1.3 Deep Learning Paradigms
To understand how foundation models are built and aligned, we must explore the three fundamental paradigms of machine learning and how they converge in modern AI systems.
Motivation: The Recipe for General Intelligence
Why do we need different paradigms? Because no single method is sufficient to build a safe, useful AI:
- Scale requires Self-Supervision: Human-labeled data is too scarce to build massive knowledge bases.
- Instruction requires Supervision: Pure text completion doesn’t make a good assistant.
- Safety requires Reinforcement Learning: We need to align model behavior with human values, which is hard to specify in rules or labels.
Understanding these paradigms helps you navigate the complex training pipelines of modern LLMs.
The Metaphor: The Three Ways to Learn
Imagine you are trying to learn how to play a complex strategy game.
- Supervised Learning is like learning with a Coach. The coach shows you a board state and tells you exactly what move to make. You learn by mimicking the expert.
- Self-Supervised Learning is like reading every book ever written about the game. You don’t have a coach, but by reading millions of sentences, you figure out which words (and concepts) usually follow each other. You learn the structure of the game’s world.
- Reinforcement Learning is like playing the game yourself. You make moves, sometimes you win, sometimes you lose. You adjust your strategy based on the feedback (rewards) from the game itself.
Modern Foundation Models use all three of these methods in a specific sequence to achieve state-of-the-art performance.
Yann LeCun’s Cake Analogy: To explain the relative information content of these paradigms, AI pioneer Yann LeCun famously introduced a cake metaphor. He described machine learning as a cake where self-supervised learning is the cake itself (the massive bulk of information), supervised learning is the icing (a small amount of information), and reinforcement learning is the cherry on top (a tiny amount of information). This highlights that the vast majority of what a foundation model knows comes from self-supervised learning on massive datasets.
A Brief History of Paradigm Shift
- The Supervised Era (2012-2018): Deep learning took off with supervised tasks like ImageNet classification. Models were brilliant but narrow specialists.
- The Self-Supervised Revolution (2018-Present): Models like BERT [1] and GPT showed that predicting missing words in unlabeled text leads to rich, general representations. This enabled the “Foundation” aspect.
- The Alignment Era (2022-Present): InstructGPT [2] popularized RLHF, showing that we can align these massive models to be helpful assistants rather than just text completers.
Comparison: The Three Paradigms
| Feature | Supervised Learning | Self-Supervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data Type | Labeled | Unlabeled (Self-labeled) | Environment interactions |
| Feedback | Direct correction | Predicting parts of data | Scalar rewards |
| Pros | High precision on clear tasks | Scales infinitely with data | Can learn complex policies |
| Cons | Expensive data labeling | May learn noise/bias | Highly unstable to train |
| Role in LLMs | Instruction tuning (SFT) | Core Pre-training | Human preference alignment |
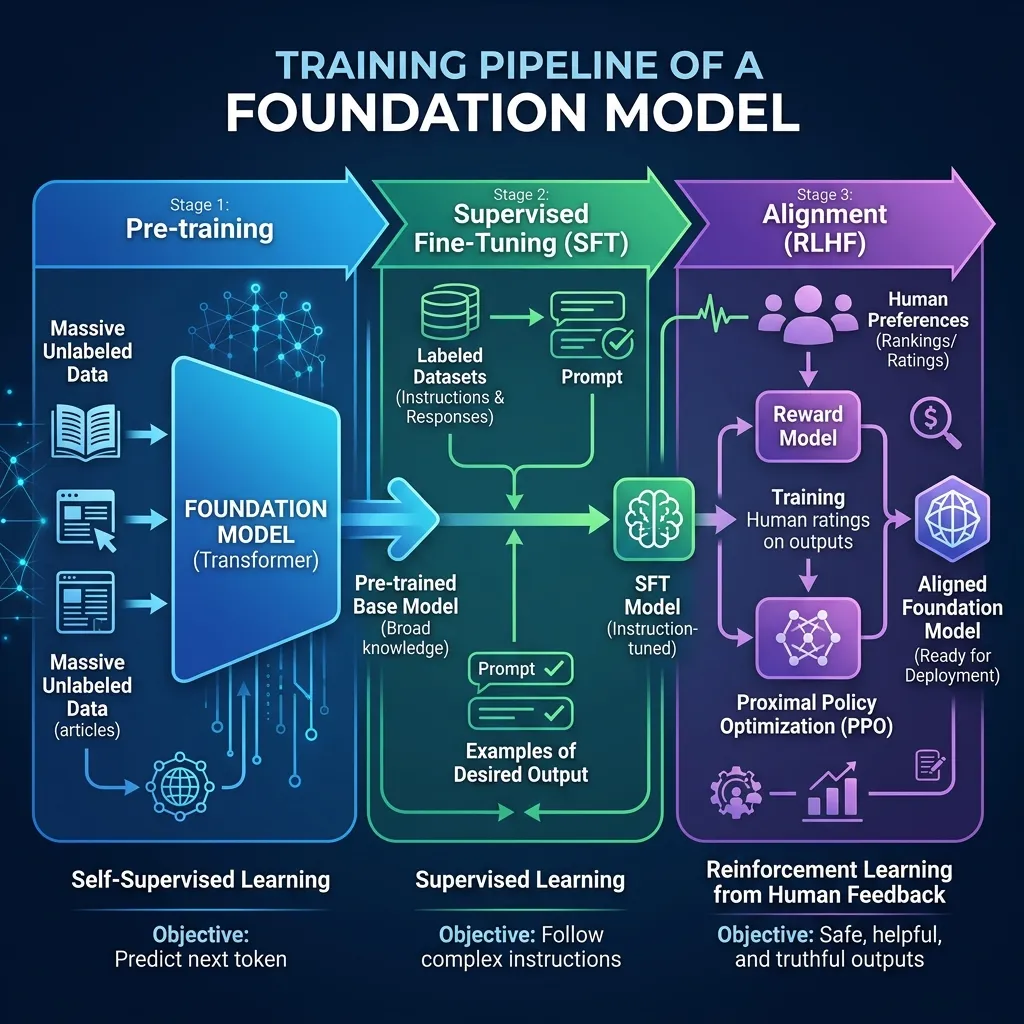
The Convergence in Foundation Models
Modern foundation models are built using a staged pipeline that combines these paradigms:
- Pre-training (Self-Supervised): Train on massive text data to learn language structure and general knowledge. This is where the model becomes smart.
- Supervised Fine-Tuning (SFT): Fine-tune on high-quality instruction data to learn to follow prompts and behave as an assistant.
- Alignment (RLHF): Use reinforcement learning with a reward model trained on human preferences to make the model helpful, honest, and harmless [2].
Autoregressive Loss Calculation
Let’s look at the core loss function used in the Self-Supervised pre-training of LLMs. It is typically the Cross-Entropy Loss applied to predicting the next token.
Here is a PyTorch snippet demonstrating how this loss is calculated for a single step.
import torch
import torch.nn as nn
# Vocabulary size and sequence length
vocab_size = 5000
seq_len = 5
# Simulated logits from a model (Batch_size, Seq_len, Vocab_size)
logits = torch.randn(2, seq_len, vocab_size)
# Target tokens (Batch_size, Seq_len) - the actual next tokens
targets = torch.randint(0, vocab_size, (2, seq_len))
# CrossEntropyLoss expects (N, C, ...) or (N, C)
# We flatten the batch and sequence dimensions
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, vocab_size), targets.view(-1))
print(f"Calculated Autoregressive Loss: {loss.item():.4f}")Example: Next Token Prediction
Experience how an Autoregressive model works. Select a prompt, and see the simulated probabilities for the next word. This is the core mechanism of Self-Supervised learning in LLMs.
Next Token Prediction
Select a prompt to see simulated probabilities for the next word.
Quizzes
Quiz 1: Why is Self-Supervised Learning considered the breakthrough for LLMs?
Because it removes the dependency on human-labeled data. SSL allows models to learn from raw, unlabeled text by creating its own labels (e.g., predicting the next word). This enables training on massive, internet-scale datasets, which is necessary for emergent capabilities.
Quiz 2: How does Reinforcement Learning differ from Supervised Learning?
In Supervised Learning, the model is given the correct output for every input. In Reinforcement Learning, the model is not told the correct action but must discover which actions yield the highest reward through trial and error interaction with an environment.
Quiz 3: What role does Supervised Fine-Tuning (SFT) play after pre-training?
Pre-training makes the model a powerful text completer, but not necessarily a good assistant. SFT trains the model on specific prompt-response pairs, teaching it to understand user intent and respond in a helpful, conversational manner.
Quiz 4: Why is RLHF needed even after SFT?
SFT teaches the model the format of an assistant, but it still mimics the training data (which may contain biases or unhelpful answers). RLHF allows humans to score model outputs, guiding the model to prefer answers that are safer, more helpful, and aligned with human values, even if they deviate from pure imitation.
Quiz 5: Can a model be trained entirely on Reinforcement Learning from scratch for natural language?
In theory, yes, but in practice, it is extremely difficult. The action space (all possible words) is too large for random exploration to succeed in generating coherent language. Pre-training with SSL is necessary to give the model a basic understanding of language before RL can be effectively applied.
Quiz 6: Formulate the objective function for Proximal Policy Optimization (PPO) with clipping, and explain how it prevents excessively large policy updates.
The clipped PPO objective is defined as: , where is the probability ratio, and is the estimated advantage at time . The operator forms a pessimistic lower bound. If the advantage is positive (), the objective increases as increases, but it is capped at , preventing the policy from changing too drastically in a positive direction. If the advantage is negative (), the objective increases as decreases, but it is bounded from below by , preventing excessive degradation of the policy.
References
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805.
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. arXiv:2203.02155.