8.3 Over-training vs Optimal-training
이전 섹션에서 우리는 엄격하게 제한된 연산 예산 내에서 사전 학습 손실(Pre-training loss)을 최소화하기 위한 Chinchilla 스케일링 법칙의 수학적 기반을 살펴보았습니다. 즉, 가장 효율적인 학습을 위해서는 파라미터 수와 학습 토큰 수가 1:20의 비율로 확장되어야 한다는 것입니다.
하지만 현재 오픈 가중치(Open-weights) 모델 생태계를 살펴보면, 업계가 이 법칙을 거의 보편적으로 포기했다는 사실을 알 수 있습니다. 예를 들어, Meta의 Llama 3 (8B)는 Chinchilla 최적 데이터 예산의 거의 100배에 달하는 15 Trillion (15조) 토큰 으로 학습되었습니다.
이러한 괴리는 수학적 오류가 아니라 철저한 경제적 계산의 결과입니다. Chinchilla 법칙은 오직 학습(Training) 단계에 투입되는 연산량만을 최적화합니다. 그러나 대규모로 서비스되는 파운데이션 모델(Foundation Models)의 관점에서, 학습 연산량은 일회성 자본 지출(CapEx)에 불과합니다. 반면 매일 수백만 명의 사용자에게 토큰을 생성해 주는 추론 연산량(Inference compute)은 지속적이고 무한한 운영 지출(OpEx)입니다.
이러한 경제적 현실이 바로 과잉 학습 (Over-training), 즉 추론 최적화 스케일링(Inference-Optimal scaling) 시대를 탄생시켰습니다. 소형 아키텍처에 엄청난 양의 데이터를 강제로 주입함으로써, 엔지니어들은 10배 더 큰 신경망의 지능에 필적하면서도 소비자용 하드웨어에서 저렴하게 구동되는 모델을 만들어냅니다.
하지만 딥러닝에 공짜 점심은 없습니다. 최근 연구에 따르면 모델을 연산 최적점(Compute-optimal point)을 넘어 너무 멀리 밀어붙일 경우 심각한 아키텍처의 취약성이 발생하며, 이는 전체 학습 수명 주기에 접근하는 우리의 방식을 근본적으로 변화시키고 있습니다.
미세 조정의 역설 (The Fine-Tuning Paradox)
수년 동안 언어 모델링 분야의 지배적인 가정은 단순했습니다. ‘사전 학습 손실(Pre-training loss)이 낮을수록 다운스트림 모델의 성능이 무조건 더 좋다’는 것이었습니다. 더 많은 토큰으로 학습하면 모델의 제로샷 퍼플렉서티(Zero-shot perplexity)가 향상되고, 논리적으로 지도 미세 조정(Supervised Fine-Tuning, SFT)과 인간 피드백 기반 강화 학습(RLHF) 이후에 더 유능한 어시스턴트가 되어야 합니다.
하지만 최근 파국적 과잉 학습 (Catastrophic Overtraining) [1] 현상이 발견되면서 이러한 가정은 완전히 깨졌습니다.
과잉 학습(Over-training)이 제로샷 벤치마크 성능을 확실하게 향상시키는 것은 맞지만 [2], 역설적으로 모델의 다운스트림 적응력(Adaptability)은 파괴합니다. 모델이 처리하는 토큰 예산이 계속 늘어남에 따라, 인스트럭션 튜닝(Instruction-tuning)을 성공적으로 수용할 수 있는 능력은 오히려 저하 됩니다.
OLMo-1B 사례 연구
이 현상을 분리하여 관찰하기 위해 연구진은 OLMo-1B 모델의 중간 체크포인트들을 분석했습니다.
- Checkpoint A: 2.3 Trillion 토큰으로 사전 학습됨.
- Checkpoint B: 3.0 Trillion 토큰으로 사전 학습됨.
예상대로 Checkpoint B는 Checkpoint A보다 엄격하게 더 낮은 사전 학습 손실을 기록했습니다. 하지만 두 모델에 정확히 동일한 인스트럭션 튜닝 레시피를 적용한 결과, Checkpoint B가 표준 LLM 벤치마크에서 2% 이상 더 나쁜 성능 을 보였습니다. 추가로 학습된 7,000억 개의 토큰이 오히려 어시스턴트로서의 모델 효용성을 적극적으로 훼손한 것입니다.
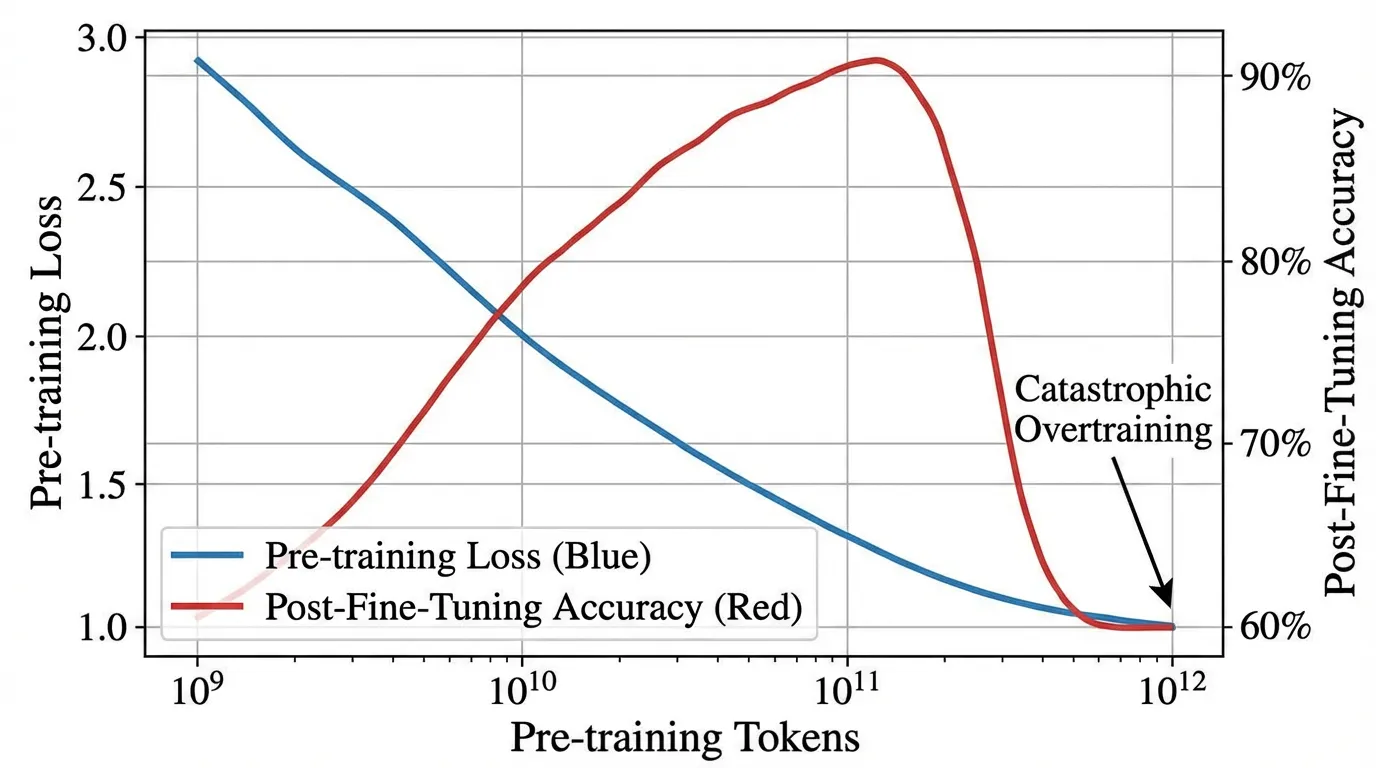 Source: Springer et al., 2025 [1]
Source: Springer et al., 2025 [1]
점진적 민감도 (Progressive Sensitivity)
그렇다면 왜 더 “똑똑한” 사전 학습 모델이 인스트럭션(지시어)을 따르는 데에는 더 서투르게 변하는 것일까요? 기술적인 근본 원인은 바로 점진적 민감도 (Progressive Sensitivity) 에 있습니다.
신경망의 잠재 공간(Latent space)을 찰흙 덩어리라고 생각해 보십시오. Chinchilla 최적점(Compute-optimal)에서 이 찰흙은 고도로 구조화되어 있으면서도 여전히 촉촉하고 유연한(Plastic) 상태입니다. 즉, 미세 조정 과정에서 특정 형태(지시를 따르는 어시스턴트)로 쉽게 빚어낼 수 있습니다.
하지만 모델이 극도로 과잉 학습될 때, 모델은 한정된 파라미터 안에 불가능할 정도로 방대한 세계의 지식을 압축하도록 강요받습니다. 이를 달성하기 위해 신경망은 점점 더 복잡하고 고도로 중첩된 표현(Superposition)에 의존하게 됩니다. 찰흙이 굳어버리는 것입니다. 파라미터들은 사전 학습 말뭉치의 정확한 데이터 분포에 과도하게 특화(Hyper-specialized)됩니다.
수학적으로 이는 피셔 정보 행렬 (Fisher Information Matrix) 의 대각합(Trace)이 급증하는 것으로 나타납니다. 과잉 학습된 가중치 주변의 손실 지형(Loss landscape)은 믿을 수 없을 정도로 날카로워집니다. 미세 조정 단계에서 아주 작은 그래디언트 업데이트만 발생해도 모델의 행동에 거대하고 예측할 수 없는 변화가 일어납니다. 파라미터들이 너무 부서지기 쉬운(Brittle) 상태가 되어 미세 조정의 충격을 견디지 못하고 산산조각 나기 때문에, 초기 사전 학습 과정에서 얻었던 폭넓고 일반적인 지식을 잃어버리게 되는 것입니다.
학습의 골디락스 존 (The Goldilocks Zone of Training)
우리는 현재 최적의 학습에 대한 정의가 재정립되는 “포스트 친칠라(Post-Chinchilla)” 시대에 진입하고 있습니다. 엔지니어들은 더 이상 사전 학습 손실만을 최소화하기 위해 최적화하지 않으며, 추론 비용을 줄이기 위해 맹목적으로 과잉 학습을 진행하지도 않습니다.
새로운 목표는 효용 최적점 (Utility-Optimal) 을 찾는 것입니다. 이는 추론 비용이 저렴할 만큼 모델 크기가 작으면서도, 얼라인먼트(Alignment)와 특화된 작업 적응 훈련을 견뎌낼 수 있을 만큼 충분한 유연성(Plasticity)을 유지하는 “골디락스 존”을 의미합니다.
| 특징 | 연산 최적화 (Chinchilla) | 효용 최적화 (Utility/SOTA) | 과잉 학습 (Brittle) |
|---|---|---|---|
| 주요 목표 | 학습 연산량 최소화 | 추론 비용과 적응력의 균형 | 수단과 방법을 가리지 않고 추론 비용 최소화 |
| 데이터-파라미터 비율 | ~20 : 1 | ~100 : 1 에서 ~400 : 1 | > 1000 : 1 |
| 미세 조정 유연성 | 매우 효과적임 | 안정적인 업데이트 가능 | 부서지기 쉬움; “파국적 과잉 학습” |
| 사전 학습 손실 | 보통 (Moderate) | 낮음 (Low) | 가장 낮음 (Lowest) |
| 다운스트림 효용성 | 좋음 | 가장 뛰어남 (Best) | 감소함 (역설 발생) |
학습 역학: 손실 vs 부서짐성
차트 위에 마우스를 올려 사전 학습 손실과 다운스트림 효용성 간의 트레이드오프를 확인하세요.
파라미터 민감도 모니터링 (Monitoring Parameter Sensitivity)
파국적 과잉 학습을 방지하기 위해, 최신 사전 학습 클러스터는 단순히 검증 손실(Validation loss)만 모니터링하지 않습니다. 이들은 신경망의 유연성(Plasticity)을 지속적으로 추적합니다.
가중치의 민감도가 급증한다면, 이는 모델이 “효용 최적점(Utility-Optimal)“을 지나 “부서지기 쉬운(Brittle)” 상태로 임계값을 넘어가고 있다는 신호입니다. 분산 학습 과정에서 이 민감도를 근사하는 효율적인 방법 중 하나는 경험적 피셔 정보 행렬(Empirical Fisher Information Matrix)의 대각합을 추적하는 것입니다. 이는 본질적으로 제곱된 그래디언트들의 합을 의미합니다.
다음 PyTorch 구현은 엔지니어가 체크포인트 전반에 걸쳐 이 지표를 어떻게 모니터링하는지 보여줍니다.
import torch
import torch.nn as nn
class TransformerBlock(nn.Module):
"""설명을 위한 단순화된 Transformer 블록입니다."""
def __init__(self, d_model=256, vocab_size=1000):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.encoder = nn.TransformerEncoderLayer(d_model=d_model, nhead=4, batch_first=True)
self.lm_head = nn.Linear(d_model, vocab_size)
def forward(self, x):
return self.lm_head(self.encoder(self.embedding(x)))
def compute_fisher_trace(model: nn.Module, inputs: torch.Tensor, targets: torch.Tensor) -> float:
"""
주어진 배치에 대한 경험적 피셔 정보 행렬(Empirical Fisher Information)의 대각합을 계산합니다.
연속적인 사전 학습 체크포인트에서 이 대각합(trace)이 상승한다면,
파라미터의 민감도(부서지기 쉬움)가 증가하고 있으며
파국적 과잉 학습(Catastrophic Overtraining)이 시작되고 있음을 나타냅니다.
"""
model.eval()
criterion = nn.CrossEntropyLoss()
# Forward pass
logits = model(inputs)
# CrossEntropy를 위한 형태 변환: (batch_size * seq_len, vocab_size)
loss = criterion(logits.view(-1, logits.size(-1)), targets.view(-1))
# 순수한 누적을 보장하기 위해 backward pass 전에 그래디언트를 초기화합니다.
model.zero_grad()
loss.backward()
fisher_trace = 0.0
for name, param in model.named_parameters():
if param.requires_grad and param.grad is not None:
# 경험적 피셔 정보 행렬의 대각선(diagonal) 요소는
# 제곱된 그래디언트로 근사할 수 있습니다.
fisher_trace += (param.grad ** 2).sum().item()
return fisher_trace
# --- 시뮬레이션: 체크포인트 모니터링 ---
torch.manual_seed(42)
model = TransformerBlock()
# 더미(Dummy) 검증 배치: 길이 32의 시퀀스 4개
val_inputs = torch.randint(0, 1000, (4, 32))
val_targets = torch.randint(0, 1000, (4, 32))
trace_value = compute_fisher_trace(model, val_inputs, val_targets)
print(f"Empirical Fisher Trace: {trace_value:.4f}")
print("System Prompt: 만약 체크포인트를 거치면서 이 값이 지속적으로 기하급수적인 증가를 보인다면, ")
print("미세 조정 유연성(Plasticity)을 보존하기 위해 조기 종료(Early stopping)를 트리거하십시오.")업계가 점점 더 거대한 데이터셋을 향해 나아감에 따라, 파운데이션 모델 엔지니어링(Foundation Model Engineering)의 규율도 변화하고 있습니다. 학습은 더 이상 손실(Loss)이 바닥을 칠 때까지 GPU에 토큰을 쏟아붓는 단순한 작업이 아닙니다. 원시 텍스트 예측기에서 인간의 가치에 정렬된(Aligned) 에이전트 AI로의 성공적인 전환을 보장하기 위해, 신경망의 물리적 상태를 동적으로 관리하는 정밀한 제어의 영역이 되었습니다.
Quizzes
Quiz 1: 사전 학습 손실(Pre-training loss)이 더 낮은 모델이 지도 미세 조정(SFT) 이후에 오히려 더 나쁜 성능을 보이는 이유는 무엇입니까?
이는 파국적 과잉 학습(Catastrophic Overtraining)으로 인해 발생하는 미세 조정의 역설(Fine-Tuning Paradox) 때문입니다. 모델이 과잉 학습됨에 따라 파라미터는 극도로 특화되고 부서지기 쉬운 상태가 됩니다(점진적 민감도). SFT 과정에서 미세 조정 데이터로부터 발생하는 그래디언트가 이러한 취약한 가중치에 거대하고 예측할 수 없는 변화를 일으켜, 사전 학습 동안 모델이 습득했던 일반적인 지식을 파괴하게 됩니다.
Quiz 2: Chinchilla 스케일링 법칙이 학습 효율성을 위한 수학적으로 최적화된 비율을 제공함에도 불구하고, Meta와 같은 기업들이 Llama 3 8B와 같은 모델에서 의도적으로 이 법칙을 무시하는 이유는 무엇입니까?
Chinchilla 법칙은 학습 연산량(CapEx)만을 최적화합니다. 하지만 오픈 가중치(Open-weights) 모델이나 대규모로 서비스되는 모델의 경우, 모델의 전체 수명 주기 동안 발생하는 추론 연산량(OpEx)이 압도적으로 큰 비용을 차지합니다. Chinchilla가 권장하는 것보다 훨씬 방대한 데이터로 작은 모델을 과잉 학습시킴으로써, 엔지니어들은 대규모 서비스 환경에서 예외적으로 저렴하고 빠르게 구동되면서도 매우 유능한 모델을 만들 수 있기 때문입니다.
Quiz 3: 대규모 사전 학습 과정에서 경험적 피셔 정보 행렬(Empirical Fisher Information Matrix)을 모니터링하는 것이 엔지니어에게 어떤 도움을 줍니까?
피셔 정보 행렬의 대각합(Trace)은 파라미터 변화에 대한 모델 손실의 민감도를 측정합니다. 만약 이 값이 급증한다면, 이는 손실 지형(Loss landscape)이 극도로 날카로워졌고 가중치가 유연성(Plasticity)을 잃었음을 의미합니다. 엔지니어는 이 지표를 조기 경보 시스템으로 활용하여, 모델이 RLHF나 SFT를 통한 정렬(Alignment) 과정을 견디지 못할 정도로 부서지기 쉬운 상태가 되기 전에 사전 학습을 적절히 중단할 수 있습니다.
References
- Springer, J. M., et al. (2025). Overtrained Language Models Are Harder to Fine-Tune. arXiv:2503.19206.
- Gadre, S. Y., et al. (2024). Language models scale reliably with over-training and on downstream tasks. arXiv:2403.08540.