19.1 Mechanistic Interpretability
현대의 대규모 언어 모델(LLM)은 종종 블랙박스 (Black Box)로 묘사됩니다. 우리는 테라바이트 단위의 데이터를 주입하고, 경사하강법을 사용해 단순한 목적 함수(다음 토큰 예측)를 최적화합니다. 그리고 그 결과로 논리적 추론, 번역, 코딩과 같은 복잡한 행동이 창발(Emergence)합니다.
Mechanistic Interpretability (기계적 해석 가능성, 이하 MechInterp) 는 이 블랙박스를 역공학(Reverse-engineering)하려는 야심 찬 과학적 시도입니다. 모델을 불투명한 통계 엔진으로 취급하는 대신, 컴파일된 컴퓨터 프로그램으로 바라봅니다. 수십억 개의 연속적인 가중치(Weights)를 인간이 이해할 수 있는 알고리즘, 자료구조, 논리 회로로 디컴파일하는 것이 목표입니다.
이는 마치 인공 두뇌를 연구하는 뇌과학이나, 외계 우주선을 역공학하는 것과 같습니다. 우리에게 하드웨어(가중치)는 있지만, 소스 코드는 없는 상태입니다.
1. Motivation and History
역사적으로 딥러닝은 모델을 더 크고 정확하게 만드는 Capability (성능) 에 집중해 왔습니다. 하지만 모델이 단순한 연구 결과물을 넘어 핵심 인프라로 전환됨에 따라, 모델이 어떻게 작동하는지 이해하는 것은 타협할 수 없는 안전 필수 요건이 되었습니다.
왜 Mechanistic Interpretability 가 필요한가?
- Alignment and Safety (정렬과 안전): 모델이 어떻게 의사결정을 내리는지 이해하지 못하면, 악의적으로 행동하지 않을 것이라고 보장할 수 없습니다 (예: 학습 중에는 정렬된 척하지만 배포 시 파괴적으로 행동하는 Deceptive Alignment).
- Debugging Hallucinations (환각 디버깅): 특정 사실을 검색하는 회로(Circuit)를 정확히 파악하면, 모델이 왜 환각을 일으키는지 짚어내고 지식을 외과 수술처럼 편집할 수 있습니다.
- Auditing (감사): 의료나 법률 같은 고위험 영역의 규제 준수를 위해서는 설명 가능한 의사결정 과정이 필요합니다.
이 분야의 현대적 뿌리는 Chris Olah (Distill, OpenAI, Anthropic) 와 같은 연구자들이 주도한 합성곱 신경망(CNN)의 Feature Visualization으로 거슬러 올라갑니다. 초기 연구는 CNN의 얕은 층이 어떻게 엣지(Edge)를 감지하고, 깊은 층이 개 코나 자동차 바퀴 같은 복잡한 개념을 감지하는지 시각화했습니다 [1].
Transformer 의 등장과 함께, 연구의 초점은 공간적 특징 맵(Spatial feature maps)에서 Residual Stream 과 Attention Matrices 로 이동했습니다. Anthropic의 기념비적인 논문인 A Mathematical Framework for Transformer Circuits [2] 는 현대 MechInterp 의 어휘를 정립하며, Transformer 를 거대한 단일 블록이 아니라 공유 메모리 대역폭(Residual Stream)을 통해 통신하는 ‘Head’들의 네트워크로 해석했습니다.
2. The Linear Representation Hypothesis
회로를 찾기 전에, 신경망이 개념을 어떻게 저장하는지 이해해야 합니다. MechInterp 에서 지배적인 이론은 Linear Representation Hypothesis (선형 표현 가설) 입니다.
이 가설은 신경망이 개념(Feature)을 개별 뉴런이 아닌 활성화 공간(Activation space)의 방향 으로 표현한다고 가정합니다.
Transformer의 Residual Stream이 고차원 벡터 공간 라면, “성별”, “복수형”, 또는 “개라는 개념”과 같은 특징은 특정 단위 벡터 로 나타납니다. 이 특징의 존재 여부는 활성화 벡터 가 이 방향으로 투영(Projection)된 값으로 결정됩니다:
임의의 기저(Arbitrary Basis) 문제
Residual Stream 은 밀집 가중치 행렬(Dense weight matrices)에 의해 변환되기 때문에 (네트워크의 용량을 변경하지 않고도 임의로 회전할 수 있음), 개별 기저 차원(문자 그대로의 뉴런 )이 깔끔한 단일 개념과 일치하는 경우는 드뭅니다.
이로 인해 Polysemanticity (다의성) 문제가 발생합니다. 즉, 단일 뉴런이 서로 관련 없는 여러 개념에 대해 활성화되는 현상입니다 (예: “거미”와 “프랑스어” 모두에 반응하는 뉴런). 이를 분리하기 위해 Sparse Autoencoders (SAE) 를 사용하는 방법은 19.4장에서 다루겠지만, 지금은 특징(Feature)은 뉴런이 아니라 방향(Direction)이다 라는 점만 이해하면 됩니다.
3. Circuits and Induction Heads
Circuit (회로) 은 인식 가능한 알고리즘을 구현하는 신경망의 부분 그래프(특정 Attention Head와 MLP 뉴런의 집합)입니다.
LLM 에서 발견된 가장 유명하고 근본적인 회로는 Induction Head (귀납 헤드) 입니다 [3]. Induction Head 는 LLM 이 가중치 업데이트 없이 프롬프트만으로 새로운 패턴을 학습하는 능력인 In-Context Learning (ICL) 에 대한 기계적 설명입니다.
Induction Head 의 알고리즘
Induction Head 는 [A] [B] ... [A] -> [B] 와 같은 단순한 패턴을 찾습니다.
만약 [A] 라는 토큰을 보게 되면, 과거 컨텍스트에서 이전의 [A] 인스턴스를 검색하고, 그 바로 뒤에 온 토큰([B])을 확인한 후, [B] 를 다음 예측 토큰으로 승격시킵니다.
이를 위해서는 서로 다른 레이어에 있는 최소 두 개의 Attention Head 가 조율되어야 합니다:
-
Previous Token Head (Layer ): 이 헤드는 단순히 현재 토큰 바로 앞의 토큰에 Attention 을 줍니다.
[A]의 정보를[B]의 Residual Stream 위치로 이동시킵니다. 이제 토큰[B]에는 “내 앞에는 A가 있다”라는 특징(Feature)이 포함됩니다. -
Induction Head (Layer , 단 ): 모델이 두 번째
[A]인스턴스를 처리할 때, Induction Head 의 Query () 는 “내 앞에는 A가 있다”라는 특징을 포함하는 Key () 를 검색합니다. 이전의[B]를 찾아 Attention 을 주고, Value () 투영을 통해 “B-ness(B의 정체성)“를 최종 Residual Stream 에 복사하여[B]를 예측합니다.
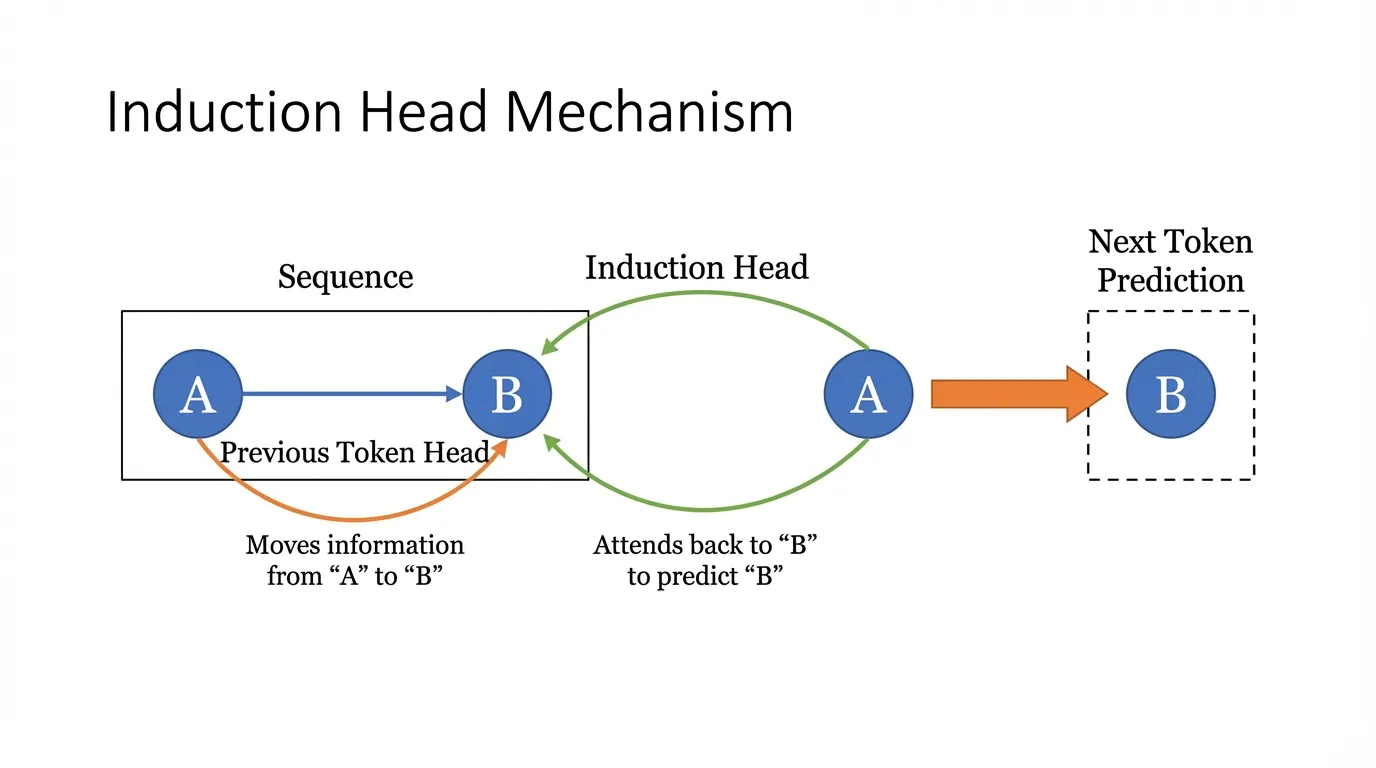 (Source: Olsson et al., 2022 [3])
(Source: Olsson et al., 2022 [3])
QK 와 OV 회로
MechInterp 는 Attention 을 두 개의 독립적인 연산으로 수학적으로 분해합니다:
- The QK Circuit (): 정보를 어디로 이동시킬지 결정합니다 (Attention 가중치).
- The OV Circuit (): Attention 이 주어졌을 때 어떤 정보를 이동시킬지 결정합니다.
Induction Head 의 경우, QK 회로는 “현재 토큰 A”와 “A가 선행된 토큰” 사이의 일치도를 계산합니다. OV 회로는 복사(Copy) 연산으로 작동하여 [B] 의 정체성을 추출하고 출력 Logit 에 씁니다.
4. Engineering the Interception: PyTorch Hooks
Mechanistic Interpretability 를 수행하려면 단순히 최종 Loss 만 봐서는 안 됩니다. 순전파(Forward pass) 중에 중간 활성화 값(Residual Stream, Attention 행렬, MLP 은닉 상태)을 추출해야 합니다.
PyTorch 에서는 register_forward_hook 을 사용하여 이를 우아하게 처리할 수 있습니다. 아래는 Induction Head 를 찾기 위해 Attention 행렬을 가로채고 분석하는 강력한 엔지니어링 패턴입니다.
import torch
import torch.nn as nn
from typing import Tuple
class InterceptHook:
"""
중간 활성화 값을 캡처하기 위해 재사용 가능한 PyTorch Hook 클래스입니다.
"""
def __init__(self, module: nn.Module):
self.activations = None
self.hook_handle = module.register_forward_hook(self._hook_fn)
def _hook_fn(self, module: nn.Module, input: Tuple[torch.Tensor], output: torch.Tensor):
# MultiheadAttention은 일반적으로 (attn_output, attn_weights)를 반환합니다.
# 우리는 attn_weights를 캡처하고자 합니다 (shape: batch_size, num_heads, seq_len, seq_len)
if isinstance(output, tuple) and len(output) == 2:
self.activations = output[1].detach().cpu()
else:
self.activations = output.detach().cpu()
def remove(self):
self.hook_handle.remove()
def analyze_attention_patterns(
model: nn.Module,
input_ids: torch.Tensor,
layer_idx: int
) -> torch.Tensor:
"""
순전파를 실행하고 특정 레이어의 Attention 행렬을 추출합니다.
"""
# 일반적인 HuggingFace/PyTorch Transformer 아키텍처 명명 규칙을 가정
target_module = model.transformer.h[layer_idx].attn
# Hook 등록
hook = InterceptHook(target_module)
# 순전파 (해석 가능성 추출을 위해 Gradient는 필요하지 않음)
with torch.no_grad():
_ = model(input_ids)
# 캡처된 Attention 가중치 회수
attn_weights = hook.activations
hook.remove()
return attn_weights
# 사용 예시 (시뮬레이션):
# input_ids 형태: [1, seq_len], "Harry Potter is a wizard. Harry Potter"를 나타냄
# attn_weights 형태: [1, num_heads, seq_len, seq_len]
#
# Induction Head를 찾으려면 'attn_weights'에서 두 번째 "Harry"에 해당하는 행이
# 첫 번째 "Potter"에 해당하는 열에서 높은 값을 가지는 Head를 찾으면 됩니다.반복되는 시퀀스로 구성된 대규모 데이터셋에 대해 모든 레이어와 헤드에 걸쳐 이러한 훅(Hooks)을 집계함으로써, 연구자들은 어떤 헤드가 In-Context Learning 을 담당하는지 체계적으로 매핑할 수 있습니다.
5. Interactive: Visualizing an Induction Head
Induction Head 가 어떻게 작동하는지 확실히 이해하기 위해 아래의 Attention 행렬과 상호작용해 보세요. 이 시각화 도구는 반복되는 시퀀스를 처리하는 Induction Head 의 Attention 가중치를 시뮬레이션합니다.
토큰의 두 번째 등장에 대한 Query 가 첫 번째 등장 다음 에 오는 토큰에 어떻게 강하게 Attention 을 주는지 주목하십시오.
Induction Head Attention Matrix
How to read: Rows are Query (current token), columns are Key (attended token).
Notice how the second "Harry" (Row 6) strongly attends to the first "Potter" (Col 2). This is the induction mechanism predicting the next token.
(실제 모델에서 Attention 행렬은 더 노이즈가 많지만, 뚜렷한 대각선 오프셋 패턴은 Induction Head 의 틀림없는 특징으로 남아 있습니다.)
6. 최신 흐름: Feature에서 Circuit Tracing으로
초기의 MechInterp는 개별 head나 작은 회로를 사람이 직접 찾는 작업에 가까웠습니다. 2024년 이후에는 Sparse Autoencoder(SAE)로 모델 내부 feature를 대량으로 찾고, 2025년에는 Anthropic의 circuit tracing처럼 feature 사이의 attribution graph를 구성하는 방향이 강해졌습니다 [5].
이 변화는 중요합니다. “모델 안에 Golden Gate Bridge feature가 있다”는 발견은 흥미롭지만, 실제 안전성에는 한 단계 더 필요합니다. 그 feature가 어떤 입력에서 켜지고, 어떤 다른 feature를 활성화하며, 최종 출력 logit에 어떻게 기여하는지 연결해야 합니다. 즉, 해석 가능성의 단위가 뉴런 → feature → feature graph/circuit 으로 이동하고 있습니다.
개발자가 바로 쓸 수 있는 MechInterp 워크플로우
모델 연구팀이 아니더라도 다음 상황에서는 해석 가능성 도구가 실무적인 도움을 줍니다.
- 반복되는 환각 디버깅: 특정 엔티티나 숫자에서 자주 틀릴 때, 중간 레이어에서 언제 잘못된 후보가 강해지는지 logit lens로 봅니다.
- Refusal 회귀 분석: 새 safety tuning 이후 정상 요청을 과잉 거부한다면, refusal 관련 feature나 activation direction이 너무 쉽게 켜지는지 확인합니다.
- Prompt template 비교: 두 프롬프트 중 하나가 더 안정적이라면, induction pattern, attention sink, evidence token attention이 어떻게 달라지는지 비교합니다.
- RAG 근거 사용 여부 확인: 답변 토큰이 실제 근거 문서 토큰에서 정보를 가져오는지, 아니면 parametric memory에 의존하는지 attention/attribution으로 검사합니다.
- Model editing 사전 점검: 특정 지식을 편집하거나 feature steering을 적용하기 전에, 해당 feature가 다른 중요한 능력과 얽혀 있는지 확인합니다.
아직 이 도구들은 “모든 모델 행동을 완전히 설명한다”기보다, 어려운 버그를 좁혀 보는 현미경에 가깝습니다. 하지만 production incident가 반복될 때는 단순 로그 분석보다 훨씬 많은 단서를 줄 수 있습니다.
7. Summary and Open Questions
Mechanistic Interpretability 는 대규모 언어 모델의 내부 메커니즘을 이해하기 위한 엄밀하고 수학적인 프레임워크를 제공합니다. 네트워크를 Linear Representation Hypothesis, QK/OV 회로, 그리고 Induction Head 와 같은 알고리즘적 부분 그래프로 분해함으로써, 우리는 AI 를 연금술로 취급하던 것에서 벗어나 소프트웨어 공학으로 다룰 수 있게 됩니다.
하지만 모델이 수조 개의 파라미터로 확장됨에 따라, 수동적인 회로 발견은 계산적으로나 인지적으로 불가능해지고 있습니다.
- 회로 발견을 어떻게 자동화할 수 있을까요?
- 모델의 세계 지식 대부분을 포함하고 있는 거대한 MLP 레이어는 어떻게 해석해야 할까요?
- 여러 개념이 동일한 뉴런 세트에 쑤셔 넣어질 때(Superposition) 어떤 일이 발생할까요?
이러한 질문에 답하기 위해, 우리는 다음 장인 19.2 Logit Lens & Attention Visualization 과 19.4 Sparse Autoencoders (SAE) 에서 고급 시각화 기법과 Superposition 문제에 대해 탐구할 것입니다.
Quizzes
Quiz 1: Linear Representation Hypothesis 에 따르면, 왜 개념들이 개별 뉴런이 아니라 Residual Stream 의 방향으로 표현될까요?
Residual Stream 은 밀집 가중치 행렬에 의해 변환되는 연속적인 벡터 공간입니다. 신경망은 고차원 공간에서 거의 직교(Almost-orthogonal)하는 방향들을 활용함으로써, 자신이 가진 차원 수보다 더 많은 특징을 표현(Superposition)할 수 있습니다. 하나의 개념을 단일 기저 벡터(뉴런)에 묶어두는 것은 벡터 공간의 용량을 매우 비효율적으로 사용하는 것입니다.
Quiz 2: 만약 Transformer 에서 위치 인코딩(RoPE 나 Sinusoidal 등)을 완전히 제거한다면, Induction Head 가 여전히 기능할 수 있을까요?
아니요. Induction Head 의 전제 조건인 Previous Token Head 는 어떤 토큰이 “이전” 토큰인지 알기 위해 전적으로 위치 정보에 의존합니다. 위치 인코딩이 없으면 모델은 시퀀스를 Bag of Words 로 취급하게 되어, [A] -> [B] 라는 순차적 관계를 형성하는 것이 불가능해집니다.
Quiz 3: 현재 Mechanistic Interpretability 가 MLP 레이어에 비해 Attention Head 를 역공학하는 데 훨씬 더 성공적인 이유는 무엇일까요?
Attention Head 에는 해석하기 쉬운 자연스러운 병목(Bottleneck)인 Attention 행렬이 있습니다. QK 회로는 어떤 토큰들이 통신하고 있는지 명시적으로 알려주고, OV 회로는 무엇이 통신되고 있는지 알려줍니다. 반면, MLP 레이어는 고도로 다의적인(Polysemantic) 뉴런을 가진 거대하고 밀집된 Key-Value 메모리로 작동하기 때문에, Sparse Autoencoders 와 같은 고급 기술 없이는 특정 논리적 라우팅을 분리해내기가 훨씬 더 어렵습니다.
Quiz 4: OV 및 QK 회로의 맥락에서, 모델이 특정 토큰을 일관되게 복사하는 법을 학습했다면(예: 이름 반복), 어떤 행렬 곱의 고유값(Eigenvalues)이 1에 가까울 가능성이 높을까요?
OV 행렬 () 입니다. OV 회로가 직접적인 복사(Copy) 연산으로 작동한다면, Residual Stream 내에서 해당 토큰 임베딩의 방향을 보존해야 합니다. 따라서 변환 행렬 는 해당 특정 부분 공간에 대해 대략 항등 행렬(Identity matrix)처럼 작동하며, 이는 그 지배적인 고유값이 1에 가까울 것임을 의미합니다.
References
- Olah, C., et al. (2020). Zoom In: An Introduction to Circuits. Distill. Link.
- Elhage, N., et al. (2021). A Mathematical Framework for Transformer Circuits. Anthropic. Link.
- Olsson, C., et al. (2022). In-context Learning and Induction Heads. arXiv:2209.11895.
- Park, K., et al. (2023). The Linear Representation Hypothesis and the Geometry of Large Language Models. arXiv:2311.03658.
- Ameisen, E., et al. (2025). Circuit Tracing: Revealing Computational Graphs in Language Models. Transformer Circuits Thread. Link.