17.1 Academic Benchmarks
이전 장에서 우리는 장기 기억, 다단계 계획, 그리고 도구 사용 능력을 갖춘 자율 에이전트를 구축하는 방법을 살펴보았습니다. 그러나 이러한 복잡한 시스템을 엔지니어링하다 보면 필연적으로 다음과 같은 운영상의 핵심 질문에 직면하게 됩니다. “우리는 모델이 실제로 더 똑똑해지고 있는지, 아니면 단순히 암기를 더 잘하게 된 것인지 어떻게 증명할 수 있을까요?”
딥러닝 붐 이전의 소프트웨어 평가는 결정론적이었습니다. 단위 테스트(Unit test)는 통과하거나 실패하거나 둘 중 하나였습니다. 하지만 파운데이션 모델(Foundation Models)을 평가하는 것은 확률론적이며 매우 미묘한 작업입니다. 우리는 지능을 정량화하기 위해 설계된 표준화된 데이터셋과 지표, 즉 벤치마크 (Benchmarks) 에 의존합니다.
이번 섹션에서는 업계에서 널리 쓰이는 학술 벤치마크(MMLU, GSM8K, HumanEval)에서 출발해, 2024-2026년에 중요해진 HLE, LiveBench, SWE-bench, LiveCodeBench, MMMU 같은 평가까지 함께 봅니다. 핵심은 “어떤 벤치마크가 더 유명한가”가 아니라, 그 벤치마크가 무엇을 실제로 측정하고, 어떤 metric이 어떤 실패를 숨기는가 를 이해하는 것입니다.
1. 평가 패러다임의 진화
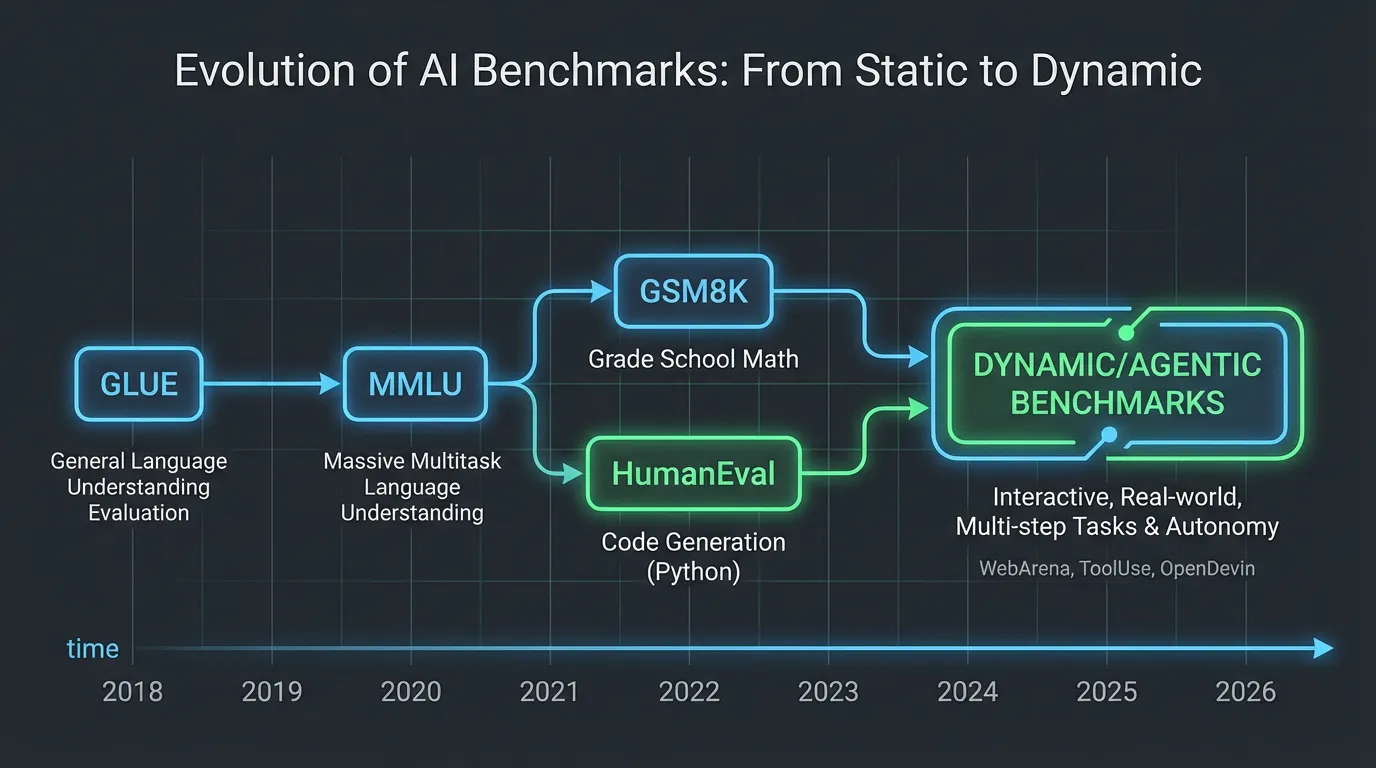
NLP 벤치마크의 역사는 끊임없이 이동하는 골대의 역사입니다. 모델의 규모가 커짐에 따라, 10년을 내다보고 설계된 벤치마크들이 불과 몇 달 만에 포화 상태(Saturated)에 이르렀습니다.
- GLUE 시대 (2018-2019): GLUE 와 SuperGLUE 같은 초기 벤치마크는 감성 분석, 자연어 추론(NLI), 문법적 정확성 등 기본적인 언어적 작업에 초점을 맞췄습니다. BERT 와 RoBERTa 가 등장할 즈음에는 이미 인간의 기준선을 넘어섰고, 최첨단(Frontier) 모델들에게 이 벤치마크들은 더 이상 변별력이 없게 되었습니다.
- 지식 시대 (2020-2022): 파라미터가 수백만 개에서 수십억 개(GPT-3, Chinchilla)로 증가함에 따라, 모델들은 방대한 양의 세상 지식을 내재화하기 시작했습니다. 평가는 상식 퀴즈, 전문직 자격 시험, 그리고 독해력 테스트로 전환되었습니다.
- 추론 시대 (2023-현재): 단순한 지식 검색(Retrieval)만으로는 충분하지 않습니다. 현대의 벤치마크는 다단계 논리, 수학적 문제 해결, 그리고 코드 생성 등 모델이 단순히 정보를 기억해내는 것을 넘어 새로운 정보를 합성해야 하는 작업들을 테스트합니다.
- 프론티어 평가 시대 (2024-현재): 모델이 기존 공개 벤치마크를 빠르게 포화시키면서, 평가도 더 어려워졌습니다. 최근 벤치마크는 fresh data, private split, expert-written problem, 실행 기반 채점, 멀티모달 입력, 장기 에이전트 작업처럼 오염과 과최적화를 줄이는 장치를 함께 설계합니다.
 Source: Generated by Gemini
Source: Generated by Gemini
2. 3대 핵심 벤치마크: MMLU, GSM8K, HumanEval
현대의 LLM 을 평가할 때, 연구자들은 일반적으로 일반 지식, 수학적 추론, 그리고 코딩이라는 세 가지 근본적인 축을 살펴봅니다.
2.1 MMLU (Massive Multitask Language Understanding)
Hendrycks et al. [1] 이 제안한 MMLU 는 일반 지식을 평가하는 절대적인 기준(Gold standard)입니다. 초등 수학부터 전문적인 법률, 양자 물리학에 이르기까지 57개 주제에 걸친 객관식 질문들로 구성되어 있습니다.
엔지니어링 과제: Logit 기반 평가 MMLU 를 평가하는 순진한(Naive) 방법은 모델에게 질문과 선택지를 프롬프트로 주고, 텍스트를 생성하게 한 뒤 출력에 “A”, “B”, “C”, 또는 “D” 가 포함되어 있는지 확인하는 것입니다. 하지만 생성 기반 평가는 매우 불안정합니다. 모델이 “정답은 확실히 A입니다” 라고 출력하거나 “첫 번째 것 같네요” 라고 출력할 수 있으며, 이를 처리하기 위해 복잡한 정규식(Regex) 파싱이 필요해집니다.
대신 엔지니어들은 Logit-based Evaluation 을 사용합니다. 정답 토큰이 위치해야 할 바로 그 지점에서 프롬프트가 끝나도록 포맷팅한 뒤, 모델이 ‘A’, ‘B’, ‘C’, ‘D’ 토큰에 할당하는 원시 확률(Logits)을 직접 측정합니다. 가장 높은 확률을 가진 토큰이 모델의 최종 답변으로 채택됩니다. 이 방식은 모델의 대화형 포맷팅 얼라인먼트(Alignment) 문제와 무관하게 모델의 순수한 지식만을 격리하여 평가할 수 있게 해줍니다.
2.2 GSM8K (Grade School Math 8K)
OpenAI 가 구축한 [2] GSM8K 는 8,500개의 고품질 초등학교 수준 수학 서술형 문제로 구성되어 있습니다. 이 벤치마크는 다단계 산술 추론을 요구합니다.
MMLU 와 달리, GSM8K 는 정답 공간이 무한대(어떤 숫자든 가능)이기 때문에 Logit 을 통한 평가가 불가능합니다. 따라서 Generative Exact Match 가 필요합니다. 모델에게 단계별로 생각하도록(Chain-of-Thought) 프롬프트를 주고, #### 42 와 같은 특정 포맷 안에 최종 정답을 출력하도록 유도합니다. 평가 스크립트는 #### 뒤의 문자열을 추출하여 실제 정답(Ground truth)과 비교합니다.
여기서 metric을 단순히 “정답률”이라고 부르면 중요한 부분을 놓칩니다. 수학 벤치마크는 보통 최종 답만 자동 채점합니다. 중간 풀이가 그럴듯해도 마지막 숫자가 틀리면 0점이고, 반대로 풀이가 이상해도 최종 답이 맞으면 통과할 수 있습니다. 그래서 수학 평가에서는 다음을 같이 기록하는 편이 좋습니다.
- Exact match after normalization: 쉼표, 단위, 분수 표현, LaTeX 표기 등을 정규화한 뒤 최종 답이 같은지 확인합니다.
- Self-consistency accuracy: 여러 풀이를 샘플링하고 최종 답의 다수결을 취했을 때의 정확도입니다. 모델의 단일 풀이 능력과 샘플링을 통한 탐색 능력을 구분하는 데 유용합니다.
- Process-aware score: 가능하면 중간 풀이의 논리도 별도로 봅니다. 특히 기업 환경에서 계산 결과를 고객에게 보여줘야 한다면, 답만 맞는 모델보다 오류를 추적할 수 있는 풀이가 더 중요할 수 있습니다.
2.3 HumanEval
Codex 와 함께 소개된 [3] HumanEval 은 코드 생성에 있어서 기능적 정확성(Functional correctness)을 측정합니다. 모델에게 Python 함수 시그니처와 독스트링(Docstring)이 주어지면, 모델은 함수 본문을 완성해야 합니다.
생성된 코드가 정답과 ‘비슷하게 생겼는지’를 확인하는 대신 (함수를 작성하는 방법은 무한하므로 이는 불가능합니다), HumanEval 은 샌드박스(Sandboxed) 환경에서 숨겨진 단위 테스트(Unit tests)를 상대로 생성된 코드를 직접 실행 합니다. 테스트를 통과하면 모델은 점수를 얻습니다.
코딩 평가는 BLEU나 ROUGE 같은 문자열 유사도와 잘 맞지 않습니다. 같은 함수를 구현하는 올바른 방법은 여러 가지이고, 반대로 표면적으로 비슷한 코드는 엣지 케이스에서 쉽게 깨집니다. 그래서 코딩 벤치마크의 metric은 대부분 execution-based 입니다.
- pass@1: 모델이 첫 번째로 낸 답이 테스트를 통과하는 비율입니다. 사용자에게 한 번에 답을 내는 챗봇이나 IDE 자동완성에 가깝습니다.
- pass@k: 여러 후보를 생성했을 때 적어도 하나가 통과하는 확률입니다. 실제 개발자가 여러 시도와 테스트 실행을 반복하는 workflow를 더 잘 반영합니다.
- resolved rate: SWE-bench 계열에서 쓰는 지표입니다. 모델이 실제 저장소를 수정한 뒤, 이슈를 재현하는 테스트와 기존 회귀 테스트를 통과하면 해결된 것으로 봅니다.
- format/apply success: 코드 에이전트에서는 “정답 알고리즘을 알고 있는가”만큼 “패치를 제대로 적용했는가”도 중요합니다. diff 형식 오류, 파일 경로 오류, 테스트 실행 실패는 별도의 운영 지표로 분리해야 합니다.
3. 최신 프론티어 벤치마크 지도
기존의 MMLU, GSM8K, HumanEval은 여전히 기준선으로 유용합니다. 다만 2026년 현재 프론티어 모델을 비교할 때는 아래 벤치마크들을 함께 봐야 합니다.
| 벤치마크 | 무엇을 보나 | 주된 metric | 실무에서 읽는 법 |
|---|---|---|---|
| HLE (Humanity’s Last Exam) [4] | 수학, 과학, 인문학 등 전문가 수준의 폐쇄형 문제와 일부 멀티모달 문제 | 객관식/단답형 자동 채점, calibration error | “검색하면 나오는 지식”보다 전문가가 검증 가능한 난문제를 푸는지 봅니다. 점수가 낮아도 이상하지 않고, 모델 간 프론티어 차이를 보기 좋습니다. |
| GPQA Diamond [5] | 박사급 과학 질문 | multiple-choice accuracy | 검색보다 깊은 전공 추론에 가깝습니다. 단, 선택지가 있는 평가이므로 추론 흔적과 confidence도 함께 봐야 합니다. |
| MATH / AIME 계열 [6] | 올림피아드 스타일 수학 문제 | normalized exact match, sometimes majority vote | 최종 답 채점이 쉬워 좋은 자동 metric이지만, 풀이의 검증 가능성을 별도로 확인해야 합니다. |
| LiveBench [7] | 최신 데이터 기반의 수학, 코딩, 추론, 데이터 분석 | objective accuracy, monthly/fresh updates | contamination을 줄이려는 목적이 큽니다. 제품 릴리스 때 공개 static benchmark를 보완하는 신선도 지표로 쓰기 좋습니다. |
| SWE-bench / SWE-bench Verified [8] | 실제 GitHub 이슈 해결 | resolved rate | 코드 생성이 아니라 저장소 이해, 테스트 실행, 다중 파일 수정 능력을 봅니다. 다만 2026년에는 Verified도 일부 포화/오염 우려가 있어 최신 변형이나 private issue set이 필요합니다 [9]. |
| LiveCodeBench [10] | 최신 코딩 콘테스트 문제, self-repair, 실행 결과 예측 | pass@1, pass@k, task별 accuracy | HumanEval보다 오염에 강하고 난도가 높습니다. 알고리즘 풀이와 실행 기반 평가를 함께 봅니다. |
| MMMU / MMMU-Pro [11] | 대학 수준의 멀티모달 전공 문제 | multiple-choice accuracy, vision-only/text-image settings | 이미지, 도표, 수식, 텍스트를 함께 읽는 능력을 봅니다. 텍스트만으로 풀리는 문제를 걸러낸 변형이 더 강한 신호를 줍니다. |
| MathVista [12] | 시각적 수학 추론 | exact match / multiple-choice accuracy | 차트, 기하 도형, 다이어그램을 읽고 계산하는 능력을 봅니다. OCR, 시각 인식, 수학 추론 중 어디서 실패했는지 분해해야 합니다. |
이 표에서 중요한 점은 벤치마크마다 “정답률”의 의미가 다르다는 것입니다. MMLU의 85%와 SWE-bench의 35%는 같은 난이도 축에 놓인 숫자가 아닙니다. 하나는 폐쇄형 질문의 선택지 확률이고, 다른 하나는 실제 저장소를 고쳐 테스트를 통과한 비율입니다.
3.1 멀티모달 평가는 무엇이 다른가
멀티모달 벤치마크는 텍스트 문제에 이미지 하나를 붙인 정도로 끝나지 않습니다. 평가자는 적어도 세 가지 실패를 분리해야 합니다.
- Perception failure: 모델이 이미지의 물체, 표, 축, 글자, 좌표를 잘못 읽습니다.
- Grounding failure: 이미지에서 읽은 정보를 질문의 조건과 연결하지 못합니다.
- Reasoning failure: 시각 정보는 맞게 읽었지만 계산이나 논리 전개에서 실패합니다.
그래서 MMMU-Pro 같은 평가에서는 텍스트만으로 풀 수 있는 문제를 제거하거나, 질문 자체를 이미지에 넣어 OCR과 시각-언어 결합 능력을 함께 봅니다. 프로덕션에서도 같은 방식이 필요합니다. 예를 들어 보험 청구서 분석 모델을 평가한다면 “문서 OCR 정확도”, “필드 추출 정확도”, “약관 적용 판단”, “최종 답변의 근거 인용”을 하나의 점수로 뭉개지 말고 분리해야 합니다.
4. Metric을 엄밀하게 설계하기
벤치마크 결과표에는 보통 숫자 하나만 보입니다. 하지만 AI 개발자가 실제로 봐야 하는 것은 “그 숫자가 어떤 채점 파이프라인에서 나왔는가”입니다. 같은 모델도 프롬프트 포맷, 샘플링 설정, 답 추출기, 통계 처리에 따라 몇 퍼센트포인트씩 달라질 수 있습니다.
4.1 객관식 평가: Accuracy만으로 충분하지 않다
MMLU나 GPQA 같은 객관식 평가는 보통 accuracy로 보고합니다. 하지만 구현은 생각보다 예민합니다.
- Micro average: 모든 문제를 하나의 풀로 합쳐 정답률을 계산합니다. 문제 수가 많은 과목이 점수에 더 큰 영향을 줍니다.
- Macro average: 과목별 정답률을 먼저 구한 뒤 평균냅니다. 과목 간 균형을 보고 싶을 때 좋습니다.
- Logprob scoring: 선택지 문자
A/B/C/D의 next-token logit을 비교하거나, 선택지 전체 문자열의 평균 log likelihood를 비교합니다. 후자는 선택지 길이 bias를 줄이기 위해 토큰 수로 정규화해야 합니다. - Option order randomization: 선택지 순서를 바꿔도 점수가 유지되는지 봅니다. 특정 위치 bias가 있는 모델은
C를 과하게 고르는 식의 패턴을 보일 수 있습니다. - Calibration: 정답률이 같아도 확신도가 다르면 운영 리스크가 다릅니다. Expected Calibration Error(ECE), Brier score, Negative Log Likelihood(NLL)를 함께 보면 “틀릴 때 얼마나 자신만만한가”를 알 수 있습니다.
실무 팁은 단순합니다. 객관식 평가 결과를 저장할 때 최종 답뿐 아니라 각 선택지의 logit/logprob, 선택지 순서, prompt template hash를 같이 남기십시오. 나중에 점수가 흔들릴 때 원인을 찾는 시간이 크게 줄어듭니다.
4.2 생성형 답안: 답 추출기가 metric의 일부다
수학, 단답형 QA, 데이터 분석 문제는 모델이 자유 형식으로 답을 생성한 뒤 마지막 답을 추출합니다. 이때 평가 스크립트가 사실상 benchmark의 일부가 됩니다.
- 정규화 규칙:
1,000,1000,1e3,\frac{1}{2},0.5처럼 같은 값을 같은 답으로 볼지 정합니다. - 수치 허용 오차: 부동소수점 답은 절대 오차와 상대 오차를 명시해야 합니다. 예를 들어
abs(pred-gold) < 1e-6인지,relative error < 1%인지에 따라 결과가 달라집니다. - 단위 처리:
5 km와5000 m를 같은 답으로 볼지, 단위 누락을 오답으로 볼지 결정해야 합니다. - 복수 정답: 집합, 범위, 순서 없는 목록은 exact string match로 채점하면 과도하게 가혹합니다. canonicalization이 필요합니다.
- 추출 실패율: 모델이 답을 냈지만 parser가 못 읽은 경우를 별도 지표로 남깁니다. 이는 모델 능력 문제가 아니라 제품 포맷팅 문제일 수 있습니다.
특히 수학 벤치마크에서는 “풀이가 맞는가”와 “최종 답이 맞는가”를 구분해야 합니다. 자동 평가는 보통 최종 답만 봅니다. 제품에서 풀이를 사용자에게 보여준다면, 별도의 process evaluation이나 human audit 샘플링이 필요합니다.
4.3 코딩 평가: 테스트가 곧 정답이다
코딩 벤치마크는 문자열 유사도가 아니라 실행 결과를 봅니다. 따라서 metric 설계는 테스트 하네스 설계와 거의 같습니다.
- Hidden tests: 공개 예제만 통과하는 코드는 점수로 인정하면 안 됩니다. 엣지 케이스와 property-based test를 포함해야 합니다.
- Timeout / resource limit: 무한 루프, 과도한 메모리 사용, 네트워크 접근을 막아야 합니다.
- Sandbox isolation: 생성 코드가 파일시스템, 환경 변수, secret, 네트워크에 접근하지 못하게 해야 합니다.
- Flaky test handling: 테스트 자체가 불안정하면 모델 점수가 흔들립니다. 동일 패치를 여러 번 실행하거나 flaky test를 제외하는 정책이 필요합니다.
- Patch application rate: SWE-bench류에서는 모델이 낸 diff가 실제 repo에 적용되는지도 metric입니다. 적용 실패와 테스트 실패는 다른 실패입니다.
- Resolved@k: 여러 후보 패치를 생성하고 테스트했을 때 적어도 하나가 이슈를 해결하는 비율입니다. pass@k와 비슷하지만, 실제 repo 상태 변경과 회귀 테스트까지 포함합니다.
코딩 평가의 함정은 테스트가 완전하지 않다는 점입니다. 테스트를 통과한 패치가 실제로 좋은 코드라는 뜻은 아닙니다. 그래서 운영 환경에서는 unit test pass와 함께 lint, type check, security scan, diff size, touched file count 같은 보조 지표를 함께 봅니다.
4.4 통계적으로 비교하기
모델 A가 72.1%, 모델 B가 72.8%라면 B가 정말 나은 것일까요? 평가셋이 작거나 모델별 실패가 강하게 겹치면 이 차이는 노이즈일 수 있습니다.
- Confidence interval: accuracy는 binomial Wilson interval이나 bootstrap interval을 함께 보고합니다.
- Paired comparison: 같은 문제 집합에서 두 모델의 정오답을 쌍으로 비교합니다. McNemar test나 paired bootstrap이 단순 독립 비율 비교보다 적절합니다.
- Slice analysis: 전체 점수보다 과목, 언어, 난이도, 입력 길이, tool 사용 여부별 점수가 더 유용할 때가 많습니다.
- Regression threshold: 릴리스 판단에서는 “평균 +0.2%”보다 “고위험 slice에서 -3% 하락 없음”이 더 중요할 수 있습니다.
좋은 평가 리포트는 리더보드 숫자 하나가 아니라, 점수, 신뢰구간, 실패 slice, 답 추출 실패율, contamination 위험, 실행 환경 을 함께 보여줍니다.
5. Pass@k 의 수학
LLM 은 확률적으로 토큰을 샘플링하기 때문에 (온도 일 때), 첫 번째 시도에서는 올바른 코드를 작성하는 데 실패하더라도 다섯 번째 시도에서는 성공할 수 있습니다. 이를 체계적으로 측정하기 위해 HumanEval 은 지표를 도입했습니다.
는 생성된 개의 코드 샘플 중 적어도 하나가 단위 테스트를 통과할 확률을 측정합니다. 우리가 총 개의 샘플을 생성하고 (), 그 중 개가 정답일 때, 무작위로 개의 샘플을 뽑았을 때 통과할 실제 확률은 다음과 같습니다.
- : 개에서 개를 고르는 전체 경우의 수.
- : 오답 풀 () 에서만 개를 고르는 경우의 수.
- 이 비율은 번의 시도가 모두 실패할 확률입니다. 이를 1에서 빼면 적어도 한 번 성공할 확률이 나옵니다.
실제 프로덕션 환경에서 거대한 조합(Combination)을 계산하면 수치적 오버플로우(Numerical overflow)가 발생합니다. 따라서 엔지니어들은 다음과 같은 동치인 곱(Product) 형태를 사용하여 이를 계산합니다.
인터랙티브 시각화: Pass@k 계산기
아래의 파라미터를 조정하여 생성량(), 모델의 능력(), 그리고 평가 예산()이 점수에 어떤 영향을 미치는지 확인해 보십시오. 단일 샷 정확도가 낮은 모델 (예: 개 중 개 정답) 이더라도 점수는 여전히 높게 나올 수 있음을 주목하십시오.
Pass@k Calculator
Evaluate the probability of generating at least one correct solution.
6. Logit-Based Evaluation 엔지니어링
학술 벤치마크가 어떻게 채점되는지 진정으로 이해하려면 추론 파이프라인 내부를 들여다보아야 합니다. 아래는 강력하고 결정론적인 Logit 기반 객관식 평가 (MMLU 의 표준) 를 수행하는 방법을 보여주는 PyTorch 구현입니다.
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
def evaluate_multiple_choice(
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
question: str,
choices: list[str],
device: str = "cuda"
) -> dict:
"""
어휘(Vocabulary) Logit 을 사용하여 객관식 질문을 평가합니다.
"""
# 1. 프롬프트를 엄격하게 포맷팅합니다.
# "Answer:" 뒤에 후행 공백(Trailing space)이 없음에 유의하십시오.
# 우리는 모델이 정확히 다음 토큰을 예측하기를 원합니다.
prompt = f"{question}\nChoices:\nA) {choices[0]}\nB) {choices[1]}\nC) {choices[2]}\nD) {choices[3]}\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 2. 유효한 선택지에 대한 토큰 ID를 가져옵니다.
# 주의: 토크나이저(예: Llama의 SentencePiece vs GPT의 BPE)에 따라
# ' A' 는 'A' 와 완전히 다른 토큰일 수 있습니다.
# 견고한 평가 스크립트는 여러 변형(Variants)을 모두 확인합니다.
choice_tokens = [" A", " B", " C", " D"]
choice_ids = [tokenizer.encode(c, add_special_tokens=False)[-1] for c in choice_tokens]
with torch.no_grad():
# 3. 단일 Forward Pass 실행
outputs = model(**inputs)
# 4. 시퀀스의 가장 마지막 토큰에 대한 Logit 추출
# 형태: (batch_size=1, vocab_size)
next_token_logits = outputs.logits[0, -1, :]
# 5. 우리가 지정한 선택지 ID들에 대한 Logit 만 분리
choice_logits = next_token_logits[choice_ids]
# 6. Softmax 를 적용하여 4개의 선택지에 대한 정규화된 확률 계산
probs = F.softmax(choice_logits, dim=0)
# 7. 모델의 최종 예측은 이 4개의 Logit 중 argmax 값
pred_idx = torch.argmax(choice_logits).item()
return {
"predicted_choice": chr(65 + pred_idx), # 0->A, 1->B 등으로 변환
"probabilities": {chr(65 + i): prob.item() for i, prob in enumerate(probs)},
"raw_logits": choice_logits.tolist()
}
# --- 실행 예시 ---
# `model` 과 `tokenizer` 가 로드되어 있다고 가정합니다:
# question = "프랑스의 수도는 어디인가요?"
# choices = ["베를린", "마드리드", "파리", "로마"]
# result = evaluate_multiple_choice(model, tokenizer, question, choices)
# print(f"모델의 선택: {result['predicted_choice']} (신뢰도 {result['probabilities']['C']:.2%})")생성 루프 (model.generate()) 를 우회하고 단일 Forward Pass 만으로 Logit 을 검사함으로써, 이 방법은 연산 비용이 훨씬 저렴하고, 완전히 결정론적(Deterministic)이며, 포맷팅 환각(Formatting hallucinations)에 면역을 갖습니다.
7. 데이터 오염 (Contamination) 의 위기
정적인 학술 벤치마크는 이제 단독 지표로는 점점 덜 믿을 만해지고 있습니다. 데이터 오염(Data Contamination) 또는 데이터 누출(Data Leakage)을 배제하기가 갈수록 어려워지기 때문입니다.
파운데이션 모델은 인터넷에서 스크랩한 수조 개의 토큰으로 사전 학습(Pre-training)됩니다. MMLU 나 HumanEval 같은 벤치마크는 GitHub 나 학술 웹사이트에 공개되어 있기 때문에, 불가피하게 사전 학습 코퍼스에 흡수됩니다. 어떤 모델이 HumanEval 에서 95%의 점수를 기록했을 때, 그것이 일반화된 코딩 지능을 증명하는 것일까요, 아니면 단순히 사전 학습 중에 정확한 해답을 암기한 것일까요?
7.1 오염 감지 (Detecting Contamination)
엔지니어들은 테스트 셋이 학습 데이터에 누출되었는지 감지하기 위해 여러 휴리스틱(Heuristics)을 사용합니다.
- N-gram Overlap: 벤치마크의 정확한 13-gram 또는 32-gram 시퀀스가 학습 코퍼스에 존재하는지 확인합니다.
- Perplexity Spikes: 모델이 유사한 구조의 새로운 질문에 비해 벤치마크 질문의 프롬프트 텍스트에 부자연스럽게 낮은 Perplexity (매우 높은 확신) 를 부여한다면, 이를 암기했을 가능성이 높습니다.
- Canary GUIDs: 현대의 벤치마크 제작자들은 데이터셋에 고유한 UUID (Canary strings) 를 삽입합니다. 연구자들이 모델의 출력이나 학습 데이터에서 이 UUID 를 발견하면 오염이 확정됩니다.
7.2 해결책: 동적 및 비공개 벤치마크
굿하트의 법칙 (“측정 지표가 목표가 되는 순간, 그것은 더 이상 좋은 지표가 아니다”) 에 대응하기 위해, 업계는 정적인 데이터셋에서 벗어나고 있습니다. 현대의 평가는 매 실행 시마다 수학 문제의 숫자와 변수가 절차적으로 무작위화되는 동적 벤치마크 (Dynamic Benchmarks) 와 인터넷에 절대 공개되지 않는 비공개 홀드아웃 셋 (Private Hold-out Sets) (Scale AI 나 LMSYS 가 사용하는 독점 데이터셋 등) 에 의존하고 있습니다.
8. 실무용 벤치마크 설계 체크리스트
기업용 AI 서비스를 만드는 팀이라면 공개 벤치마크 점수만으로 모델을 고르면 안 됩니다. 최소한 아래 네 층을 함께 가져가야 합니다.
- 공개 기준선: MMLU, GPQA, LiveBench, HumanEval, SWE-bench처럼 업계가 이해하는 공통 지표를 둡니다.
- 도메인 private set: 실제 고객 문서, 내부 코드 스타일, 회사 정책, 지원 티켓에서 나온 비공개 평가셋을 만듭니다.
- 실행 기반 평가: 코드, SQL, tool call, 수학 계산은 가능하면 실행해서 채점합니다. judge 텍스트 점수보다 테스트 통과 여부가 훨씬 강합니다.
- 회귀 추적: 모델 버전, 프롬프트 버전, retrieval index 버전, tool schema 버전을 함께 기록합니다. 모델만 바뀐 줄 알았는데 실제로는 검색 인덱스가 바뀐 경우가 매우 많습니다.
벤치마크는 “모델의 IQ 점수”가 아니라 릴리스 판단을 위한 계측 장비입니다. 계측 장비가 무엇을 재고 있는지 모르면, 점수가 높아질수록 오히려 잘못된 확신이 커집니다.
9. 미해결 과제와 다음 장으로의 연결
학술 벤치마크는 일반 지식과 이산적인 논리를 측정하기 위한 필수적인 기준선을 제공합니다. 그러나 이러한 지표들은 모델이 개방형(Open-ended) 대화에서 인간 사용자와 어떻게 상호작용하는지를 포착하는 데는 실패합니다. 어떤 모델은 MMLU 에서는 만점을 받을지 모르지만, 답변이 지나치게 장황하거나, 안전한 프롬프트마저 거부하거나, 답변의 포맷을 엉망으로 만들 수 있습니다.
객관적인 “정답(Ground truth)” 이 존재하지 않을 때, 우리는 모델의 분위기(Vibe), 유용성, 그리고 대화형 얼라인먼트를 어떻게 평가해야 할까요? 다음 섹션인 17.2 LLM-as-a-Judge 에서는 엄격한 학술 테스트와 인간의 주관적 선호도 사이의 간극을 메우기 위해, 연구자들이 최첨단 모델을 사용하여 다른 모델을 정성적으로 평가하는 프레임워크에 대해 탐구할 것입니다.
Quizzes
Quiz 1: MMLU 와 같은 객관식 벤치마크에서 텍스트 생성 기반 평가보다 Logit 기반 평가(Logit-based evaluation)가 선호되는 이유는 무엇입니까?
텍스트 생성 기반 평가는 모델이 텍스트를 직접 출력하도록 요구하는데, 이 과정에서 변동성과 포맷팅 문제가 발생합니다 (예: 모델이 단순히 “A” 라고 출력하는 대신 “제 생각에 정답은 A입니다” 라고 출력할 수 있음). 이는 불안정한 정규식 파싱을 필요로 합니다. 반면 Logit 기반 평가는 텍스트 생성을 완전히 우회하고, 정답이 예상되는 정확한 위치에서 특정 토큰(A, B, C, D)에 대한 원시 확률 분포를 직접 측정합니다. 이는 포맷팅에 구애받지 않고 모델의 내부 지식을 결정론적으로 측정할 수 있게 해줍니다.
Quiz 2: HumanEval 벤치마크의 맥락에서, 표준 정확도(k=1) 대신 지표를 사용하는 이유는 무엇입니까?
LLM 은 온도(Temperature) 파라미터에 기반하여 확률적으로 결과를 생성합니다. 코딩은 단 하나의 문자만 누락되어도 전체가 실패할 수 있는 복잡한 작업입니다. 표준 정확도(pass@1)는 모델이 첫 번째 샘플에서 단순히 운이 나빴을 경우 모델의 실제 능력을 심각하게 과소평가할 수 있습니다. 는 생성된 개의 솔루션 중 적어도 하나가 단위 테스트를 통과할 확률을 측정하며, 이는 해결책 공간을 탐색하는 모델의 능력을 더 잘 반영하고 개발자가 여러 대안을 생성하여 테스트하는 실제 워크플로우를 더 정확하게 대변합니다.
Quiz 3: 만약 어떤 모델이 GSM8K 와 같은 정적인 벤치마크에서는 예외적으로 높은 점수를 달성했지만, 사용자가 제공한 새로운 수학 문제에서는 형편없는 성능을 보인다면, 가장 가능성이 높은 엔지니어링 원인은 무엇입니까?
데이터 오염 (Data Contamination) 또는 데이터 누출(Data Leakage) 때문입니다. 정적인 벤치마크 데이터셋이 (의도적이든 웹 크롤링을 통해 우연히든) 모델의 거대한 사전 학습 코퍼스에 포함되었을 가능성이 높습니다. 모델은 일반화된 수학적 추론 능력을 학습한 것이 아니라, 단순히 특정 질문과 정답을 암기한 것입니다.
Quiz 4: Logit 평가를 위한 PyTorch 코드를 살펴보십시오. 토크나이저에 따라
SentencePiece (Llama 에서 사용) 와 같은 토크나이저는 공백(Space)을 토큰의 일부로 취급합니다 (종종 ’ ’ 와 같은 특수 문자로 표현됨). tokenizer.encode("A") 대신 tokenizer.encode(" A") 를 사용하는 것이 왜 매우 중요합니까?\nA) Choice\nAnswer: A 로 포맷팅된 프롬프트에서, 모델은 실제로는 공백 뒤에 ‘A’ 가 오는 토큰을 예측하고 있습니다. 만약 공백이 없는 “A” 의 토큰 ID 에 대한 Logit 을 조회한다면, 확률 분포의 완전히 엉뚱한 부분을 확인하게 되어 모델의 벤치마크 점수가 인위적으로 폭락하게 됩니다.
Quiz 5: 오답 샘플 수 가 보다 엄격히 작을 때 의 명시적 수학적 경계 논리를 수식화하십시오. 조합론적 정식화 측면에서 이것이 의미하는 바는 무엇입니까?
오답 샘플 수가 보다 작을 때(), 크기가 인 부분집합을 크기가 미만인 풀에서 선택할 수 없으므로 조합론적 부분집합 는 본질적으로 0이 됩니다. 정식 수식 에서 비율 항은 0으로 떨어집니다. 따라서 으로 결정론적 수렴을 이룹니다. 이러한 경계 최적화를 통해 엔지니어들은 연산 파이프라인을 단축(Short-circuit)할 수 있습니다: 만약 실패 부분집합의 크기가 아래로 떨어지면 순차적인 조합론적 처리 없이 즉시 완벽한 점수를 플래그 처리할 수 있습니다.
References
- Hendrycks, D., et al. (2020). Measuring Massive Multitask Language Understanding. arXiv:2009.03300.
- Cobbe, K., et al. (2021). Training Verifiers to Solve Math Word Problems. arXiv:2110.14168.
- Chen, M., et al. (2021). Evaluating Large Language Models Trained on Code. arXiv:2107.03374.
- Phan, L., et al. (2025/2026). Humanity’s Last Exam. arXiv:2501.14249, Nature 2026.
- Rein, D., et al. (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv:2311.12022.
- Hendrycks, D., et al. (2021). Measuring Mathematical Problem Solving With the MATH Dataset. arXiv:2103.03874.
- White, C., et al. (2024). LiveBench: A Challenging, Contamination-Free LLM Benchmark. arXiv:2406.19314, GitHub.
- Jimenez, C. E., et al. (2023). SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770.
- OpenAI. (2026). Why SWE-bench Verified no longer measures frontier coding capabilities. OpenAI Research.
- Jain, N., et al. (2024). LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv:2403.07974.
- Yue, X., et al. (2023). MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. arXiv:2311.16502.
- Lu, P., et al. (2023). MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts. arXiv:2310.02255.