4.3 Encoder-Decoder (T5/BART)
The Encoder-Decoder architecture, also known as Seq2Seq, is the original Transformer design introduced in Attention Is All You Need. It splits the job in two: an Encoder reads and organizes the input, and a Decoder turns that representation into an output sequence.
There is a simple reason this design remains important even in the age of decoder-only LLMs. Some tasks do not feel like open-ended continuation. They feel like careful transformation: translate this sentence, summarize this article, rewrite this paragraph, convert this structure into another one. Encoder-decoder models were built for exactly that style of work.
So while general-purpose assistants shifted toward decoder-only models, encoder-decoder systems remain a strong fit whenever the input sequence itself must be modeled precisely before generation begins.
The Metaphor: The Translator and The Scribe
Imagine a process of translating a book from French to English:
- The Encoder (The French Expert): Reads the entire French sentence, understands the context, and creates a detailed mental map of the meaning.
- The Decoder (The English Scribe): Takes the mental map from the encoder and starts writing the English sentence, word by word, ensuring it flows naturally in English while staying true to the original meaning.
This division of labor is the essence of the Encoder-Decoder architecture.
The Architecture: Bridging Two Worlds
The defining feature of this architecture is the interaction between the Encoder and the Decoder, mediated by Cross-Attention.
- Encoder: Uses Bidirectional Self-Attention to process the input.
- Decoder: Uses Causal Self-Attention to generate the output autoregressively.
- Cross-Attention: The Decoder attends to the Encoder’s output, allowing it to focus on relevant parts of the input sequence while generating each output token.
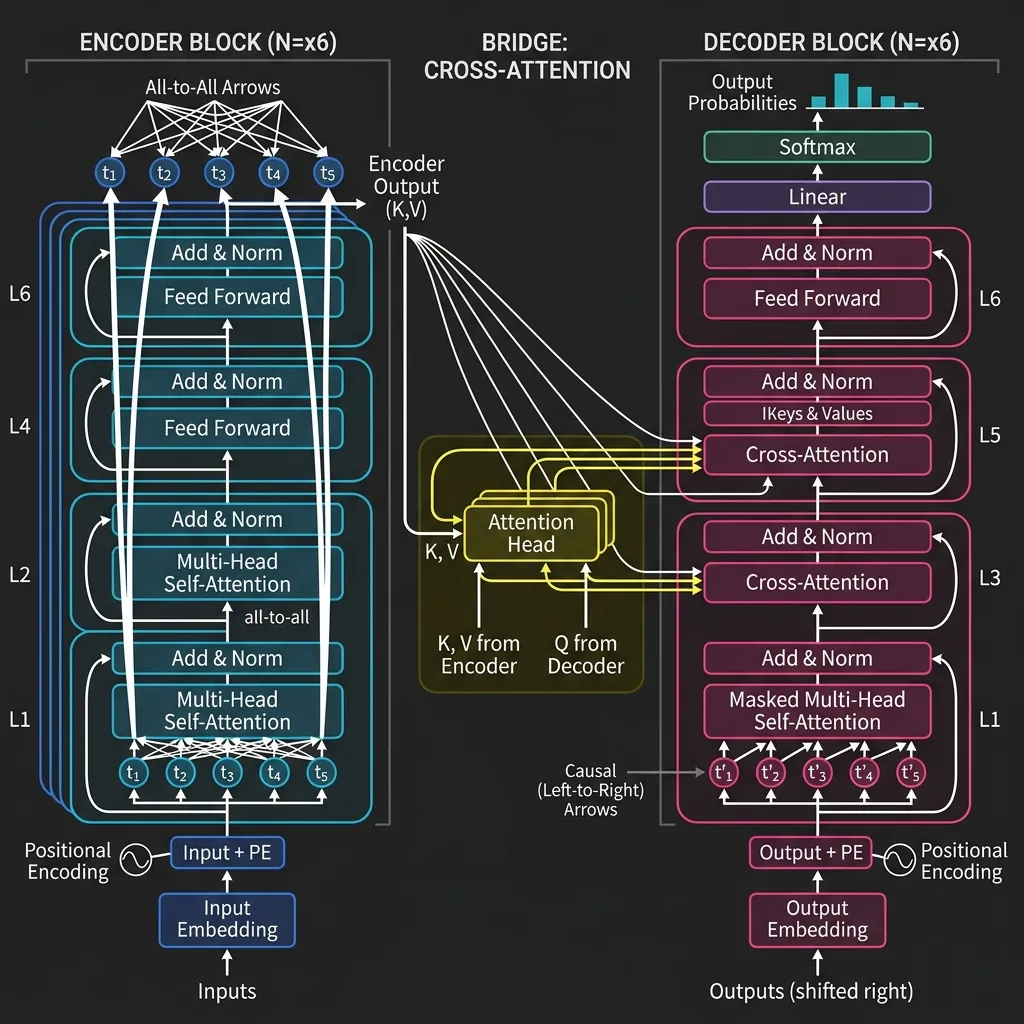
Core Mechanism: Cross-Attention
In Cross-Attention, the Queries () come from the Decoder’s previous layer, while the Keys () and Values () come from the Encoder’s output.
This allows the decoder to “look back” at the input sentence at every step of generation.
Evolution and Key Models
1. T5 (Text-to-Text Transfer Transformer)
Motivation: Before T5, different NLP tasks often required different model architectures or output heads (e.g., a classification head for sentiment analysis, a span prediction head for question answering). Google aimed to simplify this by proposing a unified framework where every NLP task is cast as a text-to-text problem, allowing the same model, loss function, and hyperparameters to be used across all tasks [1].
Key Innovations:
- Text-to-Text Framework: Framed tasks like translation, summarization, and even classification as mapping input text to output text. For example, to classify sentiment, the input is “sentiment: This movie is great” and the model outputs the text “positive”.
- Span Corruption Pre-training: Instead of masking single tokens, T5 masked contiguous spans of tokens and trained the model to reconstruct them, which proved more effective for sequence-to-sequence tasks.
- Scale and Data: Introduced the C4 dataset (Colossal Clean Crawled Corpus), pushing the boundaries of scale for Encoder-Decoder models.
2. BART
Motivation: Facebook’s BART was designed to combine the strengths of bidirectional encoders (like BERT) and autoregressive decoders (like GPT). The goal was to create a model that could excel at both understanding tasks and generation tasks, particularly those requiring sequence-to-sequence mapping like summarization and translation.
Key Innovations:
- Denoising Autoencoder: Trained by corrupting text with various noising operations and learning to reconstruct the original text [2]. Operations included token masking, token deletion, text infilling, sentence permutation, and document rotation.
- Autoregressive Decoder: Unlike BERT which predicts masked tokens in parallel, BART’s decoder generates the output autoregressively, making it much better suited for generating fluent text.
Comparison of Encoder-Decoder Models
| Feature | T5 | BART |
|---|---|---|
| Core Idea | Text-to-Text Unification | Denoising Autoencoder |
| Pre-training Task | Span Corruption (Fill in the blanks) | Multiple Denoising Tasks (Masking, Deletion, etc.) |
| Architecture | Standard Encoder-Decoder | Encoder + Autoregressive Decoder |
| Best Suited For | Multitask Learning, Translation | Summarization, Comprehension |
PyTorch Implementation: Cross-Attention
Here is a simplified implementation of the Cross-Attention mechanism.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_linear = nn.Linear(d_model, d_model)
def forward(self, decoder_hidden, encoder_output):
# decoder_hidden: (batch, seq_len_dec, d_model)
# encoder_output: (batch, seq_len_enc, d_model)
batch_size = decoder_hidden.size(0)
# Project and split into heads
Q = self.q_linear(decoder_hidden).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.k_linear(encoder_output).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.v_linear(encoder_output).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# Scaled dot-product attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
weights = F.softmax(scores, dim=-1)
# Output
output = torch.matmul(weights, V)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
return self.out_linear(output), weights
# Example usage
d_model = 64
num_heads = 4
seq_len_dec = 5
seq_len_enc = 10
batch_size = 2
decoder_hidden = torch.randn(batch_size, seq_len_dec, d_model)
encoder_output = torch.randn(batch_size, seq_len_enc, d_model)
cross_attn = CrossAttention(d_model, num_heads)
output, weights = cross_attn(decoder_hidden, encoder_output)
print("Output Shape:", output.shape) # Expected: (2, 5, 64)
print("Attention Weights Shape:", weights.shape) # Expected: (2, 4, 5, 10)Quizzes
Quiz 1: What is the main structural difference between Cross-Attention and Self-Attention?
In Self-Attention, the Queries, Keys, and Values all come from the same sequence. In Cross-Attention, the Queries come from the decoder (representing the target sequence being generated), while the Keys and Values come from the encoder (representing the source sequence being processed).
Quiz 2: Why are Encoder-Decoder models traditionally preferred for machine translation over Decoder-only models?
Because translation requires a full understanding of the source sentence before generating the target sentence. The encoder can create a rich, bidirectional representation of the source, and the decoder can then generate the translation while attending to this representation via cross-attention.
Quiz 3: How does T5 frame classification tasks (like sentiment analysis) as a text-to-text problem?
T5 takes the text to be classified as input (e.g., “translate English to German: Hello”) and is trained to output the text label directly (e.g., “positive” or “negative”) rather than a class index. This unifies all tasks into a single format.
Quiz 4: What is the purpose of the “denoising” objective in BART?
The denoising objective forces the model to recover original text from corrupted input. This teaches the model to understand the structure and semantics of language deeply, making it better at generating coherent text during fine-tuning for tasks like summarization.
Quiz 5: Why did Decoder-only models eventually become more popular than Encoder-Decoder models for general-purpose LLMs?
Decoder-only models are simpler to scale, require less complex infrastructure for serving, and exhibited powerful emergent abilities like in-context learning, which made them highly effective as general-purpose assistants without task-specific fine-tuning.
References
- Raffel, C., et al. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:1910.10683.
- Lewis, M., et al. (2019). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv:1910.13461.