20.1 상태 공간 모델 (SSM)
이전 장에서 우리는 트랜스포머(Transformer) 내부의 블랙박스를 열어 특징(Features)과 회로(Circuits)를 해석하는 방법을 다루었습니다. 이러한 복잡한 추론이 가능했던 이유는 트랜스포머가 전역적인 어텐션(Global Attention) 메커니즘을 통해 시퀀스 내의 모든 정보를 연결할 수 있었기 때문입니다. 수년간 딥러닝 커뮤니티는 Attention is All You Need 라는 단일 패러다임 아래 움직였고, 트랜스포머는 파운데이션 모델(Foundation Models)의 절대적인 왕좌를 차지했습니다.
하지만 트랜스포머는 치명적인 결함을 안고 있습니다. 바로 Quadratic Bottleneck (이차 병목현상)입니다. 모든 토큰이 이전의 모든 토큰과 어텐션을 연산해야 하므로, 시퀀스 길이 에 대해 연산 복잡도가 으로 증가합니다. 더 심각한 것은 추론(Inference) 시 KV 캐시(KV Cache)가 선형적으로 증가하여 GPU VRAM을 잠식하고 컨텍스트 윈도우(Context window) 확장을 심각하게 제한한다는 점입니다.
만약 우리가 수백만 토큰의 컨텍스트—거대한 코드베이스 전체, 유전체 시퀀스, 또는 1시간 분량의 비디오—를 처리하고자 한다면, 매 단계마다 전체 과거 기록을 “다시 읽어야” 하는 메커니즘에 의존할 수 없습니다. 새로운 정보가 들어올 때마다 과거의 고정된 크기의 메모리를 효율적으로 업데이트하는 모델이 필요합니다. 역사적으로 이는 순환 신경망(RNN)의 영역이었습니다. 그러나 RNN은 순차적인 특성 때문에 GPU에서의 병렬 학습이 불가능하여 도태되었습니다.
여기서 State Space Model (SSM) 의 르네상스가 시작됩니다. 제어 이론(Control theory)의 연속 시간(Continuous-time) 수학과 하드웨어 친화적인 GPU 알고리즘을 결합함으로써, 최신 SSM—특히 Mamba 는 선형 시간 의 확장성, 상수 의 추론 메모리, 그리고 트랜스포머 수준의 언어 모델링 성능이라는 궁극적인 목표를 달성했습니다.
20장의 흐름은 “트랜스포머 이후 무엇이 올 수 있는가”에 대한 여러 답을 차례로 보는 구조입니다. SSM과 Mamba는 긴 시퀀스를 효율적으로 흐르게 만드는 답이고, Linear Attention은 어텐션 자체를 더 싸게 바꾸려는 답입니다. Neural Networks as Programs와 MTP는 모델이 더 계획적으로 계산하도록 만드는 답이며, Diffusion LLM과 World Model은 생성 방식을 왼쪽에서 오른쪽 한 줄짜리 토큰 예측 너머로 넓히려는 답입니다.
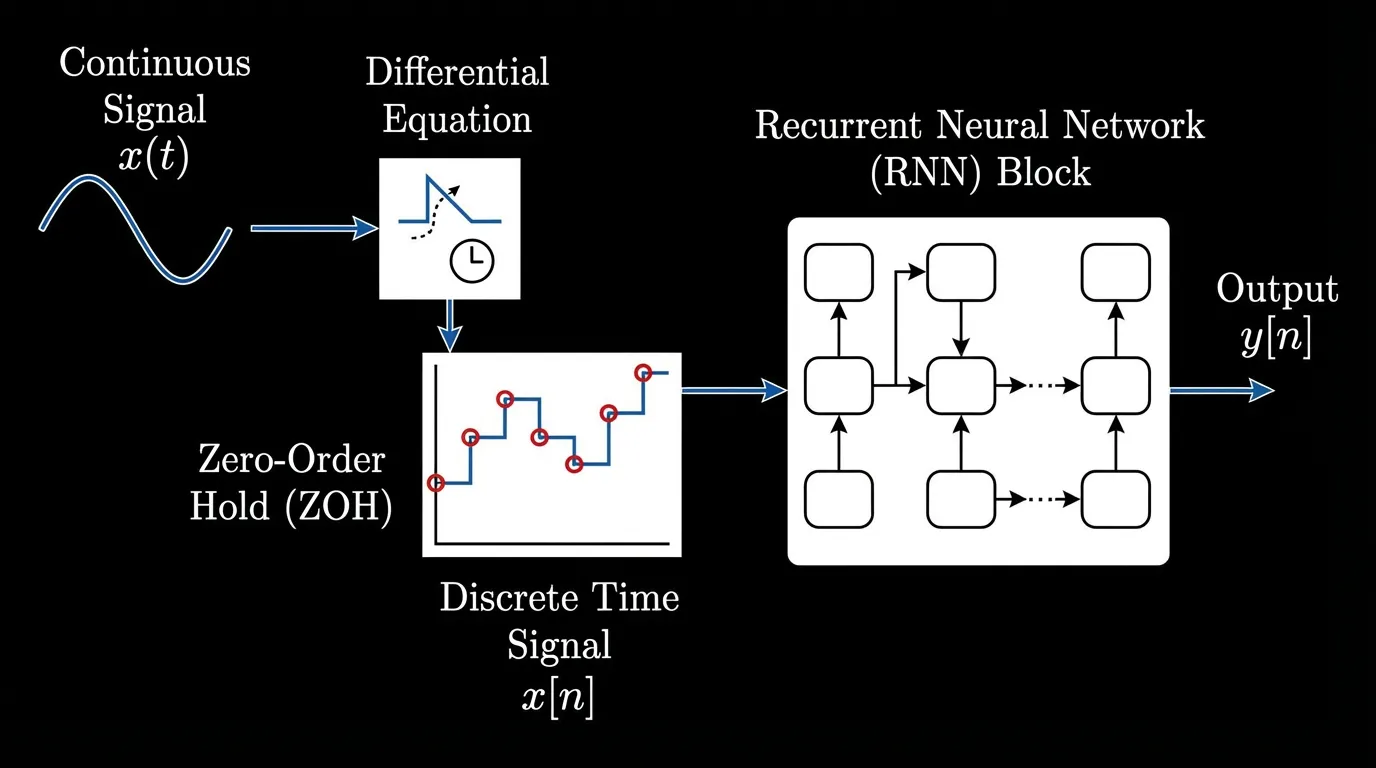
1. 연속에서 이산으로: SSM의 수학
상태 공간 모델(State Space Models)은 완전히 새로운 개념이 아닙니다. 칼만 필터(Kalman filters)와 같은 제어 공학의 기초가 되는 이론입니다. 핵심 아이디어는 암시적인 잠재 상태(Latent state) 를 통해 1차원 입력 신호 를 출력 신호 로 매핑하는 것입니다.
연속 시간(Continuous time) 환경에서 이는 다음과 같은 선형 미분 방정식 시스템으로 정의됩니다.
여기서 각 변수는 다음을 의미합니다.
- 는 상태 전이 행렬(State transition matrix)로, 은닉 상태가 어떻게 진화하는지 결정합니다.
- 는 입력을 상태 공간으로 투영합니다.
- 는 상태를 다시 출력 공간으로 투영합니다.
- 는 직접적인 스킵 커넥션(Skip connection)입니다 (종종 생략되거나 단순한 잔차 연결로 취급됨).
문장의 단어와 같은 이산적인(Discrete) 토큰을 처리하는 신경망에서 이를 사용하려면, 연속적인 시스템을 이산화해야 합니다. 이를 위해 스텝 크기를 나타내는 시간 척도 파라미터 를 도입합니다. Zero-Order Hold (ZOH) 라는 기법을 사용하여 연속 행렬 를 이산 행렬 로 변환합니다.
이 과정을 거치면 다음과 같은 이산 순환 업데이트 규칙(Discrete recurrent update rule)이 도출됩니다.
 (Source: Generated by Gemini)
(Source: Generated by Gemini)
S4와 같은 초기의 딥러닝 기반 SSM은 이 정확한 공식을 사용했습니다. 하지만 이들은 언어 모델링에서 트랜스포머의 성능을 따라잡지 못했습니다. 그 이유는 무엇일까요? 바로 이들이 Linear Time-Invariant (LTI) 즉, 선형 시불변 특성을 가졌기 때문입니다. 행렬 는 모든 타임스텝에 걸쳐 고정되어 있었습니다. 모델은 모든 토큰에 대해 완전히 동일한 동역학을 적용했으며, 내용에 기반한 추론(예: “이 특정 이름은 기억해야 하지만, 이 의미 없는 채우기 단어는 잊어버려야 해”)을 수행할 능력이 전혀 없었습니다.
2. Mamba의 돌파구: 선택적 상태 공간
2023년 말, 연구자 Tri Dao와 Albert Gu는 Selective Scan 메커니즘을 도입하여 LTI의 한계를 극복한 Mamba 를 발표했습니다 [1].
논문과 구현체에서 이 선택적 SSM 블록은 종종 S6 라고 불립니다. S6는 별도의 후속 모델 이름이라기보다, Mamba-1의 핵심 selective structured state space sequence layer를 가리키는 용어에 가깝습니다. 그래서 “Mamba와 S6”라고 말할 때는 보통 “Mamba 아키텍처와 그 안의 selective scan/SSM 블록”을 함께 설명하는 것입니다.
행렬을 고정시키는 대신, Mamba 는 , , 그리고 스텝 크기 를 입력 의 함수 로 만듭니다.
이 단순한 변화는 엄청난 결과를 가져왔습니다. 파라미터를 입력에 의존적으로 만듦으로써 모델은 선택성(Selectivity) 을 얻게 되었습니다.
- 만약 가 의미 없는 채우기 단어(Filler word)라면, 모델은 작은 를 출력하여 사실상 은닉 상태를 동결()시키고 해당 토큰을 무시할 수 있습니다.
- 만약 가 중요한 엔티티(Entity)라면, 모델은 큰 와 특정한 를 출력하여 은닉 상태의 관련 부분을 강력하게 덮어쓸 수 있습니다.
Mamba 는 고정된 크기의 순환 상태(Recurrent state) 내에서 트랜스포머가 특정 토큰에 어텐션을 기울이는 능력을 모방하여 동적으로 정보를 필터링하는 방법을 효과적으로 학습합니다.
하드웨어 병목 해결하기
행렬을 입력 의존적으로 만들었다는 것은, Mamba 가 더 이상 초기 LTI SSM들을 구동했던 빠른 합성곱 푸리에 변환(Convolutional Fourier transforms)을 사용할 수 없음을 의미했습니다. 연산은 순차적으로 이루어져야만 했습니다.
모델이 학습 중에 RNN처럼 느려지는 것을 방지하기 위해, 저자들은 하드웨어 친화적인 병렬 연관 스캔 (Hardware-aware parallel associative scan) 을 엔지니어링했습니다. 은닉 상태 를 GPU의 초고속 SRAM에 전적으로 유지하고 Prefix-sum 알고리즘을 활용함으로써, Mamba 는 시퀀스 길이에 걸쳐 순차적인 순환 연산을 병렬로 계산하여 동급 트랜스포머 대비 최대 5배 빠른 학습 처리량을 달성했습니다.
Architecture Scaling Comparison
Dense Transformer (O(N²))
Every token attends to all previous tokens.
State Space Model (O(N))
Tokens sequentially update a fixed hidden state.
h(t)
3. Mamba-2와 구조화된 상태 공간 이중성 (SSD)
Mamba-1은 선택적 SSM(Selective SSM)이 트랜스포머에 필적할 수 있음을 증명했지만, 맞춤형 병렬 스캔 커널은 더 이상 최적화하기가 어려웠습니다. 2024년, 저자들은 Structured State Space Duality (SSD) 라는 이론적 프레임워크를 도입한 Mamba-2 를 발표했습니다 [2].
SSD는 선택적 SSM과 선형 어텐션(Linear Attention)이 동전의 양면이라는 것을 수학적으로 증명했습니다. 행렬의 구조를 약간 제한(스칼라 곱 단위 행렬로 만듦)함으로써, 순환하는 SSM 업데이트를 특수한 형태의 행렬 곱셈(Matrix multiplication)으로 완벽하게 재작성할 수 있습니다.
이것이 왜 중요할까요? 바로 Tensor Cores 때문입니다. NVIDIA H100과 같은 최신 GPU는 행렬 곱셈(MatMul)에 고도로 최적화되어 있습니다. H100은 MatMul에 대해 거의 1,000 TFLOPS의 성능을 제공하지만, 맞춤형 연관 스캔에 대해서는 그 성능의 극히 일부만 제공합니다. SSM을 블록 행렬 곱셈으로 재구성함으로써, Mamba-2 는 Tensor Core 가속을 잠금 해제하였고, 상태 차원(State dimension)을 대폭 확장(Mamba-1의 에서 Mamba-2의 으로)하면서도 학습 속도를 크게 높일 수 있었습니다.
4. SOTA를 향한 엔지니어링: 하이브리드 MoE-SSM 아키텍처
순수 SSM의 우아함에도 불구하고, 2024년과 2025년의 실제 배포 환경에서는 미묘한 한계가 드러났습니다. 바로 State Decay (상태 부패) 현상입니다. SSM은 전체 시퀀스를 고정된 크기의 벡터로 압축하기 때문에, 방대한 컨텍스트에서 “건초더미에서 바늘 찾기(Needle in a haystack)“와 같은 정밀한 정보 검색에 어려움을 겪을 수 있습니다. 명시적인 KV 캐시를 가진 트랜스포머는 완벽한 “연관 메모리(Associative memory)“를 보유하고 있어 정확한 토큰을 다시 되돌아볼 수 있습니다.
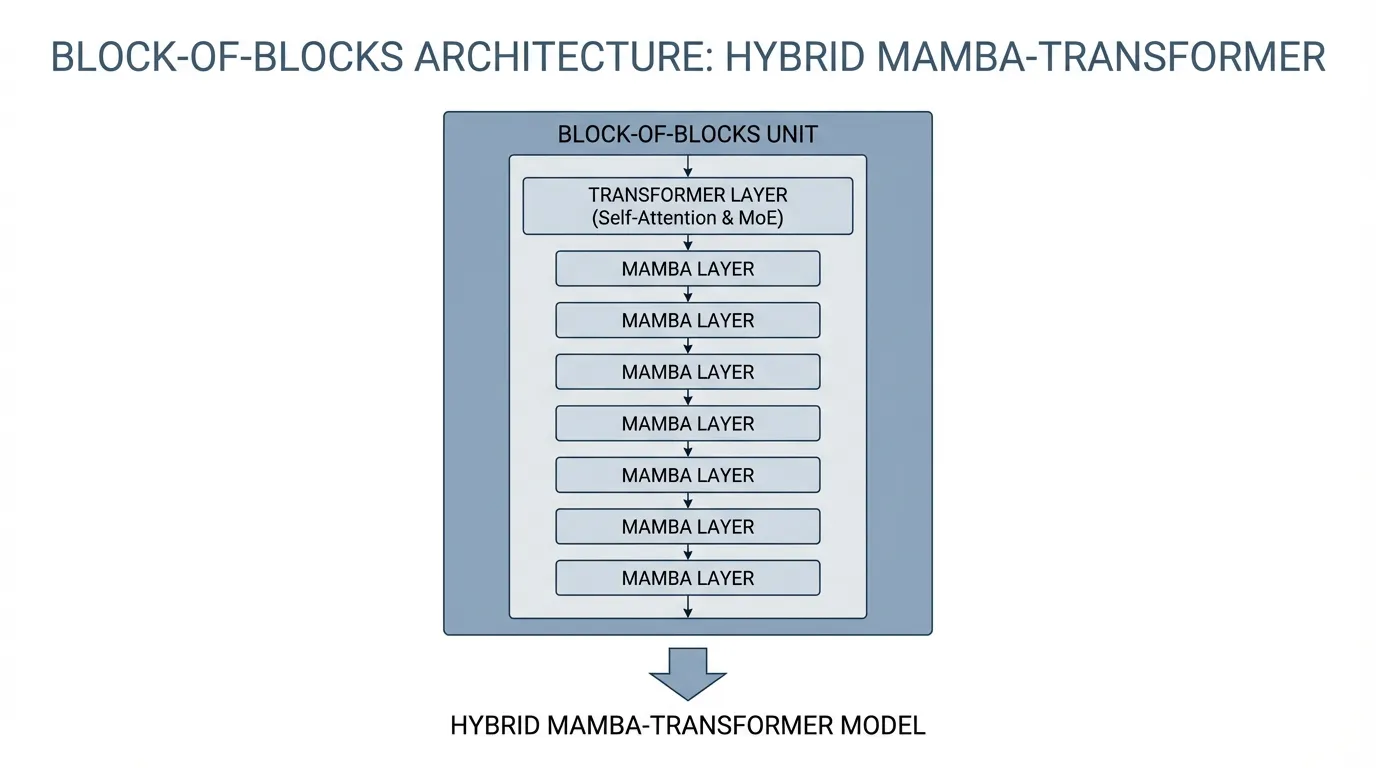
이에 대한 업계의 해결책은 Hybrid Architecture (하이브리드 아키텍처) 입니다. AI21 Labs의 Jamba [3] 와 NVIDIA의 Nemotron-Nano/H [4] 와 같은 모델들은 트랜스포머 레이어와 Mamba 레이어를 교차로 배치합니다.
 (Source: Generated by Gemini)
(Source: Generated by Gemini)
“블록 속의 블록” 전략
Jamba 모델에서 네트워크는 반복되는 블록들로 구성됩니다. 표준 구성은 1:7 비율로, 1개의 트랜스포머 레이어 뒤에 7개의 Mamba 레이어 가 따르는 형태입니다.
- Mamba 레이어 는 시퀀스 전파의 무거운 작업을 처리하며, 메모리로 컨텍스트를 효율적으로 앞으로 전달합니다.
- 트랜스포머 레이어 는 연관 메모리 체크포인트 역할을 하며, 시퀀스 전체에 걸쳐 밀집된(Dense) 내용 기반의 라우팅을 수행합니다.
연산량을 늘리지 않으면서 파라미터 수를 더 높이기 위해, 이러한 아키텍처들은 트랜스포머의 Feed-Forward 레이어에 Mixture of Experts (MoE) 를 통합합니다. 모델은 전체 52B 파라미터를 가질 수 있지만, 토큰당 활성화되는 파라미터는 12B에 불과할 수 있습니다. 이를 통해 거대한 하이브리드 모델이 단일 80GB GPU에 쉽게 들어가면서도 256k의 컨텍스트 윈도우를 처리할 수 있게 됩니다. 이는 순수 밀집 트랜스포머(Dense Transformer)로는 수학적으로 불가능한 업적입니다.
아키텍처 트레이드오프
| 특징 (Feature) | 밀집 트랜스포머 (Baseline) | 순수 SSM (Mamba-2) | 하이브리드 MoE-SSM (Jamba/Nemotron) |
|---|---|---|---|
| 연산 확장성 | 이차적 | 선형적 | 선형에 가까운 하이브리드 |
| 추론 메모리 | 시퀀스에 비례 (KV Cache) | 상수 | 대폭 감소됨 |
| 연관 메모리 | 완벽함 (명시적 조회) | 긴 구간에서 저하됨 | 높음 (체크포인트 조회) |
| 최적 사용 사례 | 짧거나 중간 컨텍스트, 최고 정밀도 | 무한 스트림 원격 측정, 오디오 | 엔터프라이즈 에이전트 AI, 롱컨텍스트 RAG |
5. 디스패처 구현: PyTorch의 Selective Scan
Mamba 의 메커니즘을 진정으로 이해하려면 코드를 살펴보아야 합니다. 아래는 Selective SSM의 순전파(Forward pass)를 교육 목적으로 단순화한 PyTorch 구현입니다.
(참고: 프로덕션 환경에서는 순차적인 for 루프가 하드웨어 친화적인 SSD 행렬 곱셈 커널로 대체됩니다. 하지만 기본 수학을 이해하는 데는 순차적으로 작성된 코드를 보는 것이 가장 좋습니다).
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimplifiedSelectiveSSM(nn.Module):
"""
Selective State Space Model의 단순화된 교육용 구현체입니다.
입력 의존적인 파라미터 생성과 ZOH 이산화(Discretization)를 시연합니다.
"""
def __init__(self, d_model: int, d_state: int):
super().__init__()
self.d_model = d_model
self.d_state = d_state
# 입력 의존적 파라미터들을 위한 투영(Projections) ("Selective"의 핵심 부분)
# dt: 스텝 크기, B 및 C: 상태 전이 행렬
self.dt_proj = nn.Linear(d_model, d_model)
self.B_proj = nn.Linear(d_model, d_state)
self.C_proj = nn.Linear(d_model, d_state)
# A는 일반적으로 과거를 기억하기 위해 특정 구조(예: HiPPO 행렬)로 초기화되며,
# 고정되거나 매우 천천히 업데이트됩니다.
# 안정성을 위해 A가 엄격하게 음수를 유지하도록 log(A)로 표현합니다.
self.A_log = nn.Parameter(torch.randn(d_model, d_state))
# 스킵 커넥션 (Skip connection)
self.D = nn.Parameter(torch.randn(d_model))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x shape: (batch_size, seq_len, d_model)
B, L, D = x.shape
# 1. 전체 시퀀스에 걸쳐 입력 의존적인 파라미터 계산
# Softplus는 스텝 크기(\Delta)가 엄격하게 양수가 되도록 보장합니다.
dt = F.softplus(self.dt_proj(x)) # (B, L, D)
B_mat = self.B_proj(x) # (B, L, d_state)
C_mat = self.C_proj(x) # (B, L, d_state)
# A는 상태 부패(State decay)를 보장하기 위해 엄격하게 음수여야 합니다 (제한된 안정성).
A = -torch.exp(self.A_log) # (D, d_state)
# 2. 이산화(Discretization) 및 상태 업데이트 계산
# [교육용 참고]: 명확성을 위해 이 루프는 순차적으로 작성되었습니다.
# Mamba-1은 여기서 병렬 연관 스캔을 사용하고, Mamba-2는 SSD 블록-행렬 곱을 사용합니다.
y = torch.zeros_like(x)
h = torch.zeros(B, D, self.d_state, device=x.device) # 초기 은닉 상태
for t in range(L):
x_t = x[:, t, :] # (B, D)
dt_t = dt[:, t, :] # (B, D)
B_t = B_mat[:, t, :] # (B, d_state)
C_t = C_mat[:, t, :] # (B, d_state)
# Zero-Order Hold (ZOH) 이산화
# \bar{A} = exp(dt * A)
# \bar{B} \approx dt * B
dA = torch.exp(dt_t.unsqueeze(-1) * A) # (B, D, d_state)
dB = dt_t.unsqueeze(-1) * B_t.unsqueeze(1) # (B, D, d_state)
# 상태 업데이트: h_t = \bar{A} h_{t-1} + \bar{B} x_t
h = dA * h + dB * x_t.unsqueeze(-1) # (B, D, d_state)
# 출력 투영: y_t = C h_t + D x_t
y_t = torch.sum(h * C_t.unsqueeze(1), dim=-1) + self.D * x_t # (B, D)
y[:, t, :] = y_t
return y
# 순전파(Forward pass)를 시뮬레이션하는 사용 예시
# Batch=2, Seq_len=128, D_model=512, D_state=16
model = SimplifiedSelectiveSSM(d_model=512, d_state=16)
dummy_input = torch.randn(2, 128, 512)
output = model(dummy_input)
print(f"Input shape: {dummy_input.shape}") # torch.Size([2, 128, 512])
print(f"Output shape: {output.shape}") # torch.Size([2, 128, 512])7. 요약과 열린 질문
State Space Models 는 트랜스포머의 등장 이후 그 지배력에 도전하는 가장 강력하고 실현 가능한 대안입니다. 연속적인 제어 이론 방정식을 이산화하고 입력 의존적인 선택성을 주입함으로써, Mamba 는 효율성과 표현력 사이의 딜레마를 해결했습니다. 맞춤형 연관 스캔(Mamba-1)에서 State Space Duality를 통한 Tensor Core 친화적인 행렬 곱셈(Mamba-2)으로의 진화는, 알고리즘과 하드웨어의 공동 설계(Co-design)가 파운데이션 모델을 확장하는 핵심임을 증명합니다.
오늘날 업계는 실용적인 절충안인 Hybrid MoE-SSM 아키텍처에 안착했습니다. 이러한 모델들은 SSM을 컨텍스트 전파를 위한 고대역폭 고속도로로 활용하고, 그 사이사이에 정밀한 연관 메모리 체크포인트 역할을 하는 트랜스포머 레이어를 배치합니다.
다음 시대를 위한 열린 질문 (Open Questions): 시퀀스 모델링을 넘어, 엄격한 1차원 시간적 순서가 없는 모달리티(Modality)에 이러한 선형 시간 아키텍처를 어떻게 적용할 수 있을까요? SSM이 고해상도 이미지의 2차원 공간적 관계나 분자 생물학의 복잡한 그래프 구조를 효과적으로 모델링할 수 있을까요? 다음 섹션에서는 이러한 개념들이 어떻게 Linear Attention 과 포스트 트랜스포머 아키텍처로 확장되는지 탐구해 보겠습니다.
Quizzes
Quiz 1: S4와 같은 초기 연속 시간 상태 공간 모델(Continuous-Time SSM)이 언어 모델링 작업에서 트랜스포머를 따라잡지 못한 이유는 무엇인가요?
초기 SSM은 선형 시불변(Linear Time-Invariant, LTI) 특성을 가졌습니다. 전이 행렬()이 고정되어 있어 모든 토큰에 정확히 동일한 동역학을 적용했습니다. 언어는 중요한 엔티티를 선택적으로 기억하고 의미 없는 단어를 잊어버리는 내용 인식 필터링 능력이 필요하지만, LTI 모델에는 이러한 선택성이 부족했습니다.
Quiz 2: Mamba가 입력 의존적인 순차적 순환을 도입했다면, 전통적인 RNN을 괴롭혔던 엄청난 학습 속도 저하를 어떻게 피할 수 있었나요?
Mamba는 하드웨어 친화적인 병렬 연관 스캔(Parallel associative scan)을 활용하여 순차적 학습의 병목 현상을 피합니다. 은닉 상태를 GPU의 초고속 SRAM 내에 전적으로 유지하고 HBM에 큰 중간 텐서를 생성하는 것을 피함으로써, Prefix-sum 알고리즘을 사용하여 순환 연산을 병렬로 계산합니다.
Quiz 3: Mamba-2에 도입된 Structured State Space Duality (SSD) 프레임워크의 주요 아키텍처적 이점은 무엇인가요?
SSD는 선택적 SSM과 선형 어텐션(Linear Attention)을 수학적으로 통합합니다. 행렬의 구조를 약간 제한함으로써, SSM 업데이트를 블록 행렬 곱셈으로 재작성할 수 있습니다. 이를 통해 모델은 (연관 스캔이 아닌 행렬 곱셈에 최적화된) GPU Tensor Cores를 최대한 활용할 수 있게 되어, 훨씬 더 큰 상태 차원과 더 빠른 학습 속도를 가능하게 합니다.
Quiz 4: Jamba나 Nemotron과 같은 최신 프로덕션 모델들이 순수 SSM 대신 하이브리드(SSM + Transformer) 아키텍처를 사용하는 이유는 무엇인가요?
순수 SSM은 처리량(Throughput)과 일정한 메모리 사용량을 유지하는 데 뛰어나지만, 극단적으로 긴 컨텍스트에서는 “상태 부패(State decay)“를 겪어 정밀한 “건초더미에서 바늘 찾기(Needle in a haystack)” 검색이 어려워집니다. 몇 개의 트랜스포머 레이어를 교차로 배치하면 명시적인 KV 캐시 연관 메모리를 제공하여, SSM의 효율성과 트랜스포머의 정확한 회상 능력을 결합한 “두 세계의 장점”을 모두 취할 수 있습니다.
References
- Gu, A., & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752.
- Dao, T., & Gu, A. (2024). Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality (Mamba-2). arXiv:2405.21060.
- Lieber, O., et al. (2024). Jamba: A Hybrid Transformer-Mamba Language Model. AI21 Labs. arXiv:2403.19887.
- NVIDIA. (2025). Nemotron-Nano: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model. arXiv:2504.03624.