3.1 Self-Attention Mathematics
The Transformer architecture, introduced in the seminal paper “Attention Is All You Need” (Vaswani et al., 2017), revolutionized AI by replacing recurrent structures with a mechanism called Self-Attention. This allows the model to process all tokens in a sequence simultaneously and model dependencies regardless of their distance.
Behind-the-Scenes Story: The title of the paper, ‘Attention Is All You Need,’ was a bold and provocative claim at the time. It suggested that one could completely discard RNNs and LSTMs, which had dominated sequence modeling for years, and rely solely on attention mechanisms. The authors at Google were motivated by the frustration with the slow training speeds of RNNs in machine translation. Their provocative title turned out to be a prophecy that changed the course of AI history.
Let’s understand the core mechanism through a familiar metaphor.
The Metaphor: The Filing Cabinet System
Imagine you are doing research in a library with a highly efficient filing system.
- Query (): This is what you are looking for. You have a topic in mind (e.g., “How do birds fly?”).
- Key (): These are the labels or tags on the filing folders. Each folder has a summary of what’s inside.
- Value (): This is the actual content inside the folder.
To find the information you need:
- You compare your Query against all the Keys to see which folders are relevant.
- You calculate a relevance score (Attention weight) for each folder.
- You extract the Values from the folders, giving more weight to the values from folders with high relevance scores.
In Self-Attention, every word in a sentence acts as a Query, a Key, and a Value to interact with every other word.
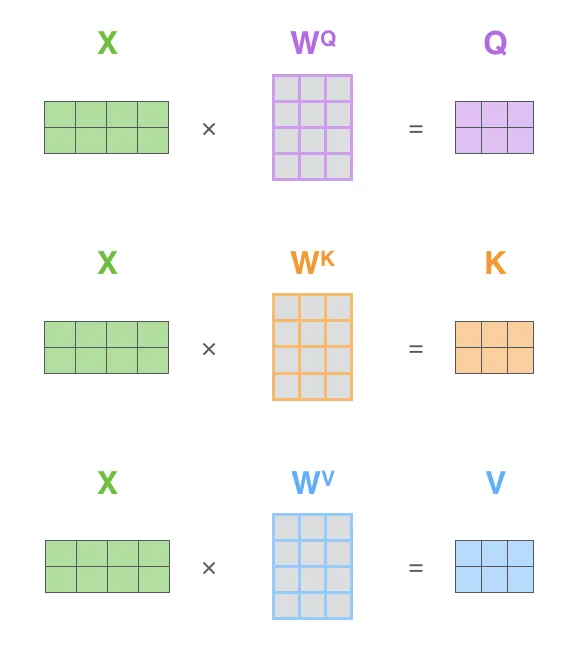
From Embeddings to Q, K, V: Linear Projections
In practice, we don’t use the input word embeddings directly as Queries, Keys, and Values. Instead, we project them into different spaces using learnable weight matrices.
Given an input sequence represented as a matrix , where is the sequence length and is the embedding dimension:
Where the learnable weight matrices are:
Why do we do this? If we used directly for all three roles, the self-attention operation would be purely based on the static embeddings. By using linear projections, the model can learn to extract different aspects of the same word for different roles. For example, a word might have a certain representation when acting as a Query looking for other words, and a different representation when acting as a Key being looked up. This significantly increases the expressiveness of the model.
The Mathematics of Scaled Dot-Product Attention
The core operation of Self-Attention is the Scaled Dot-Product Attention. Given a set of Queries, Keys, and Values packed into matrices and , the operation is defined as:
Where:
- (Matrix of Queries)
- (Matrix of Keys)
- (Matrix of Values)
- is the sequence length.
- is the dimension of the keys (and queries).
- is the scaling factor.
Step-by-Step Breakdown
- Dot Product (): Measures the raw similarity between each query and all keys.
- Scaling (): Prevents the dot products from growing too large in magnitude, which would push the softmax function into regions with extremely small gradients.
- Softmax: Converts the scaled scores into probabilities (attention weights) that sum to 1.
- Weighted Sum (): Multiplies the attention weights by the values to get the final output.
PyTorch Implementation
Let’s implement this operation from scratch in PyTorch. This is the core building block of the Transformer.
import torch
import torch.nn as nn
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Compute Scaled Dot-Product Attention.
"""
d_k = query.size(-1)
# Step 1 & 2: Dot product and scaling
# query shape: (batch, heads, seq_len, d_k)
# key.transpose(-2, -1) shape: (batch, heads, d_k, seq_len)
# scores shape: (batch, heads, seq_len, seq_len)
scores = torch.matmul(query, key.transpose(-2, -1)) / (d_k ** 0.5)
# Optional: Apply mask (e.g., for causal autoregressive decoding)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# Step 3: Softmax to get attention weights
attention_weights = F.softmax(scores, dim=-1)
# Step 4: Weighted sum of values
# output shape: (batch, heads, seq_len, d_v)
output = torch.matmul(attention_weights, value)
return output, attention_weights
# Example usage
batch_size = 1
seq_len = 4
d_k = 8
d_v = 8
# Random Tensors
Q = torch.randn(batch_size, 1, seq_len, d_k)
K = torch.randn(batch_size, 1, seq_len, d_k)
V = torch.randn(batch_size, 1, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Output Shape:", output.shape)
print("Attention Weights Shape:", weights.shape)Example: Attention Weight Matrix
Visualize how words attend to each other. Click on a word in the sentence to see its attention weights to all other words. (Simulated attention weights).
Quizzes
Quiz 1: Why is the scaling factor necessary in the attention formula?
As the dimension grows large, the magnitude of the dot products grows large. This pushes the softmax function into regions where the gradient is extremely small (vanishing gradients). Dividing by scales the variance of the dot products back to approximately 1, ensuring stable gradients.
Quiz 2: What is the difference between Self-Attention and standard Attention (like Bahdanau Attention)?
Standard attention typically aligns a decoder state with encoder states (cross-attention). Self-attention relates different positions of a single sequence to compute a representation of the same sequence (e.g., words in a sentence attending to other words in the same sentence).
Quiz 3: In the interactive example, why does the word “it” attend strongly to “animal”?
This demonstrates coreference resolution. The model learns that “it” refers to the “animal” in this context, because of the semantic relationship and the word “tired” appearing later. This is the power of Self-Attention—capturing long-range dependencies and context.
Quiz 4: Why do we use linear projections to create Q, K, V instead of using the input embeddings directly?
Linear projections allow the model to learn different representations for the same word depending on its role (Query, Key, or Value). This increases the model’s capacity to capture complex relationships compared to using static embeddings directly.
Quiz 5: How does Self-Attention handle variable-length sequences?
Self-attention handles variable-length sequences naturally because the attention operation (weighted sum) does not depend on a fixed sequence length. The output dimension is determined by the input sequence length, and the same parameters (projection matrices) are used regardless of length.
Quiz 6: Formally derive the number of parameters and the total floating-point operations (FLOPs) for a single self-attention layer with sequence length , embedding dimension , and .
Parameters: The layer requires projection matrices of dimension . The total number of parameters is . (Excluding bias for simplicity).
FLOPs: 1. Linear Projections: each require FLOPs (multiply and add). Total: .
2. Attention Matrix : Multiplying a matrix by a matrix requires FLOPs.
3. Softmax and Scaling: operations.
4. Multiplying with : Multiplying a attention matrix with a matrix requires FLOPs.
Total dominant FLOPs: .
References
- Vaswani, A., et al. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). arXiv:1706.03762.