12.5 Long Context Serving
4K 수준에 머물던 대형 언어 모델(LLM)의 컨텍스트 윈도우(Context Window)가 128K, 1M 이상으로 확장되면서, 기존의 서빙 아키텍처는 근본적인 한계에 직면했습니다. 모델 아키텍처가 이론적으로 무한한 컨텍스트를 처리할 수 있다고 하더라도, GPU 메모리와 연산 스케줄링이라는 물리적 현실은 전혀 다른 문제를 야기합니다.
긴 컨텍스트(Long Context)를 서빙하는 것은 더 이상 단순한 알고리즘 문제가 아닙니다. 이는 거대한 프롬프트를 처리하는 연산 중심(Compute-bound) 의 특성과, 응답을 생성하는 메모리 대역폭 중심(Memory-bandwidth-bound) 의 특성 사이의 충돌을 해결해야 하는 고도의 ‘분산 시스템 엔지니어링’ 문제입니다.
1. Prefill과 Decode의 이분법, 그리고 메모리 장벽 (Memory Wall)
긴 컨텍스트가 왜 기존 서빙 시스템을 망가뜨리는지 이해하려면, LLM 추론의 두 가지 단계를 다시 짚어보아야 합니다.
- Prefill Phase (연산 병목): 사용자가 프롬프트를 입력하면, 모델은 모든 토큰을 병렬로 처리합니다. 이는 거대한 밀집 행렬 곱셈(Dense Matrix Multiplication)입니다. GPU의 산술 논리 장치(ALU)가 완전히 포화되며, 이 단계는 순전히 Compute (TFLOPS) 에 의해 속도가 결정됩니다.
- Decode Phase (메모리 대역폭 병목): 모델은 자기회귀(Autoregressive) 방식으로 토큰을 하나씩 생성합니다. 새로운 토큰을 생성할 때마다 모델은 과거의 모든 Key와 Value 히스토리(KV Cache)를 고대역폭 메모리(HBM)에서 연산 코어의 SRAM으로 불러와야 합니다. 이 단계는 수학적 연산량은 적지만 엄청난 양의 데이터를 이동시켜야 하므로 Memory Bandwidth 에 의해 속도가 제한됩니다.
선두 차단 현상 (Head-of-Line Blocking)
마트의 계산대를 상상해 보십시오. Prefill 단계는 카트에 10만 개의 물건을 담아온 고객입니다. 반면 Decode 단계는 껌을 하나씩 사려는 50명의 대기열입니다.
전통적인 통합 서빙(Unified Serving) 환경에서는 10만 개의 물건을 가진 고객이 계산대에 서면, 나머지 50명은 하염없이 기다려야 합니다. LLM 시스템에서 100K 토큰의 프롬프트가 들어오면, 이 요청은 수 초 동안 GPU를 완전히 독점합니다. 이때 Decode 단계에 있던 다른 활성 요청들은 모두 멈추게 되며, 이는 엄청난 지연 시간 스파이크(Jitter)를 유발하고 TPOT (Time Per Output Token) 지표를 완전히 파괴합니다.
Long Context의 비용 (수학적 분석)
KV Cache의 물리적 크기 자체가 ‘메모리 장벽(Memory Wall)‘이 됩니다. 단일 시퀀스에 대한 KV Cache의 메모리 요구량을 계산해 보겠습니다.
여기서:
- : Key와 Value.
- : 파라미터당 바이트 수 (FP16/BF16 기준).
- : 트랜스포머 레이어 수.
- : 어텐션 헤드 수.
- : 헤드당 차원(Dimension).
- : 시퀀스 길이 (Sequence Length).
- : 배치 사이즈 (Batch Size).
Llama-3-8B 모델 (, , )을 기준으로 계산해 보면:
- 일 때, KV Cache는 약 1 GB 입니다.
- 일 때, KV Cache는 약 32 GB 에 달합니다.
단일 요청 하나가 80GB H100 GPU VRAM의 절반 가까이를 차지하게 됩니다. 이 상태에서는 여러 요청을 효율적으로 배치(Batch) 처리할 수 없습니다. GPU는 메모리 용량이 부족해 더 이상 요청을 받지 못하고, 결과적으로 연산 코어는 놀고 있는(Idle) 최악의 비효율이 발생합니다.
 Source: Generated by Gemini
Source: Generated by Gemini
2. 알고리즘적 완화: StreamingLLM과 YaRN
시스템 엔지니어링으로 넘어가기 전에, 연구자들이 어떻게 메모리를 폭발시키지 않고 모델이 더 긴 문맥을 처리하도록 ‘속이거나’ ‘압축’하는지 알아야 합니다.
StreamingLLM: 어텐션 싱크 (Attention Sinks) 현상
일반적인 LLM은 추론 시 시퀀스 길이가 사전 학습(Pre-training) 길이를 초과하여 오래된 토큰이 KV Cache에서 밀려나면(Eviction), 어텐션 점수가 붕괴되며 성능이 급락합니다. StreamingLLM [1] 은 이 과정에서 매우 흥미로운 현상인 Attention Sinks 를 발견했습니다.
모델은 토큰의 의미론적 중요도와 상관없이, 시퀀스의 가장 첫 번째 등장하는 몇 개의 토큰 에 비정상적으로 높은 어텐션 점수를 할당하는 경향이 있습니다. 이는 Softmax 함수의 특성상 불필요한 어텐션 확률 질량(Mass)을 버려두는 ‘싱크대(Sink)’ 역할을 하기 때문입니다.
만약 메모리를 아끼기 위해 이 초기 토큰들을 KV Cache에서 지워버리면, 모델의 Perplexity는 폭발하게 됩니다. StreamingLLM은 매우 단순한 윈도우 어텐션(Windowed Attention) 메커니즘을 제안합니다. “처음 4개의 토큰(Sinks)을 KV Cache에 영구적으로 유지하고, 최근 개의 토큰만 슬라이딩 윈도우로 유지하라.” 이 방법을 통해 모델은 고정된 메모리 공간만으로 무한한 텍스트 스트림을 처리할 수 있습니다.
YaRN (Yet another RoPE extensioN)
문서에서 특정 정보를 정확히 찾아내야 하는(Needle-in-a-haystack) 작업처럼 진정한 의미의 긴 문맥 이해가 필요할 때는 토큰을 함부로 버릴 수 없습니다. YaRN [2] 은 컨텍스트 윈도우를 늘리기 위해 RoPE(Rotary Position Embeddings)를 수정합니다. 위치 임베딩을 단순히 외삽(Extrapolation)하면 모델이 붕괴되지만, YaRN은 NTK-aware interpolation 을 사용합니다. 이는 RoPE 임베딩의 위상(Phase)을 비선형적으로 확장하여, 4K 토큰으로 학습된 모델이 최소한의 파인튜닝만으로 32K나 128K 토큰을 완벽하게 이해할 수 있게 해줍니다.
3. 시스템 엔지니어링: 청크 단위 프리필 (Chunked Prefill)의 한계와 확장
거대한 프롬프트로 인한 극단적인 “선두 차단 현상(Head-of-Line Blocking)“을 완화하기 위해, 우리는 12.3절에서 자세히 소개한 Chunked Prefill 개념에 의존합니다.
긴 컨텍스트 서빙 환경에서 Chunked Prefill은 100K 토큰과 같은 거대한 프롬프트를 다룰 수 있는 크기(예: 4,096 토큰)의 청크로 쪼개고, 이를 다른 활성 요청들의 디코드 단계와 교차 실행합니다. 이 방식은 시스템이 완전히 멈추는 것을 방지하지만, 이 정도 규모에서는 다음과 같은 특정 과제를 안겨줍니다:
- 선형적인 TTFT 증가: 프리필이 여러 이터레이션(Iteration)에 걸쳐 분산되므로, 긴 프롬프트에 대한 TTFT (Time-To-First-Token) 는 청크 수에 비례하여 선형적으로 증가합니다.
- 백로그(Backlog)의 벽: 1M(100만) 토큰과 같은 극단적인 롱 컨텍스트의 경우, 청크로 쪼개는 것만으로는 여전히 엄청난 양의 프리필 작업 백로그가 쌓여 결국 전체 시스템을 느리게 만듭니다.
이러한 한계는 연산 풀과 메모리 풀을 물리적으로 분리해야 하는 필요성을 직접적으로 자극하며, 이는 최신 SOTA 아키텍처인 분리형 서빙(Disaggregated Serving)(4절)으로 이어집니다.
PyTorch 시뮬레이션: Chunked Prefill 스케줄러
아래는 스케줄러가 기존의 Unified Prefill과 Chunked Prefill을 어떻게 다르게 관리하는지 보여주는 단순화된 PyTorch 실행 코드입니다.
import torch
import time
class MockInferenceEngine:
def __init__(self, max_chunk_size=4096):
self.max_chunk_size = max_chunk_size
self.hidden_dim = 4096
# GPU 연산 스트림 시뮬레이션
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def unified_prefill(self, prompt_len):
"""블로킹(Blocking)을 유발하는 거대한 Prefill 연산을 시뮬레이션합니다."""
# O(N^2) 어텐션 연산 비용을 대략적으로 시뮬레이션
flops = (prompt_len ** 2) * self.hidden_dim
# GPU 부하를 모사하기 위한 더미 연산
x = torch.randn(prompt_len, self.hidden_dim, device=self.device)
_ = torch.matmul(x, x.T)
torch.cuda.synchronize() if torch.cuda.is_available() else None
return flops
def decode_step(self, batch_size):
"""메모리 대역폭에 병목이 걸리는 Decode 단계를 시뮬레이션합니다."""
# Decode는 연산 자체는 가볍지만 메모리 접근이 많음
x = torch.randn(batch_size, self.hidden_dim, device=self.device)
_ = x * 0.1 # 매우 단순한 연산
torch.cuda.synchronize() if torch.cuda.is_available() else None
return batch_size * self.hidden_dim
def simulate_scheduling():
engine = MockInferenceEngine(max_chunk_size=4096)
long_prompt = 32768
active_decodes = 10 # 다음 토큰을 기다리는 10명의 다른 사용자
print("--- Unified Serving (선두 차단 현상 발생) ---")
start = time.time()
engine.unified_prefill(long_prompt)
prefill_time = time.time() - start
print(f"Prefill (32k) 소요 시간: {prefill_time:.4f}초. 이 시간 동안 Decode 사용자들은 멈춰있습니다!")
print("\n--- Chunked Prefill Serving ---")
chunks = [engine.max_chunk_size] * (long_prompt // engine.max_chunk_size)
start_total = time.time()
for i, chunk in enumerate(chunks):
# 1. 긴 프롬프트의 청크 하나를 처리
engine.unified_prefill(chunk)
# 2. 즉시 대기 중인 사용자들의 Decode 단계를 1회 처리 (교차 실행)
engine.decode_step(active_decodes)
if i == 0:
print(f"첫 번째 청크 처리 완료: {time.time() - start_total:.4f}초. Decode 사용자들이 훨씬 일찍 토큰을 받습니다!")
print(f"전체 Chunked Prefill + 8번의 Decode 스텝 소요 시간: {time.time() - start_total:.4f}초")
if __name__ == "__main__":
simulate_scheduling()4. 최신 SOTA: 분리형 서빙 (Disaggregated Serving)
Chunked Prefill을 사용하더라도, 단일 GPU나 동일한 스펙의 클러스터로는 Prefill(TFLOPS 필요)과 Decode(메모리 대역폭/용량 필요)라는 상충되는 하드웨어 요구사항을 동시에 완벽히 만족시킬 수 없습니다.
이를 해결하기 위해 등장한 최신 아키텍처가 바로 Splitwise [4] 와 DistServe [5] 가 주도하는 분리형 서빙(Disaggregated Serving) 입니다.
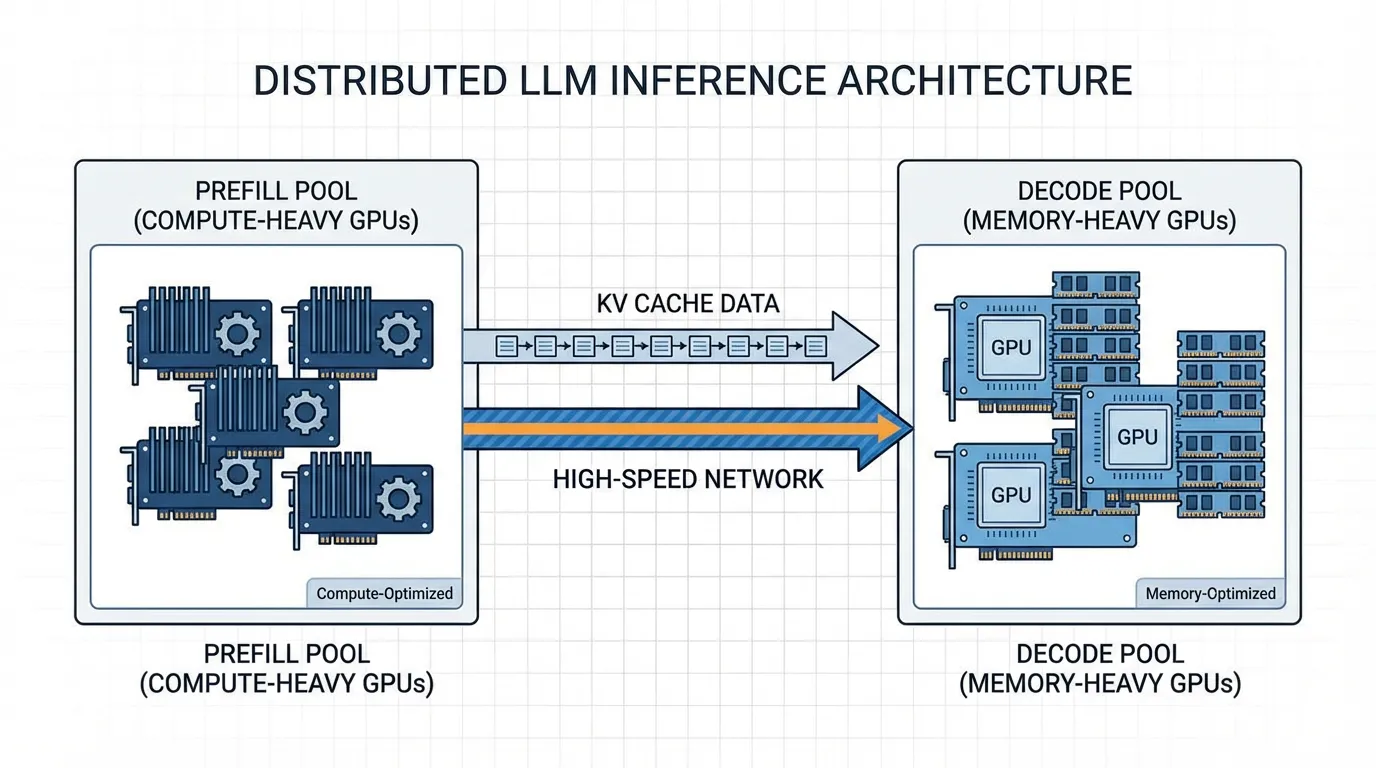
풀(Pool)의 분리
분리형 서빙은 추론 파이프라인을 두 개의 물리적으로 다른 GPU 클러스터로 완전히 나눕니다:
- Prefill Pool: 연산 능력이 압도적인 GPU(예: NVIDIA H100)로 구성됩니다. 이 노드들은 거대한 프롬프트를 삼키고, 초기 KV Cache를 계산하며, 첫 번째 토큰을 생성하는 역할만 전담합니다.
- Decode Pool: 메모리 용량과 대역폭이 크고 상대적으로 저렴한 GPU(예: NVIDIA L40S 또는 구형 A100)로 구성됩니다. 이 노드들은 Prefill Pool로부터 작업의 바통을 이어받아 자기회귀 방식의 생성을 전담합니다.
새로운 병목: 네트워크 전송 (Network Transfer)
작업을 물리적으로 분리하면 새로운 문제가 발생합니다. 바로 KV Cache 전송 입니다. Prefill Pool이 작업을 마치면, 생성된 거대한 KV Cache(예: 128K 컨텍스트의 경우 32GB)를 네트워크를 통해 Decode Pool로 보내야 합니다. 네트워크가 느리다면 전송 시간이 분리형 서빙의 이점을 모두 갉아먹게 됩니다.
이를 해결하기 위해 SOTA 시스템들은 다음 기술을 필수적으로 사용합니다:
- 고속 인터커넥트 (High-speed Interconnects): CPU를 거치지 않고 GPU VRAM 간에 직접 메모리를 쏘아 보내는 GPUDirect RDMA 기술(InfiniBand 또는 RoCE 활용).
- KV Cache 양자화 (Quantization): 전송 전에 KV Cache를 FP16에서 FP8이나 INT4로 압축하여 네트워크 페이로드 크기를 절반 이하로 줄이고, Decode 노드의 VRAM 점유율도 낮추는 기술.
 Source: Generated by Gemini
Source: Generated by Gemini
5. 인터랙티브 시각화: 스케줄링 전략 비교
이러한 시스템 레벨의 최적화가 실제로 어떻게 작동하는지 아래의 타임라인을 통해 확인해 보십시오. 무거운 Long Context 요청 1개와 가벼운 Decode 요청 여러 개가 섞여 있을 때, Unified, Chunked, Disaggregated 서빙이 자원을 어떻게 할당하는지 비교할 수 있습니다.
6. 요약 및 Open Questions
Long Context 서빙의 역사는 ‘병목(Bottleneck) 이동’의 역사입니다. 우리는 연산 병목에서 시작해 메모리 용량 병목에 부딪혔고, 이를 PagedAttention과 Chunking으로 해결한 뒤, 이제는 분리형 서빙을 통한 네트워크 대역폭 병목과 싸우고 있습니다.
다음 세대를 위한 Open Questions:
- 컨텍스트 윈도우가 1,000만 토큰(예: Llama 4 Scout)으로 확장됨에 따라, RDMA를 활용한 분리형 서빙조차도 KV Cache 전송 속도를 감당하기 어려워지고 있습니다. 우리는 결국 KV Cache를 완전히 버리고 Mamba와 같은 상태 공간 모델(SSM, State Space Models)로 넘어가게 될까요?
- 정확한 Key-Value 텐서를 모두 저장하는 대신, 정보의 ‘의미’만을 남기는 의미론적 압축(Semantic Compression) 을 KV Cache에 적용할 수 있을까요?
Quizzes
Quiz 1: Chunked Prefill 기법은 전체 시스템의 처리량(Throughput)을 향상시킴에도 불구하고, 왜 긴 컨텍스트 요청 자체의 TTFT(Time-To-First-Token)는 기술적으로 증가하게 됩니까?
Prefill 작업을 여러 청크로 쪼개고 그 사이에 다른 요청들의 Decode 단계를 교차(Interleave) 실행하기 때문입니다. 이러한 컨텍스트 스위칭 덕분에 전반적인 GPU 활용도가 극대화되고 다른 사용자들의 지연(TPOT Jitter)은 방지되지만, 긴 프롬프트 입장에서는 중간중간 Decode 연산이 끼어들기 때문에 모든 Prefill 청크를 끝마치는 데 걸리는 절대적인 시간(Wall-clock time)은 늘어나게 됩니다.
Quiz 2: Splitwise와 같은 분리형 서빙(Disaggregated Serving) 아키텍처를 구축할 때, Prefill Pool과 Decode Pool의 하드웨어 스펙(사양)을 어떻게 다르게 구성해야 합니까?
Prefill Pool의 작업은 연산(Compute) 병목이므로 강력한 Tensor Core 성능과 높은 TFLOPS를 가진 고성능 GPU(예: H100)를 우선적으로 배치해야 합니다. 반면 Decode Pool은 연산 능력은 크게 필요하지 않지만 메모리 대역폭과 용량 병목이 발생하므로, 총 VRAM 용량이 크고 대역폭이 넓은 GPU(예: 여러 대의 L40S를 묶거나 구형 A100 80GB 활용)를 배치하는 것이 경제적이고 효율적입니다.
Quiz 3: StreamingLLM에서 설명하는 ‘어텐션 싱크(Attention Sinks)‘의 근본적인 메커니즘은 무엇이며, 왜 처음 몇 개의 토큰을 지우면 Perplexity가 폭발합니까?
어텐션 메커니즘의 Softmax 함수 특성상 모든 확률의 합은 1이 되어야 합니다. 모델은 학습 과정에서 현재 토큰이 딱히 주목할 만한 과거 토큰이 없을 때, 남는 잉여 어텐션 점수를 시퀀스의 맨 처음 토큰들(Sinks)에 버리도록(Dump) 학습됩니다. 만약 메모리 절약을 위해 이 초기 토큰들을 지워버리면, 모델은 버려야 할 어텐션 점수를 의미론적으로 중요한 주변 토큰들에게 강제로 분배하게 되어 기존에 학습된 어텐션 분포가 완전히 망가지고 결과적으로 Perplexity가 폭발하게 됩니다.
Quiz 4: Prefill 노드에서 Decode 노드로 128K 토큰의 KV Cache를 전송할 때, KV Cache 양자화(예: FP8)가 단순히 Decode 노드의 VRAM을 아끼는 것 이상으로 시스템 전체에 결정적인(Critical) 이유는 무엇입니까?
분리형 서빙의 가장 큰 병목 현상은 노드 간의 네트워크 전송 시간(Network Transfer Time)이기 때문입니다. KV Cache를 FP8로 양자화하면 물리적인 데이터 페이로드 크기가 절반으로 줄어들어 InfiniBand/RDMA 네트워크를 통과하는 시간이 절반으로 단축됩니다. 이는 네트워크 지연 페널티를 직접적으로 줄여주어 Decode 노드가 훨씬 더 빨리 토큰 생성을 시작할 수 있게 만듭니다.
Quiz 5: 시퀀스 길이를 에서 로 확장할 때 RoPE (Rotary Position Embedding) 기본 주파수 에 대한 스케일링 관계식을 정의하시오.
표준 RoPE에서 기본 주파수는 입니다. 시퀀스 길이가 에서 로 확장되면 사인파 함수의 파장도 함께 늘려주어야 합니다. 선형 보간(Linear Interpolation)에서는 주파수가 의 비율로 단순 스케일링됩니다. 그러나 고주파수의 국소적(local) 관계를 보존하기 위해 Dynamic NTK-aware 스케일링은 기본 주파수 를 동적으로 스케일링합니다. 새로운 기본 주파수는 가 됩니다. 이러한 수학적 조정을 통해 모델은 저주파수 구성 요소를 늘려 긴 시퀀스 문맥을 수용하는 동시에, 고주파수 영역의 국소적 컨텍스트 충실도를 성공적으로 보존할 수 있습니다.
References
- Xiao, G., et al. (2023). Efficient Streaming Language Models with Attention Sinks. arXiv:2309.17453.
- Peng, B., et al. (2023). YaRN: Efficient Context Window Extension of Large Language Models. arXiv:2309.00071.
- Agrawal, A., et al. (2023). Sarathi: Efficient LLM Inference by Chunking Prefills. arXiv:2308.16369.
- Patel, P., et al. (2024). Splitwise: Efficient Generative LLM Inference Using Phase Splitting. arXiv:2311.18677.
- Zhong, Y., et al. (2024). DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. arXiv:2401.09670.