14.1 어휘 검색에서 시맨틱 검색으로
13장에서는 양자화와 압축을 통해 대규모 언어 모델을 더 작고 빠르게 만드는 방법을 탐구했습니다. 이러한 기술을 통해 제한된 하드웨어에서 강력한 모델을 실행할 수 있지만, 모든 파운데이션 모델의 근본적인 한계인 정적 파라미터 지식 (static parametric knowledge) 은 해결하지 못합니다.
모델의 지식은 훈련이 끝나는 시점에 고정됩니다. 그 날짜 이후의 이벤트에 대한 질문에 답할 수 없으며, 사용자의 개인 데이터나 비공개 문서에도 접근할 수 없습니다.
이 격차를 메우기 위해 우리는 검색 증강 생성 (Retrieval-Augmented Generation, RAG) 이 필요합니다. 세상의 모든 지식을 모델의 파라미터에 밀어 넣으려는 대신(이는 비용이 많이 들고 환각 현상을 유발합니다), RAG는 모델이 질의 시점에 외부 데이터베이스에서 관련 정보를 동적으로 검색할 수 있도록 합니다.
이 장은 모델 자체를 최적화하는 것에서 그 주변에 검색 인프라 를 구축하는 것으로의 전환을 의미합니다. 우리는 키워드 매칭에서 의미 매칭으로의 근본적인 전환을 이해하는 것부터 시작합니다.
정보 검색의 초기 시절에는 관련 문서를 찾는 것이 거의 전적으로 Lexical Search (키워드 검색) 에 의존했습니다. 이 접근 방식은 1세대 검색 엔진과 데이터베이스 쿼리의 기반이 되었지만, 현대의 RAG 시스템에 적용할 때는 근본적인 한계가 있습니다. 사용자의 의도를 진정으로 이해하는 시스템을 구축하기 위해서는 단어 를 검색하는 것에서 의미 를 검색하는 것으로 전환해야 합니다.
이 서브 챕터에서는 왜 벡터 임베딩이 필요한지 설명하고, 키워드 검색과 시맨틱 검색을 인터랙티브 데모와 함께 비교하며, 검색을 위해 데이터를 준비하는 고급 청킹(Chunking) 전략을 탐구합니다.
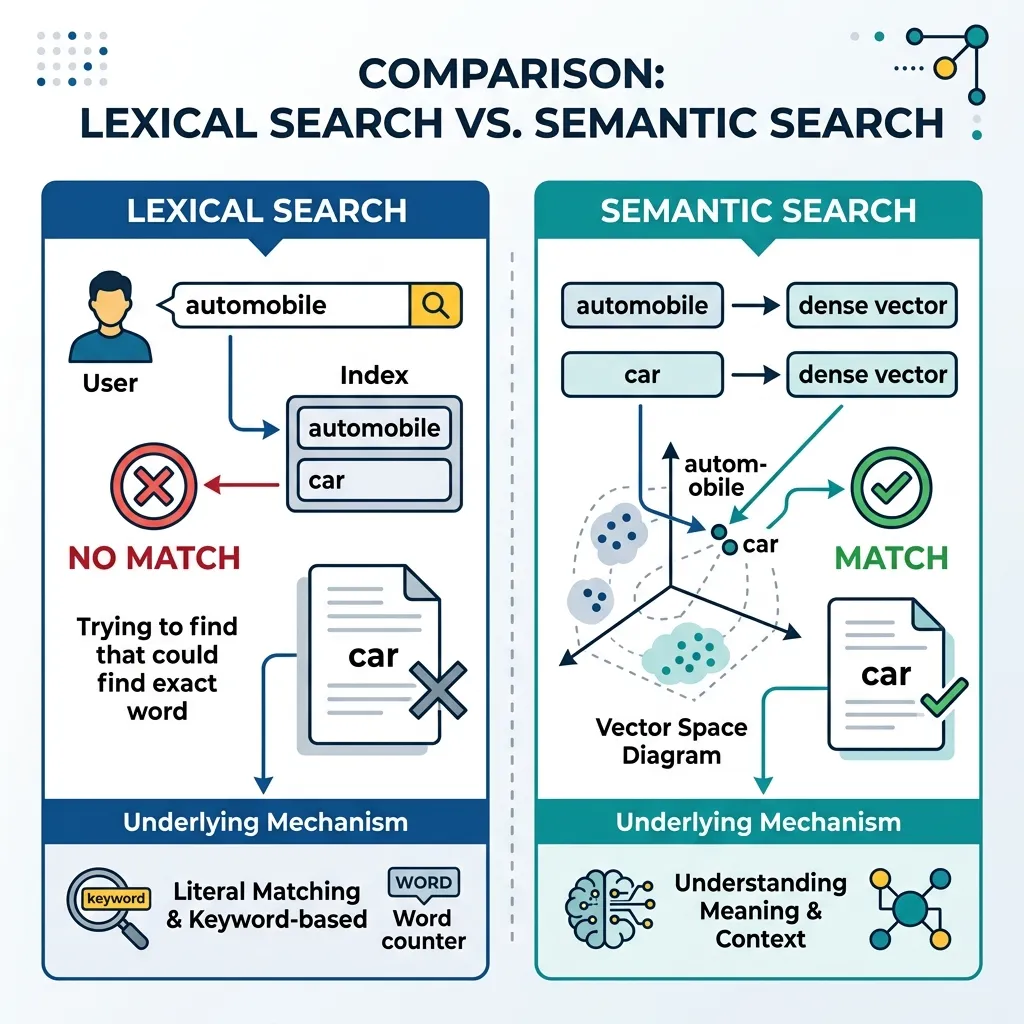
1. 키워드 검색의 한계
Lexical search 는 정확한 문자열 매칭 또는 퍼지(fuzzy) 문자열 매칭의 원칙에 따라 작동합니다. TF-IDF 나 BM25 와 같은 알고리즘은 용어 빈도(term frequency)와 역문서 빈도(inverse document frequency)를 계산하여 문서의 순위를 매깁니다. 이러한 방식은 매우 최적화되어 있고 빠르지만, 다음과 같은 몇 가지 중요한 시나리오에서는 실패합니다.
A. 동의어 문제 (Vocabulary Mismatch)
사용자가 “automobile”을 검색했지만 소스 문서에는 “car”라는 단어가 사용된 경우, 엄격한 lexical search 는 두 단어의 의미가 동일함에도 불구하고 이들을 연결하지 못합니다. 이를 어휘 불일치(vocabulary mismatch)라고 합니다.
B. 다의어 (Context Blindness)
“bank”라는 단어는 금융 기관을 의미할 수도 있고 강둑을 의미할 수도 있습니다. Lexical search 는 추가적인 문맥 단어 없이는 이러한 의미를 구별할 수 없으므로 종종 관련 없는 결과를 반환합니다.
C. 교차 언어(Cross-Lingual)의 한계
키워드 검색은 엄격하게 쿼리의 언어에 종속됩니다. 영어로 검색하면 내용이 사용자가 정확히 필요로 하는 것일지라도 한국어나 스페인어로 작성된 관련 문서를 검색할 수 없습니다.
D. 해결책: Vector Embeddings
이러한 한계를 극복하기 위해 우리는 텍스트를 기하학적 거리가 의미적 유사성에 대응하는 고차원 벡터로 표현합니다. 임베딩 모델(예: 미세 조정된 BERT 또는 현대의 대조 학습 모델)은 “automobile”과 “car”의 개념을 벡터 공간에서 가까운 점으로 매핑하여 동의어 문제를 해결하고 교차 언어 검색을 가능하게 합니다.
2. 인터랙티브 개념: Lexical vs. Semantic Search
이러한 트레이드오프를 이해하기 위해 개념도를 살펴보고 아래의 시각화 도구와 상호작용해 보세요. 다양한 주제를 다루는 작은 문서 데이터베이스가 있습니다.
텍스트에 명시적으로 언급되지 않은 개념을 검색하여(예: 텍스트에는 “young dog”라고 되어 있을 때 “puppy” 검색) semantic search 가 어떻게 빛을 발하는지 확인해 보세요. 또한 특정 제품 코드와 같이 키워드 검색이 여전히 필요할 수 있는 부분도 관찰해 보세요.
Semantic vs. Keyword Search
Try the preset queries to see the difference in behavior.
💡 Observations
- Search for "flat tire": Keyword search fails (vocabulary mismatch), but Semantic search finds both English and Korean documents (cross-lingual).
- Search for "XJ-992-B": Keyword search finds it perfectly. Semantic search gives low scores because it struggles with specific rare tokens like product codes.
키워드의 보루: 특정 정보에 대한 정밀도
위에서 보여주듯이, semantic search 는만병통치약이 아닙니다. 일련번호, 부품 코드 또는 희귀한 고유 명사와 같이 매우 구체적인 토큰을 일반적인 범주로 “흐리게(blur)” 만드는 경향이 있습니다. 예를 들어, Err-404를 검색하면 해당 정확한 문자열이 포함된 특정 로그 항목을 검색하는 대신 일반적인 “웹 오류”에 대한 문서를 검색할 수 있습니다.
이것이 엔터프라이즈 RAG 시스템이 거의 항상 Hybrid Search (두 방법을 모두 결합)를 사용하는 이유이며, 이는 14.3절에서 다룰 예정입니다.
3. 고급 청킹(Chunking) 전략
텍스트를 임베딩하고 벡터 데이터베이스에 저장하기 전에, 우리는 큰 문서를 Chunks 라고 하는 작고 일관된 조각으로 나누어야 합니다. 데이터를 청킹하는 방식은 검색 품질에 극적인 영향을 미칩니다.
A. 단순 (Fixed-Size) Chunking
가장 단순한 접근 방식은 텍스트를 고정된 수의 토큰(예: 256 토큰)으로 나누고, 문장이 중간에 잘리는 것을 방지하기 위해 작은 겹침(overlap)(예: 20 토큰)을 두는 것입니다.
- 장점: 구현이 간단하고 컴퓨팅 비용을 예측할 수 있습니다.
- 단점: 종종 의미적 일관성을 깨뜨려 단락이나 목록이 두 개의 청크로 나뉘어져 문맥을 잃게 만듭니다.
B. 계층적 (Hierarchical) Chunking
모든 청크를 동등하게 취급하는 대신, 계층적 청킹은 문서 구조를 유지합니다.
- Summary Chunk: 큰 섹션(예: 전체 장)의 상위 수준 요약.
- Detail Chunks: 해당 섹션의 실제 텍스트를 포함하는 더 작은 청크.
- 검색 시 먼저 요약 청크를 검색하여 관련 섹션을 식별한 다음 세부 청크로 좁혀갈 수 있으므로 검색 공간을 줄이고 정밀도를 높일 수 있습니다.
C. 부모-자식 (Parent-Child / Small-to-Large) Chunking
이것은 RAG에서 가장 효과적인 전략 중 하나입니다.
- 문제: 작은 청크는 정밀한 벡터 검색(노이즈가 적음)에 더 좋지만, 큰 청크는 LLM이 답변을 생성하는 데 더 좋은 문맥을 제공합니다.
- 해결책: 문서를 검색을 위한 작은 자식 청크 (예: 50 토큰)로 나눕니다. 각 자식 청크는 더 큰 부모 청크 (예: 500 토큰)에 연결됩니다. 시스템이 매우 관련성 높은 자식 청크를 검색하면, 실제로는 해당 부모 청크를 LLM에 제공합니다.
4. 의미 공간의 수학 (InfoNCE 및 Matryoshka)
모델이 이러한 의미 공간을 어떻게 생성하는지 이해하려면 모델이 어떻게 훈련되는지 살펴봐야 합니다. 현대의 밀집 검색기(dense retriever)는 일반적으로 대조 학습(Contrastive Learning) 을 사용하여 훈련됩니다.
대조 학습과 InfoNCE 손실
대조 학습의 목표는 유사한 항목은 가까이 있고 유사하지 않은 항목은 멀리 떨어져 있는 임베딩 공간을 학습하는 것입니다. RAG에서 이는 쿼리 가 관련 문서 (긍정 샘플)와는 가깝고, 다른 관련 없는 문서 (부정 샘플)와는 멀어져야 함을 의미합니다.
이를 위한 표준 손실 함수는 InfoNCE (Information Noise Contrastive Estimation) 입니다.
여기서:
- 는 유사도 측정 기준으로, 일반적으로 내적(dot product) 또는 코사인 유사도입니다.
- 는 분포의 크기를 조절하는 온도(temperature) 파라미터입니다.
- 이 공식은 본질적으로 다중 클래스 분류 문제로 프레임화되어, 부정적인 문서 세트 중에서 긍정적인 문서가 올바르게 식별될 확률을 계산합니다.
Matryoshka Representation Learning (MRL)
대규모 시스템에서 수십억 개의 문서에 대해 고차원 벡터(예: 768 또는 1536 차원)를 저장하는 것은 메모리 및 검색 지연 시간 측면에서 매우 비용이 많이 듭니다.
Matryoshka Representation Learning (MRL) [1] 은 모델이 벡터의 앞쪽 차원에 정보를 채우도록 훈련함으로써 이 문제를 해결합니다. 러시아 인형(마트료시카)에서 영감을 받은 MRL은 첫 차원(예: 64, 128, 256)만으로도 독립적으로 고품질 검색이 가능하도록 보장합니다.
개발자는 768차원 벡터를 단 128차원으로 잘라낼 수 있습니다. 이를 통해 원본 검색 성능의 최대 95%를 유지하면서 저장 공간과 컴퓨팅 비용을 줄일 수 있습니다. 이러한 “탄력적인” 임베딩 기능은 프로덕션 RAG 파이프라인에서 비용 대비 성능 트레이드오프를 최적화하는 데 매우 중요합니다.
Quizzes
Quiz 1: 사용자가 엄격한 lexical search를 사용하는 시스템에서 “How to fix a punctured tire?”를 검색합니다. 데이터베이스에는 “Repairing a flat tire”라는 제목의 문서가 있습니다. Lexical search가 이 문서를 찾을 수 있을까요? 왜 그럴까요?
퍼지 매칭이나 어간 추출(stemming)이 적극적으로 적용되지 않는 한 높은 순위에 오르기 어렵습니다. “Punctured”와 “flat”은 동의어이지만 공통된 문자가 없으며, “tire”만이 유일하게 일치하는 키워드입니다. Semantic search는 공유된 의도를 쉽게 식별할 수 있습니다.
Quiz 2: 부모-자식(Parent-Child) 청킹이 검색에는 작은 청크를 사용하고 생성에는 큰 청크를 사용하는 이유는 무엇인가요?
작은 청크는 벡터 임베딩에 대한 신호 대 잡음비(signal-to-noise ratio)가 더 높아 검색이 더 정확해집니다. 그러나 LLM은 일관되고 정확한 답변을 생성하기 위해 주변 문맥이 필요하며, 이는 더 큰 부모 청크가 제공합니다.
Quiz 3: BM25 어휘 검색 점수와 DPR(Dense Passage Retrieval)의 내적(Dot-product) 유사도를 명시적으로 결합하는 하이브리드 유사도 점수 를 수식으로 표현하고, 정규화가 필수적인 이유를 설명하시오.
하이브리드 점수는 정규화된 두 점수의 볼록 결합(Convex combination)으로 정식화됩니다: . 여기서 은 균형 하이퍼파라미터입니다. BM25 점수는 상한이 없는 영역()인 반면 임베딩 내적 점수는 벡터 크기에 따라 상한이 결정되므로, 특정 풀 경계(예: Min-Max 스케일링)로 점수를 정규화하지 않으면 한쪽 점수 분포가 최종 결합 순위를 장악하여 왜곡을 유발할 수 있습니다.
References
- Kusupati, A., et al. (2022). Matryoshka Representation Learning. arXiv:2205.13147.