7.3 Model & Pipeline Parallelism
In the previous section, we explored how ZeRO solves the Memory Wall by dynamically partitioning model states across a cluster. However, ZeRO has a fundamental limitation: it operates at the layer level. During a forward or backward pass, ZeRO must reconstruct the entire weight matrix of a specific layer on a single GPU.
As Foundation Models scale beyond 100 billion parameters, the mathematical operations themselves become too colossal. For a sufficiently large model or an extremely long context window, the activations and weights of a single layer will exceed the 80GB VRAM limit of an H100 GPU. When a single matrix multiplication cannot fit into memory, Data Parallelism (even with ZeRO) fails. We must physically shard the model itself.
This brings us to the two pillars of model sharding: Pipeline Parallelism (Inter-layer) and Tensor Parallelism (Intra-layer).
1. Pipeline Parallelism (PP)
Pipeline Parallelism treats the neural network like a factory assembly line. Instead of placing the entire model on one GPU, we slice the model by depth. For a 40-layer Transformer on 4 GPUs, GPU 0 handles layers 1-10, GPU 1 handles layers 11-20, and so on.
The Bubble Problem and Micro-batching
The naive approach to PP is disastrous for hardware utilization. If GPU 0 processes a batch and sends it to GPU 1, GPU 0 sits idle until the backward pass returns. This idle time is known as the Pipeline Bubble.
To mitigate this, Google introduced GPipe [1]. GPipe divides a large mini-batch into smaller micro-batches. GPU 0 processes Micro-batch 1 () and immediately passes it to GPU 1. While GPU 1 works on , GPU 0 can start processing . This keeps the pipeline “full” and drastically shrinks the relative size of the bubble.
1F1B (One-Forward-One-Backward)
While GPipe solves the utilization problem, it creates a severe memory problem. GPipe executes all forward micro-batches before executing any backward micro-batches. This means GPU 0 must store the activations for every single micro-batch in memory until the backward pass eventually arrives.
Modern frameworks (like Megatron-LM) replace GPipe with the 1F1B (One-Forward-One-Backward) schedule. In 1F1B, as soon as the last GPU finishes a forward pass for a micro-batch, it immediately executes the backward pass. This backward pass propagates up the pipeline, interleaving with forward passes.
By running backward passes early, 1F1B frees the activation memory immediately. While the pipeline bubble size remains mathematically identical to GPipe, the peak memory footprint is drastically reduced, bounded only by the number of pipeline stages rather than the number of micro-batches.
Interactive Visualization: GPipe vs 1F1B
Use the visualizer below to compare the GPipe and 1F1B schedules. Pay close attention to the Peak Memory chart at the bottom, which tracks how many micro-batch activations GPU 0 must hold in memory at any given time.
Pipeline Execution Timeline (4 GPUs, 4 Micro-batches)
GPU 0 Peak Memory (Stored Activations)
1F1B interleaves forward and backward passes, immediately freeing activation memory after the backward pass completes.
2. Tensor Parallelism (TP)
While Pipeline Parallelism splits the model between layers, Tensor Parallelism (TP) splits the mathematical operations inside a single layer.
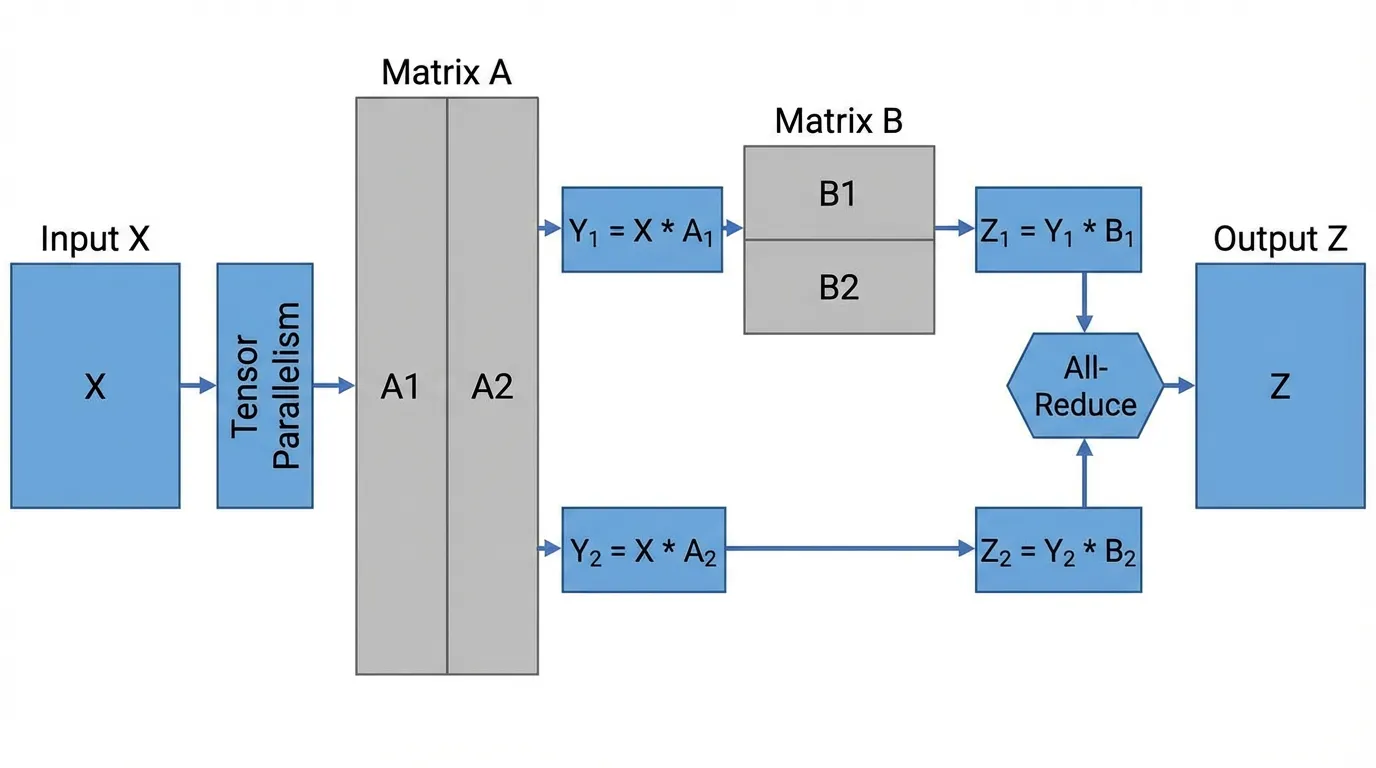
Spearheaded by NVIDIA’s Megatron-LM [2], TP is the engine that makes training massive models possible. It physically slices the weight matrices of the Multi-Head Attention (MHA) and Multi-Layer Perceptron (MLP) blocks across multiple GPUs.
 Source: Generated by Gemini. Inspired by Shoeybi et al., 2019.
Source: Generated by Gemini. Inspired by Shoeybi et al., 2019.
The Megatron-LM MLP Split
A standard Transformer MLP consists of two linear transformations: and . Megatron-LM uses a brilliant combination of Column Parallelism and Row Parallelism to distribute this computation while minimizing communication.
- Column Parallelism on : The first weight matrix is split vertically into and . GPU 0 computes and GPU 1 computes . Because the non-linear GeLU activation is element-wise, it can be applied independently on each GPU. Zero communication is required so far.
- Row Parallelism on : The second weight matrix is split horizontally into and . GPU 0 computes and GPU 1 computes .
- Synchronization: The final output requires summing the partial results: . This is achieved via a single All-Reduce operation.
Below is a realistic PyTorch implementation of the Megatron-style MLP block. Notice how standard single-GPU operations are replaced with distributed primitives.
import torch
import torch.nn as nn
import torch.distributed as dist
class MegatronMLP(nn.Module):
def __init__(self, d_model, d_ff, rank, world_size):
super().__init__()
# Column Parallelism: Split the output dimension
self.w1 = nn.Linear(d_model, d_ff // world_size)
# Row Parallelism: Split the input dimension
self.w2 = nn.Linear(d_ff // world_size, d_model)
self.gelu = nn.GELU()
def forward(self, x):
# 1. Column Parallel Forward (Independent computation, no comms)
# Input x: [batch, seq, d_model]
# Output y_local: [batch, seq, d_ff // world_size]
y_local = self.gelu(self.w1(x))
# 2. Row Parallel Forward (Compute partial sums)
# Output z_local: [batch, seq, d_model]
z_local = self.w2(y_local)
# 3. All-Reduce to sum the partial results across all TP GPUs
dist.all_reduce(z_local, op=dist.ReduceOp.SUM)
return z_localThe Communication Bottleneck
Tensor Parallelism is incredibly powerful, but it comes with a severe hardware constraint. As seen in the code, an All-Reduce operation is required inside every single Transformer block. This high-frequency, blocking communication demands massive bandwidth. Consequently, TP is almost strictly confined to GPUs within a single physical node (e.g., 8 GPUs connected via NVLink). Running TP across nodes over standard Ethernet or even InfiniBand would cripple training speed.
3. Sequence Parallelism (SP)
As the AI industry shifted towards massive context windows (e.g., 128k to 1M tokens), engineers hit a new Memory Wall. In standard TP, the weight matrices are sharded, but every GPU still holds the full sequence length of the activations. Since attention memory scales quadratically with sequence length, long contexts cause Out-Of-Memory (OOM) errors regardless of TP.
Sequence Parallelism (SP) [3] solves this by sharding the data along the sequence dimension itself. If the sequence length is 8,000 and we have 8 GPUs, each GPU only stores and processes 1,000 tokens.
- In the MLP layer, SP operates seamlessly because MLPs process tokens independently.
- In the Attention layer, SP requires complex communication algorithms (like Ring Attention or DeepSpeed-Ulysses) to allow tokens on GPU 0 to attend to tokens on GPU 7 without materializing the full sequence on any single device.
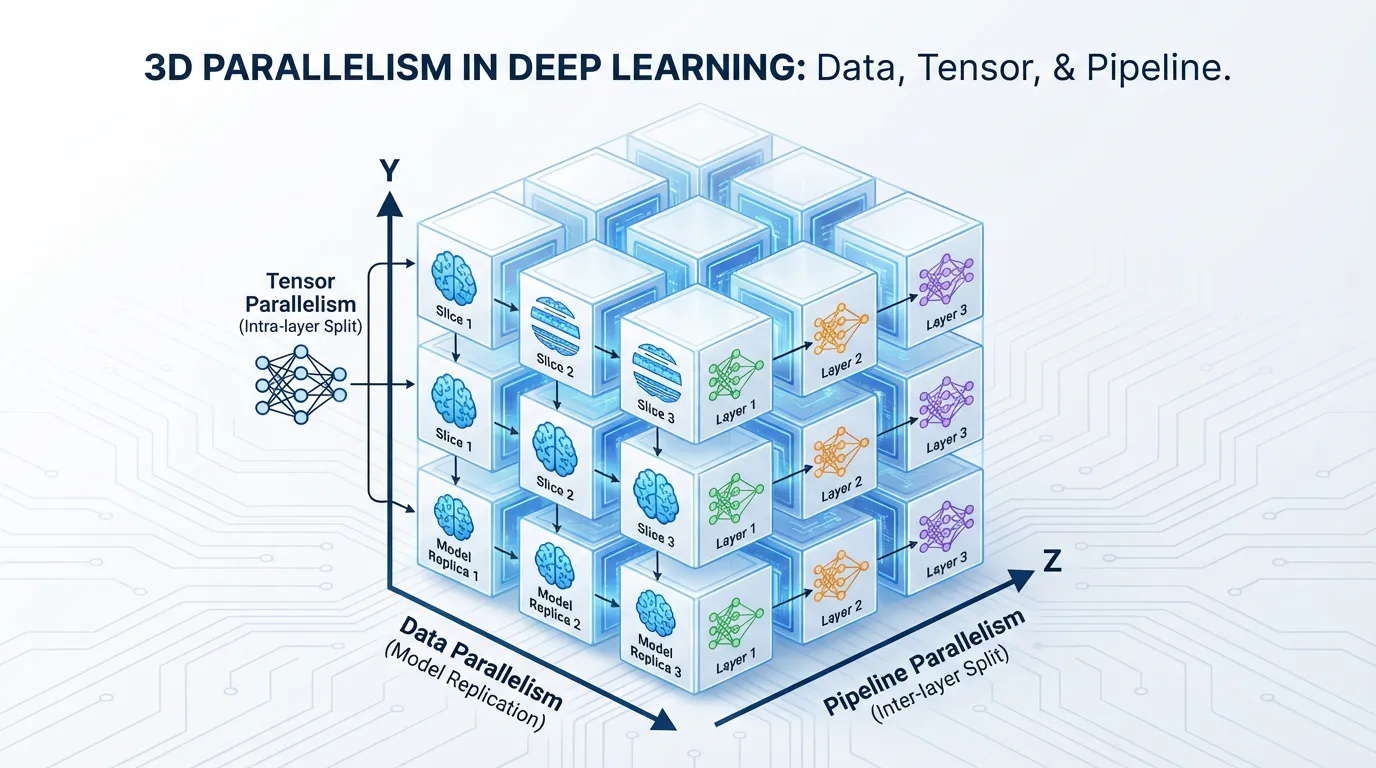
4. 3D Parallelism & Automated Sharding
To train a state-of-the-art model like Llama 3 or GPT-4, engineers do not choose between these techniques; they combine them into 3D Parallelism.
 Source: Generated by Gemini.
Source: Generated by Gemini.
- Tensor Parallelism (Intra-node): Shards the math across the 8 GPUs inside a single server using high-speed NVLink.
- Pipeline Parallelism (Inter-node): Shards the layers across multiple servers using InfiniBand.
- Data Parallelism (Cluster-wide): Replicates this entire TP+PP setup across thousands of servers to process massive datasets concurrently.
The Rise of Auto-Parallelism
Manually mapping a neural network to a 3D hardware topology is an agonizing engineering task. The current frontier of systems research is Automated Parallelism. Compilers like Alpa [4] treat parallelism as an optimization problem. By analyzing the model’s computational graph and the cluster’s network bandwidth, Alpa automatically derives the mathematically optimal combination of DP, TP, and PP without requiring engineers to write custom distributed code.
Quizzes
Quiz 1: Why does Megatron-LM specifically pair Column Parallelism for the first linear layer with Row Parallelism for the second linear layer in the MLP block?
By executing Column Parallelism first, the intermediate activation tensor is physically partitioned across the GPUs, requiring zero communication. The subsequent Row Parallelism computes a partial sum. This design ensures that the entire two-layer MLP block requires only a single All-Reduce synchronization at the very end, effectively halving the communication overhead compared to naive sharding.
Quiz 2: In Pipeline Parallelism, why does the 1F1B (One-Forward-One-Backward) schedule drastically reduce peak memory compared to GPipe, even though both have the exact same pipeline bubble size?
GPipe processes all forward micro-batches before starting any backward passes, forcing the early pipeline stages to store the activations for every single micro-batch in memory simultaneously. 1F1B interleaves the passes. As soon as a micro-batch completes its backward pass, its activations are freed. Therefore, 1F1B’s peak memory is bounded by the number of pipeline stages, independent of the total number of micro-batches.
Quiz 3: Why is Tensor Parallelism (TP) typically restricted to GPUs within the same physical server, while Pipeline Parallelism (PP) is often deployed across different servers?
TP requires a blocking All-Reduce synchronization inside every single Transformer block (multiple times per layer). This high-frequency communication requires the massive bandwidth and low latency of intra-node connections like NVLink. PP only communicates boundary activations between layers, which happens less frequently and requires far less bandwidth, making it suitable for inter-node connections like InfiniBand.
Quiz 4: How does Sequence Parallelism (SP) solve the memory bottleneck of extremely long context windows that standard Tensor Parallelism cannot resolve?
In standard Tensor Parallelism, the model weights are sharded, but every GPU still holds the full sequence length of the activations. For very long contexts, activation memory scales quadratically and causes OOM errors. SP partitions the sequence dimension itself, meaning each GPU only stores and processes a fraction of the tokens, drastically reducing the activation memory footprint.
Quiz 5: In Pipeline Parallelism with GPipe or 1F1B, let be the number of pipeline stages and be the number of micro-batches. Formulate the equation for the pipeline bubble size as a fraction of the total ideal compute time.
The pipeline bubble consists of micro-batches in both the forward and backward pass. Therefore, the total unutilized stages equal . The total ideal computational workload spans steps. The bubble fraction is expressed as: . As increases relative to , the bubble fraction approaches zero, maximizing cluster utilization.
References
- Huang, Y., et al. (2019). GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism. NeurIPS. arXiv:1811.06965.
- Shoeybi, M., et al. (2019). Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053.
- Li, S., et al. (2021). Sequence Parallelism: Making 4D Parallelism Possible. arXiv:2105.13120.
- Zheng, L., et al. (2022). Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. OSDI. arXiv:2201.12023.