9.3 Parameter-Efficient Fine-Tuning (PEFT)
In the previous section, we established that dataset curation often matters more than raw volume during post-training. We can distill alignment into a few thousand carefully crafted examples. However, a significant engineering bottleneck remains: even with a small dataset, updating the weights of a 70-billion parameter model is still computationally expensive.
During Full Fine-Tuning (FFT), the system must store the model weights, the optimizer states (e.g., Adam’s first and second moments), the gradients, and the forward activations. For a 70B model using 16-bit precision, this footprint can move into multi-terabyte territory and often requires cluster-scale GPU resources just to avoid Out-Of-Memory (OOM) errors.
To democratize model adaptation and enable rapid iteration, practitioners widely use Parameter-Efficient Fine-Tuning (PEFT). Instead of updating the entire network, PEFT methods freeze the pre-trained weights and inject or optimize a minuscule fraction of parameters (often ).
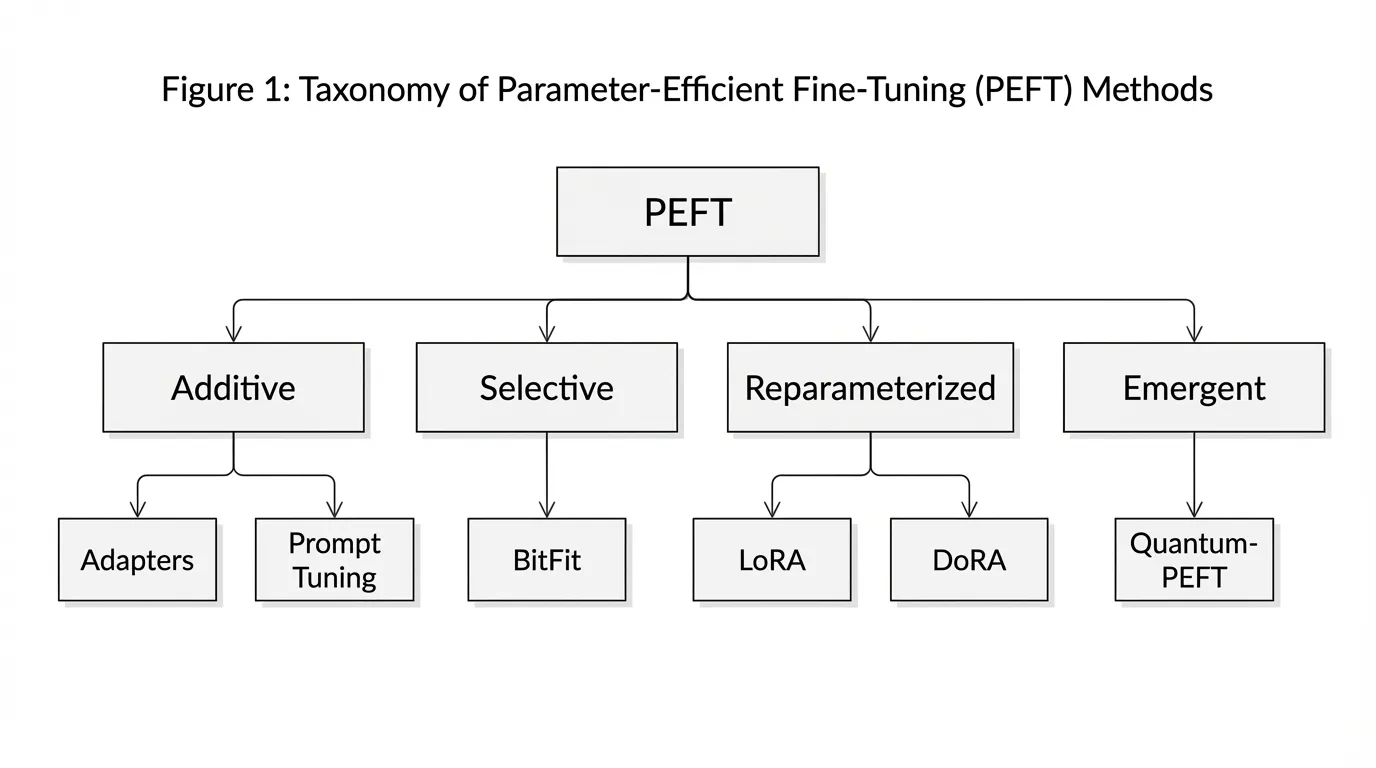
The Taxonomy of PEFT
The landscape of PEFT has matured significantly over the past few years. According to recent comprehensive surveys [1], PEFT methodologies can be categorized into four distinct structural paradigms:
- Additive PEFT: Introduces entirely new parameters into the architecture. This includes Adapters (small feed-forward networks inserted between transformer layers) and Prompt/Prefix Tuning (appending trainable continuous vectors to the input sequence).
- Selective PEFT: Identifies and updates a very small subset of the existing pre-trained parameters. A prominent example is BitFit, which only fine-tunes the bias terms of the network while freezing all weight matrices.
- Reparameterized PEFT: Leverages mathematical structures (typically low-rank matrices) to represent weight updates in a highly compressed form. LoRA and its variants dominate this category.
- Emergent PEFT (Exploratory Frontier): Next-generation techniques that move beyond linear scaling laws, exploring advanced mathematical frameworks like quantum unitary parameterization to achieve sublinear or logarithmic parameter scaling.
Reparameterization: LoRA and DoRA
In practice, the most common PEFT family is Low-Rank Adaptation (LoRA). Its popularity stems from a crucial engineering advantage: unlike Additive methods (Adapters), LoRA introduces no extra inference path once the learned update is merged back into the base weights.
The Mathematics of LoRA
The core hypothesis of LoRA is that the change in weights () required to adapt a model to a specific task has a low “intrinsic rank.” While a pre-trained weight matrix might have dimensions (e.g., ), the meaningful updates do not span this entire high-dimensional space.
LoRA freezes and represents the update as the product of two low-rank matrices, and :
Where:
- is the frozen pre-trained weight.
- is initialized to zero.
- is initialized with a Gaussian distribution.
- is the low rank (typically 8, 16, or 64).
- is a constant scaling factor.
Because is initialized to zero, at the start of training, ensuring the model behaves exactly like the pre-trained base model before any gradient updates occur.
Engineering the Forward Pass
Below is a realistic, production-grade PyTorch implementation of a LoRA layer injected into a standard linear transformation. Notice how the gradients are only computed for the small matrices and .
import torch
import torch.nn as nn
import math
class LoRALinear(nn.Module):
def __init__(self, in_features: int, out_features: int, r: int = 16, lora_alpha: int = 32, dropout: float = 0.05):
super().__init__()
# 1. The original pre-trained weight (Frozen)
self.linear = nn.Linear(in_features, out_features, bias=False)
self.linear.weight.requires_grad = False
# 2. LoRA specific attributes
self.r = r
self.lora_alpha = lora_alpha
self.scaling = self.lora_alpha / self.r
# 3. Low-rank matrices (Trainable)
self.lora_A = nn.Linear(in_features, r, bias=False)
self.lora_B = nn.Linear(r, out_features, bias=False)
self.dropout = nn.Dropout(p=dropout)
self.reset_parameters()
def reset_parameters(self):
# Initialize A with Kaiming uniform (similar to standard linear init)
nn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))
# Initialize B with zeros so that initial Delta W is exactly 0
nn.init.zeros_(self.lora_B.weight)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Standard forward pass through frozen weights
frozen_out = self.linear(x)
# LoRA forward pass: x -> Dropout -> A -> B -> Scale
lora_out = self.lora_B(self.lora_A(self.dropout(x))) * self.scaling
return frozen_out + lora_out
def merge_weights(self):
"""Merges the learned LoRA weights into the base model for zero-latency inference."""
if not self.linear.weight.requires_grad:
# W_new = W_0 + (B @ A) * scaling
delta_w = (self.lora_B.weight @ self.lora_A.weight) * self.scaling
self.linear.weight.data += delta_w
self.linear.weight.requires_grad = True # Mark as mergedPractical Implementation: PEFT & Unsloth
While implementing LoRA from scratch is valuable for understanding its mechanics, production workflows typically rely on specialized libraries that handle edge cases, multi-GPU scaling, and quantization automatically.
1. Hugging Face PEFT
The peft library is the industry standard for parameter-efficient fine-tuning. It integrates seamlessly with the transformers ecosystem.
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
# Load pre-trained base model
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B")
# Define LoRA configuration
peft_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # Apply to attention projections
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Wrap model with PEFT
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()2. Ultra-Fast Fine-Tuning with Unsloth
For maximum efficiency on single or few GPUs, unsloth has become highly popular. It provides hand-optimized Triton kernels that accelerate training by up to 2x and reduce memory usage significantly.
from unsloth import FastLanguageModel
import torch
# Load model optimized by Unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-Instruct",
max_seq_length = 2048,
dtype = None, # Auto-detect (float16 or bfloat16)
load_in_4bit = True, # Use 4-bit quantization
)
# Apply LoRA
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0, # Optimized for 0
bias = "none", # Optimized for "none"
use_gradient_checkpointing = "unsloth",
)Beyond LoRA: DoRA (Weight-Decomposed Low-Rank Adaptation)
While LoRA is efficient, researchers observed that it updates the magnitude and direction of the weight vectors in a coupled manner, which differs from how Full Fine-Tuning operates.
DoRA separates the pre-trained weight into two components: a magnitude vector and a directional matrix . It applies the LoRA update only to the directional matrix , while allowing the magnitude vector to be trained independently. This subtle geometric decoupling allows DoRA to closely mimic the learning dynamics of Full Fine-Tuning, often achieving superior accuracy on complex reasoning tasks without increasing the parameter count at inference time.
The “Unifying View” and the Bias-Only Paradox
As the PEFT literature exploded, hundreds of new methods claimed State-of-the-Art (SOTA) status. However, a critical 2025 CVPR study by Mai et al. [2] provided a much-needed reality check on the perceived complexity of PEFT methods.
The Tuning Fairness Problem
The study revealed that many complex PEFT methods appeared superior simply because they received extensive hyperparameter tuning, while baselines were neglected. When simple Selective PEFT methods—like BitFit (tuning only the bias terms of the network)—were given the same “hyperparameter love,” they routinely matched or exceeded the performance of sophisticated methods like LoRA or Adapters.
Inductive Biases & Mistake Diversity
If a simple Bias-tuning method achieves 85% accuracy and a complex LoRA method also achieves 85% accuracy, are they identical? The study proved they are not. Even when overall accuracy is identical, different PEFT methods make completely different mistakes.
This implies that PEFT architectures impose distinct inductive biases on the model. Additive methods prioritize retaining pre-trained features intact, while reparameterized methods prioritize shifting the geometric space of the features.
Expert Insight: The frontier of PEFT engineering isn’t necessarily finding a single “best” method. Because different PEFT techniques fail on different data distributions, engineers are increasingly deploying Weight-Space Ensembles—training multiple cheap adapters (e.g., one LoRA, one Prompt Tuner) and averaging their weights or outputs to achieve superior robustness against distribution shifts.
An Exploratory Frontier: Logarithmic Scaling via Quantum-PEFT
Traditional PEFT methods like LoRA scale linearly with the model’s dimension (). As Foundation Models scale to extreme widths, even the lowest-rank LoRA matrices begin to consume gigabytes of memory.
A 2025 preprint by Koike-Akino et al. [3] explores Quantum-PEFT, proposing a shift from linear to logarithmic scaling.
Instead of using standard matrix multiplication, Quantum-PEFT utilizes quantum unitary parameterization (specifically, Pauli parameterization). By mapping the weight updates into a highly structured quantum tensor space, the number of trainable parameters grows logarithmically with the ambient dimension ().
In the authors’ formulation, Quantum-PEFT can in principle represent a full-rank update while using far fewer trainable parameters than a rank-1 LoRA baseline. If that behavior proves robust in broader practice, it would make the approach especially interesting for severely resource-constrained adaptation settings.
Interactive Visualizer: The VRAM Impact
Use the interactive component below to simulate the parameter footprint of a single square weight matrix () during Full Fine-Tuning versus LoRA. Notice how drastically the parameter count drops, yet performance remains remarkably similar.
LoRA Parameter Efficiency Calculator
Full Fine-Tuning
Matrix W (d × d)
LoRA
Matrices A (d × r) + B (r × d)
Summary & Next Steps
Parameter-Efficient Fine-Tuning has evolved from a memory-saving trick into a fundamental pillar of Foundation Model engineering. From the simple elegance of bias-tuning to the geometric precision of DoRA and the logarithmic scaling of Quantum-PEFT, these techniques allow us to mold massive models without destroying their pre-trained generalizations.
However, adjusting weights—even efficiently—is still a gradient-based optimization process requiring datasets and compute. What if we could adapt a model to a new task without computing a single gradient? In the next section, 9.4 Prompt Engineering as SFT, we will explore how carefully constructed Few-Shot prompts and Chain-of-Thought structures can temporarily “fine-tune” a model’s behavior entirely in the activation space during inference.
Quizzes
Quiz 1: Why is LoRA preferred over Additive Adapters for production serving, despite both reducing training memory?
Additive Adapters introduce new neural network layers into the forward pass, which increases inference latency. LoRA, on the other hand, allows the learned low-rank matrices (B and A) to be mathematically multiplied and added directly to the original frozen weights () post-training. This results in zero additional latency during inference.
Quiz 2: According to the 2025 CVPR “Unifying View” study, why did simple methods like BitFit (Bias-tuning) historically appear inferior to complex methods in literature?
Due to a lack of “Tuning Fairness.” Researchers often spent significant compute tuning the hyperparameters (learning rate, weight decay, etc.) of their novel, complex PEFT methods while using default, unoptimized hyperparameters for simple baselines like BitFit. When tuned equally, BitFit is highly competitive.
Quiz 3: If LoRA and Prompt Tuning achieve the exact same accuracy on a validation set, why might an engineer still choose to train both?
Because different PEFT methods impose different inductive biases, causing them to make different mistakes on edge cases. By training both cheap adapters and ensembling them (e.g., via weight-space averaging or routing), the engineer can achieve higher overall robustness and generalization than using a single method.
Quiz 4: What scaling advantage is Quantum-PEFT aiming for relative to LoRA?
LoRA’s parameter count scales linearly with the model’s dimension (). Quantum-PEFT explores Pauli parameterization (quantum unitary structures) to push parameter growth toward logarithmic scaling (). In the authors’ formulation, that structure can in principle approximate full-rank updates with far fewer trainable parameters, though the idea remains exploratory.
References
- Wang, Y., et al. (2024). Parameter-Efficient Fine-Tuning in Large Models: A Survey of Methodologies. arXiv:2410.19878.
- Mai, Z., et al. (2025). Lessons and Insights from a Unifying Study of Parameter-Efficient Fine-Tuning (PEFT) in Visual Recognition. CVPR 2025. arXiv:2403.14771.
- Koike-Akino, T., et al. (2025). Quantum-PEFT: Ultra parameter-efficient fine-tuning. arXiv:2503.05431.