2.3 The Dawn of Attention
The introduction of Attention was the pivotal moment that led directly to the Transformer and the modern era of foundation models. It solved the fundamental bottleneck of sequence-to-sequence (Seq2Seq) models.
Motivation: Breaking the Information Bottleneck
Imagine you are a translator reading a long document.
- Without Attention: You must read the entire document, remember everything, close the document, and then write the translation in another language from memory. This is what early Seq2Seq models tried to do.
- With Attention: You read the document, and as you write each word of the translation, you look back at the specific parts of the original text that are relevant to that word.
Attention allowed models to handle long sentences by letting the decoder “pay attention” to relevant input words dynamically.
The Metaphor: The Highlighter
Imagine you are studying for an exam by reading a massive textbook.
- The Old Way (RNN Encoder-Decoder) is like trying to memorize the entire chapter and summarize it into a single sticky note. Then you use only that sticky note to answer exam questions. If the chapter was 50 pages long, that sticky note is going to miss a lot of details.
- The Attention Way is like going through the chapter with a highlighter. When you are asked a specific question during the exam, you look back at the pages and focus your eyes on the highlighted parts that are most relevant to the question. You don’t need to fit everything into one sticky note; you have access to the whole book, but you know where to look.
The Seq2Seq Bottleneck
Before attention, the standard approach for tasks like machine translation was the Encoder-Decoder architecture using RNNs (or LSTMs).
- Encoder: Processes the input sequence and compresses all information into a single fixed-size vector, often called the Context Vector (or state).
- Decoder: Takes this single context vector and generates the output sequence.
The Problem
Imagine translating a 50-word sentence into another language. The encoder must cram all the meaning, syntax, and nuances of those 50 words into a single vector of, say, 512 numbers. This is a severe Bottleneck. The network forgets early parts of the sentence by the time it reaches the end.
💡 Behind the Scenes: The “Reversing the Input” Hack Before Attention was invented, researchers were desperate to fix this bottleneck. In 2014, Ilya Sutskever and his team at Google found a surprisingly simple hack: they fed the input sentence to the encoder backwards! (e.g., “A B C” became “C B A”). Why did this work? Because the beginning of the translated sentence is usually highly correlated with the beginning of the source sentence. By reversing the input, the first word “A” was processed last by the encoder, making it the freshest information in the context vector just as the decoder started generating the first translated word. This elegant but hacky solution massively improved performance, highlighting exactly how desperate the field was for a true “memory” mechanism—which Attention finally provided.
The Solution: Bahdanau Attention - Translating Like a Human
In 2014, Bahdanau, Cho, and Bengio published a landmark paper: “Neural Machine Translation by Jointly Learning to Align and Translate.” [1] They introduced the concept of Attention.
Behind-the-Scenes Story: This idea was inspired by how human translators work. When translating a long sentence, a human translator doesn’t memorize the entire sentence perfectly before starting to write the translation. Instead, as they write the translation, they constantly ‘look back’ at specific parts of the source text relevant to the word they are currently translating. The researchers wanted to give models this same ability to ‘look back’.
Instead of relying on a single fixed context vector, the decoder is allowed to “look back” at all the hidden states of the encoder at each step of generation.
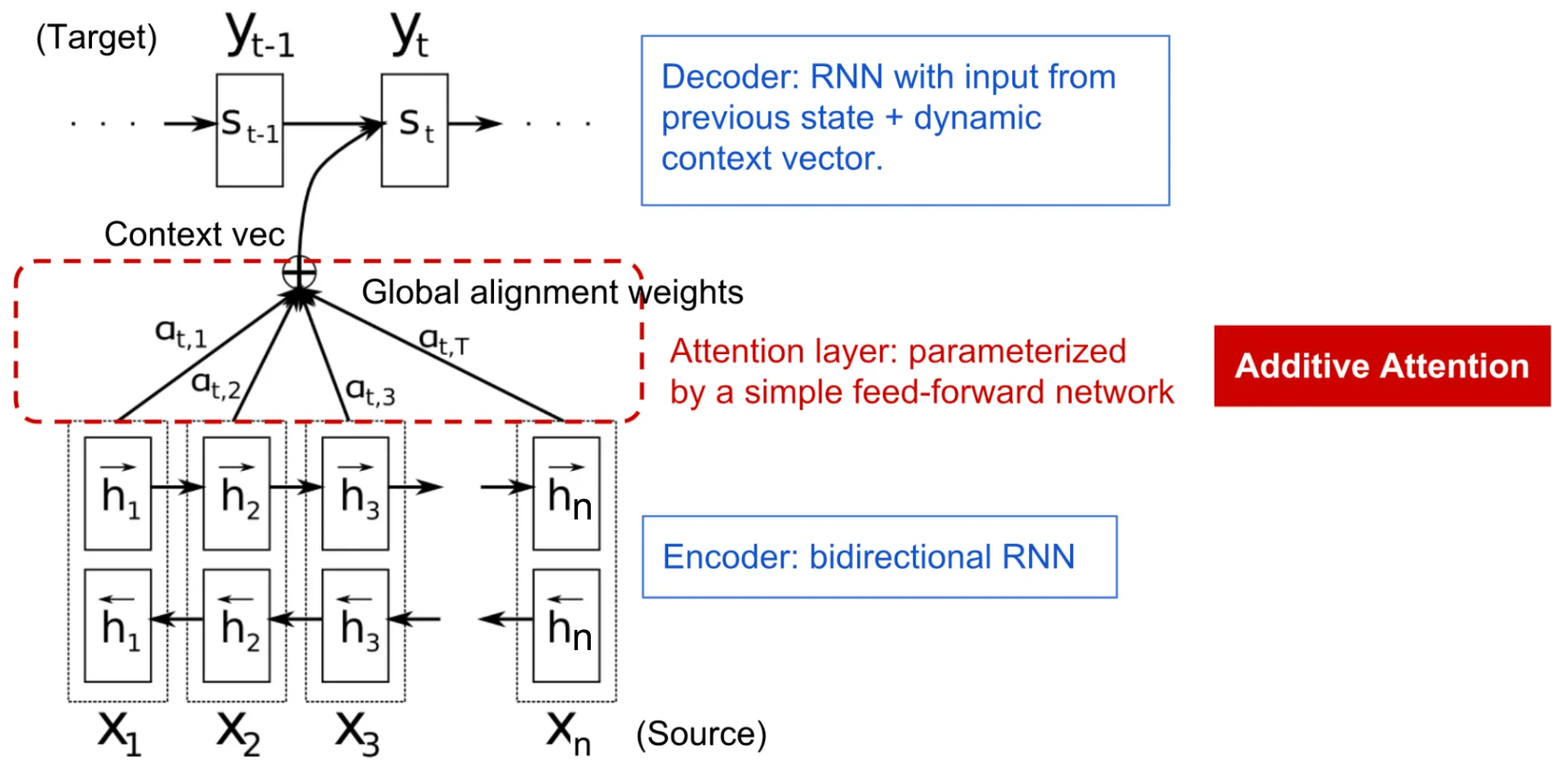
The Mechanism
- Encoder States: The encoder produces a sequence of hidden states .
- Alignment Scores: At decoding step , the model calculates a score for how well the input at position aligns with the output at position .
- Attention Weights: These scores are normalized using a softmax function to produce attention weights :
- Context Vector: The context vector for step is a weighted sum of all encoder hidden states:
PyTorch Attention
Here is a simplified implementation of dot-product attention in PyTorch, showing how we compute the context vector from decoder state and encoder states.
import torch
import torch.nn.functional as F
def simple_attention(decoder_state, encoder_states):
# decoder_state: (batch, 1, hidden_dim)
# encoder_states: (batch, seq_len, hidden_dim)
# 1. Calculate alignment scores (Dot product)
# scores shape: (batch, 1, seq_len)
scores = torch.bmm(decoder_state, encoder_states.transpose(1, 2))
# 2. Softmax to get attention weights
# weights shape: (batch, 1, seq_len)
attention_weights = F.softmax(scores, dim=-1)
# 3. Weighted sum of encoder states to get context vector
# context shape: (batch, 1, hidden_dim)
context = torch.bmm(attention_weights, encoder_states)
return context, attention_weights
# Example usage
batch_size = 1
seq_len = 5
hidden_dim = 4
# Simulated states
dec_state = torch.randn(batch_size, 1, hidden_dim)
enc_states = torch.randn(batch_size, seq_len, hidden_dim)
context, weights = simple_attention(dec_state, enc_states)
print("Context Vector Shape:", context.shape)
print("Attention Weights:\n", weights)Example: Translation Alignment
Visualize how a model attends to English words when translating to French. Click on a French word to see which English words the model focused on.
Attention Alignment Visualizer
Click on a French word (Target) to see which English words (Source) the model focused on.
Quizzes
Quiz 1: What is the “bottleneck” in traditional Encoder-Decoder models without attention?
The bottleneck is the fixed-size context vector. The encoder must compress the entire input sequence, regardless of its length, into a single vector. For long sentences, this causes information loss, especially for words at the beginning of the sequence.
Quiz 2: How does Attention compute the context vector differently than a standard RNN encoder?
In a standard RNN encoder, the context vector is simply the final hidden state of the RNN. In Attention, the context vector is a dynamically calculated weighted sum of all hidden states produced by the encoder, where the weights depend on the current decoding step.
Quiz 3: Does Bahdanau attention eliminate the need for recurrent connections?
No. Bahdanau attention was designed to enhance RNNs (specifically LSTMs or GRUs). The encoder and decoder were still recurrent networks. It was not until the “Attention is All You Need” paper (Transformer) that recurrent connections were removed entirely.
Quiz 4: Discuss the interpretability aspect of Attention models.
Attention models are more interpretable because the attention weights () can be visualized as a matrix (alignment matrix). This matrix shows exactly which source words the model was looking at when generating each target word, providing insight into the model’s decision-making process.
Quiz 5: What are common ways to compute the alignment score between decoder and encoder states?
Common methods include: 1) Dot-product: , which is simple and efficient. 2) General: , which uses a learnable weight matrix. 3) Concat (Bahdanau): , which uses a small multi-layer perceptron.
Quiz 6: Compare mathematically the alignment score formulations of Bahdanau (additive) attention and Luong (multiplicative/dot-product) attention, highlighting the difference in decoder hidden states used.
Bahdanau attention uses an additive mechanism: , where it aligns the previous decoder state with the encoder state . Luong attention introduced multiplicative formulations, most notably the ‘general’ score: , and ‘dot’: . Crucially, Luong attention aligns the current decoder state (computed after the initial RNN step) with the encoder state . Multiplicative attention is more computationally efficient as it can be optimized using highly parallelized matrix multiplications.
References
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv:1409.0473.