll) 하도록 허용합니다.
생성된 모든 토큰은 다음 단계를 위해 모델로 다시 피드백되며, 이는 사실상 연산 깊이를 곱하는 효과를 낳습니다. 만약 모델이 답을 내기 전에 100개의 추론 토큰을 생성한다면, 이는 80개의 레이어를 100번 적용한 것과 같으며, 결과적으로 8,000개 레이어 분량의 순차적 연산을 수행한 셈이 됩니다. 이 메커니즘은 OpenAI의 o1이나 DeepSeek-R1 [3] 과 같은 고급 추론 모델을 구동하는 Test-Time Compute Scaling 의 핵심 원리입니다.
엔지니어링 시대: DSPy와 프롬프트 컴파일러
프롬프팅을 SFT로 간주하게 되면 필연적인 엔지니어링적 결론에 도달하게 됩니다: 프롬프트가 학습 데이터 및 하이퍼파라미터와 동일하다면, 인간이 이를 수동으로 작성해서는 안 됩니다.
수동 프롬프트 엔지니어링은 깨지기 쉽습니다. Llama-3-70B 에 고도로 최적화된 프롬프트는 DeepSeek-V3 로 전환할 때 성능이 저하되는 경우가 많습니다. 서로 다른 모델은 서로 다른 사전 학습 매니폴드(Pre-training manifolds)와 토크나이저를 가지기 때문입니다.
이 문제를 해결하기 위해, 업계는 스탠포드 대학에서 개발한 DSPy (Declarative Self-Improving Language Programs) [4] 와 같은 프레임워크가 주도하는 알고리즘적 프롬프트 최적화 (Algorithmic Prompt Optimization) 로 패러다임을 전환했습니다.
문자열에서 파라미터로
DSPy 는 날것의 문자열 조작을 추상화합니다. 개발자는 프롬프트를 작성하는 대신, Signature (입출력 스키마)와 Module (연산 흐름)을 정의합니다. 그러면 프레임워크가 옵티마이저(“Teleprompter”)를 사용하여 검증 지표(Validation metric)를 기반으로 최적의 지시문(Instructions)을 자동으로 검색하고 최적의 퓨샷 데모를 부트스트랩(Bootstrap)합니다.
아래는 2026년 현재 프로덕션 환경에서 프롬프트 엔지니어링이 어떻게 체계적으로 실행되는지 보여주는 예시입니다:
import dspy
from dspy.teleprompt import MIPROv2
# 1. Signature 정의 ("아키텍처")
class MultiHopQA(dspy.Signature):
"""검색된 컨텍스트를 활용하여 복잡한 질문에 답변합니다."""
context = dspy.InputField(desc="검색된 사실적 스니펫들")
question = dspy.InputField()
reasoning = dspy.OutputField(desc="단계별 논리적 연역 과정")
answer = dspy.OutputField(desc="짧고 사실적인 답변")
# 2. Module 정의 ("순전파 흐름")
class RAGPipeline(dspy.Module):
def __init__(self):
super().__init__()
# CoT 레이어를 선언하지만, 프롬프트를 직접 작성하지는 않습니다!
self.generate_answer = dspy.ChainOfThought(MultiHopQA)
def forward(self, question: str, context: list[str]):
return self.generate_answer(context=context, question=question)
# 3. Compile ("SFT 학습 루프")
# MIPROv2는 베이지안 최적화를 사용하여 최적의 프롬프트 지시문과 퓨샷 예제를 찾습니다.
teleprompter = MIPROv2(
metric=exact_match_metric,
num_candidates=10,
init_temperature=1.0
)
# 이 과정은 LLM에 수천 번의 쿼리를 보내 프롬프트를 실질적으로 "학습"시킵니다.
compiled_rag = teleprompter.compile(
RAGPipeline(),
trainset=train_examples,
valset=val_examples,
requires_permission_to_run=False
)
# 4. "가중치" 저장 (최적화된 프롬프트 JSON)
compiled_rag.save("optimized_rag_prompt.json")이 패러다임에서는 기본 LLM을 교체하더라도 프롬프트를 수동으로 다시 작성하지 않습니다. 단순히 compile() 메서드를 다시 실행하기만 하면, 옵티마이저가 새로운 모델에 대해 최적의 암묵적 경사하강법을 촉발하는 정확한 문구와 예제를 찾아냅니다.
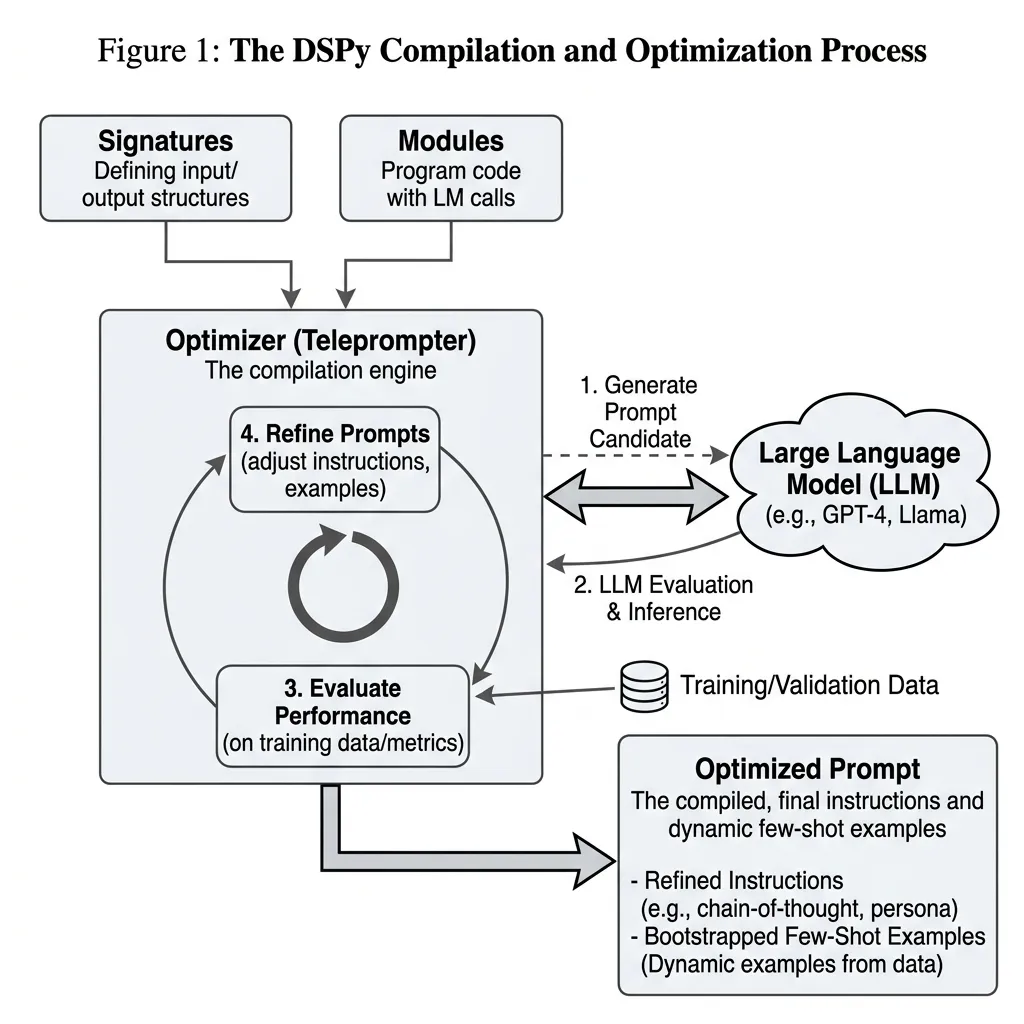 Source: Generated by Gemini. (DSPy 컴파일 과정의 흐름도: Signature와 Module이 옵티마이저를 거쳐 부트스트랩된 프롬프트를 생성하는 과정).
Source: Generated by Gemini. (DSPy 컴파일 과정의 흐름도: Signature와 Module이 옵티마이저를 거쳐 부트스트랩된 프롬프트를 생성하는 과정).
인터랙티브 시각화: 프롬프트 컴파일러
알고리즘적 프롬프트 옵티마이저가 수행하는 작업의 규모를 이해하려면 아래의 인터랙티브 컴포넌트를 사용해 보십시오. 이 시각화는 단 두 줄의 간단한 DSPy Signature가 컴파일 단계를 거치며 어떻게 거대하고 고도로 최적화된 Few-Shot Chain-of-Thought 프롬프트로 확장되는지 시뮬레이션합니다.
DSPy Prompt Compiler Simulation
Watch how a simple Python class expands into a production-grade prompt.
class MultiHopQA(dspy.Signature):
"""Answer complex questions by leveraging retrieved context."""
context = dspy.InputField(desc="Retrieved factual snippets")
question = dspy.InputField()
reasoning = dspy.OutputField(desc="Step-by-step logical deduction")
answer = dspy.OutputField(desc="Short factual answer")요약 및 다음 단계
프롬프트 엔지니어링은 휴리스틱에 의존하던 “프롬프트 속삭임(Prompt whispering)“에서 벗어나 엄밀한 엔지니어링 규율로 성숙했습니다. In-Context Learning을 암묵적 경사하강법으로, Chain-of-Thought를 추론 시간 연산 스케일링(Test-time compute scaling)으로 이해함으로써, 우리는 프롬프팅을 Supervised Fine-Tuning의 매우 효율적이고 그래디언트가 필요 없는 대안으로 활용할 수 있습니다. DSPy와 같은 프레임워크는 선언적 프로그램을 수학적으로 최적화된 프롬프트 구조로 컴파일함으로써 이를 공식화합니다.
하지만 명시적인 SFT(가중치 업데이트)를 사용하든 암묵적인 SFT(프롬프트 최적화)를 사용하든, 우리는 여전히 인간의 데모를 기반으로 모델에게 태스크를 수행하는 방법 을 가르치고 있을 뿐입니다. 만약 인간의 데모에 결함이 있거나, 모델이 단순히 인간이 작성한 것을 따라 하는 것을 넘어 인간이 선호하는 것을 학습하게 만들고 싶다면 어떻게 해야 할까요?
다음 장인 Chapter 10: Alignment: RLHF & Direct Preference 에서는 모방 학습(Imitation learning)의 경계를 넘어 선호도 최적화(Preference optimization)로 나아가며, PPO 및 DPO와 같은 알고리즘이 어떻게 모델을 복잡한 인간의 가치관 및 안전 가이드라인에 맞게 정렬(Align)시키는지 탐구해 보겠습니다.
Quizzes
Quiz 1: In-Context Learning (ICL)이 암묵적 경사하강법으로 작동한다면, 왜 명시적인 SFT는 학습할 수 있는 매우 특이한 입력 포맷(예: 공백을 밑줄로 대체)에 대해 ICL의 성능은 크게 저하되는 것일까요?
명시적인 SFT는 가중치 매니폴드를 물리적으로 변경하여 모델이 완전히 새로운 표현과 매핑을 학습할 수 있게 합니다. 반면 ICL은 전적으로 사전 학습된 가중치 내부에서 작동합니다. 이는 이미 존재하는 잠재적 회로(Latent circuitry)를 찾고 활성화하는 데 의존합니다. 포맷이 분포를 너무 크게 벗어난 경우(Out-of-distribution), 키(Key)와 값(Value)이 이전에 학습된 어떤 개념과도 일치하지 않기 때문에 어텐션 메커니즘이 의미 있는 메타 그래디언트를 계산할 수 없습니다.
Quiz 2: 트랜스포머 어텐션의 쌍대성(Dual form)에서, 모델의 암묵적 가중치를 업데이트하는 “그래디언트” 역할을 하는 구성 요소는 무엇입니까?
퓨샷 데모 예제의 값(Value) 벡터()입니다. 이 벡터들은 어텐션 점수(데모 키 와 현재 쿼리 의 내적)에 의해 가중치가 부여됩니다. 이렇게 가중치가 부여된 값들이 누적되어 동적 가중치 업데이트 을 형성합니다.
Quiz 3: 시스템 엔지니어링 관점에서 볼 때, Chain-of-Thought (CoT)가 모델의 연산 깊이를 확장하는 메커니즘으로 간주되는 이유는 무엇입니까?
트랜스포머는 고정된 수의 레이어를 가지고 있어, 생성되는 토큰당 정해진 양의 연산만 수행할 수 있습니다. 최종 답을 출력하기 전에 중간 추론 토큰을 생성함으로써, 모델은 시간에 따라 자신의 연산 그래프를 전개(Unroll)합니다. 각각의 새로운 토큰이 모델로 다시 피드백되면서, 문제 해결에 적용되는 비선형 변환의 총 횟수를 실질적으로 배가시키기 때문입니다.
Quiz 4: 광범위한 퓨샷 프롬프트를 수동으로 작성하는 대신 DSPy와 같은 프레임워크를 사용할 때 얻을 수 있는 주요 운영상의 이점은 무엇입니까?
이식성(Portability)과 최적화입니다. 수동 프롬프트는 단일 모델(예: Llama-3)의 특이성에 과적합됩니다. 모델이 업그레이드되면 프롬프트가 망가지는 경우가 많습니다. DSPy는 프롬프트를 프로그래밍적인 Signature로 추상화하고, 실제 텍스트와 예제를 학습 가능한 파라미터로 취급합니다. 컴파일을 다시 수행함으로써 프레임워크는 인간의 개입 없이도 새로운 모델에 대한 최적의 프롬프트를 자동으로 검색하고 부트스트랩합니다.
References
- Dai, D., et al. (2023). Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers. arXiv:2212.10559.
- von Oswald, J., et al. (2023). Transformers learn in-context by gradient descent. arXiv:2212.07677.
- DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948.
- Khattab, O., et al. (2024). DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv:2310.03714.