3.2 Multi-head Attention (MHA)
Self-Attention은 강력하지만, 이를 한 번만 적용하는 것(Single-Head)은 모델이 다양한 유형의 관계에 동시에 집중하는 능력을 제한합니다. Multi-Head Attention (MHA) 은 여러 개의 어텐션 매커니즘을 병렬로 실행하여 이 문제를 해결합니다.
이것을 비유를 통해 이해해 봅시다.
비유: 전문가 위원회
당신이 복잡한 법률 문서를 분석하고 있다고 가정해 봅시다.
- Single-Head Attention은 한 명의 일반 연구원 에게 문서를 읽게 하는 것과 같습니다. 그들은 잘 해낼 수 있지만, 한 번에 하나의 측면(예: 전반적인 의미)에만 집중할 수 있습니다.
- Multi-Head Attention은 전문가 위원회 를 고용하는 것과 같습니다:
- 전문가 1 은 법률 용어 에 집중합니다.
- 전문가 2 는 재정적 영향 에 집중합니다.
- 전문가 3 은 역사적 배경 에 집중합니다.
그들은 모두 동시에 같은 문서를 읽지만 서로 다른 측면에 주의(attend)를 기울입니다. 결국 그들은 결과를 결합하여 훨씬 더 풍부한 분석을 제공합니다.
MHA에서 각 “헤드(head)“는 서로 다른 유형의 관계(예: 문법, 상호 참조, 사실적 연결)에 주의를 기울이는 법을 배웁니다.
왜 Multi-Head인가? (표현 서브스페이스)
Multi-Head Attention의 이점을 이해하기 위해 “bank”라는 단어를 생각해 봅시다. 이 단어는 금융 기관을 의미할 수도 있고 강의 기슭을 의미할 수도 있습니다.
- 단일 헤드 어텐션 매커니즘에서는 모델이 “bank”에 대해 하나의 어텐션 분포를 만들어야 합니다. 만약 모델이 금융 문맥(“money”와 관련된)과 구문론적 문맥(앞에 나오는 관사 “The”와 관련된)을 모두 포착해야 한다면, 타협을 해야 합니다.
- Multi-Head Attention을 사용하면 한 헤드는 의미적 관계 (bank money)에 집중할 수 있고, 다른 헤드는 구문적 관계 (bank The)에 집중할 수 있습니다.
차원의 임베딩을 개의 더 작은 차원 의 서브스페이스(subspaces)로 투영함으로써, 각 헤드는 다른 패턴의 방해를 받지 않고 특정 유형의 패턴을 찾는 데 특화될 수 있습니다. 이는 CNN이 여러 필터를 사용하여 서로 다른 시각적 특징(예: 가장자리, 질감)을 감지하는 것과 유사합니다.
Multi-Head Attention의 수학적 원리
차원의 키, 밸류, 쿼리로 단일 어텐션을 수행하는 대신, MHA는 쿼리, 키, 밸류를 서로 다른 학습된 선형 투영(linear projections)을 통해 번 선형 투영하여 각각 차원으로 만듭니다.
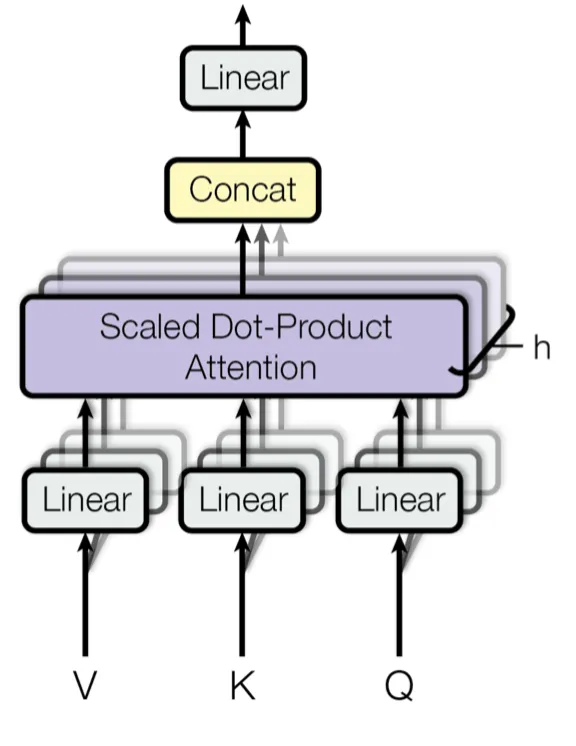
여기서:
그리고 투영 행렬들은 다음과 같은 파라미터 행렬입니다:
일반적으로 개의 병렬 어텐션 헤드를 사용합니다. 이들 각각에 대해 를 사용합니다.
PyTorch 구현
다음은 PyTorch에서 Multi-Head Attention을 구현하는 방법입니다. 여기에는 입력 투영, 여러 헤드로 분할, 어텐션 적용, 그리고 결과 연결이 포함됩니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# Q, K, V를 위한 선형 투영
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# 출력 투영
self.w_o = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 1. 선형 투영
Q = self.w_q(q)
K = self.w_k(k)
V = self.w_v(v)
# 2. 헤드로 분할
# Shape change: (batch, seq_len, d_model) -> (batch, seq_len, num_heads, d_k) -> (batch, num_heads, seq_len, d_k)
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 3. Scaled Dot-Product Attention 적용
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = F.softmax(scores, dim=-1)
attention_output = torch.matmul(weights, V)
# 4. 헤드 연결 (Concatenate)
# Shape change: (batch, num_heads, seq_len, d_k) -> (batch, seq_len, num_heads, d_k) -> (batch, seq_len, d_model)
concat_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 5. 출력 투영
output = self.w_o(concat_output)
return output, weights
# 예제 사용법
mha = MultiHeadAttention(d_model=64, num_heads=8)
x = torch.randn(2, 10, 64) # 배치 크기 2, 시퀀스 길이 10, d_model 64
output, weights = mha(x, x, x)
print("Output Shape:", output.shape)
print("Attention Weights Shape:", weights.shape)예제: 다양한 관점
두 개의 서로 다른 헤드가 “The bank was full of money.”라는 문장에 어떻게 주의를 기울이는지 시각화해 보세요.
- Head 1 은 “bank”를 “money”와 연관시키는 법을 배울 수 있습니다 (금융 문맥).
- Head 2 는 “bank”를 “The”와 같은 문법적 요소와 연관시키는 법을 배울 수 있습니다.
단어 “bank” 에 대한 시뮬레이션된 attention 패턴을 보려면 헤드를 선택하세요.
Quizzes
Quiz 1: 왜 하나의 큰 어텐션 헤드 대신 여러 개의 작은 헤드를 사용하나요?
여러 헤드를 사용하면 모델이 서로 다른 위치에서 서로 다른 표현 서브스페이스(representation subspaces)의 정보에 주의를 기울일 수 있습니다. 하나의 큰 헤드는 하나의 어텐션 가중치 집합만 계산할 수 있으므로 여러 유형의 관계를 평균화해야 하므로 표현력이 떨어질 수 있습니다.
Quiz 2: MHA에서 출력 투영 의 목적은 무엇인가요?
모든 헤드의 출력을 연결(concatenate)한 결과는 차원(일반적으로 과 같음)을 갖습니다. 출력 투영 는 모든 헤드의 정보를 혼합하고 이를 다시 공간으로 투영하여 네트워크가 결합된 정보를 효과적으로 사용할 수 있도록 하는 학습된 선형 변환입니다.
Quiz 3: 만약 이고 개의 헤드가 있다면, 각 헤드에 대한 의 차원은 얼마인가요?
일반적으로 로 설정합니다. 따라서 각 헤드에 대해 차원은 가 됩니다.
Quiz 4: 총 차원이 같을 때 Multi-Head Attention의 계산 비용은 Single-Head Attention과 어떻게 비교됩니까?
각 헤드의 차원이 줄어들기 때문에(), Multi-Head Attention의 총 계산 비용은 전체 차원을 사용하는 Single-Head Attention과 비슷합니다. 이러한 연산들은 GPU에서 효과적으로 배치 처리 및 병렬화될 수 있습니다.
Quiz 5: 헤드를 연결한 후 출력 투영 를 사용하지 않으면 어떤 일이 발생할까요?
출력 투영 가 없다면 모델은 서로 다른 헤드에서 얻은 독립적인 특징들을 어떻게 결합하거나 혼합할지 배우지 못하고 단순히 연결하기만 할 것입니다. 는 모델이 서로 다른 헤드 간의 상호 작용을 학습할 수 있게 해줍니다.
Quiz 6: 와 의 요소들이 독립이고 평균 0, 분산 1인 확률 변수라고 가정할 때, 점곱 의 분산이 임을 수학적으로 증명하고 스케일링 인자가 분산을 어떻게 1로 복원하는지 설명하시오.
벡터의 각 요소가 독립적인 확률 변수이며 및 을 만족한다고 가정해 봅시다. 두 벡터의 점곱은 입니다. 와 가 독립이므로, 입니다. 독립 변수 곱의 분산은 입니다. 각 요소가 독립적이므로, 합의 분산은 각 분산의 합과 같습니다: . 이를 로 나누면, 분산은 이 됩니다. 이 스케일링은 차원이 커질 때 소프트맥스 함수가 매우 작은 기울기를 갖는 영역으로 포화(Saturation)되는 것을 방지합니다.
References
- Vaswani, A., et al. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). arXiv:1706.03762.