8.1 The Power Law: 딥러닝의 열역학
2020년 이전의 딥러닝 아키텍처 설계는 직관, 휴리스틱(heuristics), 그리고 시행착오에 크게 의존했습니다. 엔지니어들은 모델을 만들고 학습시키면서 손실(loss) 곡선이 만족스러운 수치로 수렴하기만을 바랐습니다. 하지만 신경망의 성능이 무작위가 아니라 Scaling Laws (스케일링 법칙) 이라는 엄격하고 예측 가능한 수학적 방정식에 의해 지배된다는 사실이 밝혀지면서 패러다임이 근본적으로 바뀌었습니다.
Backpropagation (오차역전파)이 딥러닝의 ‘역학(mechanics)‘이라면, Scaling Laws 는 ‘열역학(thermodynamics)‘에 비유할 수 있습니다. 이는 시스템의 거시적인 동작, 즉 Compute (연산량), Data (데이터), Parameters (파라미터 수) 라는 세 가지 핵심 자원을 확장함에 따라 모델의 최종 손실(Loss)이 어떻게 변화하는지를 설명합니다.
이러한 예측 가능성 덕분에 AI 연구소들은 작고 저렴한 모델을 학습시켜 곡선을 피팅(fitting)한 뒤, 수백억 원이 드는 대규모 학습을 시작하기도 전에 그 최종 성능을 정확하게 예측할 수 있게 되었습니다.
경험적 발견 (The Empirical Discovery)
예측 가능한 확장에 대한 초기 관찰은 2017년 Hestness 등에 의해 문서화되었지만 [1], 현대의 Large Language Models (LLMs)를 위한 결정적인 공식화는 2020년 OpenAI의 Kaplan 연구진에 의해 발표되었습니다 [2].
수천 개에서 수십억 개의 파라미터를 가진 수십 개의 Transformer 모델을 학습시킨 결과, 이들은 세 가지 변수 중 어느 하나라도 병목(bottleneck)으로 작용하지 않는 한, Cross-entropy test loss ()가 Power Law (멱법칙) 에 따라 감소한다는 사실을 발견했습니다.
- (Parameters) : 임베딩(embedding)을 제외한 파라미터의 수.
- (Data) : 학습에 사용된 토큰(tokens)의 수.
- (Compute) : 학습 중 사용된 총 부동소수점 연산량 (FLOPs).
수학적 공식 (The Mathematical Formulation)
Power law 관계는 세 가지 독립적인 방정식으로 표현할 수 있습니다:
여기서:
- 는 손실이 얼마나 빨리 떨어지는지를 결정하는 스케일링 지수입니다. Kaplan은 이 값들을 대략 , , 으로 추정했습니다.
- 는 특성 척도(characteristic scales)를 나타내는 상수입니다.
- 은 데이터셋에 내재된 본질적 엔트로피 (inherent entropy) 입니다.
환원 불가능한 손실의 하한선 (The Irreducible Loss Floor)
항은 이론적인 최솟값을 의미합니다. 자연어에는 본질적인 모호성, 노이즈, 그리고 관찰되지 않은 컨텍스트가 포함되어 있습니다. 무한한 파라미터와 무한한 연산량을 가진 이론적인 모델조차도 매번 다음 토큰을 완벽하게 예측할 수는 없으며, 단지 이 근본적인 엔트로피 하한선에 근접할 수 있을 뿐입니다. 모델이 기하급수적으로 커짐에 따라 수확 체감의 법칙이 적용되어 손실 곡선은 평평해지며 이 하한선에 점근적으로 다가갑니다.
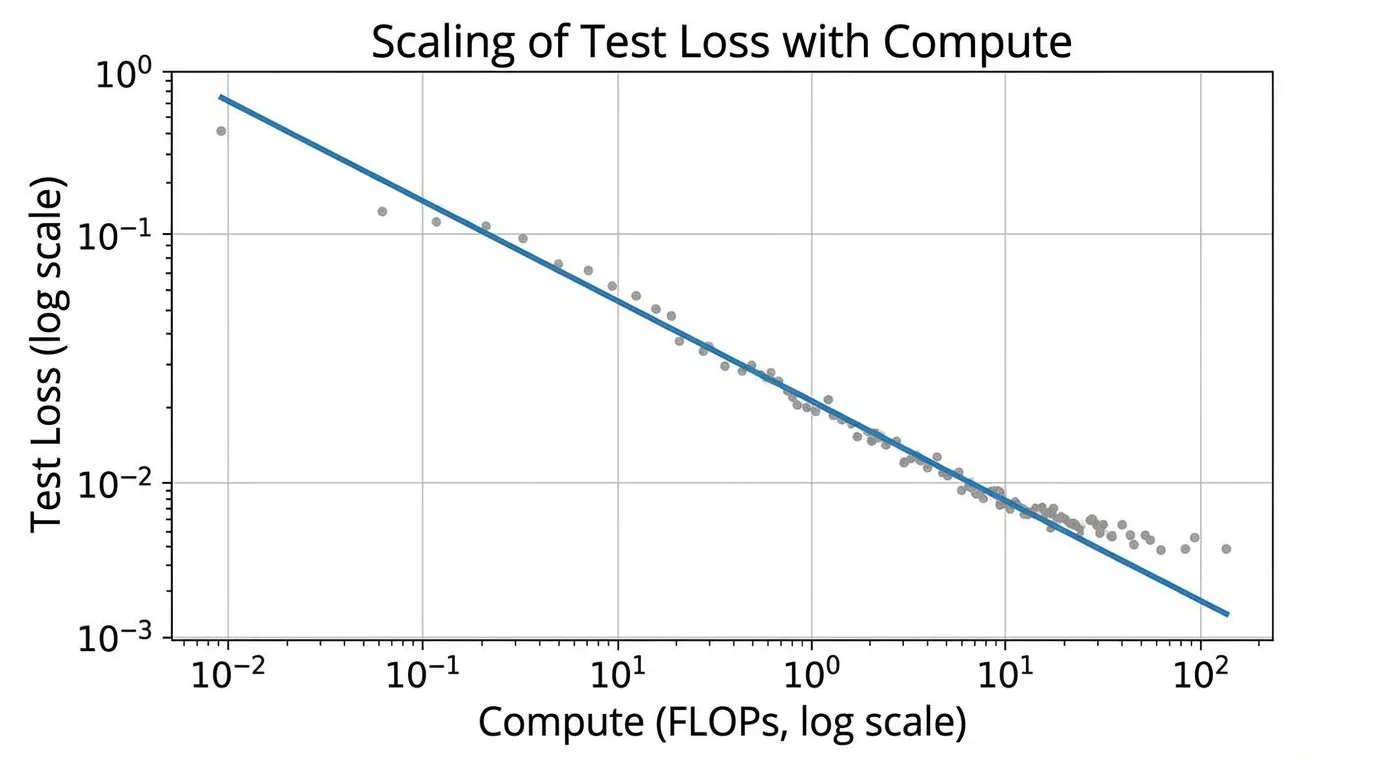
Log-Log 선형성 (Log-Log Linearity)
Power law 는 Log-Log 그래프(양대수 그래프)에서 가장 명확하게 시각화됩니다. 환원 불가능한 손실을 잠시 무시하고(하한선에서 멀리 떨어져 있다고 가정), 연산량 확장에 대한 방정식에 로그를 취하면 다음과 같습니다:
이는 직선의 방정식 ()과 동일합니다. 이러한 선형성(linearity)이야말로 엔지니어링 관점에서 스케일링 법칙을 매우 강력하게 만드는 요소입니다. 10M, 100M, 1B 파라미터 모델의 손실을 Log-Log 그래프에 점으로 찍고 그 사이를 관통하는 직선을 그으면, 100B 파라미터 거대 모델의 최종 손실을 놀라울 정도로 정확하게 예측할 수 있습니다.
Interactive Scaling Law: Loss vs. Compute
PyTorch 로 손실 외삽하기 (Extrapolating Loss in PyTorch)
실제 현업에서 Foundation Model 엔지니어들은 대규모 학습이 정상적인 궤도를 벗어나지 않았는지 확인하기 위해 스케일링 법칙을 사용합니다. 초기 소규모 실험에 곡선을 피팅하여 예상되는 손실의 “베이스라인(baseline)“을 설정하는 것입니다.
다음의 PyTorch 코드는 일련의 소규모 학습 결과에 Power law 곡선을 경험적으로 피팅(fitting)하여, 엑사플롭스(ExaFLOP) 규모 모델의 예상 손실을 프로젝션하는 방법을 보여줍니다.
import torch
import torch.nn as nn
import torch.optim as optim
# 경험적 데이터: (Compute in PetaFLOPs, Validation Loss)
# 소규모 실험 실행을 기반으로 한 시뮬레이션 데이터
compute_flops = torch.tensor([1e1, 1e2, 1e3, 1e4, 1e5], dtype=torch.float32)
empirical_loss = torch.tensor([4.65, 3.72, 3.10, 2.68, 2.41], dtype=torch.float32)
class PowerLawFitter(nn.Module):
"""
다음 방정식을 피팅합니다: L(C) = a * C^(-alpha) + E
수치적 안정성을 위해 로그 공간(log-space)에서 최적화를 진행합니다.
"""
def __init__(self):
super().__init__()
# 합리적인 초깃값으로 파라미터 초기화
self.log_a = nn.Parameter(torch.tensor(2.0))
self.alpha = nn.Parameter(torch.tensor(0.05))
self.E = nn.Parameter(torch.tensor(1.5)) # Irreducible entropy floor
def forward(self, C):
a = torch.exp(self.log_a)
return a * torch.pow(C, -self.alpha) + self.E
def fit_scaling_law(compute, loss, epochs=5000, lr=0.01):
model = PowerLawFitter()
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.MSELoss()
for epoch in range(epochs):
optimizer.zero_grad()
predictions = model(compute)
# 상대 오차를 동등하게 페널티하기 위해 손실의 로그값에 MSE를 적용
fit_loss = criterion(torch.log(predictions), torch.log(loss))
fit_loss.backward()
optimizer.step()
if epoch % 1000 == 0:
print(f"Epoch {epoch} | Fit MSE: {fit_loss.item():.6f}")
return model
# 최적화 실행
fitted_model = fit_scaling_law(compute_flops, empirical_loss)
# 학습된 계수 추출
a_learned = torch.exp(fitted_model.log_a).item()
alpha_learned = fitted_model.alpha.item()
E_learned = fitted_model.E.item()
print(f"\nFitted Equation: L(C) = {a_learned:.2f} * C^(-{alpha_learned:.4f}) + {E_learned:.2f}")
# 1 ExaFLOP 실행에 대한 손실 예측 (1e6 PetaFLOPs)
c_next_gen = torch.tensor([1e6], dtype=torch.float32)
predicted_loss = fitted_model(c_next_gen).item()
print(f"Predicted Loss for 1 ExaFLOP: {predicted_loss:.3f}")창발적 능력의 “신기루” (The “Mirage” of Emergent Abilities)
스케일링 법칙에서 반드시 짚고 넘어가야 할 중요한 미묘함은 Cross-entropy loss 와 Downstream task accuracy (하위 작업 정확도) 간의 차이입니다.
Cross-entropy loss 는 완벽하게 매끄럽고 예측 가능한 Power law 를 따르는 반면, MMLU 나 GSM8K 와 같은 특정 벤치마크에서의 성능은 특정 규모 임계값을 넘을 때 갑작스럽고 불연속적인 성능 도약을 보이는 “창발적 능력 (Emergent Abilities)“을 나타내는 것처럼 보입니다.
하지만 Schaeffer 등 (2023)의 연구 [3]는 이러한 창발성이 평가지표(metric)의 선택에 의해 발생하는 신기루에 불과하다고 주장합니다. Cross-entropy 는 연속적(continuous)이며 토큰에 대한 확률 분포를 측정합니다. 만약 모델이 정답에 부여하는 확률을 1%에서 10%로 향상시킨다면, 손실(loss)은 매끄럽게 감소합니다. 하지만 객관식 벤치마크에서는 그 확률이 경쟁하는 오답들의 확률을 뛰어넘을 때까지 모델의 점수는 계속 0점일 것이며, 정답 확률이 오답 확률을 넘어서는 순간 정확도는 갑자기 100%로 치솟게 됩니다.
즉, (손실로 측정되는) 근본적인 지능은 예측 가능하게 확장되지만, 계단 함수(step-function) 형태의 평가 지표가 갑작스러운 창발의 환상을 만들어낸다는 것입니다.
Quizzes
Quiz 1: 스케일링 법칙을 위해 파라미터 수 을 계산할 때, 연구자들이 임베딩(embedding) 파라미터를 명시적으로 제외하는 이유는 무엇일까요?
임베딩 파라미터는 핵심 연산 엔진의 깊이나 구조적 복잡성이 아니라, (고정된) 어휘 사전(vocabulary)의 크기와 은닉 차원(hidden dimension)에 엄격하게 비례하여 커집니다. 이를 포함시키면 실제 연산 능력과 손실 간의 관계가 왜곡될 수 있으며, 특히 전체 파라미터에서 임베딩이 차지하는 비중이 비정상적으로 큰 소규모 모델에서 이러한 왜곡이 심하게 나타나기 때문입니다.
Quiz 2: 방정식 에서, 이 나타내는 물리적 또는 이론적 한계는 무엇입니까?
이는 데이터셋의 본질적 엔트로피(또는 베이즈 위험, Bayes risk)를 나타냅니다. 자연어에는 피할 수 없는 모호성, 노이즈, 관찰되지 않은 컨텍스트가 포함되어 있습니다. 무한한 파라미터와 무한한 연산량을 가진 이론적인 모델조차도 매번 다음 토큰을 완벽하게 예측할 수는 없으며, 단지 이 근본적인 엔트로피 하한선에 근접할 수 있을 뿐입니다.
Quiz 3: Kaplan의 초기 연구 결과에 따르면, 연산량(Compute budget)이 10배 증가했을 때 모델 크기와 데이터 양을 동일한 비율로 확장해야 합니까?
아닙니다. Kaplan 연구진은 새로운 연산량의 대부분을 데이터보다는 모델 크기(파라미터)에 할당하는 것이 성능 확장에 더 효율적이라고 결론지었습니다. 즉, 데이터 크기보다 파라미터를 훨씬 더 빠르게 확장해야 한다고 제안했습니다. (참고: 이 결론은 훗날 Chinchilla 스케일링 법칙에 의해 반박되었으며, 1:1의 균형 잡힌 확장 접근법으로 정정되었습니다).
Quiz 4: 스케일링 법칙이 그토록 신뢰할 수 있다면, 왜 모델 학습 도중에 예상 곡선을 벗어나는 갑작스러운 “Loss Spikes (손실 급증)” 현상이 발생하는 것일까요?
스케일링 법칙은 안정적인 학습 조건 하에서의 최적화되고 수렴된 최종 손실을 예측합니다. Loss Spikes 는 잘못된 데이터 배치, 학습률(learning rate) 관리 실패, 또는 수치적 불안정성(예: FP16에서의 Gradient 폭발) 등으로 인해 발생하는 최적화 실패입니다. 이는 이론적인 스케일링 한계가 무너진 것이 아니라, 옵티마이저(optimizer)가 손실 공간(loss landscape)을 탐색하는 데 실패했음을 의미합니다.
References
- Hestness, J., et al. (2017). Deep Learning Scaling is Predictable, Empirically. arXiv:1712.00409.
- Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361.
- Schaeffer, R., et al. (2023). Are Emergent Abilities of Large Language Models a Mirage? arXiv:2304.15004.