19.2 Logit Lens & Attention Visualization
이전 장에서는 Transformer 를 여러 회로(Circuits)와 Induction Head 로 분해하여, 토큰 간에 정보가 기계적으로 어떻게 라우팅되는지 분석했습니다. 하지만 회로를 식별하는 것은 연산의 메커니즘을 알려줄 뿐, 모델이 처리 과정의 특정 시점에서 실제로 무엇을 믿고 있는지(Belief) 를 알려주지는 않습니다.
만약 24개의 레이어로 구성된 거대 언어 모델(LLM)을 12번째 레이어에서 일시 정지시킨다면, 모델은 무슨 생각을 하고 있을까요? 이미 다음 단어를 알아냈을까요, 아니면 마지막 레이어에 도달해서야 비로소 깨달음을 얻게 될까요?
이러한 질문에 답하기 위해, 우리는 가중치(Weights) 를 관찰하는 것에서 활성화 값(Activations) 을 관찰하는 것으로 시각을 전환해야 합니다. Logit Lens 와 Attention Visualization 같은 기법을 활용하면, 연속적이고 고차원적인 Residual Stream 내부를 들여다보고 모델의 낯선 내부 상태를 인간이 읽을 수 있는 개념으로 번역할 수 있습니다.
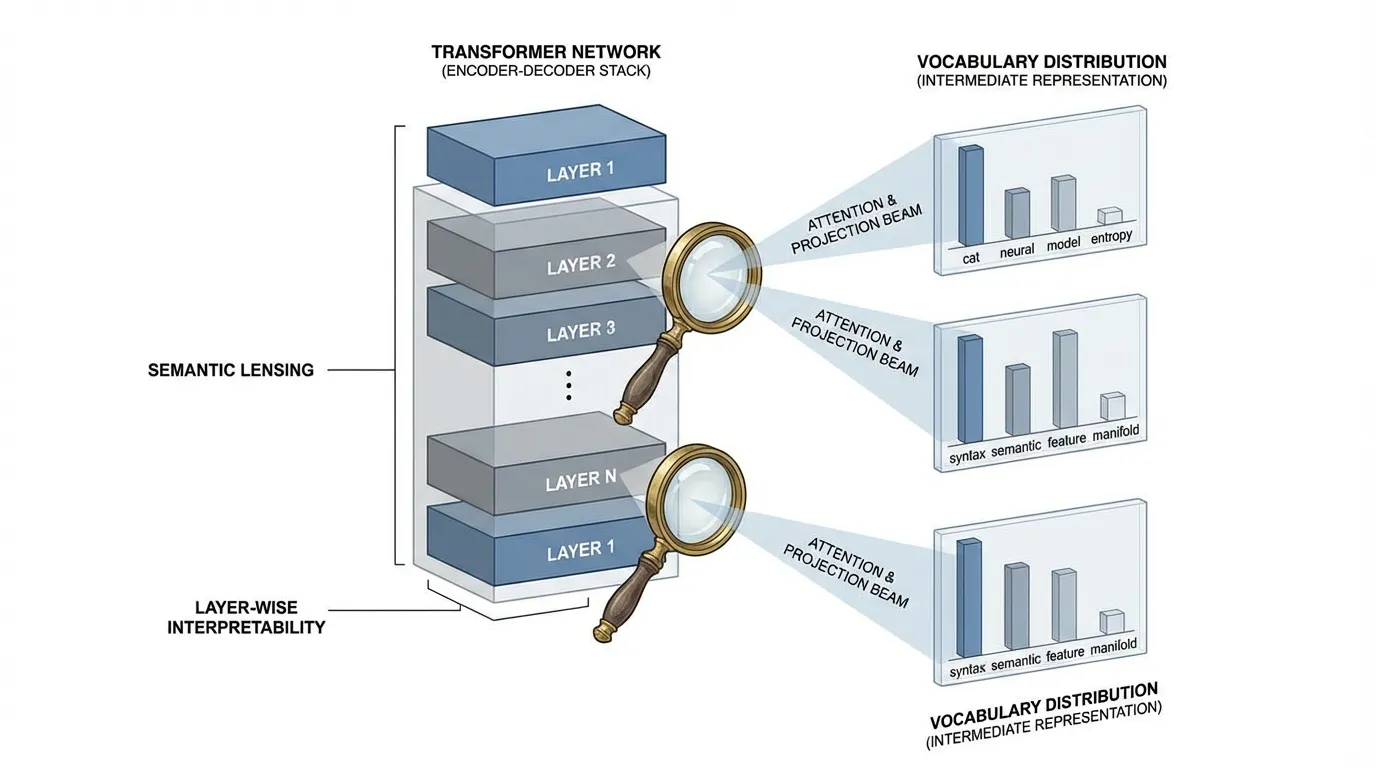
1. The Logit Lens: Reading the Residual Stream
표준 Decoder-only Transformer 에서 최종 예측은 아주 단순한 과정을 거칩니다. 가장 마지막 레이어의 Residual Stream () 을 가져와 최종 Layer Normalization 을 적용한 뒤, Unembedding 행렬 () 을 통해 투영(Projection)하여 전체 어휘(Vocabulary)에 대한 확률 분포를 얻습니다.
2020년, nostalgebraist 라는 이름으로 활동하는 독립 AI 정렬(Alignment) 연구자는 급진적일 만큼 단순한 아이디어를 제안했습니다 [1]. Residual Stream 이 정보가 덧셈 형태로 누적되는 중앙 통신 채널 역할을 한다면, 이 최종 Unembedding 행렬을 중간(Intermediate) 레이어에 바로 적용해보면 어떨까 하는 것이었습니다.
이 기법을 Logit Lens 라고 부릅니다. 이는 밀집 벡터 를 임의의 레이어 에서 다시 어휘 공간(Vocabulary space)으로 번역해 주는 해독기 역할을 합니다.
Logit Lens 가 밝혀낸 사실들
GPT-2 와 같은 모델에 Logit Lens 를 적용하자, LLM 추론의 반복적(Iterative) 특성에 대한 심오한 통찰이 드러났습니다.
- 쉬운 토큰의 조기 수렴 (Early Convergence): 문법적으로 뻔한 토큰(예: Stop words,
NewYork처럼 강력한 바이그램)의 경우, 모델은 종종 처음 몇 개의 레이어 안에서 올바른 예측으로 수렴합니다. 나머지 레이어들은 이 예측값을 건드리지 않고 그대로 앞으로 전달만 합니다. - 반복적 정제 (Iterative Refinement): 복잡한 사실적 지식을 묻는 쿼리에서, 초기 레이어는 일반적인 추측(예: 흔한 명사 예측)을 내놓고, 중간 레이어는 이를 특정 범주로 좁히며, 최종 레이어에 가서야 정확한 엔티티(Entity)를 짚어냅니다.
- 즉각적인 표현 변환 (Immediate Representation): 모델은 원본 입력 토큰을 그대로 유지하지 않습니다. 레이어 1을 통과할 즈음이면, 입력 표현은 이미 미래 토큰을 예측하기 위한 예측적(Predictive) 표현으로 변환되어 있습니다.
 (Source: Generated by Gemini)
(Source: Generated by Gemini)
2. Engineering the Extraction (PyTorch)
Logit Lens 를 구현하려면 순전파(Forward pass) 중에 중간 은닉 상태(Hidden states)를 추출해야 합니다. 표준 HuggingFace API 는 보통 output_hidden_states=True 플래그를 제공하지만, 전체 연산 그래프를 메모리에 저장하고 싶지 않은 환경이나 커스텀 아키텍처를 다룰 때는 PyTorch Hook 을 사용하여 수동으로 추출하는 엔지니어링 패턴을 이해하는 것이 필수적입니다.
아래는 최신 LLM(예: LLaMA 또는 Mistral)에서 중간 로짓을 추출하기 위한 강력한 PyTorch 엔지니어링 패턴입니다.
import torch
import torch.nn as nn
from transformers import AutoModelForCausalLM, AutoTokenizer
from typing import List
def compute_logit_lens(model_name: str, prompt: str) -> List[torch.Tensor]:
"""
LLM의 모든 중간 레이어에서 어휘(Vocabulary) 로짓을 추출합니다.
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
hidden_states = []
# 각 트랜스포머 블록의 출력을 캡처하기 위한 Hook 정의
def hook_fn(module, input, output):
# output[0]은 (batch, seq_len, hidden_dim) 형태의 은닉 상태를 포함합니다.
hidden_states.append(output[0].detach())
# 모든 레이어에 Hook 등록
# 참고: 아키텍처 경로는 모델마다 다릅니다. LLaMA/Mistral의 경우 `model.model.layers` 입니다.
# GPT-2의 경우 `model.transformer.h`가 됩니다.
hooks = []
for layer in model.model.layers:
hooks.append(layer.register_forward_hook(hook_fn))
# 순전파 (해석 가능성 추출을 위해 Gradient는 필요하지 않음)
with torch.no_grad():
_ = model(**inputs)
# 메모리 누수 방지를 위한 Hook 제거
for hook in hooks:
hook.remove()
intermediate_logits = []
# 각 중간 상태를 어휘 공간으로 투영(Projection)
for h in hidden_states:
# 매우 중요: lm_head를 통과하기 전에 최종 LayerNorm을 적용해야 합니다.
# LLaMA의 경우: model.model.norm(h)
h_norm = model.model.norm(h)
# Unembedding 행렬을 사용한 투영
logits = model.lm_head(h_norm)
intermediate_logits.append(logits)
return intermediate_logits
# 사용 예시:
# logits_per_layer = compute_logit_lens("meta-llama/Llama-2-7b-hf", "The capital of France is")
# logits_per_layer[10] -> 10번째 레이어에서의 어휘 확률 분포를 포함합니다.3. The Tuned Lens: Overcoming Basis Shift
Logit Lens 는 GPT-2 에서는 놀라울 정도로 잘 작동하지만, 연구자들은 BLOOM 이나 Pythia 와 같은 다른 모델에서는 쓰레기 값(Garbage outputs)을 생성한다는 사실을 발견했습니다.
이유가 무엇일까요? 표준 Logit Lens 는 레이어 5의 Residual Stream 벡터 공간이 최종 레이어 의 벡터 공간과 정렬되어 있다고 가정합니다. GPT-2 에서는 Tied embeddings (입력 임베딩 행렬과 최종 Unembedding 행렬이 동일한 가중치를 공유하는 구조) 덕분에 이것이 자연스럽게 발생합니다. 하지만 Tied embeddings 가 없는 모델에서는 네트워크가 레이어를 거치며 Residual Stream 의 기저(Basis)를 자유롭게 회전시키고 이동시킵니다.
이 문제를 해결하기 위해 Belrose et al. (2023) 은 Tuned Lens 를 도입했습니다 [2]. 이들은 를 직접 적용하는 대신, 각 레이어 에 대해 행렬 과 편향 로 구성된 작은 어파인 변환(Affine transformation, 일종의 번역기)을 학습시킵니다.
목적 함수 (The Objective Function)
여기서 매우 중요한 점은, Tuned Lens 가 실제 정답 토큰(Ground-truth next token)을 예측하도록 학습되지 않는다 는 것입니다. 대신, 중간 예측값과 최종 레이어의 예측값 사이의 KL 발산(KL divergence)을 최소화하도록 학습됩니다.
이러한 차이는 해석 가능성(Interpretability) 측면에서 핵심적입니다. 우리의 목표는 정답을 맞히는 조기 종료(Early-exit) 분류기를 만드는 것이 아니라, 모델이 현재 무엇을 믿고 있는지 를 충실하게 보고하는 탐침(Probe)을 만드는 것입니다. 만약 모델이 환각(Hallucination)을 일으켜 “Paris” 대신 “Rome”을 예측할 운명이라면, 충실한 Tuned Lens 는 중간 레이어에서부터 확률 질량(Probability mass)이 “Rome”으로 이동하는 것을 보여주어야 합니다.
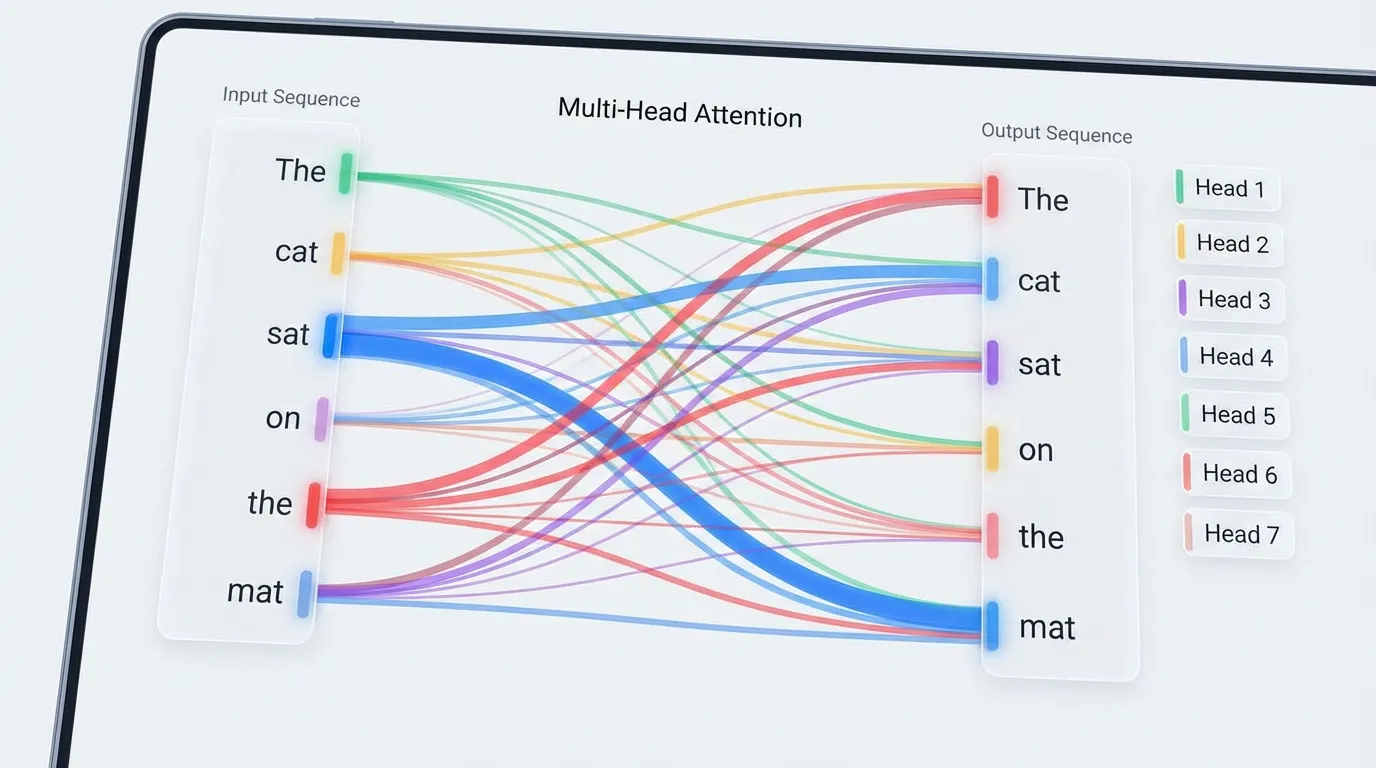
4. Attention Visualization: The “Where” of Information
Logit Lens 가 모델이 무엇을 생각하고 있는지 알려준다면, Attention Visualization (어텐션 시각화) 은 모델이 그러한 생각을 형성하기 위해 어디를 보고 있는지 알려줍니다.
BertViz [3] 와 같은 도구를 사용하면 연구자들은 불투명한 행렬 곱셈을 직접 검사할 수 있습니다. 어텐션 시각화는 일반적으로 세 가지 규모(Scale)에서 이루어집니다.
- Neuron View: 특정 Query 와 Key 벡터 간의 내적(Dot product)을 시각화합니다. 어떤 특징(Feature)이 어텐션 매칭을 유발하는지 정확히 확인하는 데 유용합니다.
- Head View: 특정 헤드의 어텐션 가중치 를 기반으로 입력 토큰과 컨텍스트 토큰을 연결하는 이분 그래프(Bipartite graph)를 표시합니다. 여기서 우리는 Induction Head 나 문법적 라우팅(예: 대명사가 명사에 어텐션을 주는 현상)을 발견할 수 있습니다.
- Model View: 모든 레이어의 모든 헤드에 걸친 어텐션 패턴을 동시에 보여주는 거시적인 그리드입니다.
 (Source: Generated by Gemini)
(Source: Generated by Gemini)
“어텐션은 설명이 아니다” (Attention is Not Explanation)
어텐션을 시각화하는 것은 강력하지만, 어텐션 가중치를 특징의 중요도(Feature importance)와 직접적으로 동일시하는 것은 흔한 함정입니다. Jain & Wallace (2019) 가 증명했듯이, 어텐션은 설명이 아닙니다 (Attention is not Explanation) [4].
헤드 가 apple 이라는 토큰에 강한 어텐션을 준다고 해서, 모델이 “사과”의 의미론적(Semantic) 의미를 추출하고 있다는 뜻은 아닙니다.
- 모델은
apple을 순전히 위치적인 앵커(Positional anchor)로만 사용하고 있을 수 있습니다. - 어텐션이 Attention Sink (예:
<s>또는[BOS]토큰) 로 향하고 있을 수 있습니다. 어텐션 가중치의 합은 항상 1이 되어야 하므로, 현재 기여할 유용한 정보가 없는 헤드들은 노이즈 데이터를 끌어오는 것을 방지하기 위해 첫 번째 토큰에 자신의 어텐션 질량을 “버립니다(Dump)”.
어텐션은 우리에게 라우팅 토폴로지(Routing topology)를 알려주지만, 라우팅되고 있는 페이로드(Payload) 가 무엇인지 이해하려면 여전히 Logit Lens 나 SAE(Sparse Autoencoders) 가 필요합니다.
5. Interactive: The Logit Lens in Action
레이어를 거치며 예측이 어떻게 진화하는지 직관적으로 이해하기 위해 아래의 대화형 Logit Lens 시각화 도구를 살펴보세요. 이 도구는 “The capital of France is” 라는 프롬프트를 처리하는 12레이어 모델의 중간 예측값을 시뮬레이션합니다.
깊이가 깊어짐에 따라 최종 토큰에 대한 예측이 일반적인 구문론적(Syntactic) 추측에서 구체적인 사실적(Factual) 답변으로 어떻게 전환되는지 주목하십시오.
Logit Lens Simulation
Hover over or click the slider to change the Transformer layer.
(Layer 12)
Late Layers (6-12): The model has converged on the factual answer. The remaining layers simply pass this confident prediction forward to the final output.
6. 실무 디버깅에서의 사용법
Logit Lens와 Attention Visualization은 논문 그림을 만들기 위한 도구만은 아닙니다. 모델이 제품에서 이상하게 행동할 때 원인을 좁히는 데 쓸 수 있습니다.
6.1 환각이 언제 시작되는지 보기
RAG 답변에서 모델이 문서에 없는 회사를 언급했다고 해봅시다. 최종 출력만 보면 “환각”이라고만 말할 수 있습니다. Logit Lens를 레이어별로 보면 더 구체적인 질문을 할 수 있습니다.
- 초기 레이어부터 잘못된 회사명이 강했는가?
- 중간 레이어에서 문서에 있는 회사명으로 갔다가 마지막 레이어에서 바뀌었는가?
- system prompt나 formatting token 이후에 잘못된 후보가 갑자기 올라왔는가?
첫 번째라면 parametric memory나 prompt bias 문제일 가능성이 큽니다. 두 번째라면 instruction tuning이나 decoding 단계에서 답변 스타일이 사실성을 덮었을 수 있습니다. 세 번째라면 template이나 delimiter 설계가 문제일 수 있습니다.
6.2 Attention을 볼 때의 최소 체크리스트
Attention heatmap을 볼 때는 예쁜 패턴보다 아래 질문이 더 중요합니다.
- 답변의 핵심 명사/숫자 토큰이 evidence token에 attention을 주는가?
- 특정 head가 항상 BOS나 delimiter에 attention을 버리는가?
- 긴 문서에서 앞부분만 과도하게 보는 positional bias가 있는가?
- tool result와 user prompt 중 어느 쪽을 더 강하게 보는가?
- prompt injection 문구가 system-like instruction으로 라우팅되는가?
이 체크리스트는 특히 RAG와 agent 로그 분석에 유용합니다. 모델이 “근거를 봤다”고 말해도 실제 attention/attribution이 전혀 다른 곳을 가리키면, citation 프롬프트를 고치는 것만으로는 부족합니다.
6.3 Early exit와 confidence 추정
Logit Lens는 추론 비용 최적화에도 힌트를 줍니다. 어떤 토큰은 얕은 레이어에서 이미 최종 예측이 안정되고, 어떤 토큰은 마지막 레이어까지 계속 바뀝니다. 이 신호를 잘 쓰면 early exit, speculative decoding, confidence-based verification 같은 시스템 최적화와 연결할 수 있습니다.
다만 주의할 점이 있습니다. 중간 레이어의 높은 confidence는 항상 정답을 의미하지 않습니다. 모델이 일찍부터 틀린 믿음으로 수렴할 수도 있습니다. 그래서 early exit는 단순 confidence threshold가 아니라 downstream task별 오류 비용과 함께 설계해야 합니다.
7. Summary and Open Questions
Logit Lens 와 Attention Visualization 은 토큰 예측의 생애 주기(Life cycle)를 관찰할 수 있는 거시적인 도구를 제공합니다. 우리는 Residual Stream 내에서 모델의 확신이 점진적으로 구축되는 과정을 지켜볼 수 있으며, 해당 예측을 내리는 데 필요한 컨텍스트를 운반하는 어텐션 고속도로(Attention highways)를 매핑할 수 있습니다.
하지만 이러한 도구들은 모델 파라미터의 약 3분의 2를 차지하는 MLP 레이어 를 단순히 Residual Stream 을 “업데이트”하는 불투명한 블랙박스로 취급합니다. 어텐션이 데이터를 라우팅한다면, MLP 는 사실과 개념을 저장하는 Key-Value 메모리 뱅크 역할을 합니다.
- MLP 내부에 저장된 구체적인 지식을 어떻게 읽어낼 수 있을까요?
- 모델이 특정 사실을 출력하지 않기로 결정했더라도, 그 사실을 “알고 있는지” 테스트할 수 있을까요?
이러한 질문에 답하기 위해, 우리는 수동적인 렌즈(Lens)를 넘어 적극적인 개입(Intervention)을 도입해야 합니다. 이는 우리의 다음 주제인 19.3 Probing Classifiers 로 이어집니다.
Quizzes
Quiz 1: 왜 초기 레이어(예: 0~2 레이어)에서는 표준 Logit Lens 가 종종 무의미한 토큰을 출력할까요?
초기 레이어는 최종적인 의미론적(Semantic) 출력을 예측하기보다는 구문 분석, 서브워드(Subword) 병합, 로컬 컨텍스트 구축 및 품사 설정 등에 주로 관여합니다. 이들의 표현(Representation)은 아직 최종 어휘 기저(Vocabulary basis)와 정렬되지 않았기 때문에, 를 통한 직접적인 투영은 신뢰할 수 없는 결과를 낳습니다.
Quiz 2: Tuned Lens 에서 중간 예측값을 정답(Ground truth) 토큰이 아닌 최종 레이어의 예측값 과의 KL 발산을 최소화하도록 학습하는 이유는 무엇일까요?
Mechanistic Interpretability 의 목표는 모델의 내부 신념(Belief)과 연산 과정을 이해하는 것입니다. 만약 탐침(Probe)을 정답 데이터로 학습시킨다면, 모델 자체가 무시하는 특징을 추출하는 완전히 새로운 분류기를 만들게 될 위험이 있습니다. 최종 레이어의 예측값과 일치시키면, 모델이 환각을 일으킬 때조차도 모델의 실제 사고 궤적을 충실하게 해독할 수 있습니다.
Quiz 3: 어텐션을 시각화할 때, 특정 어텐션 헤드가
이것은 “Attention Sink” 현상으로 알려져 있습니다. Softmax 함수는 어텐션 가중치의 합이 반드시 1이 되도록 강제하기 때문에, 현재 컨텍스트에서 관련 정보를 찾지 못한 헤드들은 자신들의 어텐션 질량을 무해한 곳에 버려야(Dump) 합니다. [BOS] (Beginning of Sequence) 토큰에 가중치의 90%를 할당하는 것을 발견했습니다. 가장 가능성 있는 기계적(Mechanical) 이유는 무엇일까요?[BOS] 토큰은 이러한 보편적이고 안전한 앵커(Anchor) 역할을 수행합니다.
Quiz 4: Tied embeddings (입력 임베딩 행렬과 최종 Unembedding 행렬이 동일한 가중치를 공유하는 구조) 의 존재가 기본 Logit Lens 의 성능에 어떤 영향을 미칠까요?
Tied embeddings 는 입력과 출력 표현이 공통의 벡터 공간을 공유하도록 강제합니다. 이는 중간 Residual Stream 이 어휘 기저(Vocabulary basis)와 더 가깝게 정렬되도록 자연스럽게 유도하므로, Tuned Lens 에서 사용되는 어파인 변환(Affine transformation) 없이도 기본 Logit Lens 가 훨씬 더 효과적으로 작동하게 만듭니다.
References
- nostalgebraist. (2020). interpreting GPT: the logit lens. AI Alignment Forum. Link.
- Belrose, N., et al. (2023). Eliciting Latent Predictions from Transformers with the Tuned Lens. arXiv:2303.08112.
- Vig, J. (2019). A Multiscale Visualization of Attention in the Transformer Model. arXiv:1906.05714.
- Jain, S., & Wallace, B. C. (2019). Attention is not Explanation. arXiv:1902.10186.