12.1 KV Cache Management
멀티모달 아키텍처가 파운데이션 모델이 생성할 수 있는 내용(what) 의 한계를 넓히는 동안, 이러한 거대 모델을 프로덕션 환경에 배포하는 것은 가혹한 엔지니어링 현실을 마주하게 합니다. 학계의 연구실에서 데이터센터 규모의 서비스 환경으로 넘어갈 때, 시스템의 병목(bottleneck)은 순수한 연산 성능(TFLOPS)에서 메모리 대역폭(Memory Bandwidth)과 용량(Capacity)으로 급격히 이동합니다. 그리고 이 병목의 중심에는 기하급수적으로 팽창하는 단 하나의 데이터 구조, 바로 KV Cache 가 자리 잡고 있습니다.
대규모 언어 모델(LLM)을 서빙하는 것이 전통적인 마이크로서비스를 서빙하는 것과 근본적으로 어떻게 다른지 이해하려면, 자기회귀적 디코딩(Autoregressive decoding)의 메커니즘, HBM(High Bandwidth Memory)의 물리적 한계, 그리고 메모리 장벽(Memory Wall)을 극복하기 위해 엔지니어들이 도입한 아키텍처적 기법들을 깊이 파고들어야 합니다.
1. The Autoregressive Bottleneck
LLM 추론은 두 개의 뚜렷하게 구분되는 단계로 작동합니다:
- The Prefill Phase (프리필 단계): 모델이 입력 프롬프트 전체를 동시에 처리합니다. 이 단계는 고도로 병렬화되어 있으며, 연산 바운드(compute-bound) 상태로 최신 GPU의 거대한 행렬 곱셈 연산 능력을 최대한 활용합니다.
- The Decode Phase (디코드 단계): 모델이 한 번에 하나의 토큰씩 출력을 생성합니다. 토큰 은 부터 까지의 모든 토큰의 컨텍스트에 의존하기 때문에, 이 과정은 엄격하게 순차적(sequential)입니다.
만약 새로운 토큰이 생성될 때마다 순진하게 self-attention을 계산한다면, 모델은 시퀀스 내의 모든 이전 토큰들을 Query (Q), Key (K), Value (V) 텐서로 다시 투영(projection)한 뒤 어텐션을 계산해야 합니다. 이는 생성 단계마다 의 시간 복잡도를 유발합니다. 4,000 토큰의 응답을 생성한다고 가정할 때, 이러한 중복 연산은 천문학적으로 느린 속도를 초래합니다.
해결책: 새로운 토큰을 생성할 때, 이전 모든 토큰들의 Key와 Value 벡터는 변하지 않습니다. 이러한 K와 V 텐서를 GPU 메모리에 캐싱해두면, 모델은 오직 현재 토큰에 대한 Q, K, V만 계산하면 됩니다. 그런 다음 현재의 Q를 캐싱된 K, V 행렬과 곱합니다. 이 최적화는 단계당 시간 복잡도를 에서 으로 줄여주며, 실시간 채팅을 가능하게 만듭니다.
하지만 이 속도 향상은 막대한 비용, 즉 메모리를 대가로 합니다.
2. The Mathematics of the Memory Wall
KV Cache 는 결코 작은 버퍼가 아닙니다. 그것은 종종 모델의 가중치(weights) 크기를 초과할 정도로 거대하고 동적으로 성장하는 메모리 할당 영역입니다.
표준 Multi-Head Attention (MHA) 모델의 경우, 단일 요청에 대한 KV Cache 를 저장하는 데 필요한 정확한 메모리 공간(바이트 단위)은 다음 공식에 의해 결정됩니다:
여기서:
- : Key와 Value 텐서 두 개를 모두 고려.
- : Batch size (동시 요청 수).
- : Sequence length (과거 토큰의 수).
- : Transformer 레이어 수.
- : Attention Heads (KV 헤드) 수.
- : 헤드당 차원(Dimension).
- : 정밀도 바이트 수 (예: FP16/BF16의 경우 2바이트).
이 공식을 이론적인 70B 파라미터 모델(80 레이어, 8 KV 헤드 (GQA 가정), 128 차원)에 적용하여, 8,192 토큰 컨텍스트를 가진 32명의 사용자를 FP16 정밀도로 서빙한다고 가정해 봅시다:
단일 NVIDIA H100 GPU는 80 GB의 HBM을 가집니다. 위 시나리오에서 KV Cache 만으로도 GPU 메모리 전체를 소비하게 되며, 140 GB에 달하는 모델 가중치를 올릴 공간조차 남지 않게 됩니다. 이를 Memory Wall (메모리 장벽) 이라고 부릅니다. 디코드 단계는 악명 높을 정도로 메모리 대역폭 바운드(memory-bandwidth bound) 상태입니다. 생성되는 매 토큰마다 이 거대한 KV 텐서들이 HBM에서 SRAM으로 스트리밍되기를 기다리며 GPU의 연산 코어들은 유휴 상태(idle)로 방치됩니다.
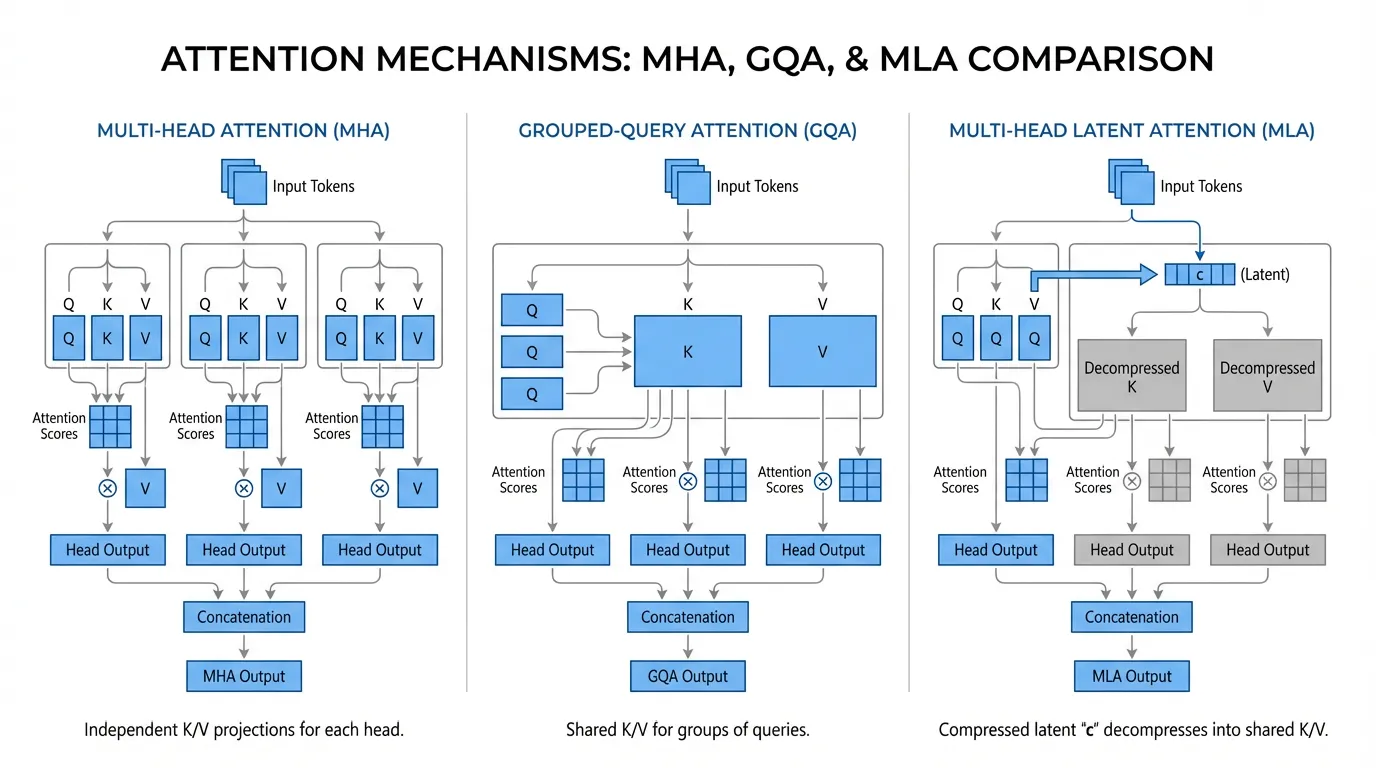
3. Architectural Evolution: MHA, GQA, and MLA
Memory Wall을 완화하기 위해 연구자들은 핵심 Transformer 아키텍처를 공격적으로 수정하여 공식의 (KV 헤드 수) 변수를 줄이는 데 집중했습니다.
 Source: Generated by Gemini
Source: Generated by Gemini
Multi-Query Attention (MQA) & Grouped-Query Attention (GQA)
2023년경 도입된 MQA 는 모든 Query 헤드가 단 하나의 KV 헤드를 공유하도록 강제합니다. 이는 캐시 크기를 최대 64배까지 줄여주지만, 모델의 추론 능력을 심각하게 저하시킵니다.
이에 따라 업계 표준은 빠르게 Grouped-Query Attention (GQA) (Llama 2/3, Mistral 등에서 사용)으로 이동했습니다. GQA는 Query 헤드들을 그룹(예: 8개 그룹)으로 나누고, 각 그룹당 하나의 KV 헤드를 할당합니다. 이는 벤치마크 성능 저하를 거의 발생시키지 않으면서도 실용적인 8배의 메모리 감소 효과를 제공합니다.
Multi-Head Latent Attention (MLA): The 최신 동향
DeepSeek (V2, V3, R1) [1] 에 의해 개척된 Multi-Head Latent Attention (MLA) 는 KV Cache 의 경제학을 완전히 재정의했습니다. 고차원의 K와 V 행렬을 캐싱하는 대신, MLA는 입력을 고도로 압축된 저차원 잠재 벡터(latent vector) (예: 512 차원)로 투영합니다.
추론 과정에서는 오직 이 작은 잠재 벡터만이 캐시에 저장됩니다.
행렬 흡수(Matrix Absorption)의 마법: 디코드 단계에서 모델이 메모리로부터 를 읽어와 업-프로젝션(up-projection) 행렬과 곱해 완전한 멀티 헤드 K와 V 텐서를 재구성해야 한다면 연산 비용이 매우 클 것이라고 생각할 수 있습니다. 그러나 MLA는 행렬 흡수(Matrix Absorption) 라는 수학적 트릭을 활용합니다. 어텐션 점수(attention score)는 내적(dot product)으로 계산되기 때문에, Keys를 위한 압축 해제 행렬()은 Query 투영 행렬()로 수학적으로 흡수될 수 있습니다.
흡수된 행렬 을 미리 계산(pre-compute)해 둠으로써, 어텐션 커널은 HBM에서 가져온 원시 압축 잠재 벡터 와 투영된 Query 간의 내적을 직접 계산할 수 있습니다. 고차원의 Key 행렬은 메모리에 전혀 구체화(materialized)되지 않습니다.
참고: 선형적으로 흡수될 수 없는 Rotary Position Embeddings (RoPE)를 처리하기 위해, MLA는 잠재 벡터와 함께 작고 분리된 RoPE 벡터 (예: 64 차원)를 명시적으로 캐싱합니다.
이를 통해 표준 MHA와 비교하여 KV Cache 의 메모리 풋프린트를 무려 20배에서 57배 까지 줄일 수 있으며, 더 적은 수의 GPU로도 긴 컨텍스트 요청의 대규모 배치를 서빙할 수 있게 됩니다.
Interactive KV Cache Calculator
Adjust the parameters below to see how architectural choices impact the memory footprint of the KV Cache.
Total KV Cache Size:
Calculation: $2 \times 32 \times 8192 \times 80 \times 8 \times 128 \times 2 \text{ bytes}$
4. Data-Level Compression: Quantization
아키텍처 변경을 넘어, 엔지니어들은 공식의 (정밀도, Precision) 변수도 공략합니다. 기본적으로 KV Cache 는 16비트 정밀도(FP16 또는 BF16, 파라미터당 2바이트)로 저장됩니다.
최신 추론 엔진(vLLM, TensorRT-LLM 등)은 네이티브하게 KV Cache 양자화(Quantization) 를 지원합니다. 캐시를 FP8 (1바이트) 또는 심지어 INT4 (0.5바이트)로 압축함으로써 메모리 풋프린트를 절반 또는 4분의 1로 줄입니다.
디코드 단계는 메모리 대역폭 바운드 상태이므로, HBM에서 INT4 KV Cache 를 읽어오는 것은 FP16 캐시를 읽어오는 것보다 최대 4배 빠릅니다. SRAM 내부에서 INT4 값을 다시 FP16으로 역양자화(dequantize)하는 데 필요한 약간의 연산 오버헤드는, 메모리 전송 시간의 막대한 감소에 의해 완전히 상쇄(hidden)됩니다. 이는 결과적으로 토큰 생성 처리량(tokens/sec)의 직접적이고 거의 선형적인 증가로 이어집니다.
5. Engineering the Cache
개념을 명확히 하기 위해, 아래는 GQA를 지원하고 동적 KV Cache 를 유지하는 현실적인 PyTorch Transformer 어텐션 레이어 구현체입니다. 시퀀스 차원(dim=1)을 따라 과거 히스토리 텐서에 현재 토큰의 상태를 이어 붙임(torch.cat)으로써 과거 토큰의 재계산을 피하는 캐시 메커니즘을 주목하십시오.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
"""
Grouped-Query Attention (GQA) 및 자기회귀적 디코딩을 위한
KV Caching을 지원하는 현실적인 Transformer 어텐션 레이어 구현체.
"""
def __init__(self, d_model=4096, n_heads=32, n_kv_heads=8):
super().__init__()
self.n_heads = n_heads
self.n_kv_heads = n_kv_heads
self.d_head = d_model // n_heads
# Projections
self.q_proj = nn.Linear(d_model, n_heads * self.d_head, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * self.d_head, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * self.d_head, bias=False)
self.o_proj = nn.Linear(d_model, d_model, bias=False)
def forward(self, x, kv_cache=None):
# x shape: (Batch, Seq_Len, Dim)
B, T, C = x.size()
q = self.q_proj(x).view(B, T, self.n_heads, self.d_head)
k = self.k_proj(x).view(B, T, self.n_kv_heads, self.d_head)
v = self.v_proj(x).view(B, T, self.n_kv_heads, self.d_head)
if kv_cache is not None:
past_k, past_v = kv_cache
# KV Caching의 핵심: 과거 히스토리와 현재 토큰을 이어 붙임(Concatenate)
k = torch.cat([past_k, k], dim=1)
v = torch.cat([past_v, v], dim=1)
# 다음 자기회귀적 단계를 위해 캐시 페이로드 업데이트
new_kv_cache = (k, v)
# GQA: Q 헤드 수에 맞추기 위해 K와 V 헤드를 반복(repeat)
groups = self.n_heads // self.n_kv_heads
k = k.repeat_interleave(groups, dim=2)
v = v.repeat_interleave(groups, dim=2)
# PyTorch 어텐션 계산을 위한 Transpose: (Batch, Heads, Seq_Len, Dim)
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
# Decode 중(T=1)에는 인과적 마스킹(causal masking)이 캐시 구조에 의해 암시적으로 처리됩니다.
# Prefill 중(T>1)에는 인과적 마스크를 적용해야 합니다.
is_causal = T > 1
# 하드웨어 가속이 지원되는 Flash Attention 활용
y = F.scaled_dot_product_attention(q, k, v, is_causal=is_causal)
# 평탄한 시퀀스로 다시 형태 변환(Reshape): (Batch, Seq_Len, Dim)
y = y.transpose(1, 2).contiguous().view(B, T, C)
return self.o_proj(y), new_kv_cache6. The Fragmentation Problem (A Look Ahead)
위의 코드는 연속적인 PyTorch 텐서를 할당하고 매 단계마다 이어 붙이는(torch.cat) 순진한(naive) 전략을 사용합니다. 수백 개의 동시 요청을 처리하는 프로덕션 서버에서 이 접근 방식은 재앙에 가깝습니다.
사용자 프롬프트의 최종 시퀀스 길이를 시작 시점에서는 알 수 없기 때문에, 시스템은 메모리를 과도하게 할당(캐시 용량의 최대 80% 낭비)하거나 텐서를 지속적으로 재할당하고 이동시켜 심각한 메모리 단편화(fragmentation)를 유발하게 됩니다. 이러한 OS 수준의 메모리 관리 문제를 해결하는 것이 바로 다음 섹션에서 살펴볼 PagedAttention 의 영역입니다.
7. Summary
KV Cache 를 관리하는 것은 LLM 추론에서 가장 중요한 엔지니어링 과제입니다. 과거의 Key와 Value 상태를 캐싱함으로써 텍스트 생성의 연산 복잡도를 이차(quadratic)에서 선형(linear)으로 낮출 수 있습니다. 그러나 이 최적화는 병목 현상을 메모리 용량과 대역폭으로 이동시킵니다. Grouped-Query Attention (GQA), DeepSeek의 Multi-Head Latent Attention (MLA), 그리고 INT4 양자화와 같은 혁신적인 기술들은 제한된 GPU 하드웨어에 거대한 컨텍스트 윈도우를 적재하기 위한 필수적인 도구입니다.
Quizzes
Quiz 1: KV Cache 없이 자기회귀적(autoregressive) 생성을 수행할 경우 왜 단계당 의 시간 복잡도가 발생하는가?
캐시가 없으면 번째 토큰을 생성할 때마다 이전 개의 모든 토큰에 대해 투영(projection) 및 어텐션 점수 계산을 처음부터 다시 수행해야 합니다. 이러한 전체 시퀀스 계산이 매 생성 단계마다 발생하기 때문에 개의 토큰을 생성하는 총 시간은 기하급수적(이차 함수형)으로 증가합니다.
Quiz 2: KV Cache 메모리 공식에서 풋프린트에 2를 곱하는 이유는 무엇인가?
시퀀스 내의 모든 토큰에 대해 Key (K) 행렬과 Value (V) 행렬 두 가지를 모두 저장해야 한다는 사실을 반영하기 위해 2를 곱합니다.
Quiz 3: DeepSeek의 Multi-Head Latent Attention (MLA)는 추론 중 고차원의 Key 행렬이 메모리에 구체화(materializing)되는 것을 어떻게 방지하는가?
MLA는 저차원의 잠재 벡터(latent vector)를 캐시에 저장합니다. 행렬 흡수(Matrix Absorption)라는 수학적 기법을 통해 Key 압축 해제 행렬을 Query 투영 행렬에 직접 흡수시킵니다. 이를 통해 어텐션 커널은 HBM에서 가져온 원시 압축 잠재 벡터와 투영된 Query 간의 내적을 계산할 수 있어, 완전한 Key 행렬을 생성할 필요를 우회합니다.
Quiz 4: INT4 양자화를 사용하여 KV Cache 메모리를 줄일 경우, 디코드 단계에서 발생하는 주요 하드웨어 트레이드오프(trade-off)는 무엇인가?
디코드 단계는 극도로 메모리 대역폭 바운드(memory-bandwidth bound) 상태이므로, GPU는 대부분의 시간을 HBM에서 SRAM으로 데이터를 전송하는 데 기다리며 보냅니다. INT4 양자화는 SRAM 내부에서 값을 FP16으로 다시 역양자화하기 위한 약간의 연산 오버헤드를 발생시키지만, 데이터 전송에 걸리는 시간을 획기적으로 줄여줍니다. 따라서 이 트레이드오프는 매우 유리하게 작용하여 토큰 생성 처리량을 크게 높여줍니다.
Quiz 5: 개의 레이어, 히든 차원 , 개의 Query 헤드, 개의 Key-Value 헤드(Grouped-Query Attention), 시퀀스 길이 , 배치 크기 를 가지며 float16 정밀도를 사용하는 LLM에 대해 정확한 KV 캐시 메모리 풋프린트(기가바이트(GB) 단위) 수학적 유도 공식을 도출하시오.
GQA (Grouped-Query Attention)에서 Key 및 Value 벡터의 차원은 비율만큼 감소합니다. KV 헤드당 차원은 입니다. 따라서 각 토큰은 레이어당 개의 파라미터를 필요로 합니다. float16 정밀도를 사용할 때 각 파라미터는 2바이트를 소비합니다. 배치 크기 및 시퀀스 길이 에 대해 바이트 단위의 총 메모리는 바이트가 됩니다. 이를 기가바이트(GB)로 변환하려면 (또는 )으로 나눕니다. 결과적으로 GB 단위의 유도 공식은 GB 입니다. 시퀀스 길이 에 정확히 선형적으로 비례하는 이러한 특성은 왜 긴 문맥 서빙에서 메모리 관리가 가장 중요한 과제가 되는지를 명확히 해줍니다.
References
- DeepSeek-AI (2025). DeepSeek-V3 Technical Report. arXiv:2412.19437
- Ainslie, J., et al. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv:2305.13245