4.2 Decoder-only (GPT-style)
Encoder-only 모델이 AI 세계의 탐정이라면, Decoder-only 모델은 즉흥적으로 이야기를 이어 가는 작가에 가깝습니다. 전체 대본을 미리 볼 수 없고, 지금까지 나온 문장만 바탕으로 바로 다음 단어를 정해야 하기 때문입니다.
이 제약은 의외로 엄청난 힘이 있습니다. GPT 계열을 통해 널리 알려진 뒤 많은 LLM이 이 구조를 채택한 이유도, decoder-only가 유일한 Transformer 구조여서가 아니라 자기회귀적 설정이 스케일링과 서빙에 잘 맞고, 사용자가 실제로 모델과 상호작용하는 방식인 “프롬프트를 주고 이어서 생성하게 하기”와 잘 맞아떨어졌기 때문입니다.
이 장에서는 decoder-only 아키텍처의 구조, autoregressive generation의 원리, 그리고 왜 이 방식이 스케일링 경쟁에서 큰 우위를 점했는지를 설명합니다.
The Metaphor: The Autoregressive Storyteller (Autoregressive 이야기꾼)
지금까지 쓴 내용만 볼 수 있고, 바로 다음 단어를 예측하는 것이 목표인 이야기를 쓰고 있다고 상상해 보세요. 일단 그 단어를 예측하면 그것은 역사의 일부가 되고, 여러분은 그것을 사용하여 그 다음 단어를 예측합니다.
이것이 바로 Autoregressive Generation (자기회귀 생성)입니다. Decoder-only 모델은 이 원칙에 따라 작동합니다. 그들은 미래를 내다볼 수 없으며, 오직 과거에만 접근할 수 있습니다. 이로 인해 유창하고 일관되며 창의적인 텍스트를 생성하는 데 탁월한 성능을 발휘합니다.
Causal Self-Attention: Masking the Future
이러한 동작을 가능하게 하는 핵심 메커니즘은 Causal Self-Attention (인과적 셀프 어텐션 또는 마스킹된 셀프 어텐션)입니다. 모든 토큰이 서로 연결되는 Encoder-only 모델의 all-to-all 연결성과 달리, Causal Attention은 어텐션 행렬에 마스크를 적용하여 토큰 가 이하의 위치에 있는 토큰에만 어텐션을 기울일 수 있도록 합니다.
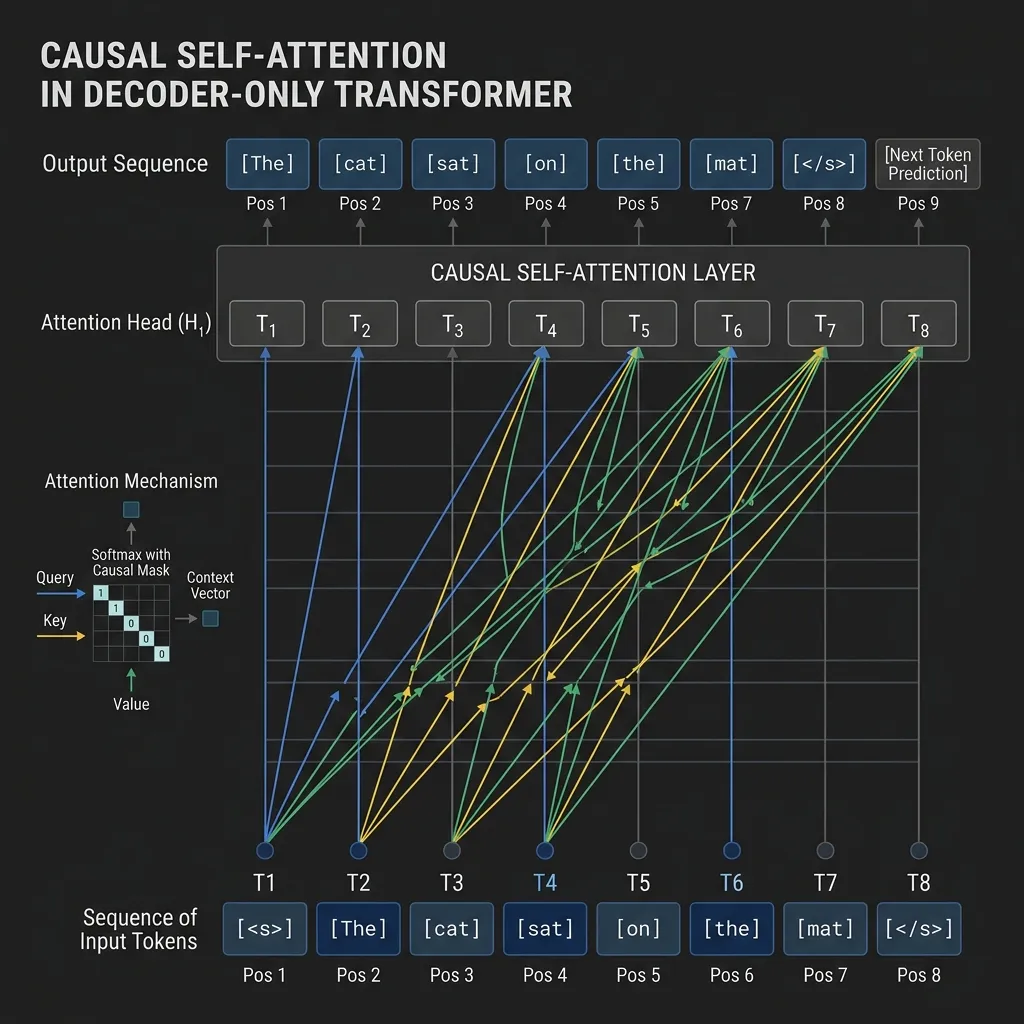
다이어그램에 표시된 것처럼 어텐션 연결은 오른쪽에서 왼쪽(과거에서 현재) 또는 토큰 자체로만 이어집니다. 이는 학습 중에 정보가 미래 토큰으로부터 거꾸로 흐르는 것을 방지합니다.
Core Training Objective: Causal Language Modeling (CLM)
Decoder-only 모델은 Causal Language Modeling (CLM), 즉 다음 토큰 예측 과업으로 학습됩니다.
토큰 시퀀스 가 주어지면, 목표는 확률의 연쇄 법칙(chain rule)을 사용하여 분해할 수 있는 시퀀스의 가능도(likelihood)를 최대화하는 것입니다.
CLM의 수학적 정의
손실 함수는 각 위치에서 올바른 다음 토큰의 음의 로그 가능도(negative log-likelihood)입니다.
여기서 는 위치 이전의 모든 토큰을 나타냅니다. 이 목표는 단순하지만 방대한 양의 데이터 및 연산량과 결합하여 스케일업되었을 때 믿을 수 없을 정도로 강력해집니다.
Evolution and Key Models
1. GPT-3 (2020)
Motivation: GPT-3 이전의 지배적인 패러다임은 대규모 코퍼스에서 모델을 사전 학습한 다음, 특정 작업에 맞는 데이터로 미세 조정(fine-tuning)하는 것이었습니다. GPT-3의 제작자들은 충분히 큰 언어 모델이 프롬프트를 이해하는 것만으로도 작업별 데이터 없이도 작업을 수행할 수 있는 “In-Context Learning”을 수행할 수 있다는 가설을 테스트하고자 했습니다 [1].
핵심 혁신 (Key Innovations):
- 거대한 스케일: Decoder-only 아키텍처를 GPT-2보다 100배 증가한 1750억 개의 파라미터로 스케일링했습니다.
- In-Context Learning: 대규모 모델이 그래디언트 업데이트나 미세 조정 없이도 제로샷, 원샷, 퓨샷 학습을 수행할 수 있음을 보여주었습니다.
- 프롬프팅 패러다임: 초점을 미세 조정에서 프롬프트 엔지니어링으로 전환하여 입력 텍스트에 의해 모델의 행동이 유도되도록 했습니다.
2. Llama 3 (2024)
Motivation: 거대 독점 모델들이 시장을 지배하는 동안, Meta는 고품질의 오픈 가중치(open-weights) 모델을 출시하여 AI 연구를 민주화하고자 했습니다. Llama 3의 목표는 더 작은 모델이라도 훨씬 더 많은 데이터로 학습시키면 훨씬 더 큰 모델의 성능과 일치하거나 능가할 수 있음을 증명하여 배포 효율성을 높이는 것이었습니다.
핵심 혁신 (Key Innovations):
- 조 단위 규모의 사전 학습: 15조 개 이상의 토큰 데이터로 학습되어(GPT-3의 약 3000억 개 대비), 대부분의 모델이 파라미터 수에 비해 과소적합되었음을 보여주었습니다 [2].
- 그룹화된 쿼리 어텐션 (Grouped Query Attention, GQA): GQA를 사용하여 추론 효율성을 높이고 메모리 대역폭 요구 사항을 줄였습니다.
- 고품질 토크나이저: 128k 토큰의 어휘를 가진 토크나이저를 사용하여 텍스트 인코딩 효율성을 향상시켰습니다.
Decoder-only 모델 비교
| 특징 | GPT-3 (175B) | Llama 3 (8B/70B) |
|---|---|---|
| 파라미터 수 | 1750억 개 | 8B / 70B |
| 학습 토큰 수 | ~3000억 개 | 15조 개 이상 |
| 접근성 | 폐쇄형 (API) | 오픈 가중치 (Open Weights) |
| 어텐션 | 표준 | 그룹화된 쿼리 어텐션 (GQA) |
| 컨텍스트 길이 | 2,048 토큰 | 8,192 토큰 |
Why Decoder-Only Won the Scaling War (왜 Decoder-Only가 승리했는가)
Transformer의 초기 시절에는 Encoder-Decoder 모델(T5 등)이 더 다재다능한 것으로 여겨졌습니다. 그러나 현재 생성형 AI 시장은 Decoder-only 모델이 완전히 지배하고 있습니다. 그 이유에 대한 심층적인 분석은 다음과 같습니다.
1. The Power of a Unified Objective (통합된 목표의 힘)
Decoder-only 모델은 오직 ‘다음 토큰 예측(Next-Token Prediction)’ 이라는 단 하나의 목표로 학습됩니다. 이 목표는 매우 단순해 보이지만, 방대한 데이터와 결합하여 모델 크기를 키웠을 때(Scaling) 놀라운 창발적 능력(Emergent Abilities) 을 보여주었습니다. 복잡한 추론, 코드 생성, 번역 등 모든 고등 지능이 결국 ‘다음에 올 가장 자연스러운 말’을 찾는 과정에서 파생될 수 있음이 증명되었습니다.
2. Architectural Simplicity and Scaling (아키텍처의 단순성과 스케일링)
- 균일성(Uniformity): 별도의 Encoder와 Decoder를 두지 않고 동일한 Transformer 블록을 길게 쌓는 구조입니다. 이는 하드웨어(GPU) 가속 및 분산 학습(Distributed Training)을 구현할 때 엔지니어링 복잡도를 획기적으로 낮춰줍니다.
- 컨텍스트 윈도우의 유연한 활용: Encoder-Decoder 구조는 입력(Encoder)과 출력(Decoder)의 길이가 분리되어 처리되는 경우가 많습니다. 반면 Decoder-only는 입력(프롬프트)과 출력(생성 결과)이 하나의 시퀀스로 취급되므로, 제한된 컨텍스트 윈도우 내에서 프롬프트와 생성 결과의 비율을 유연하게 조절할 수 있습니다.
3. In-Context Learning and Prompting (인컨텍스트 러닝과 프롬프팅)
Decoder-only 모델을 스케일업하면서 발견된 가장 놀라운 현상 중 하나는 In-Context Learning 입니다. 모델의 가중치(Weights)를 수정하지 않고도, 프롬프트에 몇 가지 예시(Few-shot)를 제공하는 것만으로도 새로운 과업을 수행할 수 있습니다. 이는 모델이 단순히 데이터를 암기하는 것을 넘어, 문맥을 ‘이해’하고 ‘추론’하는 능력을 갖추었음을 보여줍니다.
4. Zero-overhead for Task Specificity (과업 특화 오버헤드 제로)
Encoder-Decoder 모델은 번역, 요약 등 특정 과업에 맞춰 입출력 포맷을 설계해야 하는 경우가 많았습니다. 반면 Decoder-only 모델은 모든 문제를 ‘텍스트 이어 쓰기’라는 하나의 인터페이스로 통합했습니다. 질문을 던지면 답을 이어 쓰고, 코드를 짜달라고 하면 코드를 이어 씁니다. 이러한 범용성이 현대 LLM의 핵심 경쟁력이 되었습니다.
5. KV Caching Efficiency (KV 캐싱의 효율성)
생성(Inference) 단계에서 Decoder-only 모델은 이전 단계에서 계산된 Key와 Value를 캐싱(KV Caching)하여 재사용합니다. 이는 매 토큰 생성 시점마다 과거의 모든 토큰을 다시 계산할 필요가 없게 만들어주어, 긴 텍스트를 생성할 때 매우 효율적입니다. 인코더-디코더도 인코더의 출력을 캐싱하지만, 디코더 온리는 단일 시퀀스 내에서 모든 컨텍스트를 처리하므로 메모리 관리가 더 직관적입니다.
PyTorch Implementation: Causal Mask
다음은 토큰이 미래에 어텐션을 기울이지 못하도록 PyTorch에서 causal mask를 생성하는 방법입니다.
import torch
def create_causal_mask(seq_len):
"""
Create a 2D causal mask for self-attention.
Shape: (seq_len, seq_len)
"""
# torch.tril creates a lower triangular matrix
mask = torch.tril(torch.ones(seq_len, seq_len))
return mask
# Example usage
seq_len = 5
mask = create_causal_mask(seq_len)
print("Causal Mask:")
print(mask)
# In practice, we often use this mask to fill scores with -inf before softmax
scores = torch.randn(seq_len, seq_len)
masked_scores = scores.masked_fill(mask == 0, float('-inf'))
print("\nMasked Scores (before softmax):")
print(masked_scores)Quizzes
Quiz 1: BERT와 GPT의 어텐션 메커니즘의 가장 큰 차이점은 무엇입니까?
BERT는 bidirectional self-attention을 사용하여 토큰이 과거와 미래 토큰 모두에 어텐션을 기울일 수 있도록 합니다. 반면 GPT는 causal (masked) self-attention을 사용하여 토큰이 과거와 현재 토큰에만 어텐션을 기울이도록 제한합니다.
Quiz 2: Decoder-only 모델이 Encoder-only 모델보다 제로샷 및 퓨샷 학습에 더 적합한 이유는 무엇입니까?
Decoder-only 모델은 프롬프트를 기반으로 다음 토큰을 예측하도록 학습됩니다. 이 학습 목표는 모델이 프롬프트에 제공된 컨텍스트를 기반으로 시퀀스를 이어가는 제로샷 및 퓨샷 프롬프팅과 완벽하게 일치합니다.
Quiz 3: “autoregressive generation”이란 무엇이며 어떻게 작동합니까?
Autoregressive 생성은 시퀀스를 한 번에 하나의 토큰씩 생성하는 과정입니다. 모델은 이전 토큰들을 기반으로 다음 토큰을 예측하고, 생성된 토큰은 다음 예측 단계를 위해 입력에 추가됩니다.
Quiz 4: Causal mask를 적용하면 왜 어텐션 스코어에서 1로 이루어진 하삼각행렬(lower triangular matrix)이 생성됩니까?
하삼각행렬은 주 대각선과 그 아래에는 1이 있고 그 위에는 0이 있습니다. 이는 위치가 위치에만 어텐션을 기울일 수 있도록 보장합니다. 대각선 위의 0은 미래 토큰에 대한 어텐션을 차단합니다.
Quiz 5: Encoder-only 모델과 비교하여 Decoder-only 모델의 단점 한 가지를 언급해 보세요.
Decoder-only 모델은 전체 컨텍스트를 한 번에 고려하기보다는 정보를 단방향으로 처리하기 때문에, 고정된 텍스트 본문을 동시에 이해해야 하는 과업(예: 분류 또는 검색)에는 일반적으로 덜 효율적입니다.
Quiz 6: 자기회귀(Autoregressive) 추론 과정에서 Decoder-only 모델의 KV 캐시(KV Cache)에 필요한 VRAM 용량(기가바이트 단위)을 계산하는 명시적인 공식을 유도하시오.
KV 캐시는 각 레이어에서 모든 과거 토큰의 Key와 Value를 저장합니다. 배치 크기를 , 시퀀스 길이를 , 레이어 수를 , Key/Value 헤드 수를 , 각 헤드의 차원을 , 정밀도 바이트 수를 (예: FP16/BF16의 경우 2)라고 합시다. 저장해야 하는 총 원소의 수는 입니다. 기가바이트(GB) 단위의 VRAM 용량은 다음과 같이 계산됩니다: . 예를 들어, 인 표준 MHA 구조의 7B 모델 ()을 FP16, 배치 크기 1, 시퀀스 길이 2048로 추론할 때 필요한 용량은 입니다.
References
- Brown, T., et al. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165.
- Dubey, A., et al. (2024). The Llama 3 Herd of Models. arXiv:2407.21783.