5.4 Collapsing & Load Balancing (전문가 붕괴와 부하 분산)
이전 섹션들에서 우리는 라우팅의 수학적 우아함과 전문가 병렬화(Expert Parallelism)의 시스템적 필요성을 탐구했습니다. 하지만 우리는 동시에 한 가지 치명적인 취약점도 발견했습니다. Mixture of Experts (MoE) 모델은 본질적으로 불안정하다는 것입니다.
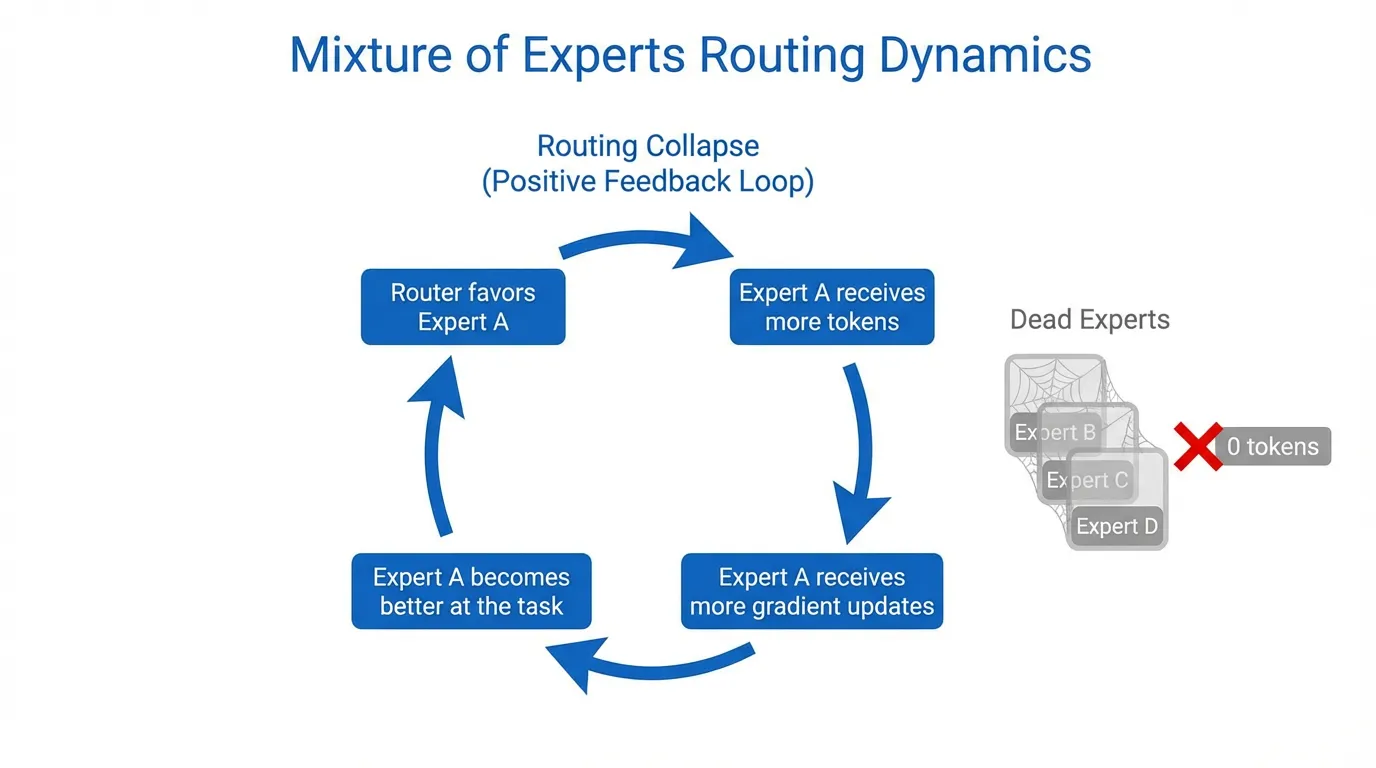
라우터를 그대로 방치하면 필연적으로 “마태 효과(The Matthew Effect, 부익부 빈익빈)“에 굴복하게 됩니다. 만약 특정 전문가가 다른 전문가들보다 아주 조금이라도 더 잘 초기화되어 있다면, 라우터는 그 전문가에게 더 많은 토큰을 보낼 것입니다. 이 전문가는 더 많은 그래디언트를 받아 더 빨리 개선되고, 결과적으로 훨씬 더 많은 토큰을 끌어당기게 됩니다. 몇 번의 학습 단계 내에 전체 모델은 단 하나의 전문가로 “붕괴(Collapse)“하며, 조 단위 파라미터의 희소 모델을 훨씬 작은 밀집 모델로 전락시킵니다. 이때 나머지 파라미터와 GPU들은 유휴 상태로 방치됩니다.
이러한 파괴적인 과소 활용을 방지하기 위해 MoE 엔지니어링은 일련의 로드 밸런싱(Load Balancing, 부하 분산) 전략에 의존합니다. 이 섹션에서는 희소 모델을 균형 있고 안정적으로 유지하는 안전장치들을 분석합니다.
1. 전문가 붕괴(Expert Collapse) 현상
전문가 붕괴는 단순한 성능 문제가 아니라, 분산 시스템에서 하드웨어 성능을 저하시키는 치명적인 사건입니다. 라우터가 붕괴되면 다음과 같은 일이 발생합니다.
- VRAM 오버플로우 (OOM): “인기 있는” 전문가를 보유한 GPU가 배치의 모든 토큰을 할당받게 되어, 미리 할당된 메모리 버퍼를 초과하게 됩니다.
- 연산 기아(Compute Starvation): 클러스터 내의 나머지 GPU들은 과부하된 GPU가 작업을 마칠 때까지 유휴 상태로 대기하게 되어, 시스템 처리량이 거의 0에 가깝게 떨어집니다.
- 표현력 퇴화(Representational Degeneracy): 모델이 전문화될 수 있는 능력을 잃게 됩니다. 단 하나의 가중치 세트가 Python 코드부터 프랑스 시까지 모든 시맨틱 개념을 억지로 표현해야 하기 때문입니다.
2. 1세대: 보조 부하 분산 손실 (Auxiliary Load-Balancing Loss)
GShard [1] 에서 도입된 가장 초기이자 널리 사용되는 해결책은 보조 손실(Auxiliary Loss, ) 입니다. 단순히 다음 토큰 예측을 최적화하는 대신, 라우터가 모든 명의 전문가에게 토큰을 균등하게 분배하도록 장려하는 페널티 항을 추가하는 방식입니다.
이 손실은 일반적으로 각 전문가에게 전송된 토큰 비율과 해당 전문가에 대한 평균 라우팅 확률 사이의 스케일링된 내적(Dot product)으로 정의됩니다.
여기서:
- : 전문가 로 배분된 토큰의 비율.
- : 배치 전체에서 전문가 에 대한 평균 라우팅 확률.
- : 균형 제약 조건의 강도를 조절하는 하이퍼파라미터.
치명적인 결함: 보조 손실은 그래디언트 충돌(Gradient Conflict) 을 유발합니다. 모델의 지능이 토큰이 전문가 A로 가야 한다고 판단하더라도, 만약 전문가 A가 이미 가득 찼다면 보조 손실은 라우터가 토큰을 전문가 B로 보내도록 강제합니다. 이러한 “부자연스러운 라우팅”은 모델의 정확도를 능동적으로 저하시키며, 이 현상을 MoE 정렬 세금(MoE Alignment Tax) 이라고 부릅니다.
 Source: Generated by Gemini
Source: Generated by Gemini
3. 인프라 안전장치: 용량 계수(Capacity Factor)와 토큰 드롭핑(Token Dropping)
보조 손실이 있더라도 완벽한 균형이 항상 보장되는 것은 아닙니다. OOM 이벤트로부터 하드웨어를 보호하기 위해 엔지니어들은 용량 계수(Capacity Factor, C) 를 사용합니다.
각 전문가에게는 최대 용량이 할당됩니다.
- 이면 시스템은 여유를 허용하지 않습니다. 전문가는 오직 자신의 “공정한 몫”만큼만 받을 수 있습니다.
- 이면 자연적인 변동을 고려하여 전문가는 평균 몫보다 50% 더 많은 토큰을 받을 수 있습니다.
용량을 초과하면 어떻게 되나요? 초과된 토큰은 버려집니다(Dropped). 이 토큰들은 어떤 전문가에 의해서도 처리되지 않고 잔차 연결()을 통해 그대로 다음 레이어로 전달됩니다. 이는 GPU의 다운을 방지하지만, 모델의 추론 과정에 “사각지대(Dark spots)“를 만들어 롱 컨텍스트(Long-context) 작업에서의 성능을 크게 저하시킵니다.
4. 고급 안정성: 라우터 Z-손실 (Router Z-Loss)
대규모 MoE 학습은 종종 “로짓 표류(Logit Drift)” 현상을 겪습니다. 라우터의 출력값(로짓)이 제어할 수 없이 커져서 수치적 불안정성과 학습 스파이크를 유발하는 현상입니다.
이를 해결하기 위해 Mesh-TensorFlow와 같은 프레임워크는 라우터 Z-손실(Router Z-Loss) [2] 을 도입했습니다. 이는 라우팅 로짓의 절대적인 크기에 페널티를 부여하여 건강한 범위 내로 유지합니다.
이 단순한 정규화 항은 수천억 개의 파라미터를 가진 MoE 모델을 학습시키는 데 필수적인 표준이 되었습니다. 이를 통해 수개월 간의 연속 학습 중에도 라우터가 “얌전하게” 동작하도록 보장합니다.
5. 보조 손실 없는 라우팅 (Auxiliary-Loss-Free Routing)
2024년 말, 연구자들은 고정된 손실 기반의 밸런싱이 항상 모델 지능을 제한한다는 사실을 깨달았습니다. DeepSeek-V3 [3] 는 동적 편향(Dynamic bias)을 사용한 보조 손실 없는 라우팅 을 개척했습니다.
손실 항 대신, 이들은 전문가의 부하를 실시간으로 모니터링하는 컨트롤러(Controller) 를 사용합니다. 특정 전문가가 과소 활용되면 컨트롤러는 해당 전문가의 라우팅 로짓에 작은 양의 편향()을 더합니다. 과다 활용되면 편향을 뺍니다.
승리하는 이유: 편향이 그래디언트에서 분리(Detached) 되어 있기 때문에, 모델의 가중치는 결코 나쁜 라우팅을 배우도록 “강요”받지 않습니다. 라우터는 “순수한” 토큰-전문가 친화도를 학습하고, 편향은 “지저분한” 하드웨어 밸런싱 문제를 별도로 처리합니다.
구현: MoE 로드 밸런싱 및 Z-손실
이 PyTorch 코드 조각은 고전적인 로드 밸런싱 손실과 현대적인 라우터 Z-손실을 계산하는 방법을 보여줍니다.
import torch
import torch.nn.functional as F
def compute_moe_losses(router_logits, top_k_indices, alpha=1e-2, beta=1e-4):
"""
router_logits: [batch_size * seq_len, num_experts]
top_k_indices: [batch_size * seq_len, k]
"""
num_experts = router_logits.size(-1)
num_tokens = router_logits.size(0)
# 1. 보조 부하 분산 손실 (Auxiliary Load Balancing Loss)
# 각 전문가에게 전송된 토큰의 비율(f_i) 계산
expert_mask = F.one_hot(top_k_indices[:, 0], num_classes=num_experts).float()
f_i = expert_mask.mean(dim=0)
# 평균 라우팅 확률(P_i) 계산
probs = F.softmax(router_logits, dim=-1)
P_i = probs.mean(dim=0)
# L_aux = alpha * E * sum(f_i * P_i)
l_aux = alpha * num_experts * torch.sum(f_i * P_i)
# 2. 라우터 Z-손실 (Router Z-Loss)
# 수치적 안정성을 위해 큰 로짓 값에 페널티 부여
log_z = torch.logsumexp(router_logits, dim=-1)
l_z = beta * torch.mean(log_z**2)
return l_aux, l_z
# 사용 예시
logits = torch.randn(1024, 8) # 1024개 토큰, 8명의 전문가
indices = torch.topk(logits, k=1, dim=-1).indices
l_aux, l_z = compute_moe_losses(logits, indices)
print(f"보조 손실: {l_aux.item():.4f}, Z-손실: {l_z.item():.4f}")요약
로드 밸런싱은 MoE 엔지니어링의 “어둠의 예술(Dark art)“과 같습니다. 이는 모델 지능(토큰을 최적의 전문가에게 보내려는 성질)과 시스템 효율성(토큰을 유휴 상태의 전문가에게 보내려는 성질) 사이의 끊임없는 긴장을 나타냅니다. 과거의 경직된 보조 손실부터 현대적인 동적이고 손실 없는 편향에 이르기까지, 목표는 동일합니다. 우리가 비용을 지불한 모든 파라미터가 모델의 지능에 실제로 기여하도록 보장하는 것입니다.
이 장의 마지막 섹션인 5.5 Case Study 에서는 Mixtral부터 거대한 DeepSeek-V3에 이르기까지, 세계에서 가장 성공적인 희소 모델들에서 이러한 개념들이 어떻게 하나로 결합되는지 살펴보겠습니다.
Quizzes
Quiz 1: 로드 밸런싱 메커니즘을 사용하지 않을 때, 학습 과정에서 “부익부 빈익빈” 현상(전문가 붕괴)이 어떻게 발생하는지 설명하십시오.
무작위 초기화에서 시작됩니다. 만약 전문가 A가 특정 토큰 군집에 대해 전문가 B보다 약간이라도 더 낮은 손실을 생성한다면, 라우터의 그래디언트는 해당 토큰들에 대해 전문가 A를 선호하도록 업데이트됩니다. 전문가 A는 이제 더 많은 토큰을 받게 되므로 더 자주 가중치 업데이트를 거치게 되고, 결과적으로 더욱 전문화되고 효율적이 됩니다. 이는 전문가 A가 점점 더 많은 토큰에게 “최적의” 선택지가 되는 양의 피드백 루프를 생성하며, 결국 모든 트래픽을 독점하게 됩니다. 반면 전문가 B는 그래디언트를 전혀 받지 못해 결코 개선되지 않습니다.
Quiz 2: 용량 계수(Capacity Factor)가 1.0인 시스템에서, 대상 전문가의 용량이 가득 차서 토큰이 “버려질(Dropped)” 경우 어떤 결과가 발생하나요? 이것이 장거리 의존성 모델링에 어떤 영향을 미치나요?
버려진 토큰은 일반적으로 MoE 레이어를 완전히 우회합니다. 즉, 해당 레이어에서 토큰의 표현은 순수한 항등 함수(잔차 연결)가 됩니다. 토큰은 비선형 변환이나 정보 처리를 전혀 거치지 못하게 됩니다. 장거리 모델링에서 긴 문장의 주어와 같은 핵심 토큰이 버려지면, 모델은 해당 토큰의 정교한 시맨틱 의미를 “망각”하게 되어, 이후 레이어에서 문맥의 일관성이 깨지거나 잘못된 사실 관계를 연결하는 오류를 범하게 됩니다.
Quiz 3: 모델 지능을 보존하는 관점에서 DeepSeek-V3의 동적 편향 전략이 표준 보조 손실보다 우수한 이유는 무엇인가요?
표준 보조 손실은 목적 함수()의 일부입니다. 즉, 균형 제약 조건을 만족시키기 위해 모델의 가중치를 물리적으로 변화시키는 그래디언트를 생성합니다. 이는 모델이 최적이 아닌 가중치를 학습하도록 강요합니다. 반면 DeepSeek의 동적 편향은 선택을 위한 로짓에 더해지지만, 그래디언트 테이프에서는 분리되어 있습니다. 이는 모델의 가중치()가 오직 언어 모델링 손실(순수한 친화도)에 기반해서만 학습된다는 것을 의미합니다. 균형은 학습된 표현을 오염시키지 않고 순전파 과정에서의 기계적인 “넛지”를 통해 달성됩니다.
References
- Lepikhin, D., et al. (2020). GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. arXiv:2006.16668.
- Zoph, B., et al. (2022). ST-MoE: Designing Stable and Transferable Sparse Expert Models. arXiv:2202.08906.
- DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv:2412.19437.