3.4 Layer Normalization & Residuals
Building deep Transformers requires more than just self-attention. To ensure stable training and allow networks to grow to hundreds of layers, two critical components are used: Layer Normalization and Residual Connections.
Motivation: The Deep Network Dilemma
As we stack more layers in a neural network:
- Covariate Shift: The distribution of inputs to deeper layers changes constantly during training, making it hard for them to learn.
- Degradation Problem: Adding more layers can sometimes lead to higher training error, not because of overfitting, but because gradients struggle to flow back through so many layers.
Layer Norm and Residuals are the stabilization pillars that make deep learning actually work at scale.
The Metaphor: The Choir and The Shortcut
Imagine you are leading a large choir.
- Layer Normalization is like a Volume Controller. If some singers are shouting and others are whispering, the harmony is ruined. Layer Norm ensures that at each step, everyone’s volume is adjusted to be at a standard, controlled level. It keeps the signals from blowing up or dying out.
- Residual Connections are like building a Highway next to a winding side street. If you want to send a message from the beginning of the city to the end, going through every side street (layer) takes a long time and the message might get lost. A residual connection provides a highway (skip connection) where the message can travel directly without distortion.
Residual Connections: The Highway
Introduced in ResNet (He et al., 2015) [1], residual connections simply add the input of a sub-layer to its output.
Behind-the-Scenes Story: When Kaiming He and his team proposed ResNet in 2015, they were motivated by a counter-intuitive discovery: adding more layers to a deep network caused the training error to increase. This wasn’t due to overfitting, but rather a fundamental difficulty in optimization. They introduced the simple idea of adding the input directly to the output, creating a ‘residual’ for the layer to learn. This brilliant hack allowed them to train networks with over 100 layers for the first time.
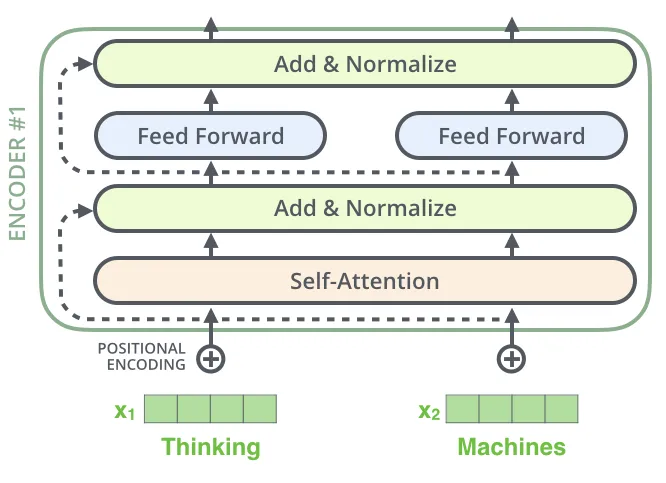
This simple addition operation allows gradients to flow directly through the identity mapping (), bypassing the complex non-linearities of the sub-layer during backpropagation. This effectively solves the vanishing gradient problem for extremely deep networks.
Layer Normalization: Keeping it Stable
Unlike Batch Normalization, which normalizes across the batch dimension, Layer Normalization (Ba et al., 2016) [2] normalizes the inputs across the features for each training case independently.
For a vector of dimension :
Where and are learnable parameters, and is a small constant for numerical stability. Layer Norm is preferred in NLP because it works well with variable sequence lengths and small batch sizes.
PyTorch Implementation
Here is how these are combined in a standard Transformer block.
import torch
import torch.nn as nn
class TransformerSublayer(nn.Module):
def __init__(self, d_model):
super(TransformerSublayer, self).__init__()
self.norm = nn.LayerNorm(d_model)
# Simulated sublayer (e.g., self-attention or feed-forward)
self.sublayer = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
# Post-LN architecture (as in original paper)
# 1. Sublayer operation
out = self.sublayer(x)
# 2. Dropout and Residual addition
out = x + self.dropout(out)
# 3. Layer Normalization
out = self.norm(out)
return out
# Example usage
d_model = 64
layer = TransformerSublayer(d_model)
x = torch.randn(2, 10, d_model)
output = layer(x)
print("Output Shape:", output.shape)[!NOTE] Modern Transformers often use Pre-LN, where normalization happens before the sublayer:
x + sublayer(norm(x)). This is found to be even more stable.
Pre-LN vs. Post-LN: The Architectural Shift
The original Transformer paper placed the Layer Normalization after the residual addition (Post-LN). However, most modern Transformers (like GPT-2, GPT-3, Llama) use Pre-LN. Let’s compare them:
Post-LN (Original)
- Pros: The output of each layer is well-normalized, which can lead to better performance if trained successfully.
- Cons: Gradients can become unstable at initialization, requiring a careful learning rate warm-up schedule. The variance of the hidden states increases as we go deeper.
Pre-LN (Modern Standard)
- Pros: Training is much more stable. Gradients can flow directly through the residual connection without being altered by normalization layers. This allows for training much deeper networks without complex warm-up schedules.
- Cons: The identity branch is directly added to, which can lead to representation collapse if not careful, though in practice it performs very well.
Researchers found that in Post-LN, the expected gradient norm at the layers near the input is much smaller than at the layers near the output, leading to vanishing gradients. Pre-LN solves this by ensuring that the gradient norm is well-behaved across all layers.
Example: Normalization Effect
See how Layer Normalization transforms a vector with wild values into a normalized distribution with mean 0 and variance 1.
Quizzes
Quiz 1: Why is Layer Normalization preferred over Batch Normalization in NLP?
Batch Normalization computes statistics across the batch dimension. In NLP, sequences often have variable lengths, making batch statistics unstable. Also, small batch sizes (often used due to memory constraints of large models) make Batch Norm inaccurate. Layer Norm computes statistics across features for each token independently, making it invariant to batch size and sequence length.
Quiz 2: How do Residual Connections solve the vanishing gradient problem?
In a residual block , the derivative with respect to the input contains a term from the identity mapping (i.e., ). This term ensures that gradients can flow back directly even if the derivative of is very small, preventing the gradient from vanishing.
Quiz 3: What is the difference between Pre-LN and Post-LN architectures?
In Post-LN (the original Transformer), normalization is applied after the residual addition: . In Pre-LN, normalization is applied to the input before the sublayer, and the output is added to the original input: . Pre-LN is found to be more stable for training very deep networks without warm-up.
Quiz 4: Why do we need the learnable parameters and in Layer Normalization?
Without and , Layer Normalization would force the activations to always have mean 0 and variance 1. This might limit the expressive power of the network. The learnable parameters allow the network to scale and shift the normalized values to whatever distribution is optimal for learning, effectively allowing the network to “undo” the normalization if that is beneficial.
Quiz 5: In the Post-LN formula , why does the variance grow with depth?
Since the output of the sublayer is added to the input before normalization, the variance of the sum is the sum of the variances (assuming independence). As we go deeper, these additions accumulate, causing the scale of the hidden states to grow before being squashed by the next LayerNorm. This makes optimization harder.
Quiz 6: Mathematically formulate the variance of the hidden state at layer for both Post-LN and Pre-LN architectures, assuming the sublayer output has a variance of .
In a standard residual branch without LayerNorm, the variance propagates as assuming independence. For Post-LN: . Since LayerNorm restores the variance to 1 at each step, the variance entering the next layer is always 1, but the hidden state scale before norm grows linearly: . For Pre-LN: . The variance grows linearly with depth: . Because Pre-LN maintains an unaltered identity branch, the scale of gradients flowing back is independent of , preventing vanishing gradients without warm-up.
References
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
- Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv:1607.06450.