3.4 레이어 정규화 및 잔차
깊은 트랜스포머를 구축하려면 셀프 어텐션 이상의 것이 필요합니다. 안정적인 학습을 보장하고 네트워크가 수백 개의 레이어로 성장할 수 있도록 두 가지 중요한 구성 요소가 사용됩니다. 바로 레이어 정규화(Layer Normalization) 와 잔차 연결(Residual Connections) 입니다.
동기: 깊은 네트워크의 딜레마
신경망에 더 많은 레이어를 쌓을수록:
- 공변량 변화 (Covariate Shift): 학습 중에 깊은 레이어에 대한 입력 분포가 계속 바뀌어 학습이 어려워집니다.
- 열화 문제 (Degradation Problem): 레이어를 더 많이 추가하면 과적합 때문이 아니라 그래디언트가 너무 많은 레이어를 통과하는 데 어려움을 겪기 때문에 오히려 학습 오차가 높아질 수 있습니다.
레이어 정규화와 잔차는 딥러닝이 실제로 대규모로 작동하도록 만드는 안정화 기둥입니다.
비유: 합창단과 지름길
당신이 대규모 합창단을 이끌고 있다고 상상해 보세요.
- 레이어 정규화는 볼륨 컨트롤러와 같습니다. 어떤 가수는 소리를 지르고 다른 가수는 속삭이면 화음이 깨집니다. 레이어 정규화는 각 단계에서 모든 사람의 볼륨이 표준적이고 제어된 수준이 되도록 조정합니다. 신호가 폭주하거나 사라지는 것을 방지합니다.
- 잔차 연결은 구불구불한 골목길 옆에 고속도로를 건설하는 것과 같습니다. 도시의 시작부터 끝까지 메시지를 보내고 싶은데, 모든 골목길(레이어)을 거쳐 가려면 시간이 오래 걸리고 메시지가 손실될 수 있습니다. 잔차 연결은 메시지가 왜곡 없이 직접 이동할 수 있는 고속도로(스킵 연결)를 제공합니다.
잔차 연결: 고속도로
ResNet (He et al., 2015) [1]에서 도입된 잔차 연결(Residual Connections)은 단순히 서브 레이어의 입력을 그 출력에 더하는 것입니다.
비하인드 스토리: 2015년 Kaiming He 등이 ResNet을 제안했을 때, 그들은 신경망에 층을 더 많이 쌓을수록 오히려 학습 오차가 높아지는 현상(Degradation Problem)에 주목했습니다. 이는 상식에 반하는 결과였습니다. 그들은 단순히 입력을 출력에 더해주는 ‘잔차 연결’이라는 기발한 아이디어로 이 문제를 해결했고, 이로 인해 100층이 넘는 깊은 네트워크를 학습할 수 있게 되었습니다.
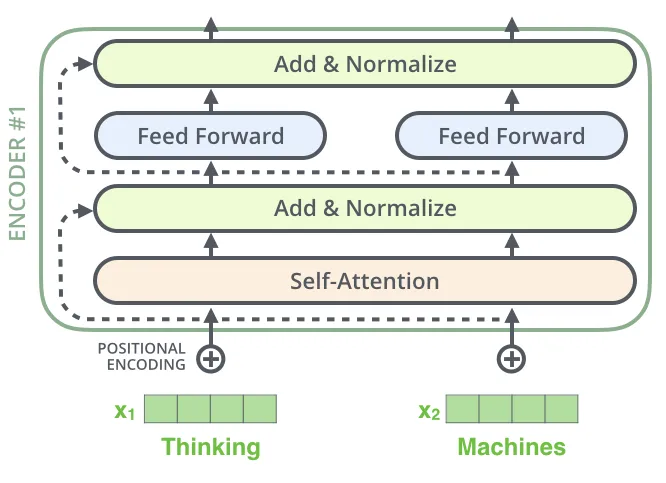
이 단순한 덧셈 연산은 역전파 중에 서브 레이어의 복잡한 비선형성을 우회하여 그래디언트가 항등 매핑()을 통해 직접 흐를 수 있도록 합니다. 이는 극도로 깊은 네트워크에서 발생하는 기울기 소실 문제를 효과적으로 해결합니다.
레이어 정규화: 안정성 유지
배치 차원에 대해 통계량을 계산하는 배치 정규화(Batch Normalization)와 달리, 레이어 정규화 (Ba et al., 2016) [2]는 각 학습 사례에 대해 독립적으로 피처에 걸쳐 입력을 정규화합니다.
차원의 벡터 에 대해:
여기서 와 는 학습 가능한 파라미터이고, 은 수치적 안정성을 위한 작은 상수입니다. 레이어 정규화는 가변적인 시퀀스 길이와 작은 배치 크기에서도 잘 작동하기 때문에 NLP에서 선호됩니다.
PyTorch 구현
다음은 표준 트랜스포머 블록에서 이들이 어떻게 결합되는지 보여줍니다.
import torch
import torch.nn as nn
class TransformerSublayer(nn.Module):
def __init__(self, d_model):
super(TransformerSublayer, self).__init__()
self.norm = nn.LayerNorm(d_model)
# 시뮬레이션된 서브 레이어 (예: 셀프 어텐션 또는 피드 포워드)
self.sublayer = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
# Post-LN 아키텍처 (원래 논문에서와 같이)
# 1. 서브 레이어 연산
out = self.sublayer(x)
# 2. 드롭아웃 및 잔차 추가
out = x + self.dropout(out)
# 3. 레이어 정규화
out = self.norm(out)
return out
# 사용 예시
d_model = 64
layer = TransformerSublayer(d_model)
x = torch.randn(2, 10, d_model)
output = layer(x)
print("출력 형태:", output.shape)[!NOTE] 현대 트랜스포머는 종종 서브 레이어 이전에 정규화가 수행되는 Pre-LN 을 사용합니다:
x + sublayer(norm(x)). 이 방식이 훨씬 더 안정적인 것으로 밝혀졌습니다.
Pre-LN vs. Post-LN: 아키텍처의 변화
원래 트랜스포머 논문은 레이어 정규화를 잔차 추가 이후에 배치했습니다 (Post-LN). 그러나 대부분의 현대 트랜스포머(예: GPT-2, GPT-3, Llama)는 Pre-LN을 사용합니다. 이 둘을 비교해 봅시다:
Post-LN (원본)
- 장점: 각 레이어의 출력이 잘 정규화되어 있어, 성공적으로 학습된다면 더 좋은 성능을 낼 수 있습니다.
- 단점: 초기화 시 그래디언트가 불안정해질 수 있어, 신중한 학습률 웜업(warm-up) 스케줄이 필요합니다. 깊어질수록 은닉 상태의 분산이 증가합니다.
Pre-LN (현대 표준)
- 장점: 학습이 훨씬 더 안정적입니다. 그래디언트가 정규화 레이어에 의해 변형되지 않고 잔차 연결을 통해 직접 흐를 수 있습니다. 이를 통해 복잡한 웜업 스케줄 없이도 훨씬 더 깊은 네트워크를 학습할 수 있습니다.
- 단점: 항등(identity) 분기에 직접 더해지기 때문에 주의하지 않으면 표현 붕괴(representation collapse)가 발생할 수 있지만, 실제로는 매우 잘 작동합니다.
연구원들은 Post-LN에서 입력에 가까운 레이어의 기대 그래디언트 노름(norm)이 출력에 가까운 레이어보다 훨씬 작아서 기울기 소실로 이어진다는 것을 발견했습니다. Pre-LN은 그래디언트 노름이 모든 레이어에 걸쳐 잘 유지되도록 보장함으로써 이 문제를 해결합니다.
예제: 정규화 효과
레이어 정규화가 거친 값들을 가진 벡터를 어떻게 평균 0, 분산 1의 정규화된 분포로 변환하는지 확인해 보세요.
Quizzes
Quiz 1: 왜 NLP에서는 배치 정규화보다 레이어 정규화가 선호됩니까?
배치 정규화는 배치 차원에 대해 통계량을 계산합니다. NLP에서 시퀀스는 종종 가변적인 길이를 가지므로 배치 통계량이 불안정해집니다. 또한 대규모 모델의 메모리 제약으로 인해 종종 사용되는 작은 배치 크기는 배치 정규화를 부정확하게 만듭니다. 레이어 정규화는 각 토큰에 대해 독립적으로 피처에 걸쳐 통계량을 계산하므로 배치 크기와 시퀀스 길이에 영향을 받지 않습니다.
Quiz 2: 잔차 연결은 어떻게 기울기 소실 문제를 해결합니까?
잔차 블록 에서 입력에 대한 도함수는 항등 매핑으로부터 항을 포함합니다 (즉, ). 이 항은 의 도함수가 매우 작더라도 그래디언트가 직접 역전파될 수 있도록 보장하여 그래디언트가 소실되는 것을 방지합니다.
Quiz 3: Pre-LN과 Post-LN 아키텍처의 차이점은 무엇입니까?
Post-LN(원래 트랜스포머)에서는 잔차 추가 이후에 정규화가 적용됩니다: . Pre-LN에서는 서브 레이어 이전에 입력에 정규화가 적용되고 그 출력이 원래 입력에 더해집니다: . Pre-LN은 웜업(warm-up) 없이 매우 깊은 네트워크를 학습하는 데 더 안정적인 것으로 밝혀졌습니다.
Quiz 4: 레이어 정규화에서 왜 학습 가능한 파라미터 와 가 필요합니까?
와 가 없다면 레이어 정규화는 활성화 값이 항상 평균 0, 분산 1을 갖도록 강제할 것입니다. 이는 네트워크의 표현력을 제한할 수 있습니다. 학습 가능한 파라미터를 통해 네트워크는 정규화된 값을 학습에 가장 적합한 분포로 스케일링하고 이동할 수 있으며, 필요하다면 정규화를 “취소”할 수도 있습니다.
Quiz 5: Post-LN 공식 에서 왜 깊이에 따라 분산이 증가합니까?
정규화 전에 서브 레이어의 출력이 입력에 더해지기 때문에, 합의 분산은 분산들의 합이 됩니다(독립을 가정할 때). 깊어질수록 이러한 덧셈이 누적되어 다음 LayerNorm에 의해 찌그러지기 전에 은닉 상태의 크기가 커지게 됩니다. 이는 최적화를 더 어렵게 만듭니다.
Quiz 6: 서브레이어의 출력 의 분산을 이라고 가정할 때, Post-LN 및 Pre-LN 아키텍처에서 레이어 에서의 은닉 상태 의 분산을 수학적으로 유도하고 이의 구조적 차이를 기술하시오.
레이어 정규화가 없는 표준 잔차 연결에서는 독립성을 가정할 때 분산이 로 전달됩니다. Post-LN의 경우: 입니다. LayerNorm이 매 단계마다 분산을 1로 복원하므로 다음 레이어로 진입하는 분산은 항상 1이지만, 정규화 직전의 은닉 상태 스케일은 선형적으로 증가합니다: . 반면 Pre-LN의 경우: 입니다. 따라서 깊이에 따라 분산이 선형적으로 증가합니다: 。 Pre-LN은 변형되지 않은 항등 연결(Identity Branch)을 유지하기 때문에, 역전파되는 기울기의 스케일이 깊이 에 무관하게 유지되어 Warm-up 없이도 안정적인 학습이 가능합니다.
References
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
- Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv:1607.06450.