8.4 Transfer Learning & Generalization
이전 섹션에서 우리는 사전 학습(Pre-training) 연산량을 확장할 때 발생하는 경제적, 물리적 트레이드오프와 ‘과잉 학습(Over-training)‘의 역설에 대해 살펴보았습니다. 하지만 파운데이션 모델(Foundation Model)의 사전 학습은 그 자체로 최종 목적이 되는 경우가 드뭅니다. 이는 단지 거대한 초기화(Initialization) 단계일 뿐입니다. 모델의 진정한 효용 가치는 방대하고 구조화되지 않은 잠재 지식(Latent knowledge)을 지도 미세 조정(SFT), 인간 피드백 기반 강화 학습(RLHF) 또는 제로샷(Zero-shot) 적용과 같은 특정 다운스트림 작업으로 얼마나 잘 전이(Transfer)시킬 수 있느냐에 따라 결정됩니다.
이것이 바로 일반화 (Generalization) 의 과학입니다. 사전 학습된 지식은 얼마나 예측 가능하게 전이될까요? 새로운 데이터 분포에 적응하도록 강요받을 때 모델의 내부 표현(Internal representation)에는 어떤 변화가 일어날까요? 그리고 가장 중요하게, 인간 감독자보다 훨씬 뛰어난 능력을 갖춘 초인적(Superhuman) AI에게 우리는 어떻게 올바른 의도를 전이시킬 수 있을까요?
지식 전이의 물리학 (The Physics of Knowledge Transfer)
전이 학습(Transfer learning)은 마법이 아니며, 엄격한 경험적 스케일링 법칙(Empirical scaling laws)을 따릅니다. 사전 학습된 모델을 다운스트림 데이터셋으로 미세 조정할 때, 그 성능 향상 궤적은 처음부터(From-scratch) 학습하는 모델과는 근본적으로 다릅니다.
이를 정량화하기 위해 연구자들은 유효 전이 데이터 (Effective Data Transferred, ) 라는 지표를 정의했습니다 [1]. 크기가 인 다운스트림 데이터셋으로 사전 학습 모델을 미세 조정하여 특정 검증 손실(Validation loss) 을 달성했다고 가정해 봅시다. 이때 다음과 같은 질문을 던질 수 있습니다. “정확히 동일한 아키텍처를 가진 모델을 처음부터 학습시켜 동일한 손실 에 도달하려면 몇 개의 데이터 포인트()가 필요할까?”
유효 전이 데이터는 단순히 이 둘의 차이입니다:
경험적 연구에 따르면 적은 데이터(Low-data) 영역에서 는 모델의 파라미터 수()와 미세 조정 데이터셋 크기()에 대해 멱법칙(Power law)의 형태로 스케일링됩니다:
이 방정식에는 심오한 공학적 의미가 담겨 있습니다. 이기 때문에, 파라미터 수 을 기하급수적으로 늘리면 전이되는 유효 데이터의 양도 기하급수적으로 증가합니다. 즉, 1,000억(100B) 개의 파라미터를 가진 모델은 100억(10B) 개의 파라미터를 가진 모델보다 1,000개의 미세 조정 예시로부터 훨씬 더 방대한 일반화된 효용성을 추출해 냅니다. 이것이 바로 거대한 파운데이션 모델이 놀라운 퓨샷 학습자(Few-shot learner)가 되는 이유입니다. 모델의 거대한 ‘스케일’ 자체가 미세 조정 데이터의 가치를 폭발적으로 증폭시키는 물리적 승수(Multiplier) 역할을 하는 것입니다.
그로킹: 지연된 일반화 (Grokking: The Delayed Generalization)
스케일링 법칙이 전이 학습의 거시적(Macroscopic) 행동을 설명한다면, 미시적(Microscopic) 학습 동역학은 훨씬 더 기이한 현상을 보여줍니다. 수년 동안 기계 학습 분야의 지배적인 가정은 ‘암기(Memorization)‘와 ‘일반화(Generalization)‘가 서로 반대되는 힘이며, 학습 손실이 감소함에 따라 일반화 성능도 부드럽게 향상된다는 것이었습니다.
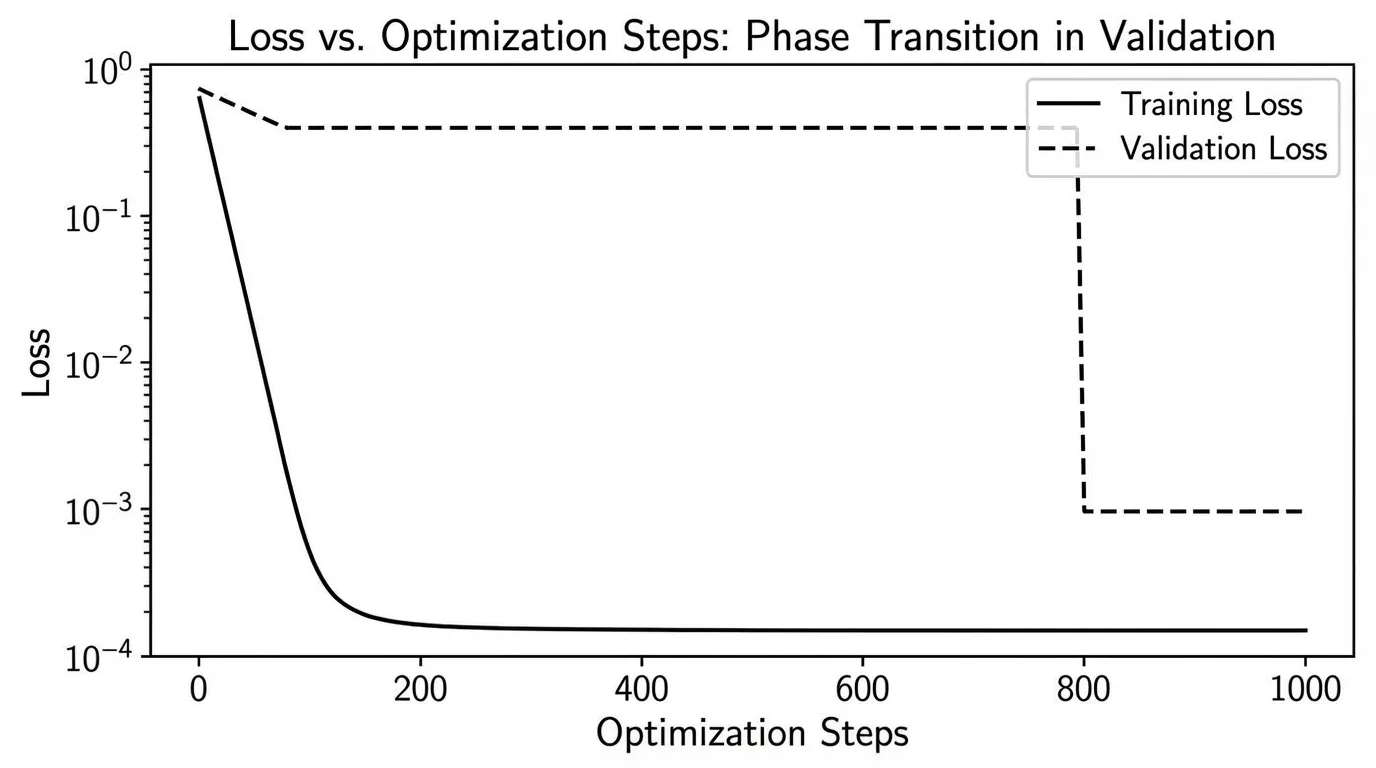
하지만 그로킹 (Grokking) [2] 현상의 발견은 이러한 가정을 완전히 산산조각 냈습니다. 특정 조건에서 모델은 훈련 데이터셋을 완벽하게 암기하여 훈련 손실(Training loss)을 거의 0으로 빠르게 떨어뜨리지만, 검증 손실(Validation loss)은 여전히 극도로 높은 상태에 머물러 있습니다. 만약 이 시점에서 학습을 중단한다면, 우리는 모델이 단순히 과적합(Overfitted)되었다고 판단할 것입니다. 그러나 훈련 손실이 평탄해진 이후에도 수천 스텝 동안 학습을 계속 진행하면, 어느 순간 검증 손실이 갑자기 수직 낙하하는 현상이 발생합니다. 모델이 데이터의 근본적인 규칙을 마침내 “깨달은(Grok)” 것입니다.
 Source: Power et al., 2022 [2]
Source: Power et al., 2022 [2]
최근의 이론적 돌파구 [3]는 이러한 지연 현상을 수학적으로 공식화했습니다. 그로킹은 마법이 아니라, 가중치 노름 (Norm) 에 의해 주도되는 표현적 상전이 (Representational phase transition) 입니다.
학습의 초기 단계에서 옵티마이저는 무차별적인 암기를 통해 훈련 데이터를 보간(Interpolate)하는 “게으른(Lazy)” 고-노름(High-norm) 솔루션을 찾습니다. 하지만 가중치 감쇠(Weight decay)와 같은 정규화(Regularizer) 기법은 이 고-노름 상태에 지속적으로 페널티를 부여합니다. 수천 스텝에 걸쳐 옵티마이저는 가중치를 서서히 수축(Contract)시킵니다. 가중치 노름이 특정 임계값 아래로 떨어지는 순간, 암기 회로(Memorization circuits)가 붕괴되고 네트워크는 보지 못한 데이터에도 일반화될 수 있는 저-노름(Low-norm)의 구조화된 표현을 강제로 채택하게 됩니다.
그로킹이 발생하기까지의 지연 시간()은 그 자체로 정밀한 스케일링 법칙을 따릅니다: 여기서 는 옵티마이저의 유효 수축률(예: SGD의 경우 학습률 가중치 감쇠)이며, 은 암기 시점의 가중치 노름, 는 일반화 솔루션의 가중치 노름입니다.
이는 일반화가 항상 즉각적으로 일어나는 것이 아님을 증명합니다. 복잡한 전이 학습 시나리오에서는, 겉보기에 수렴한 것처럼 보이는 시점 이후에 소비되는 연산량이야말로 견고하고 일반화 가능한 논리 회로를 결정짓는 핵심 요소가 될 수 있습니다.
Interactive: Grokking Phase Transition
훈련 손실(Training Loss)이 0에 도달한 후에도 검증 손실(Validation Loss)이 높게 유지되다가, 가중치 노름(Weight Norm)이 충분히 수축하면서 "그로킹(Grokking)" 상전이가 발생하는 과정을 관찰해 보세요.
약한 감독에서 강한 일반화로 (Weak-to-Strong Generalization)
모델의 스케일이 커짐에 따라 우리는 독특한 전이 학습의 병목 현상, 즉 정렬 문제 (The Alignment Problem) 에 직면하게 됩니다. 전통적으로 우리는 RLHF나 SFT를 통해 모델에게 인간의 의도를 전이시키며, 이때 인간은 ‘정답(Ground-truth)‘을 제공하는 감독자 역할을 합니다. 하지만 모델이 인간보다 훨씬 똑똑해지면 어떻게 될까요? 우리가 완전히 이해할 수 없는 출력을 내놓는 시스템을 어떻게 감독할 수 있을까요?
이를 경험적으로 연구하기 위해 연구자들은 약-강 일반화 (Weak-to-Strong Generalization) 라는 패러다임을 도입했습니다 [4]. 이 설정은 초인적 AI의 정렬(Superhuman alignment)을 위한 훌륭한 비유가 됩니다:
- 약하고 능력치가 떨어지는 모델(예: 1B 파라미터 모델)을 특정 작업에 대해 학습시킵니다.
- 이 약한 모델을 사용하여 노이즈가 많고 불완전한 라벨을 생성합니다.
- 오직 이 ‘약한 라벨’만을 사용하여 강력하고 능력이 뛰어난 사전 학습 모델(예: 100B 파라미터 모델)을 미세 조정합니다.
순진한 가정에 따르면, 강한 모델은 단순히 약한 모델을 모방하여 그 모든 오류와 환각적인 논리까지 그대로 물려받을 것입니다. 하지만 경험적인 현실은 훨씬 더 낙관적입니다. 강한 모델은 지속적으로 약한 감독자의 성능을 뛰어넘습니다.
그 이유는 무엇일까요? 강한 모델은 작업을 처음부터 새로 배우는 것이 아니기 때문입니다. 강한 모델은 약한 라벨을 단순히 작업의 형식(Format)과 의도(Intent) 를 연역하기 위한 힌트로만 사용하며, 실제 논리를 실행할 때는 자신만의 강력한 사전 학습된 잠재 표현(Latent representation)에 의존합니다. 즉, 약한 감독자가 남긴 빈틈을 채우기 위해 자신이 이미 가지고 있던 방대한 지식을 전이시키는 것입니다.
자신감 엔지니어링 (Engineering Confidence)
약-강 일반화(Weak-to-Strong generalization)를 극대화하기 위해 엔지니어는 강한 모델이 약한 감독자의 특정 오류에 과적합(Overfitting)되는 것을 막아야 합니다. 이를 위한 매우 효과적인 기법 중 하나가 바로 보조 신뢰도 손실 (Auxiliary Confidence Loss) 입니다.
강한 모델의 출력 분포에 대한 엔트로피(Entropy)를 최소화하는 페널티를 추가함으로써, 우리는 모델이 자신의 예측에 대해 높은 ‘자신감’을 갖도록 강제합니다. 이는 강한 모델이 자신의 잠재 지식을 신뢰하도록 장려하며, 결과적으로 약한 감독자가 명백한 오류를 범했을 때 그에 동의하지 않고 자신만의 정답을 밀고 나갈 수 있게 해줍니다.
다음 PyTorch 구현은 분류 기반의 정렬(Alignment) 작업에서 이 손실 함수가 어떻게 구성되는지 보여줍니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class WeakToStrongLoss(nn.Module):
"""
약-강 일반화(Weak-to-Strong generalization) 목적 함수를 구현합니다.
강한 학생(Student) 모델이 약한 감독자(Supervisor)의 소프트 라벨(Soft labels)로부터 배우도록 강제하는 동시에,
자신만의 잠재 표현에 대한 확신(Confidence)을 유지하도록 만듭니다.
"""
def __init__(self, confidence_coef: float = 0.2):
super().__init__()
# 강한 모델이 자신의 예측에 대해 얼마나 공격적으로 확신을 갖게 할지 제어하는 계수입니다.
self.confidence_coef = confidence_coef
def forward(
self,
strong_logits: torch.Tensor,
weak_soft_labels: torch.Tensor
) -> torch.Tensor:
"""
Args:
strong_logits: (Batch, Num_Classes) - 강한 모델의 원본 로짓(Logits).
weak_soft_labels: (Batch, Num_Classes) - 약한 모델의 확률 분포.
"""
# 1. 모방 손실 (Imitation Loss - KL Divergence)
# 약한 감독자의 지침을 기반으로 강한 모델에게
# 작업의 전반적인 의도와 형식을 가르칩니다.
log_probs_strong = F.log_softmax(strong_logits, dim=-1)
imitation_loss = F.kl_div(
log_probs_strong,
weak_soft_labels,
reduction='batchmean'
)
# 2. 보조 신뢰도 손실 (Auxiliary Confidence Loss - Entropy Minimization)
# 강한 모델 예측의 엔트로피를 최소화합니다.
# 이는 강한 모델이 약한 모델의 불확실성을 그대로 모방하는 것을 방지하고,
# 우수한 사전 학습 지식을 사용하여 "동의하지 않을" 수 있도록 장려합니다.
probs_strong = F.softmax(strong_logits, dim=-1)
entropy = -torch.sum(probs_strong * log_probs_strong, dim=-1).mean()
# 전체 목적 함수 (Total Objective)
total_loss = imitation_loss + self.confidence_coef * entropy
return total_loss
# --- 시뮬레이션 ---
torch.manual_seed(42)
batch_size, num_classes = 4, 10
# 약한 감독자(Weak supervisor)의 시뮬레이션된 예측 (높은 불확실성/엔트로피)
weak_logits = torch.randn(batch_size, num_classes) * 0.5
weak_soft_labels = F.softmax(weak_logits, dim=-1)
# 강한 사전 학습 모델(Strong pre-trained model)의 시뮬레이션된 원본 로짓
strong_logits = torch.randn(batch_size, num_classes) * 2.0
criterion = WeakToStrongLoss(confidence_coef=0.2)
loss = criterion(strong_logits, weak_soft_labels)
print(f"Weak-to-Strong Objective Loss: {loss.item():.4f}")일반화는 원시적인 연산량과 실제 지능을 연결하는 필수적인 다리입니다. 복잡한 데이터셋을 ‘그로킹’하기 위해 상전이(Phase transition)를 기다리는 것이든, 모델의 잠재 지식을 활용하여 감독자의 한계를 뛰어넘는 것이든, 이러한 전이 동역학(Transfer dynamics)을 숙달하는 것은 자율적이고 에이전트적인(Agentic) AI 시스템을 구축하기 위한 핵심 열쇠입니다.
파운데이션 모델 학습 파이프라인: 종합 (The Foundation Model Training Pipeline: A Synthesis)
데이터 엔지니어링(6장), 아키텍처(7장), 그리고 스케일링 동역학(8장)을 살펴보았으므로, 이제 파운데이션 모델의 전체 학습 프로세스를 하나의 통합된 파이프라인으로 종합할 수 있습니다.
원시 데이터에서 사전 학습된 모델로의 여정은 우리가 논의한 물리적 및 경제적 원칙에 의해 지배되는 일련의 신중하게 오케스트레이션된 단계들을 포함합니다.
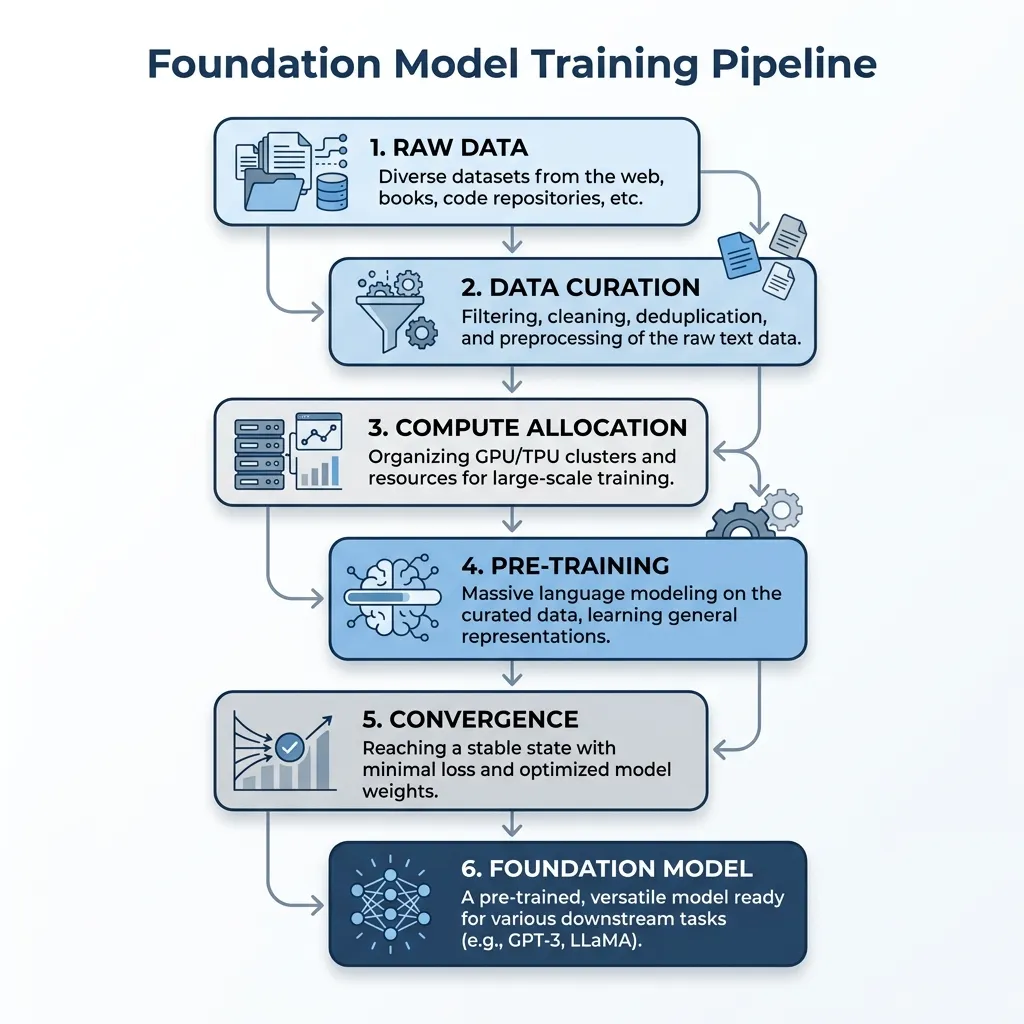
통합 워크플로우 (The Integrated Workflow)
- 기반으로서의 데이터: 프로세스는 정제되지 않은 원시 데이터에서 시작됩니다. 6장에서 보았듯이, 토크나이저의 선택과 데이터 필터링의 엄격함이 모델 능력의 상한선을 설정합니다. 고품질의 깨끗한 데이터는 타협할 수 없는 필수 조건입니다.
- 크기 조정 및 할당: 학습이 시작되기 전에 엔지니어들은 스케일링 법칙(8장)을 적용하여 연산량의 최적 할당을 결정합니다. 친칠라 최적성을 목표로 하든, 추론 효율성을 위해 과잉 학습을 하든, 이 단계에서 물리적 아키텍처와 토큰 예산이 정의됩니다.
- 분산된 도가니: 수십억 개의 파라미터를 가진 모델을 학습시키려면 수천 개의 GPU가 필요합니다. 모델은 토큰을 처리하고, 손실을 계산하며, 지속적으로 가중치를 업데이트합니다. 엔지니어들은 이상 징후를 감지하기 위해 예측된 멱법칙 곡선과 비교하여 학습 손실을 모니터링합니다.
- 결과: 이 거대한 작업의 결과물은 베이스 파운데이션 모델입니다. 이는 세상의 지식이 고도로 압축된 저장소이며, 이어지는 장들에서 전이 학습과 정렬을 통해 특정 과업에 맞게 형상화될 준비가 되어 있습니다.
8장 요약 및 개발자 인사이트
요약
이 장에서 우리는 파운데이션 모델의 스케일링 물리학을 탐구했습니다. 먼저 연산량, 데이터, 파라미터를 기반으로 모델 성능을 예측할 수 있게 해주는 멱법칙 (Power Law) (8.1)으로 시작했습니다. 그런 다음 파라미터와 데이터를 동일하게 스케일링할 것을 주장하여 초기 스케일링 법칙을 수정한 친칠라 최적성 (Chinchilla Optimality) (8.2)을 살펴보았습니다. 그러나 추론 비용이라는 경제적 현실로 인해, 치명적인 과잉 학습과 가소성 상실의 위험에도 불구하고 배포를 위해 더 작고 효율적인 모델을 만들기 위해 친칠라 최적점을 훨씬 넘어서 모델을 학습시키는 과잉 학습 (Over-training) (8.3)의 시대로 접어들었습니다. 마지막으로 전이 학습 및 일반화 (Transfer Learning and Generalization) (8.4)를 살펴보며, 스케일이 미세 조정 데이터의 승수로 작용하는 방식, 그로킹 현상, 그리고 강한 모델이 약한 감독을 넘어서 일반화하는 방법을 이해했습니다.
개발자 인사이트
- 친칠라를 맹목적으로 따르지 마세요: 대규모 배포를 목표로 한다면, 훈련 FLOPs를 낭비하더라도 더 작은 모델을 과잉 학습시키는 것이 종종 올바른 경제적 선택입니다.
- 가소성 모니터링: 과잉 학습을 진행할 때는 피셔 정보 행렬(Fisher Information Matrix)의 대각합이나 그래디언트 노름을 모니터링하여, 모델이 명령어 튜닝(Instruction-tuning)이 불가능한 “취약한(Brittle)” 영역으로 들어가지 않도록 하세요.
- 스케일은 데이터를 증폭합니다: 거대한 사전 학습 모델은 작은 모델과 동일한 성능을 달성하는 데 훨씬 적은 미세 조정 데이터를 필요로 합니다. 데이터 수집 비용을 아끼려면 스케일에 투자하세요.
- 그로킹은 시간이 걸립니다: 모델이 과적합된 것처럼 보이더라도 작업이 알고리즘적이거나 고도로 구조화되어 있다면 계속 학습시키세요. 일반화가 코앞에 다가왔을 수 있습니다.
Quizzes
Quiz 1: 전이 학습(Transfer learning)에 대한 경험적 스케일링 법칙에 따르면, 사전 학습된 모델의 파라미터 수()가 증가할 때 유효 전이 데이터()에는 어떤 변화가 일어납니까?
유효 전이 데이터는 파라미터 수에 대해 멱법칙()으로 증가합니다. 이는 모델의 크기가 커질수록 미세 조정 데이터에서 추출하는 가치가 기하급수적으로 증폭되기 때문에, 더 작은 모델과 동일한 다운스트림 성능을 달성하는 데 필요한 미세 조정 데이터의 양이 기하급수적으로 줄어듦을 의미합니다.
Quiz 2: 그로킹(Grokking)의 맥락에서, 훈련 손실(Training loss)이 이미 0에 도달한 후 수천 스텝이 지나서야 검증 손실(Validation loss)이 갑자기 떨어지는 이유는 무엇입니까?
그로킹은 표현적 상전이(Representational phase transition)에 의해 주도됩니다. 초기에는 옵티마이저가 훈련 데이터를 완벽하게 암기하는 “게으른” 고-노름(High-norm) 솔루션을 찾습니다. 하지만 학습이 계속되면서 가중치 감쇠와 같은 정규화 기법이 가중치를 서서히 수축시킵니다. 가중치 노름이 임계값 아래로 떨어지면 암기 회로가 붕괴되고, 네트워크는 보지 못한 데이터에도 일반화할 수 있는 저-노름의 구조화된 표현으로 전환되기 때문입니다.
Quiz 3: 약-강 일반화(Weak-to-Strong Generalization) 과정에서, 작은 GPT-2 급 모델이 생성한 노이즈가 많은 라벨만으로 거대한 GPT-4 급 모델을 미세 조정할 때, 왜 강한 모델의 성능이 약한 모델 수준으로 똑같이 떨어지지 않습니까?
강한 모델은 작업을 처음부터 새로 배우는 것이 아니기 때문입니다. 강한 모델은 약한 라벨을 주로 작업의 형식과 의도를 파악하는 데 사용합니다. 하지만 입력값을 실제로 처리하고 논리를 실행할 때는 자신이 이미 가지고 있는 훨씬 우수한 사전 학습된 잠재 표현(Latent representation)에 의존하므로, 약한 감독자의 오류를 넘어서 일반화하고 자신의 지식을 이끌어낼 수 있습니다.
Quiz 4: 약-강 미세 조정(Weak-to-Strong fine-tuning) 중에 엔트로피 최소화(Entropy minimization)와 같은 보조 신뢰도 손실(Auxiliary Confidence Loss)을 추가하는 기계적인 목적은 무엇입니까?
보조 신뢰도 손실은 강한 모델이 약한 감독자의 불확실성과 특정 오류에 과적합되는 것을 방지합니다. 강한 모델이 자신의 예측에 대해 높은 확신을 갖도록 강제함으로써, 모델이 자신의 잠재 지식을 신뢰하게 만들고, 약한 감독자가 틀렸을 때 그에 동의하지 않고 자신의 정답을 밀고 나갈 수 있는 용기를 부여합니다.
References
- Hernandez, D., et al. (2021). Scaling Laws for Transfer. arXiv:2102.01293.
- Power, A., et al. (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. arXiv:2201.02177.
- Tian, Y. (2026). Why Grokking Takes So Long: A First-Principles Theory of Representational Phase Transitions. arXiv:2603.13331.
- Burns, C., et al. (2023). Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision. arXiv:2312.09390.