4.1 Encoder-only (BERT-style)
Google의 BERT (Bidirectional Encoder Representations from Transformers)로 대표되는 Encoder-only 모델은 Transformer 가족 트리에서 핵심적인 분기를 차지합니다. 생성형 사촌들(GPT와 같은 Decoder-only 모델)과 달리, Encoder-only 모델은 전체 컨텍스트를 동시에 바라봄으로써 텍스트를 이해 하고 표현 하도록 설계되었습니다.
이 장에서는 최초의 BERT부터 ModernBERT에 이르는 최신 발전에 이르기까지 Encoder-only 모델의 아키텍처, 동기 및 진화를 살펴봅니다.
The Metaphor: The Detective vs. The Storyteller (탐정과 이야기꾼)
Encoder-only 모델과 Decoder-only 모델의 차이를 이해하기 위해 두 가지 다른 과업을 상상해 보세요.
- Decoder-only (이야기꾼): 이야기를 한 줄씩 읽고 다음에 무슨 일이 일어날지 예측합니다. 미래를 보는 것은 “부정행위”가 되기 때문에 앞을 내다볼 수 없습니다. 그들은 오직 과거만 알고 있습니다.
- Encoder-only (탐정): 범죄 현장에 도착하여 모든 단서를 동시에 살펴봅니다. A 지점에서 무슨 일이 일어났는지 이해하기 위해 탐정은 B, C, D 지점을 살핍니다. 그들은 전체 그림을 이해하기 위해 Bidirectional (양방향) 시야가 필요합니다.
Encoder-only 모델은 탐정입니다. 그들은 전체 입력 시퀀스를 한 번에 처리하므로 모든 토큰이 다른 모든 토큰에 어텐션을 기울일 수 있습니다.
Bidirectional Attention: All-to-All Connectivity
Encoder-only 모델의 결정적인 특징은 Bidirectional Self-Attention 을 사용한다는 점입니다. 미래의 토큰을 마스킹하는 Causal Self-Attention (Decoder에서 사용)과 달리, Bidirectional Attention은 완전한 가시성을 제공합니다.
토큰 시퀀스가 주어지면 어텐션 행렬은 가득 차며, 마스킹이 적용되지 않습니다 (패딩 토큰 제외).
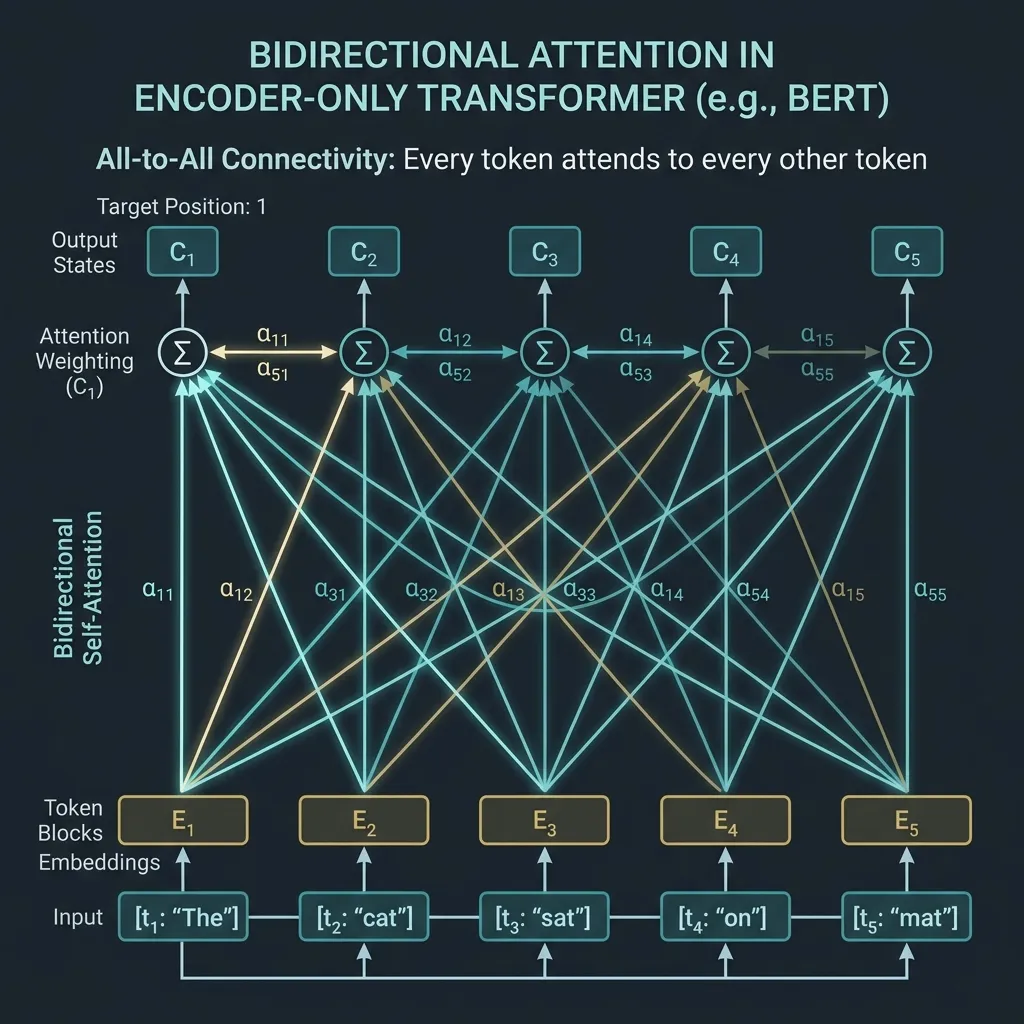
이러한 all-to-all 연결성은 Encoder-only 모델이 다음과 같이 문장의 모든 단어 간의 관계에 대한 깊은 이해가 필요한 과업에 탁월한 성능을 발휘하게 합니다.
- Sentiment Analysis (감성 분석)
- Named Entity Recognition (NER, 개체명 인식)
- Question Answering (추출형 질의응답)
- Text Classification (텍스트 분류)
Core Training Objective: Masked Language Modeling (MLM)
Encoder-only 모델은 전체 시퀀스를 보기 때문에, 단순히 다음 단어를 예측하는 방식(이것은 너무 쉽기 때문에)으로는 학습시킬 수 없습니다. 대신 BERT는 Masked Language Modeling (MLM) 을 도입했습니다.
MLM 작동 방식
- Masking: 입력 토큰의 특정 비율(일반적으로 15%)이 무작위로 선택됩니다.
- Replacement:
- 80%의 경우, 토큰은 특수
[MASK]토큰으로 교체됩니다. - 10%의 경우, 무작위 토큰으로 교체됩니다.
- 10%의 경우, 변경되지 않은 상태로 유지됩니다 (실제 관찰된 단어에 대한 표현을 편향시키기 위해).
- 80%의 경우, 토큰은 특수
- Prediction: 모델은 마스킹되지 않은 토큰이 제공하는 컨텍스트를 기반으로 마스킹된 위치의 원래 토큰을 예측하려고 시도합니다.
MLM의 수학적 정의
MLM의 손실 함수는 마스킹된 토큰의 음의 로그 가능도(negative log-likelihood)입니다. 을 마스킹된 인덱스의 집합이라 하고, 를 인덱스 의 원래 토큰이라 합니다. 모델은 각 마스킹된 위치에 대해 어휘(vocabulary)에 대한 확률 분포를 출력합니다: , 여기서 은 토큰이 마스킹된 시퀀스입니다.
MLM loss는 다음과 같이 정의됩니다.
이것은 모델이 빈칸을 채우기 위해 깊은 bidirectional 표현을 학습하도록 강제합니다.
Evolution and Key Models
0. The Precursor: ELMo and the Sesame Street Naming Trend
BERT를 다루기 전에, NLP 역사에서 중요한 이정표가 된 ELMo (Embeddings from Language Models)를 언급하지 않을 수 없습니다. 2018년 초에 발표된 ELMo는 단어의 고정된 벡터(Word2Vec 등) 대신, 문맥에 따라 단어의 의미가 변하는 ‘Contextualized Word Embeddings’의 개념을 대중화했습니다 [1]. ELMo는 비록 Transformer가 아닌 양방향 LSTM을 사용했지만, BERT가 탄생하는 데 결정적인 영감을 주었습니다.
💡 Behind the Scenes: 세서미 스트리트와 NLP의 언어유희 여기서 재미있는 비하인드 스토리가 있습니다. ELMo와 BERT는 모두 미국의 유명 어린이 프로그램인 세서미 스트리트(Sesame Street) 의 캐릭터 이름입니다.
- ELMo 는 빨간색 털 뭉치 캐릭터인 ‘엘모’에서 이름을 땄고,
- BERT 는 노란색 캐릭터인 ‘버트’에서 이름을 땄습니다.
ELMo 연구진이 논문 제목을 맞추기 위해 절묘하게 끼워 맞춘 약어(Embeddings from Language Models)를 만든 이후, Google 연구진이 이를 유쾌하게 이어받아 BERT (Bidirectional Encoder Representations from Transformers)라는 이름을 지으면서 NLP 학계의 거대한 ‘세서미 스트리트 세계관’이 시작되었습니다. 이후 바이두의 ERNIE, Google의 Big Bird 등 세서미 스트리트 캐릭터 이름을 딴 모델들이 줄을 이으며, AI 연구자들의 유쾌한 언어유희(Wordplay) 문화로 자리 잡았습니다.
1. BERT (2018)
Motivation: BERT 이전의 대부분의 언어 모델은 단방향(GPT-1과 같이)이거나 독립적인 좌우 및 우좌 모델의 얕은 결합(ELMo와 같이)을 사용했습니다. 이는 진정한 양방향 컨텍스트를 캡처하는 능력을 제한했으며, 이는 단어의 의미가 앞뒤 문맥 모두에 의존하는 질의응답이나 감성 분석과 같은 이해 과업에서 매우 중요합니다.
핵심 혁신 (Key Innovations):
- 깊은 양방향 표현 (Deep Bidirectional Representations): BERT는 최초로 깊은 양방향 Transformer 인코더를 사용하여 모든 토큰이 모든 레이어에서 다른 모든 토큰에 어텐션을 기울일 수 있도록 했습니다 [2].
- 마스크드 언어 모델링 (Masked Language Modeling, MLM): 15%의 토큰을 마스킹하여 양방향 모델에서의 자명한 예측 문제를 해결했습니다.
- 다음 문장 예측 (Next Sentence Prediction, NSP): 문장 B가 문장 A 뒤에 오는지 예측하는 이진 분류 과업으로, 모델이 문장 간의 관계를 이해하도록 돕습니다.
2. RoBERTa (2019)
Motivation: RoBERTa의 저자들은 오리지널 BERT 모델이 상당히 과소적합(undertrained)되었다는 가설을 세웠습니다. 그들은 핵심 설계를 변경하지 않고도 하이퍼파라미터를 신중하게 튜닝하고 데이터 크기를 늘림으로써 동일한 아키텍처로 훨씬 더 나은 결과를 얻을 수 있음을 보여주고자 했습니다.
핵심 혁신 (Key Innovations):
- 동적 마스킹 (Dynamic Masking): 데이터 전처리 중에 정적 마스크를 적용하는 대신, 시퀀스가 모델에 입력될 때마다 마스킹을 동적으로 적용하여 더 나은 일반화를 이끌어냈습니다 [3].
- NSP 제거: 긴 연속 시퀀스에 대해 학습할 때 NSP 과업이 필요하지 않으며 때로는 오히려 성능을 저하시킨다는 것을 발견했습니다.
- 더 큰 배치와 더 많은 데이터: 더 큰 배치 크기(최대 8k)와 160GB의 텍스트(BERT의 16GB 대비)로 학습하여 인코더에서도 컴퓨팅과 데이터 스케일이 여전히 중요함을 보여주었습니다.
3. ModernBERT (2024)
Motivation: 생성형 AI 붐(2022-2024년) 동안 Decoder-only 모델이 대부분의 연구 관심과 하드웨어 최적화를 받았습니다. 그러나 Encoder-only 모델은 검색(RAG) 및 분류와 같은 중요한 과업에서 여전히 핵심적인 역할을 하고 있습니다. ModernBERT는 LLM을 위해 개발된 아키텍처 개선 사항과 하드웨어 최적화를 통합하여 Encoder-only 모델을 현대화하기 위해 만들어졌습니다.
핵심 혁신 (Key Innovations):
- 긴 컨텍스트 지원 (Long Context Support): RoPE(Rotary Position Embeddings)를 사용하여 컨텍스트 윈도우를 BERT의 512토큰에서 8,192토큰으로 확장했습니다 [4].
- 하드웨어 효율성 (Hardware Efficiency): Flash Attention, GeGLU 활성화 함수, 그리고 적극적인 unpadding(처리 전 패딩 토큰 제거)을 통합하여 최신 GPU에서 최대 3배의 속도 향상을 달성했습니다.
- 부활한 아키텍처 (Revitalized Architecture): 비생성형 과업의 경우, 현대화된 인코더가 유사한 크기의 디코더보다 여전히 더 효율적임을 입증했습니다.
Encoder-only 모델 비교
| 특징 | BERT (Base) | RoBERTa (Base) | ModernBERT (Base) |
|---|---|---|---|
| 최대 컨텍스트 | 512 토큰 | 512 토큰 | 8,192 토큰 |
| 마스킹 | 정적 (Static) | 동적 (Dynamic) | 동적 (Dynamic) |
| NSP 과업 | 있음 | 없음 | 없음 |
| 위치 임베딩 | 절대적 (Absolute) | 절대적 (Absolute) | RoPE |
| 활성화 함수 | GELU | GELU | GeGLU |
| 효율성 | 표준 | 표준 | Flash Attention, Unpadding |
Why Encoder-Only Models Still Matter (왜 Encoder-only 모델이 여전히 쓰이는가)
Decoder-only 모델이 생성형 AI의 대세가 되었음에도 불구하고, BERT 계열의 Encoder-only 모델은 여전히 실무에서 널리 쓰이며 중요한 역할을 하고 있습니다. 그 이유는 다음과 같습니다.
1. Bidirectional Context is Superior for Understanding (이해를 위한 양방향 문맥의 우월성)
텍스트를 ‘생성’하는 것이 아니라 ‘이해’하는 것이 목표일 때, 미래의 토큰을 보지 못하게 막는 Causal Attention은 오히려 독이 될 수 있습니다.
- 문맥의 온전한 파악: “사과”라는 단어가 먹는 과일인지, 용서를 구하는 사과(Apology)인지는 뒤에 오는 문맥을 봐야만 정확히 알 수 있습니다. Encoder-only 모델은 모든 토큰이 서로를 참조할 수 있으므로, 이러한 동음이의어나 복잡한 문맥을 파악하는 데 훨씬 유리합니다.
- 분류 및 개체명 인식(NER): 텍스트의 감성을 분석하거나, 문서에서 핵심 정보를 추출하는 과업에서는 전체 텍스트를 한 번에 조망하는 양방향 어텐션이 더 높은 정확도를 보입니다.
2. Extreme Efficiency in Feature Extraction (특징 추출 및 임베딩의 압도적 효율성)
최근 각광받는 RAG (Retrieval-Augmented Generation) 시스템에서는 문서를 벡터로 변환하는 ‘임베딩(Embedding)’ 과정이 필수적입니다.
- Encoder-only 모델은 텍스트를 고차원 벡터로 압축하여 표현하는 데 최적화되어 있습니다.
- Decoder-only 모델로 임베딩을 추출하려면 미래 토큰을 보지 못하는 제약 때문에 비효율적인 프롬프팅이나 특수한 풀링(Pooling) 기법을 써야 합니다. 반면 Encoder-only 모델은 문장 전체의 의미를 담은
[CLS]토큰 등을 통해 훨씬 빠르고 정확한 임베딩을 제공합니다.
3. Cost-Effective Deployment (비용 효율적인 배포)
Decoder-only 모델은 수십억(Billion) 단위의 파라미터를 갖는 경우가 많아 서빙 비용이 매우 높습니다.
- 반면 BERT나 RoBERTa 같은 Encoder-only 모델은 대개 수억(Million) 단위의 파라미터로도 훌륭한 이해 성능을 냅니다.
- 분류, 검색, 매칭 등 생성이 필요 없는 작업에서는 굳이 거대한 디코더 모델을 쓸 필요 없이, 훨씬 작고 빠른 인코더 모델을 사용하여 인프라 비용을 수십 분의 일로 절감할 수 있습니다.
4. ModernBERT: The Renaissance of Encoders (모던BERT의 등장과 부활)
ModernBERT의 등장은 Encoder-only 모델도 LLM의 발전 혜택을 받을 수 있음을 보여주었습니다. 긴 컨텍스트 지원과 Flash Attention 적용으로, 이제 대규모 문서 검색 및 분석 작업에서 디코더 모델을 능가하는 속도와 효율성을 보여주고 있습니다.
PyTorch Implementation: MLM Head
다음은 Transformer Encoder 위에 있는 Masked Language Modeling head의 단순화된 구현입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MLMHead(nn.Module):
def __init__(self, hidden_size, vocab_size):
super().__init__()
self.dense = nn.Linear(hidden_size, hidden_size)
self.layer_norm = nn.LayerNorm(hidden_size)
self.decoder = nn.Linear(hidden_size, vocab_size, bias=False)
# Link bias to decoder
self.bias = nn.Parameter(torch.zeros(vocab_size))
self.decoder.bias = self.bias
def forward(self, hidden_states):
# hidden_states shape: (batch_size, seq_len, hidden_size)
x = self.dense(hidden_states)
x = F.gelu(x)
x = self.layer_norm(x)
# Project to vocab size
# logits shape: (batch_size, seq_len, vocab_size)
logits = self.decoder(x)
return logits
# Example usage
hidden_size = 768
vocab_size = 30522 # Standard BERT vocab size
seq_len = 10
batch_size = 2
# Simulated output from Transformer Encoder
hidden_states = torch.randn(batch_size, seq_len, hidden_size)
mlm_head = MLMHead(hidden_size, vocab_size)
logits = mlm_head(hidden_states)
print("Logits Shape:", logits.shape) # Expected: (2, 10, 30522)Quizzes
Quiz 1: Encoder-only 모델을 표준 Causal Language Modeling (다음 토큰 예측)을 사용하여 학습할 수 없는 이유는 무엇입니까?
Encoder-only 모델은 bidirectional attention을 사용하기 때문입니다. 정답을 포함한 전체 시퀀스를 보면서 다음 토큰을 예측하라고 하면, 과업이 너무 쉬워져서 모델이 아무것도 배우지 못할 것입니다. 그저 입력에서 정답을 복사하는 법만 배우게 됩니다.
Quiz 2: RoBERTa가 BERT에서 도입된 Next Sentence Prediction (NSP) 과업을 제거한 이유는 무엇입니까?
후속 연구에 따르면 NSP 과업은 원래 생각했던 것만큼 유익하지 않았으며, 때로는 오히려 성능을 저하시키는 것으로 나타났습니다. 이를 제거하고 더 긴 연속된 시퀀스에 대해 학습함으로써 모델이 더 나은 표현을 학습할 수 있었습니다.
Quiz 3: 오리지널 BERT 대비 ModernBERT의 주요 장점은 무엇입니까?
ModernBERT는 훨씬 더 긴 컨텍스트(최대 8k 토큰)를 지원하고 Flash Attention 및 GeGLU와 같은 현대적인 하드웨어 최적화를 통합하여 오리지널 BERT의 한계를 해결함으로써 현대적인 GPU에서 훨씬 더 빠르고 효율적입니다.
Quiz 4: MLM에서 선택된 토큰의 10%를 무작위 토큰으로 교체하고, 10%를 변경하지 않은 채로 두는 이유는 무엇입니까?
이는 pre-training과 fine-tuning 사이의 불일치를 줄이기 위해 수행됩니다. Fine-tuning 중에는 모델이 [MASK] 토큰을 전혀 보지 못합니다. 가끔 원래 단어를 유지하거나 무작위 단어를 사용함으로써, 모델은 단지 [MASK]를 볼 때만 예측하는 것이 아니라 모든 토큰에 대한 표현을 유지하는 법을 배웁니다.
Quiz 5: 어떤 종류의 과업에서 Encoder-only 모델보다 Decoder-only 모델이 선호됩니까?
Decoder-only 모델은 이야기 쓰기, 코드 생성 또는 대화 나누기와 같은 개방형 생성(open-ended generation) 과업에 선호됩니다. Encoder-only 모델은 분류, 추출 및 검색과 같이 전체 컨텍스트를 사용할 수 있는 이해 과업에 더 적합합니다.
References
- Peters, M. E., et al. (2018). Deep contextualized word representations. arXiv:1802.05365.
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805.
- Liu, Y., et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692.
- Answer.AI. (2024). ModernBERT: Going Beyond the Limits of Encoder-only Models. arXiv:2412.13663.