6.4 Infrastructure
6.3절에서 수천억 개의 파라미터를 가진 모델의 수학적 안정성을 확보하는 방법을 다루었다면, 이 장에서는 그 연산을 물리적으로 실현하는 거대한 인프라를 다룹니다. 초기 딥러닝 시대에서 파운데이션 모델(Foundation Model) 시대로의 전환은 하드웨어 추상화에 있어 근본적인 패러다임의 변화를 의미합니다. 이제 데이터센터 자체가 하나의 거대한 컴퓨터입니다.
엔지니어들이 Llama 3나 Grok 3를 학습시킨다고 말할 때, 그들은 단일 서버나 랙(Rack) 하나를 이야기하는 것이 아닙니다. 수백 메가와트(MW)의 전력을 소비하고, 수천 킬로미터의 광섬유 케이블로 얽혀 있으며, 최대 10만 개 이상의 GPU가 고도로 동기화되어 움직이는 ‘창고 규모의 슈퍼컴퓨터(Warehouse-scale Supercomputer)‘를 의미합니다.
이러한 극단적인 스케일에서는 열역학, 빛의 속도로 인한 지연(Latency) 한계, 그리고 부품의 엔트로피(고장 확률)와 같은 물리학의 법칙이 시스템 아키텍처를 결정합니다. 이 섹션에서는 랙 스케일(Rack-scale)의 액체 냉각 시스템부터 InfiniBand와 Ethernet 간의 치열한 주도권 경쟁에 이르기까지, 2026년 현재 최첨단 AI 인프라의 뼈대를 해부합니다.
1. 연산 밀도 (Compute Density): 랙 스케일(Rack-Scale) 패러다임
역사적으로 AI 클러스터는 8개의 GPU(예: NVIDIA HGX A100 또는 H100)를 탑재한 표준 4U 또는 8U 서버를 ToR(Top-of-Rack) 스위치로 연결하여 구축되었습니다. 그러나 모델이 수조 개의 파라미터를 가진 MoE (Mixture-of-Experts) 아키텍처로 진화함에 따라, 이러한 개별 서버 간의 통신 오버헤드는 치명적인 병목 현상을 유발했습니다.
이에 대한 업계의 해답은 NVIDIA GB200 NVL72 [1] 와 같은 시스템으로 대표되는 Rack-Scale Architecture 입니다.
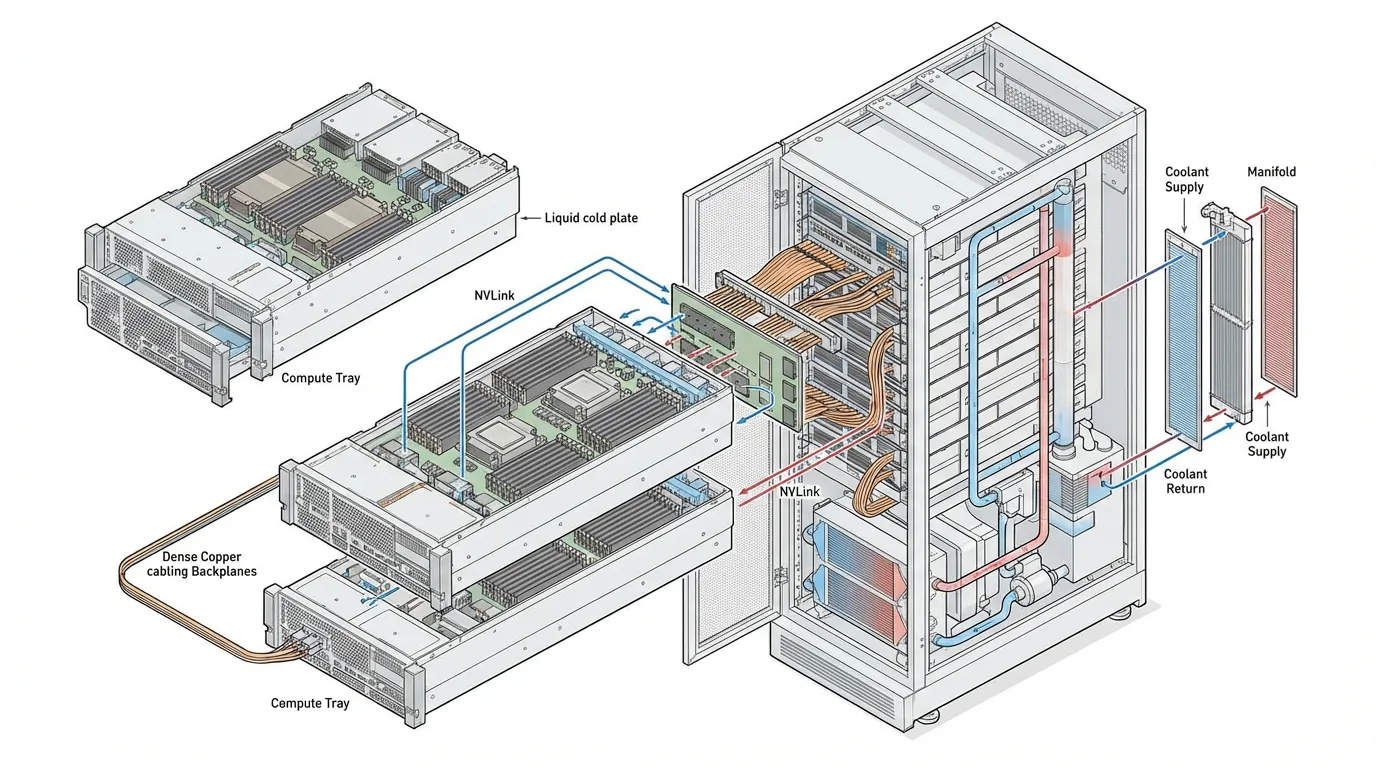 Source: Generated by Gemini
Source: Generated by Gemini
랙 스케일 설계에서는 전통적인 “서버”의 경계가 무너집니다.
- 거대한 단일 GPU (The Massive Single GPU): GB200 NVL72는 72개의 Blackwell GPU와 36개의 Grace CPU를 하나의 랙에 담습니다. 이들은 표준 이더넷으로 연결되는 대신, 구리 백플레인(Blind-mate copper backplane)을 통해 전체 72개의 GPU가 단일 NVLink domain 으로 묶입니다. 이는 130 TB/s의 양방향 대역폭을 제공하며, PyTorch 컴파일러의 관점에서 이 거대한 랙은 ‘하나의 거대하고 일관된 가속기’로 인식됩니다.
- 직접 액체 냉각 (Direct-to-Chip Liquid Cooling): 단일 NVL72 랙은 약 120 킬로와트(kW)의 전력을 소비합니다. 공랭식(Air cooling)으로는 물리적으로 이 엄청난 열을 배출할 수 없습니다. 따라서 CDU(Coolant Distribution Unit)가 특수 냉각액을 CPU, GPU, 그리고 NVLink 스위치 실리콘 위로 직접 순환시키는 DTC(Direct-to-Chip) 방식이 표준이 되었습니다.
2. 인터커넥트 전쟁: 스케일 아웃(Scale-Out) 네트워킹
NVLink가 랙 내부의 통신인 Scale-Up 을 담당한다면, 최첨단 파운데이션 모델을 학습시키기 위해서는 수천 개의 랙을 가로지르는 Scale-Out 통신이 필수적입니다. 이는 RDMA (Remote Direct Memory Access) 를 통해 달성됩니다. RDMA는 한 서버가 CPU와 운영체제(OS) 커널을 완전히 우회하여 다른 서버의 GPU 고대역폭 메모리(HBM)에 직접 데이터를 읽고 쓸 수 있게 해 주며, 마이크로초(microsecond) 단위의 초저지연을 실현합니다.
지난 10년 동안 RDMA의 절대 강자는 InfiniBand 였습니다. 하지만 2024년에서 2026년에 이르는 기간 동안, 업계는 RoCEv2 (RDMA over Converged Ethernet) 로 대대적인 전환을 맞이했습니다.
InfiniBand: 전통의 챔피언
InfiniBand는 고성능 컴퓨팅(HPC)을 위해 밑바닥부터 설계되었습니다. 가장 큰 장점은 크레딧 기반 흐름 제어(Credit-based flow control) 입니다. 송신자는 수신자가 버퍼 공간이 있음을 확인하는 “크레딧”을 명시적으로 부여하지 않는 한 데이터를 전송하지 않습니다. 이로 인해 InfiniBand는 태생적으로 패킷 손실이 없는(Lossless) 네트워크이며, 동기화가 생명인 AI 학습에서 치명적인 지연 시간 급증(Latency spike)을 방지합니다.
Ethernet (RoCEv2): 하이퍼스케일의 도전자
이더넷(Ethernet)은 어디에나 존재하고, 저렴하며, 거대한 오픈 생태계의 이점을 누립니다. 하지만 표준 이더넷은 혼잡할 때 패킷을 버리는 “Lossy” 네트워크입니다. RoCEv2는 PFC(Priority Flow Control)와 ECN(Explicit Congestion Notification)을 사용하여 이 문제를 해결하고자 합니다.
과거 RoCEv2는 단일 포트의 혼잡이 전체 네트워크의 트래픽을 일시 중지시키는 “PFC Storm” 문제로 고전했습니다. 하지만 두 건의 거대한 구축 사례가 프런티어 스케일에서 이더넷의 가능성을 입증했습니다.
- Meta의 Llama 3 클러스터: Meta는 24,576개의 GPU를 가진 클러스터를 두 개(하나는 InfiniBand, 다른 하나는 RoCEv2) 병렬로 구축했습니다. 정교한 토폴로지 인식 스케줄링(Topology-aware scheduling)과 네트워크 튜닝을 거친 결과, 이더넷 클러스터가 InfiniBand의 학습 처리량(Throughput)과 동등한 성능을 낼 수 있음을 증명했습니다 [3].
- xAI Colossus: 일론 머스크의 xAI는 단 122일 만에 100,000개의 H100 GPU(이후 200,000개로 확장) 클러스터를 구축했습니다. 이들은 InfiniBand를 완전히 배제하고 NVIDIA의 Spectrum-X 이더넷 패브릭을 선택했습니다. SmartNIC(BlueField-3 DPU)에 혼잡 제어를 오프로드(Offload)함으로써, Colossus는 패킷 손실 제로(Zero packet loss) 상태에서 95%의 지속적인 처리량을 달성했습니다 [2].
3. 구글의 대안: TPU와 빛(Optical)의 활용
업계의 대부분이 전기적 패킷 스위치를 이용한 계층적 Fat-Tree 네트워크를 구축할 때, 구글의 엔지니어들은 TPU (Tensor Processing Unit) 팟(Pod)을 위해 완전히 다른 철학을 적용했습니다. 바로 3D Torus 와 광학 회로 스위치 (OCS, Optical Circuit Switches) 입니다 [4].
TPU v5p 팟에서는 8,960개의 칩이 3차원 그리드(16×20×28) 형태로 이웃 칩과 직접 연결됩니다. 수많은 전기적 Spine 및 Leaf 스위치 계층을 통해 패킷을 라우팅하는 대신, 이 그리드의 가장자리는 OCS에 연결됩니다.
 Source: Generated by Gemini
Source: Generated by Gemini
MEMS 거울의 마법
전기 스위치는 들어오는 광학 신호를 전기로 변환하고, 패킷 헤더를 읽어 라우팅한 뒤, 다시 빛으로 변환해야 합니다. 이 과정은 엄청난 전력을 소모합니다.
반면 OCS에는 미세한 MEMS (Micro-Electro-Mechanical Systems) 거울 배열이 들어 있습니다. 연결이 설정되면 거울이 물리적으로 기울어져 입력 광섬유에서 나오는 레이저 빔을 출력 광섬유로 직접 반사합니다.
- 제로 전력 오버헤드 (Zero Power Overhead): 일단 거울의 방향이 설정되면, 대역폭이 아무리 커져도 데이터를 라우팅하는 데 추가적인 전력이 들지 않습니다.
- 동적 토폴로지 (Dynamic Topology): TPU 칩에 장애가 발생하면(거대한 규모에서는 매일 일어나는 일입니다), OCS는 엔지니어가 물리적으로 랙의 케이블을 다시 꽂을 필요 없이 거울을 조정하여 죽은 칩을 우회하도록 논리적 Torus 토폴로지를 즉시 재구성합니다.
4. Interactive: Cluster Topology Explorer
아래의 탐색기를 사용하여 Rack-Scale NVLink, Fat-Tree Ethernet, 그리고 TPU Torus 토폴로지 간의 아키텍처적 차이를 직관적으로 비교해 보십시오.
A Scale-Up architecture where all GPUs within a single rack are fully connected (All-to-All) via a copper backplane with 130 TB/s bandwidth.
5. 물리적 현실: 전력(Power)과 엔트로피(Entropy)
100,000개의 GPU를 운영하는 것은 열역학과 엔트로피와의 전쟁입니다.
전력 스파이크(Power Spike) 문제
10만 개의 GPU 클러스터는 소도시 하나를 운영할 수 있는 약 250 메가와트(MW) 의 전력을 끌어다 씁니다. AI 워크로드는 극도로 동기화되어 있습니다. 순전파(Forward pass)와 역전파(Backward pass) 중에는 전력 소비가 극대화됩니다. 그러나 네트워크를 통해 그래디언트를 동기화(All-Reduce)하거나 스토리지에 체크포인트를 기록하기 위해 GPU 연산이 일시 중지되면, 연산 활용도는 0에 가깝게 떨어집니다.
이는 전력 수요에 있어 폭력적이고 순간적인 변동(수십 밀리초 만에 수십 메가와트가 급락하고 급등함)을 일으킵니다. 지역 전력망은 이러한 변동성을 감당할 수 없습니다. 전력망 차단기가 내려가는 것을 막기 위해 하이퍼스케일러들은 데이터센터 바로 옆에 거대한 배터리 에너지 저장 시스템 (BESS, Battery Energy Storage Systems) (예: Tesla Megapack)을 배치하여 이러한 순간적인 스파이크를 완충합니다 [2].
폭발 반경 (The Blast Radius)
10만 개의 부품이 모인 규모에서는 평균 무고장 시간(MTBF, Mean Time Between Failures)이 시간 단위로 측정됩니다. 우주선(Cosmic rays)이 메모리 비트를 뒤집어 조용한 데이터 손상(Silent Data Corruption)을 일으키고, 광 트랜시버가 타버리며, 액체 냉각 펌프의 성능이 저하됩니다. 이 스케일에서 인프라 엔지니어링은 고장을 ‘예방’하는 것보다 폭발 반경(Blast Radius) 을 최소화하는 데 초점을 맞춥니다. 단 하나의 NIC(네트워크 카드) 고장이 1만 개 GPU의 학습 작업을 중단시키지 않도록, 분산된 체크포인트를 통해 즉각적으로 복구할 수 있는 회복 탄력성(Resilience)을 확보하는 것이 핵심입니다.
6. 소프트웨어 추상화: NCCL
그렇다면 AI 연구자는 이 거대한 인프라를 실제로 어떻게 사용할까요? 연구자들은 소켓(Socket) 코드를 직접 작성하거나 MEMS 거울을 구성하지 않습니다. 물리적 네트워크의 복잡성은 통신 라이브러리, 특히 NCCL (NVIDIA Collective Communications Library) 에 의해 완벽하게 추상화됩니다.
PyTorch 스크립트가 분산 연산을 호출하면, NCCL은 물리적 토폴로지를 쿼리(Query)합니다. 두 GPU가 동일한 NVLink 스위치를 공유하는지, 아니면 BlueField DPU를 통해 RoCEv2를 타고 외부로 나가야 하는지 자동으로 감지하고, 텐서를 이동시키기 위한 최적의 알고리즘(예: Ring 또는 Double-Tree 라우팅)을 실행합니다.
import torch
import torch.distributed as dist
import os
def setup_distributed_environment():
# 프로덕션 클러스터에서는 Slurm과 같은 오케스트레이터에 의해 환경 변수가 주입됩니다.
os.environ.setdefault('MASTER_ADDR', '10.0.0.1')
os.environ.setdefault('MASTER_PORT', '29500')
os.environ.setdefault('WORLD_SIZE', '8')
os.environ.setdefault('RANK', '0')
os.environ.setdefault('LOCAL_RANK', '0')
# NCCL 백엔드를 초기화합니다. NCCL은 NVLink, PCIe,
# 그리고 InfiniBand/RoCEv2를 통한 물리적 라우팅을 자동으로 처리합니다.
dist.init_process_group(backend='nccl')
local_rank = int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(local_rank)
return local_rank
def sync_gradients(model: torch.nn.Module):
"""
All-Reduce 연산을 수동으로 적용하는 예시입니다.
실제 환경에서는 DistributedDataParallel (DDP)가 이를 자동으로 처리합니다.
"""
# 모델의 모든 파라미터를 순회합니다.
for param in model.parameters():
if param.grad is not None:
# 클러스터 내의 모든 GPU에 걸쳐 그래디언트를 동기적으로 합산(SUM)합니다.
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
# 전체 GPU 개수(World Size)를 기반으로 그래디언트의 평균을 구합니다.
param.grad.data /= dist.get_world_size()
if __name__ == "__main__":
# local_rank = setup_distributed_environment()
# model = MyFoundationModel().cuda(local_rank)
# ... compute loss and loss.backward() ...
# sync_gradients(model)
pass물리적 인프라가 구축되고 네트워크가 안정화되었으니, 이제 다음 과제에 직면하게 됩니다. “이 수조 개의 파라미터를 가진 거대한 모델을 어떻게 쪼개어 수만 개의 GPU에 효율적으로 분산시킬 것인가?” 이어지는 Chapter 7: Training Optimization & Systems 에서는 3D 병렬화(3D Parallelism)와 ZeRO 최적화 기법을 심도 있게 탐구할 것입니다.
Quizzes
Quiz 1: 개의 디바이스에 걸쳐 전문가 병렬 처리(Expert Parallelism)를 수행하는 Mixture-of-Experts(MoE) 모델을 가정합니다. 글로벌 배치 크기는 토큰입니다. 각 토큰은 개의 전문가를 선택합니다. 히든 차원(Hidden dimension)은 이고 데이터 타입은 float16(2바이트)입니다. 균등한 전문가 라우팅 분포를 가정할 때, 전문가 디스패치(Dispatching)를 위한 All-to-All 통신 단계에서 단일 디바이스가 전송해야 하는 총 데이터 볼륨(Gigabytes, GB 단위)을 유도하고 계산하세요.
디스패칭 전 디바이스당 로컬 배치 크기는 토큰입니다. Top- 게이팅()을 적용하면 각 토큰은 2개의 전문가에게 전달됩니다. 균등 분포를 가정하면 각 디바이스는 할당된 토큰의 을 자체 유지하고 를 다른 디바이스로 전송합니다. 디바이스당 총 전송 토큰 수 = 토큰입니다. 토큰당 데이터 볼륨 = 입니다. 단일 디바이스가 전송하는 총 데이터 볼륨 = (또는 )입니다.
Quiz 2: RoCEv2 네트워크에서 분산 학습을 수행할 때, RDMA(Remote Direct Memory Access)는 전통적인 TCP/IP 통신과 근본적으로 어떻게 다릅니까?
전통적인 TCP/IP는 데이터가 OS 커널을 통과해야 하므로 CPU 인터럽트가 발생하고 유저 공간과 커널 공간 사이에서 여러 번의 메모리 복사가 일어납니다. 반면 RDMA는 네트워크 인터페이스 카드(NIC)가 CPU와 OS를 완전히 우회하여 대상 GPU의 HBM(고대역폭 메모리)에 직접 데이터를 읽고 쓸 수 있게 합니다. 이로 인해 지연 시간이 밀리초(ms)에서 마이크로초(μs) 단위로 단축되며, 이는 동기식 그래디언트 업데이트에서 절대적으로 중요합니다.
Quiz 3: 대규모 TPU 팟(Pod)에서 구글이 전통적인 전기적 패킷 스위치 대신 광학 회로 스위치(OCS)를 사용하여 얻는 가장 핵심적인 아키텍처적 이점은 무엇입니까?
OCS는 MEMS 거울을 사용하여 빛을 물리적으로 반사하므로, 한 번 경로가 설정되면 데이터를 전송하는 데 전력이 거의 들지 않습니다. 또한 칩에 장애가 발생했을 때 물리적인 케이블 재배치 없이 거울의 각도만 조절하여 네트워크 토폴로지를 동적으로 재구성할 수 있습니다.
Quiz 4: xAI의 10만 개 GPU 클러스터(Colossus)와 같은 거대 AI 클러스터가 전력망에 직접 연결하는 것에 그치지 않고 Tesla Megapack과 같은 거대한 배터리 에너지 저장 시스템(BESS)을 함께 구축해야 하는 이유는 무엇입니까?
AI 학습 워크로드는 극도로 동기화되어 있습니다. 수만 개의 GPU가 동시에 연산을 마치고 통신 단계로 진입하거나 체크포인트를 저장할 때, 데이터센터 전체의 전력 수요가 순간적으로 수십 메가와트씩 급락하거나 급등합니다. 배터리 시스템은 이러한 극단적이고 폭력적인 전력 스파이크를 완충하여 지역 전력망이 불안정해지거나 차단기가 떨어지는 것을 방지하는 역할을 합니다.
References
- NVIDIA. (2024). “NVIDIA GB200 NVL72 Architecture.” Link.
- ServeTheHome. (2024). “Inside the 100K GPU xAI Colossus Cluster that Supermicro Helped Build for Elon Musk.” Link.
- Meta. (2024). “Meta Unveils 24k GPU AI Infrastructure Design.” Link.
- Google Cloud. (2024). “Google TPU Architecture: 7 Generations Explained.” Link.