4.4 Hybrid & Prefix LM
While Encoder-only and Decoder-only models represent the two extremes of the Transformer spectrum, Hybrid and Prefix Language Models (Prefix LM) aim to bridge the gap, offering the best of both worlds.
These architectures are designed to handle tasks that require both deep bidirectional understanding of a prompt (like an Encoder) and fluent autoregressive generation (like a Decoder), without the full complexity of a separate Encoder-Decoder architecture.
The Metaphor: The Guided Storyteller
Imagine a writer who is given a detailed outline (the Prefix) and asked to write the story (the Target).
- While reading and understanding the outline, the writer can look back and forth freely to grasp the full context.
- However, when writing the story itself, they must write word by word, only looking at what they have written so far and the outline.
This is how a Prefix LM works. It allows bidirectional attention within the prefix (prompt) but enforces causal attention for the generated target.
Prefix LM: Non-Causal Attention on the Prompt
In a Prefix LM, the input sequence is divided into two parts: a prefix of length and a target of length .
- Prefix Tokens (): Can attend to all other prefix tokens bidirectionally.
- Target Tokens (): Can attend to all prefix tokens and all preceding target tokens (causal attention).
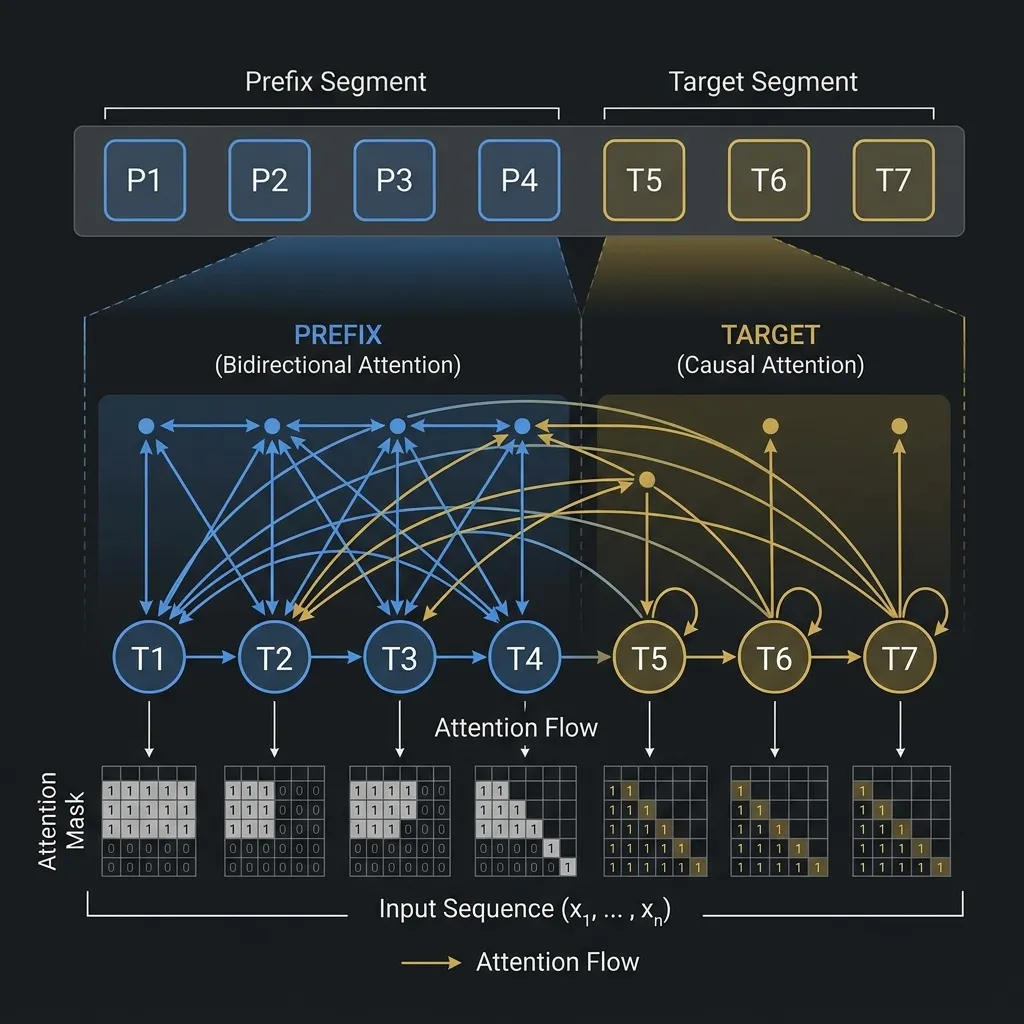
As shown in the diagram, the attention mask is a hybrid: full visibility in the prefix region and a lower-triangular shape in the target region.
Key Models and Innovations
1. GLM (General Language Model) (2021)
Motivation: The AI field was divided between Encoder-only models (good for understanding) and Decoder-only models (good for generation). The authors of GLM wanted to create a single model that could excel at both types of tasks by unifying the pre-training objectives. They aimed to overcome the limitations of BERT (not suitable for generation) and GPT (suboptimal for understanding due to unidirectional attention).
Key Innovations:
- Autoregressive Blank Infilling: GLM randomly blanks out contiguous spans of tokens from the input (similar to T5’s span corruption). However, instead of predicting them in parallel, it reconstructs them autoregressively, token by token [1].
- 2D Positional Encoding: To handle the autoregressive generation of missing spans, GLM uses a unique 2D positional encoding that captures both the position in the original sentence and the position within the generated span.
- Flexibility: By varying the number and length of blanks, GLM can be trained to act like an Encoder-only model, a Decoder-only model, or a full Encoder-Decoder model.
2. PaLM and Parallel Attention
While Google’s PaLM (Pathways Language Model) is primarily a Decoder-only model, it introduced architectural tweaks that are highly relevant to hybrid designs.
- Parallel Layers: Instead of serialized attention and feed-forward layers (LayerNorm -> Attention -> LayerNorm -> FFN), PaLM executed them in parallel. This improved training speed significantly on TPU clusters.
- Relevance to Hybrid Designs: This parallel structure inspired later hybrid models that try to balance the heavy context processing of encoders with the fast generation of decoders.
PyTorch Implementation: Prefix Mask
Here is how to construct an attention mask for a Prefix LM in PyTorch.
import torch
def create_prefix_mask(prefix_len, total_len):
"""
Create an attention mask for a Prefix LM.
"""
mask = torch.zeros(total_len, total_len)
# 1. Prefix can attend to all prefix tokens bidirectionally
mask[:prefix_len, :prefix_len] = 1
# 2. Target tokens can attend to all prefix tokens and preceding target tokens
for i in range(prefix_len, total_len):
mask[i, :i+1] = 1
return mask
# Example usage
prefix_len = 3
total_len = 7 # prefix_len (3) + target_len (4)
mask = create_prefix_mask(prefix_len, total_len)
print("Prefix LM Mask:")
print(mask)Expected output for prefix_len=3 and total_len=7:
[[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1.]]Quizzes
Quiz 1: How does a Prefix LM differ from a standard Decoder-only model in processing the prompt?
A standard Decoder-only model processes the prompt causally, meaning a token in the prompt cannot attend to subsequent tokens in the prompt. A Prefix LM allows bidirectional attention within the prompt, allowing tokens to see the entire context of the prompt.
Quiz 2: What is the main advantage of Prefix LM over a full Encoder-Decoder architecture?
Prefix LM uses a single unified stack of Transformer layers, whereas Encoder-Decoder uses two separate stacks. This makes Prefix LM simpler to implement and potentially more parameter-efficient, while still providing some benefits of bidirectional prompt understanding.
Quiz 3: In the PyTorch example, why is the top-left block of the mask filled with 1s?
Because the prefix length is 3, and tokens in the prefix are allowed to attend to all other tokens in the prefix bidirectionally. Thus, all pairs within the prefix have valid attention.
Quiz 4: For what kind of tasks might a Prefix LM be particularly suitable?
Prefix LMs are suitable for tasks with a clear separation between a context/prompt and a generation target, such as summarization (prompt is the text, target is the summary) or translation, where full understanding of the prompt is beneficial before generation begins.
Quiz 5: What is the core idea behind GLM’s pre-training objective?
GLM uses an autoregressive blank-infilling objective. It randomly blanks out contiguous spans of tokens from the input and trains the model to reconstruct them autoregressively, allowing it to handle both understanding and generation tasks effectively.
References
- Du, Z., et al. (2021). GLM: General Language Model Pretraining with Autoregressive Blank Infilling. arXiv:2103.10360.