20.5 멀티 토큰 예측 (MTP)
앞 절에서 우리는 모델이 프로그램을 만들고 실행 결과를 활용하는 패턴을 봤습니다. 그런 작업에서는 모델이 바로 다음 토큰만 잘 맞히는 것보다, 몇 토큰 뒤의 구조를 미리 잡는 능력이 중요합니다. 함수 본문, SQL query, 수학 풀이, JSON tool call은 모두 “다음 글자”가 아니라 “곧 완성될 구조”를 요구합니다.
수년 동안 자기회귀(Autoregressive) 언어 모델링의 절대적인 공리는 Next-Token Prediction (NTP) 이었습니다. 우리는 과거의 컨텍스트 가 주어졌을 때 의 우도(likelihood)를 최대화하도록 모델을 학습시켜 왔습니다. 수학적으로는 우아하지만, 이 접근법은 심각한 구조적 병목 현상을 강제합니다. 모델은 미래의 구문, 논리, 추론을 위한 모든 ‘계획’을 오직 바로 다음 단계 하나만을 나타내는 단일 밀집 벡터(Dense Vector)에 압축해 넣어야 하기 때문입니다.
기존의 NTP 방식을 칠흑 같은 어둠 속에서 전방 1미터만 비추는 헤드라이트를 켜고 운전하는 것에 비유해 봅시다. 끊임없이 미세하게 방향을 조정하며 차선을 유지할 수는 있지만, 급격한 커브를 미리 예측하려면 장기적인 시야(Long horizon)에 걸쳐 암묵적이고 잠재적인 통찰력을 유지해야 하며, 이는 모델에게 극도로 어려운 작업입니다.
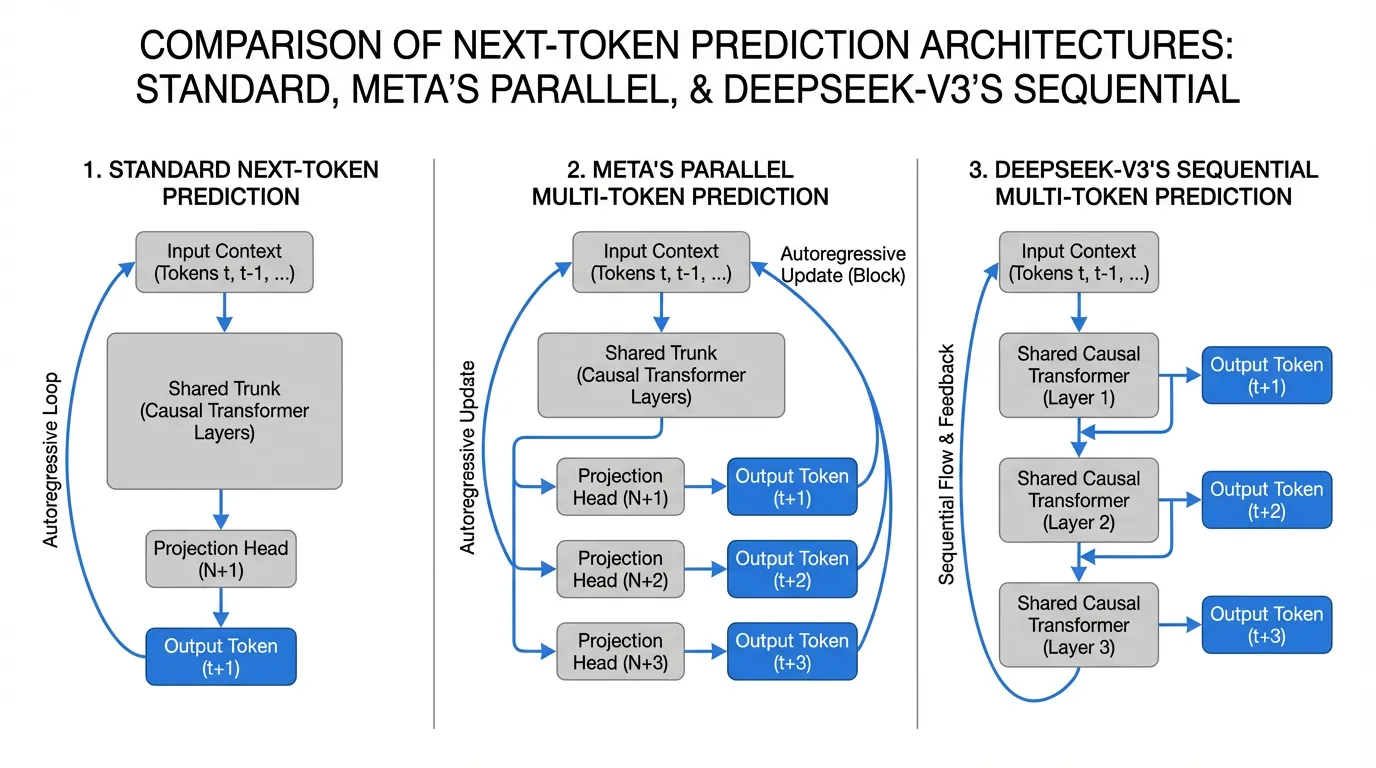
Multi-Token Prediction (MTP) 은 이러한 병목 현상을 근본적으로 해소합니다. 학습 과정에서 모델이 미래의 개 토큰을 명시적으로 예측하도록 강제함으로써, 지도 신호(Supervision signal)의 밀도를 높이고 은닉 표현(Hidden representations)이 장기적인 구조적 의존성을 인코딩하도록 만듭니다 [2]. 이 섹션에서는 MTP 패러다임을 해체하고, Meta가 도입한 병렬 아키텍처와 DeepSeek-V3에 배포된 순차적 인과(Causal) 아키텍처를 비교 분석해 보겠습니다 [1].
1. 아키텍처의 진화 (The Architectural Evolution)
역사적으로 다중 토큰 디코딩(Multi-token decoding)은 추론(Inference) 단계의 기교 정도로 취급되었습니다. Medusa나 Eagle과 같은 프레임워크는 사전 학습된 모델에 보조 예측 헤드를 접목하여 추측 해독(Speculative Decoding)을 위한 Draft 모델로 미세 조정(Fine-tuning)했습니다. 이는 추론 속도를 가속화했지만, 기본 모델 자체의 본질적인 추론 능력을 향상시키지는 못했습니다.
이러한 패러다임은 연구자들이 MTP 를 사전 학습 목표(Pre-training objective) 로 적용하기 시작하면서 완전히 전환되었습니다.
 Source: Generated by Gemini (Conceptual comparison of Parallel vs Sequential MTP)
Source: Generated by Gemini (Conceptual comparison of Parallel vs Sequential MTP)
Meta의 병렬 헤드 (Parallel Heads) 구조
Meta FAIR 연구진은 모델이 처음부터 미래의 여러 토큰을 동시에 예측하도록 학습시키면 훨씬 우수한 표현(Representation)을 얻을 수 있음을 증명했습니다 [2]. 이 아키텍처에서 메인 Transformer 트렁크(Trunk)는 은닉 상태 를 출력합니다. 단일 LM 헤드 대신, 모델은 개의 독립적인 프로젝션 블록을 갖습니다. 각 블록은 동일한 를 입력받아 독립적으로 을 예측합니다.
DeepSeek-V3의 순차적 헤드 (Sequential Heads) 구조
DeepSeek-V3는 이를 더욱 정교하게 다듬어 순차적이고 인과적인(Causal) MTP 모듈을 도입했습니다 [1]. 미래를 고립된 상태에서 독립적으로 예측하는 병렬 헤드와 달리, DeepSeek의 MTP 는 인과 사슬(Causal chain)을 유지합니다. 를 예측하기 위해, 모듈은 을 예측하는 데 사용된 은닉 상태와 의 실제 임베딩(학습 중에는 이미 알고 있음)을 결합하여 추가적인 공유 Transformer 레이어를 통과시킵니다 [1]. 이를 통해 토큰 의 예측이 선행하는 모든 토큰의 표현에 인과적으로 조건부화(Conditioned)되도록 보장합니다.
2. 수학적 정식화 및 PyTorch 구현 (Mathematical Formulation)
병렬 MTP 접근법을 수식화해 보겠습니다. 표준 NTP 에서 스텝 의 교차 엔트로피 손실(Cross-entropy loss)은 다음과 같습니다.
-토큰 MTP 설정에서는 다음 토큰에 대한 손실과 더불어, 미래의 개 토큰에 대한 보조 손실(Auxiliary loss)을 하이퍼파라미터 로 가중치를 두어 합산합니다 (일반적으로 1.0으로 설정하거나 먼 토큰일수록 감쇠시킴) [2].
학습 처리량(Throughput)을 저하시키지 않으면서 이를 PyTorch에서 효율적으로 구현하려면, 메인 LM 헤드( 매핑)를 개의 모든 예측에 걸쳐 공유하되, 은닉 상태 를 미래의 잠재 공간(Latent space) 로 이동시키는 경량 프로젝션 블록을 도입해야 합니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ParallelMTPModule(nn.Module):
"""
Multi-Token Prediction (Parallel Heads) 구현체
Reference: Gloeckle et al., 2024 (Meta FAIR)
"""
def __init__(self, d_model: int, vocab_size: int, num_future_tokens: int = 4):
super().__init__()
self.num_future_tokens = num_future_tokens
# VRAM 절약을 위해 모든 예측에 공유되는 LM 헤드
self.shared_lm_head = nn.Linear(d_model, vocab_size, bias=False)
# MTP 프로젝션 블록 (k=2 부터 n까지)
# k=1 은 표준 Next-Token Prediction이므로 메인 트렁크에서 직접 처리됨
self.mtp_projections = nn.ModuleList([
nn.Sequential(
nn.RMSNorm(d_model),
nn.Linear(d_model, d_model * 2, bias=False),
nn.SiLU(),
nn.Linear(d_model * 2, d_model, bias=False)
) for _ in range(num_future_tokens - 1)
])
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
"""
hidden_states: 메인 트렁크에서 온 [batch_size, seq_len, d_model]
Returns: [batch_size, num_future_tokens, seq_len, vocab_size] 형태의 로짓(logits)
"""
# 1. 표준 Next-token 예측 (k=1)
logits_k1 = self.shared_lm_head(hidden_states) # [B, S, V]
all_logits = [logits_k1]
# 2. 미래 토큰 예측 (k=2 부터 n까지)
for proj in self.mtp_projections:
# k번째 미래 토큰을 위해 트렁크의 은닉 상태를 프로젝션
# 표현(Representation)을 고정하기 위해 잔차 연결(Residual connection) 사용
z_k = proj(hidden_states) + hidden_states
logits_k = self.shared_lm_head(z_k)
all_logits.append(logits_k)
return torch.stack(all_logits, dim=1) # [B, n, S, V]
def compute_mtp_loss(logits: torch.Tensor, targets: torch.Tensor, loss_weights: list[float]) -> torch.Tensor:
"""
이동된 예측값과 타겟 시퀀스를 정렬하고 CE Loss를 계산합니다.
logits: [B, n, S, V]
targets: [B, S]
"""
B, n, S, V = logits.shape
total_loss = 0.0
for k in range(n):
shift = k + 1 # k=0은 t+1 예측, k=1은 t+2 예측 등
# 시퀀스 끝부분의 유효하지 않은(Invalid) 위치 잘라내기
valid_logits = logits[:, k, :-shift, :].reshape(-1, V)
valid_targets = targets[:, shift:].reshape(-1)
step_loss = F.cross_entropy(valid_logits, valid_targets)
total_loss += loss_weights[k] * step_loss
return total_loss타겟 정렬(Target Alignment)의 엔지니어링 과제
손실 함수 코드에서 shift = k + 1 로직에 주목해야 합니다. 표준 자기회귀 학습에서는 인덱스 t 의 로짓이 t+1 의 타겟과 평가됩니다. 두 번째 MTP 헤드()의 경우, 인덱스 t 의 로짓은 t+2 의 타겟과 평가되어야 합니다. 이러한 시프트(Shift)로 인해 가 증가할수록 시퀀스 끝에서 개의 유효한 학습 토큰을 잃게 됩니다. 시퀀스 길이가 4096이고 인 경우 이러한 잘림(Truncation)은 무시할 만한 수준이지만, Out-of-bounds 에러를 방지하기 위해 매우 세심한 텐서 슬라이싱(Tensor Slicing)이 요구됩니다.
3. 추론: 추측 해독의 “공짜 점심” (The “Free Lunch” of Speculative Decoding)
MTP 는 본질적으로 모델의 내부 표현(Internal representations)을 개선하기 위해 설계된 학습 목표입니다. 그러나 이는 엄청난 부가적 이점을 제공하는데, 바로 내장된 추측 해독(Built-in Speculative Decoding) 입니다 [2].
표준 추측 해독(Speculative Decoding)은 후보 토큰을 생성하기 위해 별도의 작은 “Draft 모델”을 VRAM에 로드해야 하며, 이후 거대한 “Target 모델”이 이를 검증합니다. 이러한 듀얼 모델 설정은 연산 구조상 번거롭고, 메모리 대역폭을 낭비하며, 특징 불일치(Feature misalignment, Draft 모델이 Target 모델이 절대 선택하지 않을 토큰을 예측하는 현상) 문제를 겪습니다.
MTP 환경에서는 을 예측하도록 학습된 보조 헤드들이 추론 시에도 그대로 유지됩니다. 이들은 메인 모델과 완전히 동일한 Transformer 트렁크 및 어휘 사전(Vocabulary)을 공유하기 때문에 이상적이고 오버헤드가 전혀 없는(Zero-overhead) Draft 모델 역할을 수행합니다 [1]. 추론 스텝 에서 MTP 헤드들은 개의 Draft 토큰 시퀀스를 생성합니다. 다음 스텝에서 메인 모델은 단 한 번의 병렬 Forward Pass로 이 Draft들을 검증합니다.
Interactive: MTP Speculative Decoding Process
The base Transformer model generates the hidden state h_t based on the current context.
(Shared) -> h_t
메인 모델이 Draft 토큰들에 동의하면, 단일 스텝 내에서 생성이 개 토큰만큼 앞으로 건너뛰게 되어 실제 소요 시간(Wall-clock time) 기준 최대 3배의 속도 향상을 얻을 수 있습니다 [2].
4. 스케일링 법칙과 트레이드오프 (Scaling Laws and Trade-offs)
MTP 는 만능 해결책이 아니며, 엄격한 스케일링 법칙을 따르고 특정한 엔지니어링 트레이드오프를 수반합니다 [2].
- 용량 임계점 (The Capacity Threshold): MTP 는 7B 파라미터 미만의 소형 모델에서는 오히려 성능을 저하시킵니다. 작은 신경망에 미래의 여러 토큰을 예측하도록 강제하면 제한된 파라미터 용량이 압도되어 기본 목표인 Next-token 예측조차 과소적합(Underfitting)되는 결과를 초래합니다. MTP 의 진정한 이점은 규모가 커질 때만 나타나며, 70B 이상의 대형 모델 영역에서 유의미한 성능 향상을 보여줍니다 [2].
- 추론 능력 vs 단순 사실 검색 (Reasoning vs. Fact Retrieval): MTP 는 모델이 구조적 계획(Structural planning)을 세우도록 강하게 편향시킵니다. 결과적으로 MTP 로 학습된 모델은 함수나 증명의 구조를 미리 내다보는 것이 필수적인 코드 생성(HumanEval) 및 수학적 추론(GSM8K) 벤치마크에서 압도적인 성능을 보입니다 [2]. 그러나 이는 순수한 사실 검색 작업(예: TriviaQA)에서는 약간의 성능 손실을 대가로 합니다. 잠재 공간(Latent space)이 깊고 정적인 암기보다는 미래의 구문을 압축하는 데 최적화되기 때문입니다.
어디에 특히 유용한가
- 코드 생성: 닫는 괄호, 타입, return value, helper function 사용이 몇 토큰 뒤와 맞아야 합니다.
- 수학 풀이: 다음 한 줄보다 풀이의 방향이 중요합니다.
- 구조화 출력: JSON, XML, tool call처럼 전체 schema 일관성이 필요한 경우 장기 계획 신호가 도움이 됩니다.
- Speculative decoding: 학습된 미래 토큰 head가 draft 역할을 해, 별도 작은 모델 없이 추론을 가속할 수 있습니다.
조심해야 할 점
MTP head를 붙였다고 항상 production latency가 줄어드는 것은 아닙니다. 실제 속도 향상은 draft token accept rate, batch size, KV cache 관리, 검증 패스 구현에 좌우됩니다. 또한 학습 중 auxiliary loss의 가중치가 너무 크면 기본 next-token 품질이 흔들릴 수 있습니다. 따라서 MTP는 모델 구조만이 아니라 training recipe와 serving stack을 함께 설계해야 하는 기법입니다.
5. 요약 및 열린 질문들 (Summary and Open Questions)
Multi-Token Prediction은 단순한 반응형 시퀀스 모델링에서 선제적인 구조적 계획(Proactive structural planning)으로의 패러다임 전환을 의미합니다. 학습 신호를 조밀하게 만들고 모델이 미래 상태를 명시적으로 모델링하도록 강제함으로써, MTP 는 추론 능력을 향상시키는 동시에 추론 가속화를 위한 네이티브 메커니즘을 제공합니다.
이제 한 단계 더 나아가면 질문은 “미래 몇 토큰을 동시에 예측할 수 있는가”에서 “전체 시퀀스를 여러 번 고쳐 쓰며 만들 수 있는가”로 바뀝니다. 바로 다음 절의 확산 기반 LLM이 이 질문을 다룹니다.
파운데이션 모델의 미래를 전망하며, 다음과 같은 열린 질문들을 고민해 볼 수 있습니다:
- MTP 가 추론(Reasoning)과 사실 검색(Factual retrieval) 사이의 트레이드오프를 강제한다면, 학습 중 토큰을 동적으로 라우팅하여 코드 블록은 MTP 지도를 받고 일반 사실 텍스트는 표준 NTP 지도를 받도록 설계할 수 있을까요?
- 기술적으로 미래의 시퀀스 위치를 차지하는 토큰을 예측할 때, MTP 는 RoPE와 같은 고급 위치 임베딩(Positional Embeddings)과 내부적으로 어떻게 상호작용할까요?
Quizzes
Quiz 1: 손실(Loss)을 계산할 때 각 프로젝션 헤드마다 타겟 시퀀스를 다르게 이동(Shift)시켜야 하는 이유는 무엇인가요?
각 헤드가 서로 다른 미래 오프셋(Offset)에 있는 토큰을 예측하기 때문입니다. 위치 의 기본 트렁크는 을 예측하므로 타겟을 1만큼 이동시킵니다. 위치 의 첫 번째 MTP 헤드는 를 예측하므로, 그 출력은 2만큼 이동된 타겟 시퀀스와 비교되어야 합니다. 올바르게 이동시키지 않으면 모델이 미래를 정확히 예측했음에도 불구하고 페널티를 받게 됩니다.
Quiz 2: DeepSeek-V3의 순차적(Sequential) MTP 아키텍처는 Meta의 병렬(Parallel) MTP 아키텍처와 개념적으로 어떻게 다른가요?
Meta의 병렬 MTP는 동일한 은닉 상태 에서 분기하는 독립적인 프로젝션 헤드를 사용하므로, 의 예측이 의 예측에 조건부화되지 않습니다. 반면 DeepSeek-V3는 인과 사슬을 유지하는 순차적 Transformer 블록을 사용합니다. 를 위한 MTP 모듈은 의 은닉 상태와 토큰 의 실제 임베딩을 함께 입력받아, 미래 예측이 완전한 인과적 컨텍스트에 기반하도록 보장합니다.
Quiz 3: 추측 해독(Speculative Decoding)을 수행할 때, 별도의 Draft 모델을 사용하는 것보다 MTP로 학습된 모델을 사용하는 것이 압도적으로 유리한 이유는 무엇인가요?
별도의 Draft 모델은 추가적인 VRAM을 소모하고 가중치를 로드하기 위한 메모리 대역폭을 요구하며, Target 모델과의 어휘(Vocabulary) 또는 표현 불일치로 인해 Draft 채택률이 낮아지는 문제를 겪습니다. 반면 MTP 모델은 자신의 프로젝션 헤드를 Drafter로 사용하므로 완벽한 잠재 공간 정렬(Latent space alignment)을 보장하고 메인 트렁크의 KV 캐시를 재사용하며 추가적인 메모리 오버헤드가 거의 발생하지 않습니다.
Quiz 4: 1B 파라미터 모델에서는 MTP가 성능을 저하시키지만 70B 파라미터 모델에서는 성능을 크게 향상시키는 현상의 원인은 무엇인가요?
MTP는 강력한 정규화(Regularization) 및 구조적 제약으로 작용합니다. 소형 모델은 다음 토큰 확률을 암기하는 동시에 장기적인 구조적 계획을 압축할 파라미터 용량이 부족하여 과소적합(Underfitting)이 발생합니다. 반면 대형 모델은 잉여 용량을 가지고 있으며, MTP는 이 잠재 용량을 활용하여 내부 표현을 강제로 개선함으로써 로컬 구문에 대한 과적합을 방지하고 전역적인 추론 능력을 향상시킵니다.
References
- DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv:2412.19437.
- Gloeckle, F., et al. (2024). Better & Faster Large Language Models via Multi-token Prediction. Meta FAIR. arXiv:2404.19737.