11.4 이미지 확산 모델 (Image Diffusion Models)
이전 섹션들이 서로 다른 모달리티(Modality)를 이해하고 연결하는 데 집중했다면, 이번 섹션에서는 생성(Generation) — 구체적으로 모델이 텍스트 프롬프트로부터 고화질 이미지를 생성하는 방법에 대해 깊이 파고듭니다. 이를 가능하게 한 핵심 혁신은 확산(Diffusion) 모델로, 이는 시각적 합성(Visual synthesis) 분야에서 Generative Adversarial Networks (GAN) 과 자기회귀(Autoregressive) 모델을 대부분 대체한 패러다임입니다.
1. 비유: 안개 걷어내기
두껍고 무작위로 낀 안개로 완전히 가려진 창문을 보고 있다고 상상해 보세요. 밖에는 아무것도 보이지 않습니다. 이제 여러분에게 이 안개를 한 번에 조금씩 걷어낼 수 있는 마법의 도구가 있다고 상상해 보세요. 만약 여러분이 무엇을 보고 싶은지 (예: 정원의 고양이) 알고 있다면, 그 지식을 활용하여 안개를 걷어내는 과정을 안내할 수 있습니다. 각 단계마다 무작위 안개를 조금씩 제거하고 고양이처럼 보이는 구조를 조금씩 추가합니다. 결국 창문이 투명해지고, 아름다운 고양이 그림이 나타납니다.
이것이 바로 확산 모델이 작동하는 방식입니다. 이들은 순수한 무작위 노이즈(두꺼운 안개)의 캔버스에서 시작하여 텍스트 프롬프트의 안내에 따라 노이즈를 반복적으로 제거하고 구조를 추가하여 선명한 이미지가 나타날 때까지 진행합니다.
Diffusion Visualizer
Step t: 0 / 100
2. 핵심 메커니즘: 순방향 및 역방향 확산
확산 모델은 비평형 열역학(Non-equilibrium thermodynamics)에서 영감을 얻은 연속 시간(Continuous-time) 생성 모델입니다. 이들은 데이터에 노이즈를 점진적으로 추가하여 파괴하는 과정을 역으로 거슬러 올라가며 데이터를 생성하는 법을 학습합니다.
순방향 프로세스 (가우시안 확산)
순방향 프로세스(Forward process)에서는 깨끗한 이미지 에서 시작하여 일련의 타임스텝 에 걸쳐 점진적으로 가우시안 노이즈(Gaussian noise)를 추가합니다. 이 과정은 다음과 같은 마르코프 체인(Markov chain)으로 정의됩니다: 여기서 는 분산 스케줄(Variance schedule)입니다.
이 공식의 매우 중요한 특성은 재매개변수화 트릭(Reparameterization trick) 을 사용하여 중간 단계를 거치지 않고 로부터 임의의 타임스텝 에서의 를 직접 샘플링할 수 있다는 점입니다: 여기서 이고, 이며, 입니다. 일 때, 는 순수한 가우시안 노이즈와 거의 구별할 수 없게 됩니다.
역방향 프로세스 (생성적 노이즈 제거)
생성 모델링의 목표는 역방향 프로세스인 를 학습하는 것입니다. 이 과정을 역으로 돌릴 수 있다면, 무작위 노이즈 에서 시작하여 실제 데이터 분포 로부터 샘플을 생성할 수 있습니다.
진정한 역방향 분포는 다루기 어렵지만(전체 데이터 분포에 의존하므로), Ho et al. (2020) [1] 은 가 작을 때 역방향 단계 역시 가우시안으로 근사될 수 있음을 보여주었습니다. 우리는 이 역방향 전이를 학습하기 위해 신경망 를 훈련시킵니다:
실제 구현에서는 평균 를 직접 예측하는 것보다, 에 추가되어 를 생성한 노이즈 을 예측하도록 네트워크 를 훈련시키는 것이 더 좋은 결과를 냅니다. 이 경우 손실 함수는 다음과 같이 단순한 평균 제곱 오차(MSE) 회귀로 단순화됩니다:
이러한 스코어 매칭(Score Matching) 및 랑제뱅 동역학(Langevin dynamics)과의 연결이 바로 확산 모델을 강력하게 만드는 원천입니다. 네트워크는 본질적으로 데이터 분포의 로그 밀도 그래디언트(Score function)를 학습하는 것입니다.
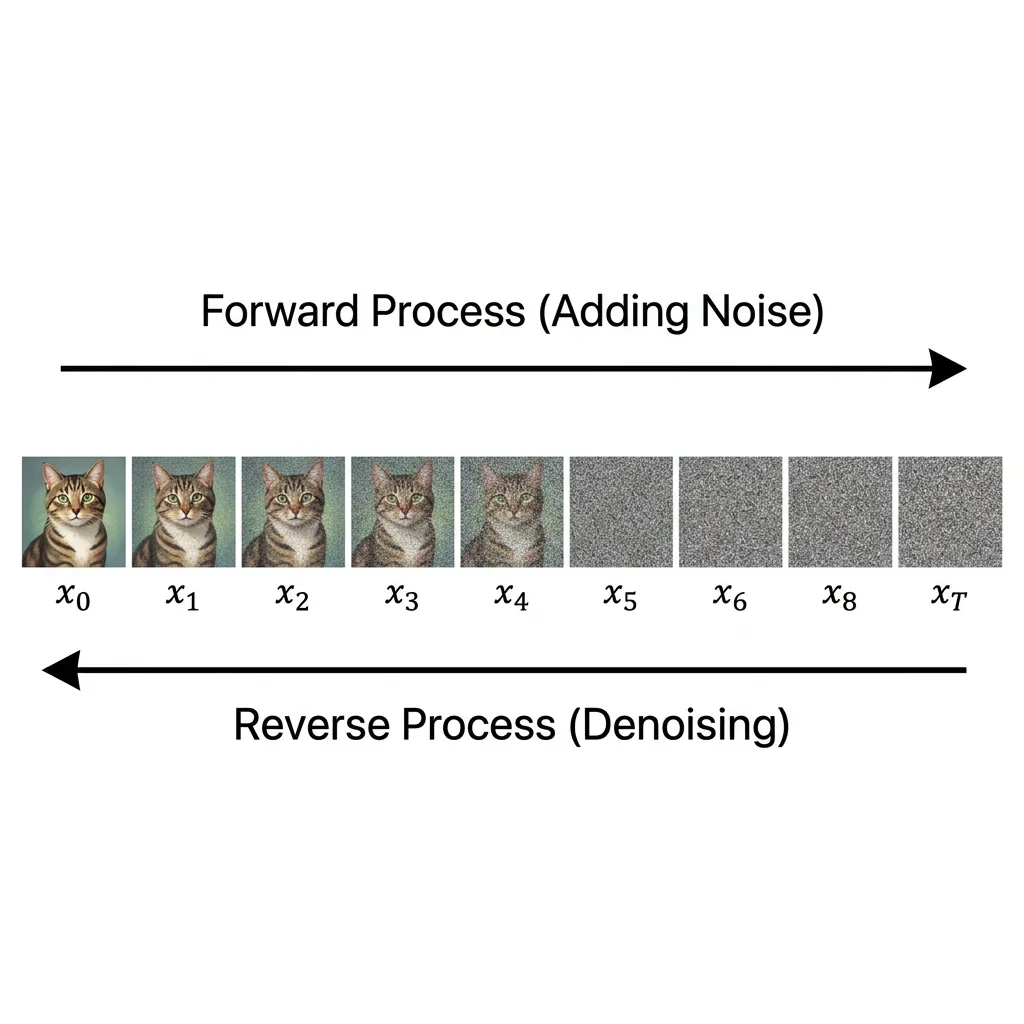 그림: 노이즈를 추가하는 순방향 확산 프로세스와 이를 제거하는 역방향 프로세스.
그림: 노이즈를 추가하는 순방향 확산 프로세스와 이를 제거하는 역방향 프로세스.
3. 잠재 확산 모델 (Latent Diffusion Models, LDM): 해상도 위기의 해결
초기의 확산 모델은 픽셀 공간(Pixel space)에서 직접 작동했습니다. 이 방식은 효과적이었지만, 고해상도 이미지의 경우 연산량이 기하급수적으로 증가하는 치명적인 문제가 있었습니다. 모든 타임스텝마다 깊은 U-Net을 통해 거대한 텐서를 처리해야 했기 때문에 학습과 추론 비용이 엄청나게 높았습니다.
Stable Diffusion 의 탄생으로 이어진 돌파구는 잠재 확산(Latent Diffusion) 이었습니다 [2]. 핵심 아이디어는 학습 과정을 두 가지 뚜렷한 단계로 분리하는 것이었습니다:
1단계: 지각적 압축 (VAE)
먼저 오토인코더(특히 Variational Autoencoder, VAE)를 훈련시킵니다. 인코더 는 고해상도 이미지 를 더 낮은 차원의 잠재 공간 로 매핑합니다 (여기서 , ). 디코더 는 이를 다시 복원합니다: . 이 단계는 인간의 눈으로 식별하기 어려운 고주파(High-frequency) 중복 정보를 제거하고, 잠재 공간에 핵심적인 시맨틱(Semantic) 정보만 남깁니다.
2단계: 시맨틱 생성 (잠재 확산)
확산 프로세스(순방향 및 역방향 모두)는 이 압축된 잠재 공간 내에서만 수행됩니다. 이제 네트워크는 잠재 공간 에서 노이즈를 예측하므로 연산 비용이 획기적으로 감소합니다.
크로스 어텐션을 통한 조건부 생성 (Conditioning)
텍스트-이미지 생성을 가능하게 하기 위해, LDM은 노이즈 제거 네트워크에 크로스 어텐션(Cross-attention) 메커니즘을 도입합니다. 텍스트 프롬프트 는 사전 학습된 텍스트 인코더(예: CLIP)를 통해 인코딩되며, 이 임베딩들은 U-Net의 어텐션 레이어에 주입됩니다: 여기서 는 평탄화된 잠재 표현에서 파생되고, 와 는 텍스트 임베딩에서 파생됩니다. 이를 통해 모델은 텍스트에 설명된 시맨틱 개념을 엄격하게 준수하는 이미지를 생성할 수 있습니다.
4. 확산 모델 vs. GAN: 확산이 승리한 이유
수년 동안 Generative Adversarial Networks (GAN) 은 이미지 생성 분야의 최첨단(SOTA)이었습니다. 하지만 현재는 확산 모델이 이를 거의 완전히 대체했습니다. 그 이유는 다음과 같습니다:
- 안정적인 학습: GAN은 생성자와 판별자 간의 미니맥스 게임(Minimax game)에 의존하기 때문에 학습이 매우 어렵고 불안정하며 진동하는 경향이 있습니다. 반면 확산 모델은 단순한 MSE 회귀 손실을 사용하므로 학습이 매우 안정적이고 스케일링이 용이합니다.
- 모드 붕괴(Mode Collapse) 방지: GAN은 생성자가 판별자를 속일 수 있는 데이터 분포의 아주 작은 부분집합만을 생성하는 법을 학습하는 ‘모드 붕괴’ 문제로 악명이 높습니다. 확산 모델은 데이터 분포의 가능도(Likelihood)를 명시적으로 최대화하므로 데이터셋의 모든 모드를 훨씬 더 잘 포괄합니다.
- 확장성 (Scalability): 확산 모델은 LLM과 유사하게 연산량과 모델 파라미터에 따라 매우 잘 확장되므로, Flux와 같은 모델에서 볼 수 있는 강력한 성능을 이끌어낼 수 있습니다.
5. 유명한 오픈소스 모델 및 비교
Stable Diffusion이 이 분야를 촉발시켰지만, 이후 여러 강력한 오픈소스 모델들이 등장했습니다.
| 모델 | 아키텍처 | 오픈소스 여부 | 주요 특징 / 혁신 |
|---|---|---|---|
| Stable Diffusion v1.5/2.1 | U-Net + CLIP | 예 | 잠재 확산을 대중화했으며, 거대한 커뮤니티 생태계를 보유함. |
| SDXL (Stable Diffusion XL) | 더 큰 U-Net + Refiner | 예 | 더 나은 해부학적 표현, 사실적인 묘사 및 네이티브 고해상도 생성. |
| Flux.1 | Diffusion Transformer (DiT) | 예 (Dev/Schnell) | 최첨단 프롬프트 준수 능력 및 이미지 내 텍스트 렌더링. |
| PixArt- | DiT + T5 | 예 | 매우 효율적인 학습; 뛰어난 텍스트-이미지 정렬. |
| Kandinsky | UnCLIP 스타일 | 예 | 뛰어난 다국어 지원 및 이미지-투-이미지(Image-to-Image) 기능. |
6. Case Study: Stable Diffusion의 부흥과 진화
Stable Diffusion의 이야기는 생성형 AI 역사에서 가장 흥미로운 장 중 하나입니다. 이는 오픈소스 접근성이 어떻게 기술 발전을 급격히 가속화할 수 있는지 보여주는 동시에, 아키텍처적 한계라는 냉혹한 현실도 함께 보여줍니다.
붐: 민주화와 커뮤니티
2022년, OpenAI의 DALL-E 2가 세상을 놀라게 했지만, 이는 폐쇄적인 API로만 제공되었습니다. 얼마 지나지 않아 Stable Diffusion이 오픈 가중치 로 공개되었습니다. 괜찮은 소비자용 GPU만 있다면 누구나 다운로드하여 실행할 수 있었습니다.
이는 캄브리아기 폭발을 촉발했습니다:
- 생태계 성장: 개발자들은 SD를 전문적인 도구로 변화시킨 WebUI(예: Automatic1111 및 ComfyUI)를 구축했습니다.
- 미세 튜닝 (LoRAs): 커뮤니티는 단 몇 장의 이미지만을 사용하여 특정 스타일이나 캐릭터에 대해 SD를 미세 조정하는 방법을 발명했습니다.
- ControlNet: 연구원들은 사용자가 스케치, 포즈 또는 깊이 맵으로 생성을 안내할 수 있는 ControlNet을 개발했습니다.
피벗: 스케일링의 벽과 기업의 변화
그러나 2024년에 이르러 환경이 바뀌기 시작했습니다. 원래의 Stable Diffusion 모델들은 U-Net 아키텍처를 기반으로 했습니다. 사용자들이 더 높은 해상도와 더 나은 텍스트 렌더링을 요구함에 따라, U-Net은 한계에 부딪히기 시작했습니다.
Stability AI를 떠난 연구원들은 새로운 회사인 Black Forest Labs 를 설립하고 Flux.1 을 출시했습니다. Flux는 U-Net을 버리고 Diffusion Transformer (DiT) 를 채택하여 이미지 패치를 토큰처럼 취급함으로써 훨씬 더 잘 스케일링되며, 프롬프트 준수 및 텍스트 렌더링에서 거대한 도약을 이루었습니다.
7. 코드: 간단한 노이즈 예측 단계
위의 수식을 이해하기 위해, Denoising Diffusion Probabilistic Model (DDPM) 의 단일 단계를 시뮬레이션하는 간단한 PyTorch 예제입니다.
import torch
import torch.nn as nn
class SimpleDenoisingModel(nn.Module):
def __init__(self, img_channels=3):
super().__init__()
# 노이즈를 예측하는 간단한 CNN
self.net = nn.Sequential(
nn.Conv2d(img_channels, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, img_channels, 3, padding=1)
)
def forward(self, x, t):
# 실제 모델에서는 't' (타임스텝)가 임베딩되어 네트워크에 주입됩니다.
return self.net(x)
def ddpm_step(x_t, predicted_noise, t, beta_t):
"""
역방향 DDPM 프로세스의 단순화된 단일 단계.
"""
alpha_t = 1 - beta_t
# x_t와 예측된 노이즈로부터 x_{t-1}을 추정하는 수식
x_prev = (1 / torch.sqrt(alpha_t)) * (x_t - (beta_t / torch.sqrt(1 - alpha_t)) * predicted_noise)
# 역방향 단계에서 노이즈 추가 (마지막 단계 제외)
if t > 0:
noise = torch.randn_like(x_t)
x_prev += torch.sqrt(beta_t) * noise
return x_prev
# 시뮬레이션
img = torch.randn(1, 3, 64, 64) # 순수한 노이즈로 시작
model = SimpleDenoisingModel()
beta_schedule = torch.linspace(0.0001, 0.02, 1000)
# 노이즈 제거 한 단계
t = 999
pred_noise = model(img, t)
denoised_img = ddpm_step(img, pred_noise, t, beta_schedule[t])
print(f"Denoised image shape: {denoised_img.shape}")8. 이미지를 넘어서: 확산 기반 LLM (Diffusion-Based LLMs)
20.6장 (확산 기반 LLM) 에서 살펴보겠지만, 연구자들은 언어 모델링에 확산을 적용하기 위한 기술들을 적극적으로 개발하고 있습니다. 연속적인 임베딩 공간에서 확산을 수행하거나 이산 확산 프로세스를 사용함으로써, 이러한 모델들은 표준 자기회귀 LLM에 비해 비자기회귀 생성 및 더 나은 제어 가능성과 같은 잠재적 이점을 제공합니다.
Quizzes
Quiz 1: 잠재 확산 모델이 픽셀 공간 확산보다 연산량이 적은 이유는 무엇입니까?
모든 타임스텝마다 거대한 고해상도 픽셀 텐서를 처리하는 대신, VAE에 의해 압축된 더 낮은 차원의 잠재 공간에서 작동하기 때문입니다.
Quiz 2: 확산 모델에서 순방향 프로세스의 목적은 무엇입니까?
순방향 프로세스는 깨끗한 이미지에 점진적으로 노이즈를 추가하여 순수한 노이즈로 만듭니다. 이는 모델이 역방향 프로세스(노이즈 제거)를 학습할 수 있도록 훈련 데이터를 제공합니다.
Quiz 3: Flux와 같은 모델이 기존 Stable Diffusion보다 더 잘 스케일링될 수 있도록 한 아키텍처 전환은 무엇입니까?
U-Net 아키텍처에서 연산 및 파라미터 확장에 더 유리한 Diffusion Transformer (DiT) 아키텍처로의 전환입니다.
References
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. arXiv:2006.11239.
- Rombach, R., et al. (2022). High-resolution image synthesis with latent diffusion models. arXiv:2112.10752.
- Peebles, W., & Xie, S. (2023). Scalable diffusion models with transformers. arXiv:2212.09748.