10.2 PPO (Proximal Policy Optimization)
10.1절에서 우리는 궤적(Trajectory)을 생성, 필터링 및 검증하는 비동기식 인프라인 ‘피드백-데이터 팩토리(Feedback-Data Factory)‘를 구축했습니다. 하지만 고품질의 선호도 데이터를 수집하는 것은 정렬(Alignment)을 위한 전제 조건일 뿐입니다. 모델의 행동을 근본적으로 변화시키려면, 이렇게 검증된 궤적을 물리적인 가중치 업데이트로 변환해야 합니다.
역사적으로 강화 학습(RL, Reinforcement Learning)을 심층 신경망에 적용하는 것은 극도로 불안정한 과정이었습니다. 단 한 번의 공격적인 가중치 업데이트만으로도 모델이 사전 학습된 문법을 잊어버리고 의미 없는 텍스트를 생성하는 정책 붕괴 (Policy collapse) 가 발생할 수 있습니다. PPO (Proximal Policy Optimization) 는 바로 이러한 안정성 문제를 해결하기 위해 도입되었습니다.
전통적인 PPO가 2017년 이후 정렬 기술의 핵심 엔진으로 자리 잡았지만, 최신 파운데이션 모델의 방대한 규모는 기존 PPO의 수학적 한계를 드러냈습니다. 2024년과 2025년에 등장한 최신 연구들은 PPO를 근본적으로 해체하여, 경직된 단일 알고리즘에서 모듈화된 그래디언트 추정(Gradient-estimation) 프레임워크로 진화시켰습니다.
1. 신뢰 영역(Trust Region)과 클리핑(Clipping) 메커니즘
현대의 PPO를 이해하려면 먼저 이 알고리즘이 원래 해결하고자 했던 수학적 병목 현상을 살펴봐야 합니다. 정책 를 업데이트할 때, 우리의 목표는 기대 보상을 극대화하는 것입니다. 그러나 새로운 정책이 이전 정책 에서 너무 멀리 벗어나면, 어드밴티지(Advantage) 를 추정하는 데 사용된 수학적 가정이 무너집니다.
TRPO (Trust Region Policy Optimization) 는 이전 정책과 새로운 정책 간의 쿨백-라이블러 발산(KL Divergence)을 엄격하게 제한하여 이 문제를 해결했습니다. 하지만 이는 수십억 개의 파라미터를 가진 LLM에서는 연산 비용이 감당할 수 없을 정도로 높은 2차 미분(피셔 정보 행렬, Fisher Information Matrix) 계산을 요구했습니다.
PPO [1] 는 연산 비용이 저렴한 1차 근사 방식인 클리핑 메커니즘 을 사용하여 이 신뢰 영역(Trust Region)을 근사합니다. 이 방식은 확률 비율(Probability ratio) 에 의존합니다:
PPO는 복잡한 KL 페널티 대신, 다음과 같은 비관적 대리 목적 함수(Pessimistic surrogate objective)를 최적화합니다:
클리핑되지 않은 값과 클리핑된 값 중 최솟값을 취함으로써, PPO는 목적 함수가 무한정 커지는 것을 방지합니다. 만약 특정 행동이 긍정적인 어드밴티지()를 산출하더라도, 이 되는 순간 목적 함수의 증가는 멈춥니다. 즉, 그래디언트가 0이 되어 단일한 ‘운 좋은’ 궤적에 정책이 과도하게 업데이트되는 것을 막아줍니다.
인터랙티브 시각화: PPO 대리 목적 함수
아래의 시각화 도구를 사용하여 클리핑 메커니즘이 긍정적 및 부정적 어드밴티지에 어떻게 반응하는지 탐색해 보십시오. 일 때, 함수는 오직 일 때만 클리핑됩니다. 가 1보다 클 때는 클리핑되지 않는데 , 나쁜 행동의 확률을 낮추는 것은 그래디언트가 정확히 수행해야 할 역할이기 때문입니다.
Positive Advantage: The action was better than expected. Objective is clipped when r_t > 1.2 to prevent over-updating.
2. 2024년의 패러다임 전환: 구조적 분해 (Outer-PPO)
수년 동안 RL 커뮤니티는 PPO 업데이트를 단일한 원자적 연산으로 취급했습니다. 을 계산하고, .backward() 를 호출한 다음, Adam 최적화기의 스텝을 밟는 방식이었습니다.
하지만 최근 연구(Tan et al., 2024) [2] 는 이러한 모놀리식(Monolithic) 접근 방식의 치명적인 결함을 밝혀냈습니다. 표준 PPO 구현은 실제 정책 스텝에서 1.0의 학습률(Unity learning rate) 과 모멘텀(Momentum) 0을 암묵적으로 강제합니다. 연구진은 PPO를 두 개의 고유한 루프로 분해할 것을 제안했습니다:
- 내부 루프 (추정, Estimation): 표준 PPO의 클리핑된 목적 함수를 데이터 배치에 대해 반복적으로 최적화하여 최적의 “업데이트 벡터”(유사 그래디언트, Pseudo-gradient)를 추정합니다.
- 외부 루프 (적용, Application): 이렇게 추정된 업데이트 벡터를 임의의 최적화기(예: AdamW 또는 모멘텀이 있는 SGD)를 사용하여 실제 모델 가중치에 적용합니다.
추정(Estimation)과 적용(Application)을 분리함으로써, 엔지니어는 외부 루프에 1.0이 아닌 학습률과 모멘텀을 적용할 수 있게 되었습니다. 이러한 “Outer-PPO” 프레임워크는 핵심 대리 목적 함수를 변경하지 않고도, 특히 고차원 연속 제어 및 복잡한 추론 태스크에서 샘플 효율성과 학습 안정성을 통계적으로 유의미하게 향상시킵니다.
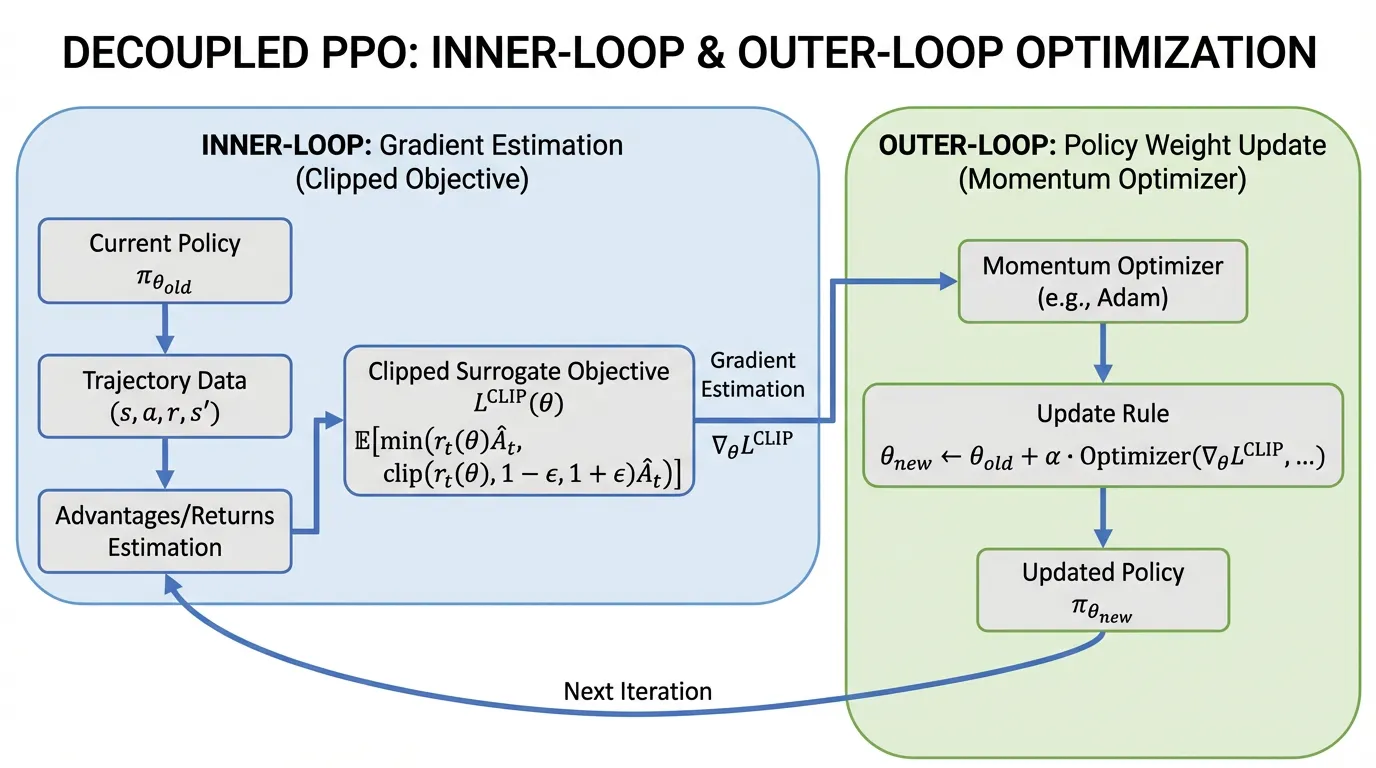 Source: Generated by Gemini. (그래디언트 추정과 가중치 적용을 분리한 Outer-PPO의 디커플링 아키텍처).
Source: Generated by Gemini. (그래디언트 추정과 가중치 적용을 분리한 Outer-PPO의 디커플링 아키텍처).
엔지니어링: 디커플링된 업데이트 구현
다음 PyTorch 구현은 이 디커플링된 업데이트를 어떻게 구조화하는지 보여줍니다. 내부 루프가 복제된 정책(Cloned policy)에서 작동하여 업데이트 벡터를 추정한 다음, 이를 외부 최적화기로 전달하는 방식에 주목하십시오.
import torch
import torch.nn as nn
import torch.optim as optim
def outer_ppo_step(
policy: nn.Module,
old_policy: nn.Module,
states: torch.Tensor,
actions: torch.Tensor,
advantages: torch.Tensor,
outer_optimizer: optim.Optimizer,
clip_epsilon: float = 0.2,
inner_epochs: int = 4
):
"""
Decoupled 'Outer-PPO' 업데이트(Tan et al., 2024)의 구현 예시입니다.
Shapes: states (B, SeqLen, Dim), actions (B, SeqLen), advantages (B, SeqLen)
"""
# 1. 내부 루프 (Inner Loop): 업데이트 벡터 추정
# '내부' 탐색 지점 역할을 할 정책을 복제합니다.
inner_policy = type(policy)(policy.config)
inner_policy.load_state_dict(policy.state_dict())
# 순수 추정을 위해 내부 최적화기는 모멘텀 없이 학습률 1.0을 사용합니다.
inner_optimizer = optim.SGD(inner_policy.parameters(), lr=1.0)
for _ in range(inner_epochs):
inner_optimizer.zero_grad()
# 확률 비율 r_t(theta) 계산
current_logits = inner_policy(states).logits
old_logits = old_policy(states).logits.detach()
current_dist = torch.distributions.Categorical(logits=current_logits)
old_dist = torch.distributions.Categorical(logits=old_logits)
log_probs = current_dist.log_prob(actions)
old_log_probs = old_dist.log_prob(actions)
ratio = torch.exp(log_probs - old_log_probs)
# 클리핑된 대리 목적 함수(Surrogate objective) 계산
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - clip_epsilon, 1.0 + clip_epsilon) * advantages
# 목적 함수 극대화 -> 음의 목적 함수 극소화
loss = -torch.min(surr1, surr2).mean()
loss.backward()
inner_optimizer.step()
# 2. 외부 루프 (Outer Loop): 추정된 업데이트 벡터를 실제 정책에 적용
outer_optimizer.zero_grad()
# 외부 최적화기를 위한 유사 그래디언트(Pseudo-gradient) 계산
with torch.no_grad():
for param, inner_param in zip(policy.parameters(), inner_policy.parameters()):
# pseudo-gradient = current_weight - optimized_inner_weight
param.grad = param.data - inner_param.data
# 외부 최적화기를 사용하여 업데이트 적용 (예: 튜닝된 LR/모멘텀을 가진 AdamW)
outer_optimizer.step()
# 다음 롤아웃 페이즈를 위해 이전 정책(old_policy) 동기화
old_policy.load_state_dict(policy.state_dict())3. 샘플 비효율성 극복: HP3O (Hybrid-Policy PPO)
표준 PPO의 근본적인 단점은 엄격하게 On-policy 로 작동한다는 것입니다. 한 배치의 궤적이 업데이트에 사용되면 즉시 폐기됩니다. 대규모 LLM 정렬에서, 비싸고 검증된 궤적을 단 한 번의 업데이트 후에 버리는 것은 매우 비효율적입니다.
그렇다고 해서 단순히 오래된 궤적(Off-policy 데이터)을 주입하면 신뢰 영역(Trust region)의 수학적 경계가 무너져 높은 분산과 분포 이동(Distribution drift)이 발생합니다.
이러한 격차를 해소하기 위해 HP3O (Hybrid-Policy Proximal Policy Optimization) [3] 와 같은 최근의 발전은 궤적 인지 리플레이(Trajectory-aware Replay) 메커니즘을 도입했습니다. HP3O는 엄격한 FIFO (First-In, First-Out) 궤적 리플레이 버퍼를 활용합니다. 업데이트 단계에서 알고리즘은 다음과 같이 구성된 하이브리드 배치를 샘플링합니다:
- 최근 기록 중 가장 성능이 좋았던 궤적 (Best-performing trajectory).
- FIFO 버퍼에서 무작위로 선택된 최근 궤적들.
업데이트를 가장 최근의 “성공” 사례에 고정시키는 동시에 FIFO를 통해 버퍼의 연한(Age)을 엄격하게 제한함으로써, HP3O는 데이터 분포 이동을 완화합니다. 이는 경험적으로 그래디언트 추정기의 분산을 줄이고, 복잡한 추론 행동을 정렬하는 데 필요한 샘플 복잡성(Sample complexity)을 크게 낮춥니다.
클래식 PPO vs 최신 SOTA PPO 비교
| 특징 | Classic PPO (2017) | Modern SOTA (2024-2025) |
|---|---|---|
| 업데이트 로직 | 대리 손실에 대한 단일 스텝 그래디언트 상승. | 디커플링된 내부(추정) 및 외부(적용) 루프. |
| 외부 최적화기 | 암묵적인 학습률 1.0, 모멘텀 없음. | 명시적으로 튜닝된 LR 및 모멘텀 활용 (예: AdamW/Nesterov). |
| 데이터 사용 | 순수 On-policy; 사용 후 궤적 폐기. | 하이브리드 Off/On-policy 학습을 위한 궤적 인지 FIFO 버퍼 (HP3O). |
| 안정성 확보 | 순수하게 클리핑 메커니즘에 의해 제한됨. | 클리핑 + 외부 루프 모멘텀 + 궤적 최신성(Recency)에 의해 제한됨. |
요약 및 다음 단계
PPO (Proximal Policy Optimization) 는 더 이상 단순하고 정적인 알고리즘이 아닙니다; 이는 안정적인 그래디언트 추정을 위한 프레임워크입니다. 내부 추정 루프를 외부 적용 루프에서 분리하고(Outer-PPO), 궤적 인지 리플레이 버퍼(HP3O)를 활용함으로써 엔지니어는 정책 붕괴에 빠지지 않고 비동기식 피드백-데이터 팩토리에서 최대의 가치를 추출할 수 있습니다.
그러나 PPO는 여전히 여러 모델(정책, 참조, 보상 및 가치 모델)을 메모리에 유지해야 하므로 메모리 부하가 극도로 높습니다. 다음 섹션인 10.3 DPO (Direct Preference Optimization) 에서는 보상 모델과 RL 루프를 완전히 우회하여, 지도 학습(Supervised learning) 손실에 대해 직접 선호도를 최적화하는 수학적 혁신을 탐구해 보겠습니다.
Quizzes
Quiz 1: PPO가 TRPO처럼 하드(Hard)한 KL-발산 제약 조건을 사용하지 않고 확률 비율 를 클리핑하는 이유는 무엇입니까?
이전 정책과 새로운 정책 간의 KL-발산 제약 조건을 강제하려면 2차 미분(피셔 정보 행렬)을 계산해야 하는데, 이는 대규모 신경망에서는 연산 비용이 너무 높아 불가능에 가깝습니다. 클리핑은 연산 비용을 저렴하게 유지하면서도 대규모 정책 이동을 방지하는 1차 근사치를 제공합니다.
Quiz 2: “Outer-PPO” 프레임워크에서 노출되고 튜닝되는 표준 PPO의 암묵적인 하이퍼파라미터는 무엇입니까?
표준 PPO는 추정된 업데이트 벡터를 외부 루프 학습률 1.0 및 모멘텀 0으로 암묵적으로 적용합니다. Outer-PPO는 이를 노출시켜, 엔지니어가 업데이트의 ‘적용’ 단계에 튜닝된 학습률과 모멘텀을 가진 표준 최적화기를 사용할 수 있게 해줍니다.
Quiz 3: 만약 어떤 행동이 부정적인 어드밴티지()를 산출하고 확률 비율 가 1.5라면, PPO 목적 함수는 그래디언트를 클리핑합니까?
아니요. 어드밴티지가 음수라면 우리는 해당 행동의 확률을 낮추기를 원합니다. 가 1.5라는 것은 정책이 실제로 이 나쁜 행동의 확률을 증가시켰음을 의미합니다. 클리핑 함수 는 클리핑되지 않은 로 평가되어, 그래디언트가 확률을 다시 공격적으로 낮출 수 있도록 허용합니다.
Quiz 4: HP3O가 DQN 스타일의 우선순위 경험 리플레이(PER, Prioritized Experience Replay) 대신 엄격한 FIFO 버퍼를 사용하는 이유는 무엇입니까?
PPO는 근접(Proximal, 신뢰 영역) 업데이트에 의존합니다. PER은 데이터 분포를 오차가 큰 트랜지션으로 심하게 편향시키며, 이는 On-policy 가정을 공격적으로 깨뜨리고 엄청난 분포 이동을 유발합니다. FIFO 버퍼는 최신성(Recency)을 보장하여 데이터의 “근접성”을 유지하면서도 샘플 효율성을 향상시킵니다.
References
- Schulman, J., et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
- Tan, C. B., et al. (2024). Beyond the Boundaries of Proximal Policy Optimization. arXiv:2411.00632.
- Liu, Q., et al. (2025). Enhancing PPO with Trajectory-Aware Hybrid Policies. arXiv:2502.15579.