17.2 LLM-as-a-Judge
이전 장에서 우리는 MMLU 와 HumanEval 같은 학술 벤치마크를 살펴보았습니다. 이러한 정적인 데이터셋은 이산적인 논리와 팩트 리콜(Factual recall)을 테스트하는 데는 훌륭하지만, 현대 AI 시대에는 두 가지 치명적인 결함을 안고 있습니다. 첫째, 데이터 오염(Data contamination)에 매우 취약하며, 둘째, 인간 대화의 정성적인(Qualitative) 뉘앙스를 측정하는 데 완전히 실패한다는 점입니다.
모델의 어조가 “도움이 되지만 지나치게 공손하지는 않은지”를 어떻게 프로그래밍 방식으로 평가할 수 있을까요? 객관적인 정답이 없는 창의적인 글쓰기 프롬프트를 어떻게 채점할 수 있을까요? 참조 텍스트와의 N-gram 겹침을 측정하는 BLEU 나 ROUGE 와 같은 전통적인 NLP 지표들은 개방형(Open-ended) 생성 작업에서 쓸모없기로 악명이 높습니다.
이 문제를 해결하기 위해, 업계는 LLM-as-a-Judge (심판으로서의 LLM) 라는 패러다임으로 전환했습니다. 다른 모델의 출력을 평가하기 위해 프론티어 모델을 활용하면, 엔지니어들은 인간 평가자를 매번 대규모로 고용하지 않고도 정성 평가를 빠르게 반복할 수 있습니다. 다만 judge는 만능 채점기가 아닙니다. 좋은 judge 파이프라인은 “큰 모델에게 물어보기”가 아니라, 루브릭, 샘플링, 편향 점검, 인간 보정셋, 실패 분석이 결합된 평가 시스템입니다. 이번 섹션에서는 그 시스템을 어떻게 설계하는지에 초점을 맞춥니다.
1. 평가의 분류 체계 (The Taxonomy of Judgment)
LLM-as-a-Judge 패러다임에 대한 최근의 포괄적인 연구 [1] 에 따르면, 평가 작업은 일반적으로 세 가지 차원, 즉 무엇을 평가할 것인가 (What to judge) , 어떻게 평가할 것인가 (How to judge) , 그리고 어떻게 벤치마킹할 것인가 (How to benchmark) 로 구성됩니다.
1.1 무엇을 평가할 것인가 (출력 포맷)
엔지니어링 목표에 따라 심판 LLM 에게 다음 세 가지 유형 중 하나의 출력을 요구합니다.
- Scoring (Pointwise): 심판은 단일 응답을 독립적으로 평가하고 특정 루브릭(Rubric)에 따라 절대적인 점수(예: 1~10점)를 부여합니다. 단일 모델의 성능 저하를 추적하는 데 유용하지만, LLM 은 절대적인 영점 조절(Calibration)에 매우 취약합니다 (오늘의 “7점”이 내일은 “8점”이 될 수 있습니다).
- Ranking (Pairwise / Listwise): 심판에게 프롬프트와 두 개 이상의 경쟁 응답이 주어지며, 승자를 선언하거나 순위를 매겨야 합니다. 쌍대 비교(Pairwise) 평가는 업계 표준입니다. 인간과 마찬가지로 LLM 도 절대 평가보다 상대 평가를 훨씬 더 잘 수행하기 때문입니다.
- Selection: 심판이 풀(Pool)에서 최상의 응답을 선택합니다. 여러 작은 모델이 후보를 생성하고 더 큰 심판 모델이 최종 출력을 선택하는 라우팅(Routing) 아키텍처에서 자주 사용됩니다.
1.2 어떻게 평가할 것인가 (입력 컨텍스트)
- Reference-based: 심판에게 “골드 스탠다드(Gold standard)” 인간 답변이 제공됩니다. 심판의 임무는 단순히 후보 모델의 응답이 참조 답변의 팩트와 얼마나 잘 일치하는지 평가하는 것입니다.
- Reference-free: 심판은 후보의 응답이 사실적으로 정확하고, 안전하며, 도움이 되는지 판단하기 위해 전적으로 자신의 내부 세상 지식에 의존해야 합니다. 개방형 챗 모델을 평가할 때 가장 일반적인 설정입니다.
2. 쌍대 비교 심판 파이프라인 엔지니어링
LLM-as-a-Judge 시스템을 구축하는 것은 단순히 “어느 것이 더 낫습니까?” 라고 묻는 것만큼 간단하지 않습니다. LLM 은 프롬프트 포맷팅에 매우 민감하며, 품질과 관계없이 자신이 처음 읽은 응답(Model A)을 불균형적으로 선호하는 심각한 Position Bias (위치 편향) 를 보입니다.
견고한 파이프라인을 엔지니어링하기 위해, 우리는 반드시 Position Swapping (위치 교환) 을 구현해야 합니다. 심판에게 Model A 와 Model B 를 평가하도록 요청한 다음, 별도의 추론 패스(Inference pass)에서 Model B 와 Model A 를 평가하도록 요청합니다. 심판이 두 순열(Permutations) 모두에서 일관되게 한 모델을 선호할 때만 최종 승자를 선언합니다.
다음은 위치 편향을 완화하고 구조화된 JSON 출력을 강제하는 현실적인 PyTorch 및 Hugging Face transformers 기반의 쌍대 비교 심판 구현입니다.
import torch
import json
from transformers import AutoModelForCausalLM, AutoTokenizer
def pairwise_judge(
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
prompt: str,
response_1: str,
response_2: str,
device: str = "cuda"
) -> dict:
"""
위치 편향(Position bias)을 완화하기 위해 위치 교환(Position swapping)을 수행하는
쌍대 비교 LLM-as-a-Judge 평가를 실행합니다.
"""
# 시스템 프롬프트는 엄격한 루브릭과 JSON 출력을 강제합니다.
system_prompt = (
"You are an impartial expert judge evaluating AI models. "
"Evaluate which response better addresses the user's prompt based on helpfulness, "
"clarity, and accuracy. You must output a valid JSON object with two keys: "
"'reasoning' (a brief step-by-step explanation) and 'winner' (either 'Response A', "
"'Response B', or 'Tie')."
)
def get_verdict(res_a: str, res_b: str) -> str:
user_content = f"[User Prompt]\n{prompt}\n\n[Response A]\n{res_a}\n\n[Response B]\n{res_b}"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content}
]
inputs = tokenizer.apply_chat_template(
messages, return_tensors="pt", add_generation_prompt=True
).to(device)
with torch.no_grad():
outputs = model.generate(
inputs,
max_new_tokens=256,
temperature=0.0, # 결정론적 판단을 위한 Greedy decoding
pad_token_id=tokenizer.eos_token_id
)
# 새로 생성된 토큰만 추출합니다.
generated_ids = outputs[0, inputs.shape[1]:]
output_text = tokenizer.decode(generated_ids, skip_special_tokens=True)
try:
# 프로덕션 환경에서는 JSON 포맷을 보장하기 위해 제한적 디코딩(Constrained decoding,
# 예: Outlines 또는 Guidance)을 사용합니다. 여기서는 문자열을 파싱합니다.
return json.loads(output_text).get("winner", "Error")
except json.JSONDecodeError:
return "Error"
# 패스 1: Model 1 이 A, Model 2 가 B
verdict_forward = get_verdict(response_1, response_2)
# 패스 2: 위치 교환 (Model 2 가 A, Model 1 이 B)
verdict_backward = get_verdict(response_2, response_1)
# 최종 승자 결정
final_winner = "Tie"
if verdict_forward == "Response A" and verdict_backward == "Response B":
final_winner = "Model 1"
elif verdict_forward == "Response B" and verdict_backward == "Response A":
final_winner = "Model 2"
elif verdict_forward == verdict_backward:
final_winner = "Inconsistent (Position Bias Detected)"
return {
"forward_verdict": verdict_forward,
"backward_verdict": verdict_backward,
"final_winner": final_winner
}3. 최신 기술 (SOTA): 생각하는 심판 (Thinking Judges)
역사적으로 연구자들은 심판에게 표준적인 Chain-of-Thought (CoT) 프롬프팅(예: “결정하기 전에 단계별로 생각하세요”)을 사용하도록 강제했습니다. 그러나 표준 CoT 는 평가의 계획(Planning) 과 평가의 실행(Execution) 을 뒤섞어 버리기 때문에, 모델이 추론 도중 평가 기준을 환각(Hallucinate)하게 만드는 문제를 일으킵니다.
현재의 SOTA (State-of-the-Art) 접근법은 이러한 인지적 단계를 분리합니다. 2025년에 소개된 EvalPlanner 알고리즘 [2] 은 엄격한 3단계 파이프라인을 통해 심판을 “생각하는 LLM(Thinking LLM)” 으로 변환합니다.
- Unconstrained Planning (제약 없는 계획): 심판은 먼저 프롬프트에 특화된 맞춤형 루브릭을 작성합니다 (예: “1단계: Python 코드가 실행되는지 확인합니다. 2단계: 어조가 전문적인지 확인합니다. 3단계: 추가 라이브러리를 임포트하지 않았는지 확인합니다.”).
- Execution (실행): 심판은 후보 응답들을 상대로 자신이 세운 계획을 단계별로 실행합니다.
- Final Judgment (최종 판단): 오직 실행 추적(Execution trace) 결과에만 엄격하게 기반하여 최종 판결을 내립니다.
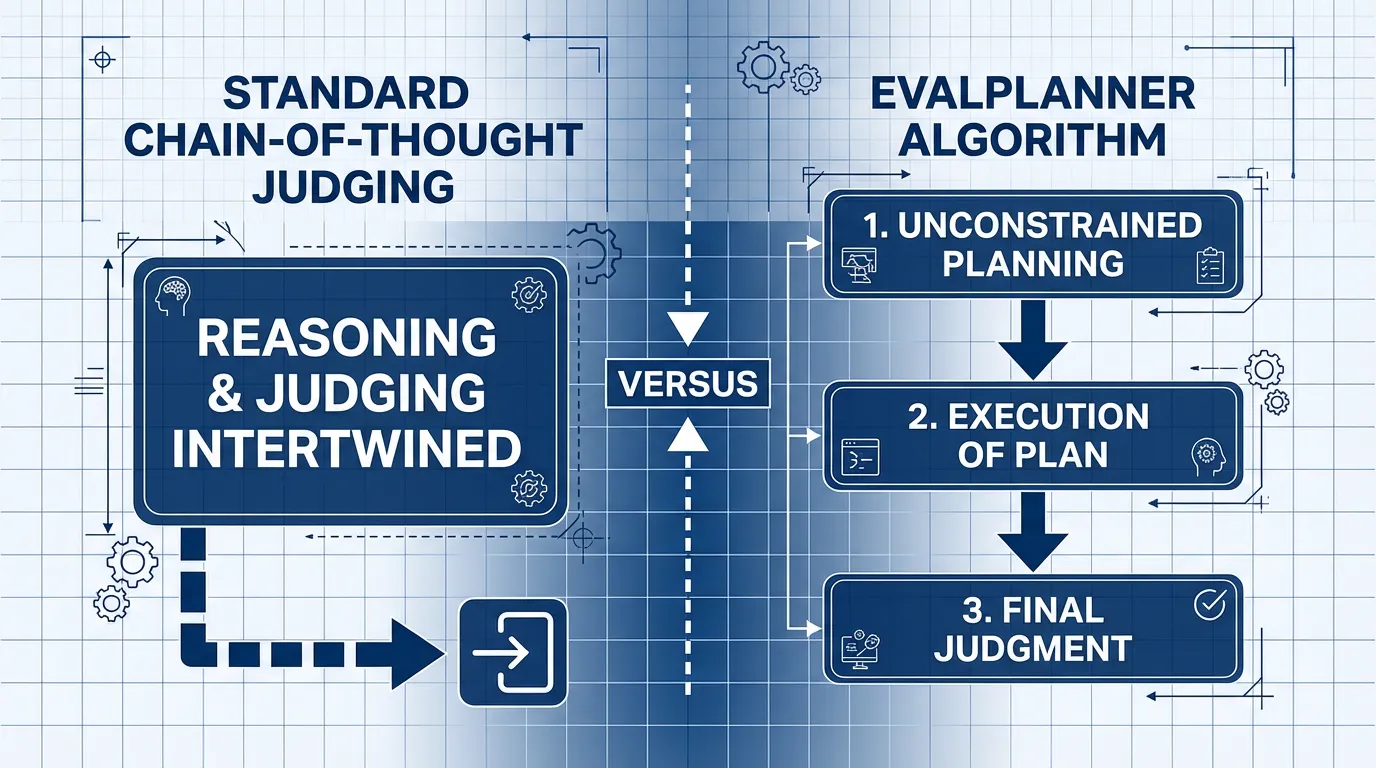 Source: Concept adapted from Saha et al., 2025 [2].
Source: Concept adapted from Saha et al., 2025 [2].
이러한 (계획 실행 판결) 트리플렛의 합성 선호도 쌍을 사용하여 모델을 최적화함으로써, 연구자들은 더 적은 양의 합성 데이터만으로도 RewardBench 에서 93.9 라는 SOTA 점수를 달성했습니다. 이는 심판이 자신의 생각을 어떻게 구조화하는지가 파라미터 크기만큼이나 중요하다는 것을 증명합니다.
4. 실전 가이드: 들쭉날쭉한 평가를 잡는 엔지니어링 (Practical Guide to Reliable Judgment)
LLM-as-a-Judge를 실무에 도입할 때 가장 큰 문제는 평가의 변동성(Variance) 과 극단적인 점수 부여(Extremism) 입니다. 동일한 프롬프트에 대해 모델이 어떤 때는 5점을, 어떤 때는 1점을 주거나, 대부분의 답변에 10점 아니면 1점을 주는 현상이 자주 발생합니다.
이러한 현상을 완화하고 신뢰성 높은 심판 시스템을 구축하기 위한 실전 전략과 예시를 소개합니다.
4.1 대표적인 Task별 구성 예시
| Task | 평가 방식 | 권장 구성 및 프롬프트 전략 |
|---|---|---|
| 문서 요약 (Summarization) | Pointwise (절대 평가) 또는 Reference-based | - 핵심 기준: 정보성(Informativeness), 정확성(Accuracy), 간결성(Conciseness). - 전략: 골드 데이터(참조 답변)를 제공하고, “참조 답변에 없는 내용이 포함되었는가?” 또는 “핵심 내용이 누락되었는가?”를 체크리스트 형태로 검증하게 합니다. |
| 챗봇 답변 유용성 (Helpfulness) | Pairwise (쌍대 비교) | - 핵심 기준: 사용자 의도 파악, 친절도, 해결책 제시. - 전략: 절대 점수 대신 두 답변 중 우위를 가리게 하되, 위치 편향(Position Bias)을 방지하기 위해 순서를 바꾸어 두 번 평가합니다. |
| 코드 리뷰 (Code Review) | Rubric-based Pointwise | - 핵심 기준: 동작 가능성, 효율성, 가독성, 보안. - 전략: 1~5점의 척도를 주되, 각 점수별 기준(예: 5점은 최적의 알고리즘이며 보안 결함이 없음)을 명확히 정의한 루브릭을 제공합니다. |
| RAG 답변 검증 | Reference-based + claim-level scoring | - 핵심 기준: 검색 문서에 근거가 있는가, 근거를 왜곡하지 않았는가, 답변하지 말아야 할 때 모른다고 말하는가. - 전략: 답변을 원자적 주장(atomic claims)으로 쪼개고, 각 주장마다 supporting passage ID를 요구합니다. judge는 “좋아 보이는 답변”이 아니라 “근거가 있는 주장”만 통과시켜야 합니다. |
| Tool-use / Agent workflow | Trace-level rubric + execution score | - 핵심 기준: 올바른 tool을 호출했는가, 인자를 정확히 채웠는가, 중간 오류를 복구했는가, 최종 상태가 맞는가. - 전략: 최종 답변만 judge하지 말고 action trace를 함께 평가합니다. 가능하면 tool 실행 결과로 objective score를 만들고, judge는 실패 원인 분류에 사용합니다. |
| 정책/컴플라이언스 답변 | Checklist-based binary gates | - 핵심 기준: 금지된 조언을 하지 않았는가, 필요한 disclaimer나 escalation을 포함했는가, 허용된 정보까지 과잉 거부하지 않았는가. - 전략: 1~10점보다 pass/fail/not_applicable 체크리스트가 낫습니다. 규정 준수 평가는 예쁜 문장보다 누락된 조건이 더 중요합니다. |
4.2 Judge prompt를 제품 명세처럼 작성하기
평가 프롬프트는 일반 프롬프트보다 더 보수적으로 작성해야 합니다. 특히 같은 평가를 몇 달 동안 반복할 수 있어야 하므로, judge prompt 자체가 작은 제품 명세서처럼 관리되어야 합니다.
좋은 judge prompt에는 보통 다음 요소가 들어갑니다.
- 평가 대상의 경계: “문체는 평가하지 말고 사실성만 평가하라”처럼 제외 기준을 명시합니다.
- 루브릭의 우선순위: 정확성이 문체보다 우선인지, 안전성이 유용성보다 우선인지 순서를 정합니다.
- 출력 스키마: JSON schema, enum 값, nullable field를 강제합니다. free-form 텍스트는 후처리 비용을 크게 만듭니다.
- 증거 요구: 특히 RAG에서는 judge가 각 판정마다 어떤 문서 조각을 근거로 삼았는지 쓰게 해야 합니다.
- 불확실성 처리: 판단이 어려운 경우 억지로 승자를 고르지 않고
tie,insufficient_evidence,needs_human_review를 허용합니다.
실무에서는 judge가 낸 자연어 이유를 그대로 믿기보다, 구조화된 필드를 우선 사용합니다. 이유 문장은 디버깅과 human review를 돕는 보조 산출물이고, 릴리스 게이트를 통과시키는 주 신호는 안정적으로 집계 가능한 필드여야 합니다.
4.3 들쭉날쭉한 평가와 극단적 점수 완화 전략 (Mitigating Inconsistency & Extremism)
최신 연구와 엔지니어링 사례에서 권장하는 변동성 줄이기 전략입니다.
-
세부 루브릭(Detailed Rubric) 제공 (G-Eval 방식 [4]) 단순히 “1~5점 사이로 채점하라”고 하면 모델은 주관적인 기준에 따라 극단적인 점수를 주기 쉽습니다. 대신 각 점수(1, 2, 3, 4, 5)가 의미하는 바를 텍스트로 명확히 정의해 주어야 합니다. 예시: “3점: 질문에 대한 답변은 포함되어 있으나, 설명이 다소 모호하거나 예시가 부족함.”
-
퓨샷(Few-Shot) 예시로 영점 조절 (Calibration) 프롬프트에 “좋은 답변(5점)의 예시와 이유”, “보통 답변(3점)의 예시와 이유”, “나쁜 답변(1점)의 예시와 이유”를 인컨텍스트(In-context)로 주입합니다. 이는 모델의 평가 기준을 사용자의 의도에 맞게 고정하는 강력한 닻(Anchor) 역할을 합니다.
-
다수결 및 앙상블 (Ensemble of Judges) 단일 심판의 변동성을 줄이기 위해 여러 심판의 의견을 모읍니다.
- 자가 앙상블: 동일한 모델에 온도를 약간 올리고(예:
temperature=0.7) 3~5회 반복 호출하여 평균을 내거나 다수결을 취합니다. - 이종 모델 앙상블: GPT-4와 Claude 등 서로 다른 아키텍처의 모델을 동시에 심판으로 활용하여 상호 보완합니다.
- 자가 앙상블: 동일한 모델에 온도를 약간 올리고(예:
-
소수점 점수(Float Scores) 허용 또는 확률값 활용 정수 점수(1, 2, 3…)만 허용하면 모델은 특정 점수로 몰리는 경향이 있습니다. 소수점 점수(예: 3.5)를 허용하거나, 토큰 확률값(Logprobs)을 사용하여 가중 평균 점수를 계산하면 더 세밀하고 안정적인 평가 분포를 얻을 수 있습니다.
4.4 운영 파이프라인에서의 권장 집계 방식
모델 릴리스 비교에서는 단일 judge verdict보다 계층적 집계 가 더 안전합니다.
- 각 샘플에서 position swap을 적용해 pairwise verdict를 얻습니다.
- 샘플별 결과를 task category별로 먼저 집계합니다. 예를 들어 “요약”, “코드 설명”, “RAG”, “안전 거부”를 섞어 평균내지 않습니다.
- 각 카테고리에서 bootstrap confidence interval을 계산합니다. 승률이 52%라도 신뢰구간이 48-56%라면 릴리스 근거로 약합니다.
- “전체 평균 승률”과 별개로 high-severity regression count를 봅니다. 평균은 좋아졌지만 의료/법률/결제 workflow에서만 나빠지는 모델은 릴리스하면 안 됩니다.
이런 집계 구조를 갖추면 LLM-as-a-Judge는 연구용 장난감이 아니라 실제 release gate의 한 축이 됩니다.
5. 어두운 이면: 편향과 선호도 누출
LLM-as-a-Judge 는 훌륭하게 확장되지만, 리더보드를 심각하게 왜곡할 수 있는 시스템적 편향을 도입합니다. 앞서 첫 번째 옵션을 선호하는 Position Bias 에 대해 논의했지만, 심판들은 추가된 텍스트가 쓸모없는 내용일지라도 “더 긴 응답”을 “더 나은 응답”으로 동일시하는 강한 경향인 Verbosity Bias (장황함 편향) 도 겪습니다.
그러나 최근 발견된 가장 교활한 위협은 Preference Leakage (선호도 누출) [3] 입니다.
업계가 “LLM-in-the-loop” 개발로 이동함에 따라, 프론티어 모델은 종종 더 작은 모델을 위한 합성 학습 데이터를 생성하는 데 사용되며, 그 후 바로 그 동일한 프론티어 모델이 작은 모델들을 평가하는 심판으로 사용됩니다. 이는 거대한 이해상충(Conflict of interest)을 발생시킵니다.
선호도 누출은 심판이 자신과 ‘관련된’ 모델에 대해 시스템적인 편향을 보이기 때문에 발생합니다. 이 관련성(Relatedness)은 세 가지 수준으로 분류됩니다.
- Same Model (동일 모델): 모델이 자신의 출력을 스스로 평가하면 점수가 인위적으로 부풀려집니다.
- Inheritance (상속): 거대한 교사 모델(예: GPT-4)은 자신으로부터 증류(Distill)된 작은 학생 모델(예: GPT-4o-mini)의 출력을 본질적으로 선호합니다. 학생이 교사의 잠재적인 “사고 패턴”과 어휘 분포를 모방하기 때문입니다.
- Family (제품군): 동일한 조직에서 동일한 기반 데이터셋으로 학습된 모델들(예: Llama 2 를 평가하는 Llama 3)은 서로에 대해 정당하지 않은 편애를 보입니다.
관련된 모델들은 유사한 잠재 표현(Latent representations)을 공유하기 때문에, 심판은 관련 후보의 출력을 더 “자연스럽거나” “정확하다”고 느끼게 되며, 이는 순환 참조적 검증이라는 에코 체임버(Echo chamber)로 이어집니다.
인터랙티브 시각화: Judge Bias Simulator
이러한 편향들이 벤치마크 결과를 얼마나 극적으로 왜곡하는지 이해하려면 아래 시뮬레이터를 사용해 보십시오. 두 경쟁 모델의 실제 근본적인 품질을 설정한 다음, 다양한 편향을 토글하여 LLM 심판의 최종 판결이 현실에서 어떻게 왜곡되는지 확인하십시오.
LLM Judge Bias Simulator
See how specific biases alter the judge's perception of reality.
1. Set True Quality
2. Inject Biases (Favoring Model A)
Judge's Perceived Score
6. 평가자를 평가하기
만약 우리가 다른 LLM 을 판단하기 위해 LLM 을 사용한다면, 그 심판 자체는 어떻게 평가해야 할까요? 심판의 신뢰성은 일반적으로 세 가지 지표를 사용하여 정량화됩니다.
- Consistency (일관성): 응답의 순서를 바꾸거나(Position Swap), 프롬프트를 약간 다른 말로 바꾸어 표현해도 심판이 동일한 판결을 내리는가?
- Robustness (견고성): 후보 모델이 장황함 편향(Verbosity Bias)을 유발하기 위해 의도적으로 관련 없는 텍스트로 답변을 부풀리는 등 적대적인 섭동(Adversarial perturbations)에 저항할 수 있는가?
- Human Alignment (인간 정렬): 궁극적인 지표입니다. LLM 심판이 전문가 인간 평가자들의 합의와 얼마나 자주 일치하는지를 측정합니다.
인간 정렬은 종종 코헨의 카파 (Cohen’s Kappa, ) 를 사용하여 계산됩니다. 이는 심판과 인간이 순전히 우연에 의해 일치할 가능성을 고려한 통계적 척도입니다.
여기서:
- 는 평가자들 간의 상대적인 관측 일치도입니다 (예: 심판과 인간이 85% 의 확률로 일치함).
- 는 우연에 의한 가상의 일치 확률입니다.
- 점수가 이상이면 일반적으로 매우 우수한 정렬로 간주됩니다.
실무에서는 하나만 보지 말고 아래 지표를 같이 봅니다.
- pairwise agreement: judge와 인간이 같은 승자를 고른 비율입니다. 가장 이해하기 쉽지만, 무승부 비율이 높으면 해석이 흐려집니다.
- category-wise agreement: 전체 평균은 좋아도 특정 카테고리에서 틀릴 수 있습니다. 예를 들어 judge가 일반 글쓰기는 잘 보지만 코드 보안 취약점은 놓칠 수 있습니다.
- calibration curve: judge가 0.9 확신으로 낸 판정이 실제로 90% 맞는지 봅니다. 확신 점수는 ranking보다 훨씬 자주 calibration이 깨집니다.
- adversarial robustness: 장황한 답변, 과도한 인용, 권위 있는 말투, 모델 이름 노출 같은 교란에 판정이 흔들리는지 봅니다.
가장 좋은 운영 관행은 “judge를 신뢰한다”가 아니라 “judge가 언제 틀리는지 알고 쓴다”에 가깝습니다.
7. 미해결 과제와 다음 장으로의 연결
LLM-as-a-Judge 는 생성형 AI 의 평가를 민주화하여, 오픈소스 연구자들이 수천 명의 인간 평가자를 보유한 거대 기업들만 가능했던 규모로 모델을 평가할 수 있게 해주었습니다. 그러나 선호도 누출(Preference Leakage)의 발견은 우리가 공정한 심판 역할을 할 단 하나의 “신적 모델(God Model)“에 의존할 수 없음을 경고합니다.
개별 심판들이 편향되어 있다면, 수백 개의 서로 다른 모델과 수천 명의 인간 사용자의 의견을 어떻게 단일하고 신뢰할 수 있는 리더보드로 통합할 수 있을까요? 다음 섹션인 17.3 Elo Rating & Leaderboards 에서는 LMSYS Chatbot Arena 의 이면에 있는 수학과, 체스 랭킹 시스템이 어떻게 인공지능에서 가장 신뢰받는 지표가 되었는지 탐구할 것입니다.
Quizzes
Quiz 1: LLM 을 심판으로 사용할 때 “Pointwise Scoring (절대 평가)” 보다 “Pairwise Ranking (쌍대 비교)” 이 일반적으로 선호되는 이유는 무엇입니까?
LLM 은 절대적인 영점 조절(Calibration)에 어려움을 겪습니다. “8/10” 이라는 점수는 시스템 프롬프트, 온도(Temperature), 또는 특정 모델 버전에 따라 다른 의미를 가질 수 있어, 서로 다른 평가 실행 간에 점수를 비교하기 어렵게 만듭니다. 반면 쌍대 비교(A vs B)는 상대적인 비교에 의존하며, LLM 은 이를 훨씬 더 신뢰할 수 있게 처리합니다. 이는 완벽하게 객관적인 숫자 등급을 매기는 것보다 “이것이 저것보다 낫다”고 말하는 것이 더 쉬운 인간의 심리를 반영합니다.
Quiz 2: 만약 LLM 심판이 Model A 와 Model B 를 평가하여 Model A 를 선택했지만, 위치를 교환하여(B vs A) 평가했을 때 Model B 를 선택한다면, 어떤 특정 편향이 발생한 것이며 표준적인 엔지니어링 해결책은 무엇입니까?
심판은 실제 품질과 관계없이 프롬프트 컨텍스트에 처음 제시된 응답을 선호하는 Position Bias (위치 편향) 를 보이고 있습니다. 표준적인 엔지니어링 해결책은 결과를 “무승부(Tie)” 또는 “일관성 없음(Inconsistent)” 으로 선언하고 최종 승률 계산에서 제외하여, 견고한 선호도만이 집계되도록 보장하는 것입니다.
Quiz 3: EvalPlanner 알고리즘은 LLM 심판을 위한 표준 Chain-of-Thought (CoT) 프롬프팅을 어떻게 개선합니까?
표준 CoT 는 평가 기준을 공식화하는 과정과 텍스트의 실제 평가 과정을 뒤섞어 모델의 논리가 표류하게 만들 수 있습니다. EvalPlanner 는 이 과정을 세 가지 명확한 단계로 엄격하게 분리합니다: 제약 없는 계획 (프롬프트에 대한 특정 루브릭 작성), 실행 (루브릭을 단계별로 적용), 그리고 최종 판단 (실행 추적 결과에만 전적으로 기반하여 판결 내리기). 이러한 전략과 분석의 분리는 추론의 견고성을 크게 향상시킵니다.
Quiz 4: 한 스타트업이 GPT-4o 의 출력을 증류(Distill)하여 8B 파라미터의 작은 모델을 학습시켰습니다. 그런 다음 GPT-4o 를 자동화된 심판으로 사용하여 자신들의 새로운 8B 모델과 오픈소스 Llama-3-8B 모델을 비교했습니다. GPT-4o 는 압도적으로 스타트업의 모델을 승자로 선언했습니다. 이 결과를 왜 엄격하게 검증해야 합니까?
이는 “상속(Inheritance)” 을 통한 Preference Leakage (선호도 누출) 의 전형적인 사례입니다. 스타트업의 모델은 GPT-4o 의 데이터로 학습되었기 때문에, GPT-4o 의 특정 어휘, 어조, 그리고 포맷팅 선호도를 모방하는 법을 배웠습니다. GPT-4o 가 심판 역할을 할 때, 자신과 가장 비슷하게 들리는 모델을 본질적으로 편애하게 되며, 이는 Llama 3 와 같은 독립적인 모델에 비해 증류된 모델의 점수를 인위적으로 부풀리게 됩니다.
Quiz 5: LLM이 쌍대 비교 심판으로 작동할 때, 소프트 로짓(Soft-logits) 내부의 명시적 위치 편향 매개변수를 정식화하십시오. 단일 추론 패스에서 이 편향을 교정하기 위한 명시적 수학 방정식을 제공하시오.
위치 편향은 B에 대한 A의 소프트 로짓 시퀀스에서 컨텍스트 편향 매개변수 를 분리하여 모델링됩니다: . 여기서 는 연속적인 품질 벡터이고 은 첫 번째 위치에 대한 우선순위를 나타냅니다. 교차 위치 쌍대 추론 오버헤드 없이 단일 패스에서 이를 중화하기 위해 엔지니어들은 로짓 교정 시퀀스 방정식을 통해 경계를 설정합니다: . 제어 데이터셋을 통해 를 오프라인으로 영점 조절하면 토큰 계산량을 로 늘리지 않고도 결정론적으로 위치 우선 편향을 중화할 수 있습니다.
References
- Li, D., et al. (2024). From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge. arXiv:2411.16594.
- Saha, S., et al. (2025). Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge. arXiv:2501.18099.
- Li, D., et al. (2025). Preference Leakage: A Contamination Problem in LLM-as-a-judge. arXiv:2502.01534.
- Liu, Y., et al. (2023). G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. arXiv:2303.16634.